


(beta) Dynamic Quantization on BERT¶
Tip
To get the most of this tutorial, we suggest using this Colab Version. This will allow you to experiment with the information presented below.
Author: Jianyu Huang
Reviewed by: Raghuraman Krishnamoorthi
Edited by: Jessica Lin
Introduction¶
In this tutorial, we will apply the dynamic quantization on a BERT model, closely following the BERT model from the HuggingFace Transformers examples. With this step-by-step journey, we would like to demonstrate how to convert a well-known state-of-the-art model like BERT into dynamic quantized model.
BERT, or Bidirectional Embedding Representations from Transformers, is a new method of pre-training language representations which achieves the state-of-the-art accuracy results on many popular Natural Language Processing (NLP) tasks, such as question answering, text classification, and others. The original paper can be found here.
Dynamic quantization support in PyTorch converts a float model to a quantized model with static int8 or float16 data types for the weights and dynamic quantization for the activations. The activations are quantized dynamically (per batch) to int8 when the weights are quantized to int8. In PyTorch, we have torch.quantization.quantize_dynamic API, which replaces specified modules with dynamic weight-only quantized versions and output the quantized model.
We demonstrate the accuracy and inference performance results on the Microsoft Research Paraphrase Corpus (MRPC) task in the General Language Understanding Evaluation benchmark (GLUE). The MRPC (Dolan and Brockett, 2005) is a corpus of sentence pairs automatically extracted from online news sources, with human annotations of whether the sentences in the pair are semantically equivalent. As the classes are imbalanced (68% positive, 32% negative), we follow the common practice and report F1 score. MRPC is a common NLP task for language pair classification, as shown below.
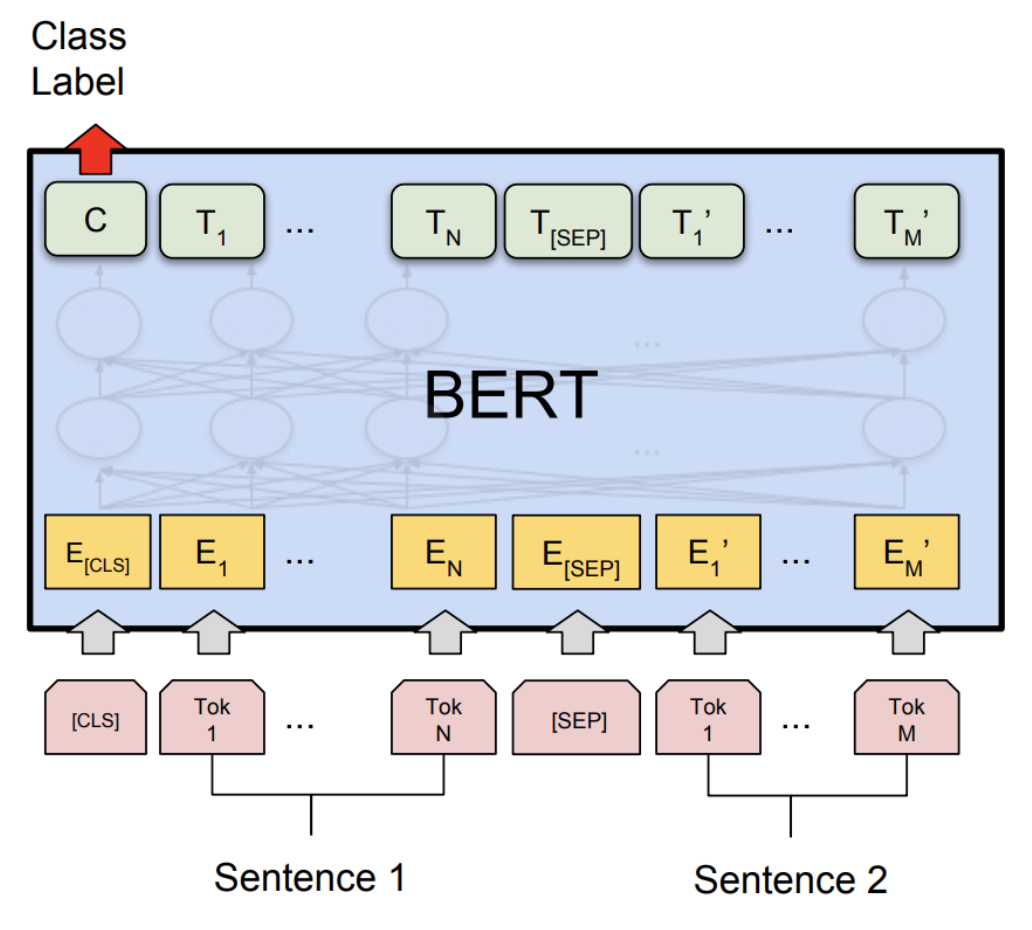
1. Setup¶
1.1 Install PyTorch and HuggingFace Transformers¶
To start this tutorial, let’s first follow the installation instructions in PyTorch here and HuggingFace Github Repo here. In addition, we also install scikit-learn package, as we will reuse its built-in F1 score calculation helper function.
pip install sklearn
pip install transformers==4.29.2
Because we will be using the beta parts of the PyTorch, it is recommended to install the latest version of torch and torchvision. You can find the most recent instructions on local installation here. For example, to install on Mac:
yes y | pip uninstall torch tochvision
yes y | pip install --pre torch -f https://download.pytorch.org/whl/nightly/cu101/torch_nightly.html
1.2 Import the necessary modules¶
In this step we import the necessary Python modules for the tutorial.
import logging
import numpy as np
import os
import random
import sys
import time
import torch
from argparse import Namespace
from torch.utils.data import (DataLoader, RandomSampler, SequentialSampler,
TensorDataset)
from tqdm import tqdm
from transformers import (BertConfig, BertForSequenceClassification, BertTokenizer,)
from transformers import glue_compute_metrics as compute_metrics
from transformers import glue_output_modes as output_modes
from transformers import glue_processors as processors
from transformers import glue_convert_examples_to_features as convert_examples_to_features
# Setup logging
logger = logging.getLogger(__name__)
logging.basicConfig(format = '%(asctime)s - %(levelname)s - %(name)s - %(message)s',
datefmt = '%m/%d/%Y %H:%M:%S',
level = logging.WARN)
logging.getLogger("transformers.modeling_utils").setLevel(
logging.WARN) # Reduce logging
print(torch.__version__)
We set the number of threads to compare the single thread performance between FP32 and INT8 performance. In the end of the tutorial, the user can set other number of threads by building PyTorch with right parallel backend.
torch.set_num_threads(1)
print(torch.__config__.parallel_info())
1.3 Learn about helper functions¶
The helper functions are built-in in transformers library. We mainly use the following helper functions: one for converting the text examples into the feature vectors; The other one for measuring the F1 score of the predicted result.
The glue_convert_examples_to_features function converts the texts into input features:
Tokenize the input sequences;
Insert [CLS] in the beginning;
Insert [SEP] between the first sentence and the second sentence, and in the end;
Generate token type ids to indicate whether a token belongs to the first sequence or the second sequence.
The glue_compute_metrics function has the compute metrics with the F1 score, which can be interpreted as a weighted average of the precision and recall, where an F1 score reaches its best value at 1 and worst score at 0. The relative contribution of precision and recall to the F1 score are equal.
The equation for the F1 score is:
1.4 Download the dataset¶
Before running MRPC tasks we download the GLUE data by running this script
and unpack it to a directory glue_data.
python download_glue_data.py --data_dir='glue_data' --tasks='MRPC'
2. Fine-tune the BERT model¶
The spirit of BERT is to pre-train the language representations and then to fine-tune the deep bi-directional representations on a wide range of tasks with minimal task-dependent parameters, and achieves state-of-the-art results. In this tutorial, we will focus on fine-tuning with the pre-trained BERT model to classify semantically equivalent sentence pairs on MRPC task.
To fine-tune the pre-trained BERT model (bert-base-uncased model in
HuggingFace transformers) for the MRPC task, you can follow the command
in examples:
export GLUE_DIR=./glue_data
export TASK_NAME=MRPC
export OUT_DIR=./$TASK_NAME/
python ./run_glue.py \
--model_type bert \
--model_name_or_path bert-base-uncased \
--task_name $TASK_NAME \
--do_train \
--do_eval \
--do_lower_case \
--data_dir $GLUE_DIR/$TASK_NAME \
--max_seq_length 128 \
--per_gpu_eval_batch_size=8 \
--per_gpu_train_batch_size=8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--save_steps 100000 \
--output_dir $OUT_DIR
We provide the fined-tuned BERT model for MRPC task here.
To save time, you can download the model file (~400 MB) directly into your local folder $OUT_DIR.
2.1 Set global configurations¶
Here we set the global configurations for evaluating the fine-tuned BERT model before and after the dynamic quantization.
configs = Namespace()
# The output directory for the fine-tuned model, $OUT_DIR.
configs.output_dir = "./MRPC/"
# The data directory for the MRPC task in the GLUE benchmark, $GLUE_DIR/$TASK_NAME.
configs.data_dir = "./glue_data/MRPC"
# The model name or path for the pre-trained model.
configs.model_name_or_path = "bert-base-uncased"
# The maximum length of an input sequence
configs.max_seq_length = 128
# Prepare GLUE task.
configs.task_name = "MRPC".lower()
configs.processor = processors[configs.task_name]()
configs.output_mode = output_modes[configs.task_name]
configs.label_list = configs.processor.get_labels()
configs.model_type = "bert".lower()
configs.do_lower_case = True
# Set the device, batch size, topology, and caching flags.
configs.device = "cpu"
configs.per_gpu_eval_batch_size = 8
configs.n_gpu = 0
configs.local_rank = -1
configs.overwrite_cache = False
# Set random seed for reproducibility.
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
set_seed(42)
2.2 Load the fine-tuned BERT model¶
We load the tokenizer and fine-tuned BERT sequence classifier model
(FP32) from the configs.output_dir.
tokenizer = BertTokenizer.from_pretrained(
configs.output_dir, do_lower_case=configs.do_lower_case)
model = BertForSequenceClassification.from_pretrained(configs.output_dir)
model.to(configs.device)
2.3 Define the tokenize and evaluation function¶
We reuse the tokenize and evaluation function from Huggingface.
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
def evaluate(args, model, tokenizer, prefix=""):
# Loop to handle MNLI double evaluation (matched, mis-matched)
eval_task_names = ("mnli", "mnli-mm") if args.task_name == "mnli" else (args.task_name,)
eval_outputs_dirs = (args.output_dir, args.output_dir + '-MM') if args.task_name == "mnli" else (args.output_dir,)
results = {}
for eval_task, eval_output_dir in zip(eval_task_names, eval_outputs_dirs):
eval_dataset = load_and_cache_examples(args, eval_task, tokenizer, evaluate=True)
if not os.path.exists(eval_output_dir) and args.local_rank in [-1, 0]:
os.makedirs(eval_output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(eval_dataset) if args.local_rank == -1 else DistributedSampler(eval_dataset)
eval_dataloader = DataLoader(eval_dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# multi-gpu eval
if args.n_gpu > 1:
model = torch.nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(eval_dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
eval_loss = 0.0
nb_eval_steps = 0
preds = None
out_label_ids = None
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {'input_ids': batch[0],
'attention_mask': batch[1],
'labels': batch[3]}
if args.model_type != 'distilbert':
inputs['token_type_ids'] = batch[2] if args.model_type in ['bert', 'xlnet'] else None # XLM, DistilBERT and RoBERTa don't use segment_ids
outputs = model(**inputs)
tmp_eval_loss, logits = outputs[:2]
eval_loss += tmp_eval_loss.mean().item()
nb_eval_steps += 1
if preds is None:
preds = logits.detach().cpu().numpy()
out_label_ids = inputs['labels'].detach().cpu().numpy()
else:
preds = np.append(preds, logits.detach().cpu().numpy(), axis=0)
out_label_ids = np.append(out_label_ids, inputs['labels'].detach().cpu().numpy(), axis=0)
eval_loss = eval_loss / nb_eval_steps
if args.output_mode == "classification":
preds = np.argmax(preds, axis=1)
elif args.output_mode == "regression":
preds = np.squeeze(preds)
result = compute_metrics(eval_task, preds, out_label_ids)
results.update(result)
output_eval_file = os.path.join(eval_output_dir, prefix, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results {} *****".format(prefix))
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
return results
def load_and_cache_examples(args, task, tokenizer, evaluate=False):
if args.local_rank not in [-1, 0] and not evaluate:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
processor = processors[task]()
output_mode = output_modes[task]
# Load data features from cache or dataset file
cached_features_file = os.path.join(args.data_dir, 'cached_{}_{}_{}_{}'.format(
'dev' if evaluate else 'train',
list(filter(None, args.model_name_or_path.split('/'))).pop(),
str(args.max_seq_length),
str(task)))
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
logger.info("Creating features from dataset file at %s", args.data_dir)
label_list = processor.get_labels()
if task in ['mnli', 'mnli-mm'] and args.model_type in ['roberta']:
# HACK(label indices are swapped in RoBERTa pretrained model)
label_list[1], label_list[2] = label_list[2], label_list[1]
examples = processor.get_dev_examples(args.data_dir) if evaluate else processor.get_train_examples(args.data_dir)
features = convert_examples_to_features(examples,
tokenizer,
label_list=label_list,
max_length=args.max_seq_length,
output_mode=output_mode,
pad_on_left=bool(args.model_type in ['xlnet']), # pad on the left for xlnet
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=4 if args.model_type in ['xlnet'] else 0,
)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
if args.local_rank == 0 and not evaluate:
torch.distributed.barrier() # Make sure only the first process in distributed training process the dataset, and the others will use the cache
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
if output_mode == "classification":
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
elif output_mode == "regression":
all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
return dataset
3. Apply the dynamic quantization¶
We call torch.quantization.quantize_dynamic on the model to apply
the dynamic quantization on the HuggingFace BERT model. Specifically,
We specify that we want the torch.nn.Linear modules in our model to be quantized;
We specify that we want weights to be converted to quantized int8 values.
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
print(quantized_model)
3.1 Check the model size¶
Let’s first check the model size. We can observe a significant reduction in model size (FP32 total size: 438 MB; INT8 total size: 181 MB):
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
print_size_of_model(model)
print_size_of_model(quantized_model)
The BERT model used in this tutorial (bert-base-uncased) has a
vocabulary size V of 30522. With the embedding size of 768, the total
size of the word embedding table is ~ 4 (Bytes/FP32) * 30522 * 768 =
90 MB. So with the help of quantization, the model size of the
non-embedding table part is reduced from 350 MB (FP32 model) to 90 MB
(INT8 model).
3.2 Evaluate the inference accuracy and time¶
Next, let’s compare the inference time as well as the evaluation accuracy between the original FP32 model and the INT8 model after the dynamic quantization.
def time_model_evaluation(model, configs, tokenizer):
eval_start_time = time.time()
result = evaluate(configs, model, tokenizer, prefix="")
eval_end_time = time.time()
eval_duration_time = eval_end_time - eval_start_time
print(result)
print("Evaluate total time (seconds): {0:.1f}".format(eval_duration_time))
# Evaluate the original FP32 BERT model
time_model_evaluation(model, configs, tokenizer)
# Evaluate the INT8 BERT model after the dynamic quantization
time_model_evaluation(quantized_model, configs, tokenizer)
Running this locally on a MacBook Pro, without quantization, inference (for all 408 examples in MRPC dataset) takes about 160 seconds, and with quantization it takes just about 90 seconds. We summarize the results for running the quantized BERT model inference on a Macbook Pro as the follows:
| Prec | F1 score | Model Size | 1 thread | 4 threads |
| FP32 | 0.9019 | 438 MB | 160 sec | 85 sec |
| INT8 | 0.902 | 181 MB | 90 sec | 46 sec |
We have 0.6% lower F1 score accuracy after applying the post-training dynamic quantization on the fine-tuned BERT model on the MRPC task. As a comparison, in a recent paper (Table 1), it achieved 0.8788 by applying the post-training dynamic quantization and 0.8956 by applying the quantization-aware training. The main difference is that we support the asymmetric quantization in PyTorch while that paper supports the symmetric quantization only.
Note that we set the number of threads to 1 for the single-thread
comparison in this tutorial. We also support the intra-op
parallelization for these quantized INT8 operators. The users can now
set multi-thread by torch.set_num_threads(N) (N is the number of
intra-op parallelization threads). One preliminary requirement to enable
the intra-op parallelization support is to build PyTorch with the right
backend
such as OpenMP, Native or TBB.
You can use torch.__config__.parallel_info() to check the
parallelization settings. On the same MacBook Pro using PyTorch with
Native backend for parallelization, we can get about 46 seconds for
processing the evaluation of MRPC dataset.
3.3 Serialize the quantized model¶
We can serialize and save the quantized model for the future use using torch.jit.save after tracing the model.
def ids_tensor(shape, vocab_size):
# Creates a random int32 tensor of the shape within the vocab size
return torch.randint(0, vocab_size, shape=shape, dtype=torch.int, device='cpu')
input_ids = ids_tensor([8, 128], 2)
token_type_ids = ids_tensor([8, 128], 2)
attention_mask = ids_tensor([8, 128], vocab_size=2)
dummy_input = (input_ids, attention_mask, token_type_ids)
traced_model = torch.jit.trace(quantized_model, dummy_input)
torch.jit.save(traced_model, "bert_traced_eager_quant.pt")
To load the quantized model, we can use torch.jit.load
loaded_quantized_model = torch.jit.load("bert_traced_eager_quant.pt")
Conclusion¶
In this tutorial, we demonstrated how to convert a well-known state-of-the-art NLP model like BERT into dynamic quantized model. Dynamic quantization can reduce the size of the model while only having a limited implication on accuracy.
Thanks for reading! As always, we welcome any feedback, so please create an issue here if you have any.
References¶
[1] J.Devlin, M. Chang, K. Lee and K. Toutanova, BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (2018).
[3] O. Zafrir, G. Boudoukh, P. Izsak, and M. Wasserblat (2019). Q8BERT: Quantized 8bit BERT.
