⚠️ Notice: Limited Maintenance
This project is no longer actively maintained. While existing releases remain available, there are no planned updates, bug fixes, new features, or security patches. Users should be aware that vulnerabilities may not be addressed.
Enhancing LLM Serving with Torch Compiled RAG on AWS Graviton
Previously, it has been demonstrated how to deploy Llama with TorchServe. Deploying just the LLM can have limitations such as lack of up-to-date information & limited domain specific knowledge. Retrieval Augmented Generation (RAG) is a technique that can be used to enhance the accuracy and reliability of an LLM by providing the context of up-to-date, relevant information. This blog post illustrates how to implement RAG alongside LLM in a microservices-based architecture, which enhances scalability and expedites development. Additionally, by utilizing CPU-based RAG with AWS Graviton, customers can efficiently use compute resources, ultimately leading to cost savings.
Problem
Consider this simple design of a user querying a TorchServe endpoint serving Llama 3 (Llama3-8b-instruct), as shown in Figure 1. Instructions to deploy this endpoint can be found in this link. This model was deployed without quantization on NVIDIA GPU (A10Gx4) which is available as g5.12xlarge instance on AWS.
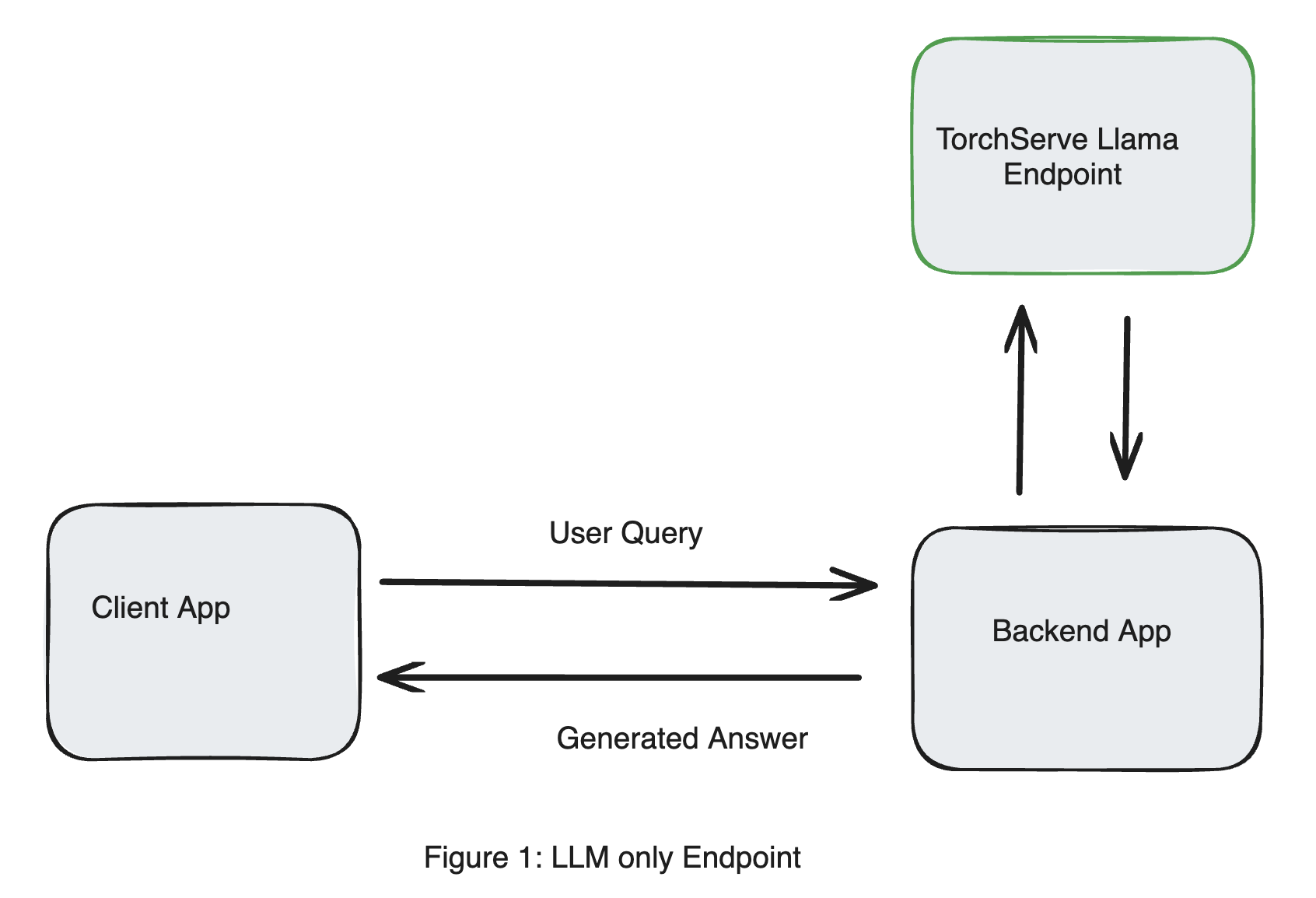
Suppose we want to find out what’s new with Llama 3, we send the following query to the TorchServe Llama endpoint.
Question: What's new with Llama 3.1?
The response returned by the model talks about a data visualization tool called Llama 3.1 and is not what we expect.
Answer: (Updated)
We've been busy bees in the Llama office, and we're excited to share the latest updates with you!
Llama 3.1 brings a bunch of new features and improvements to make your workflow even smoother and more efficient. Here are some of the highlights:
**New Features:**
1. **Customizable Columns**: You can now customize the columns in your Llama tables to fit your specific needs. This includes adding, removing, and rearranging columns, as well as setting default values for certain columns.
2. **Advanced Filtering**: Llama 3.1 introduces advanced filtering capabilities, allowing you to filter your data using a variety of conditions, such as date ranges, text matches, and more.
3. **Conditional Formatting**: You can now apply conditional formatting to your data, making it easier to visualize and analyze your results.
4. **Improved Data Import**: We've streamlined the data import process, making it easier to import data from various sources, including CSV
Retrieval Augmented Generation
Large Language Models (LLMs) such as Llama are good at performing many complex text generation tasks. However, when using LLMs for a specific domain, they do suffer from limitations such as
Outdated information: There can be advances in the domain which the model is not aware of since it was trained at an earlier date (a.k.a knowledge cutoff date).
Lack of knowledge of the specific domain: When using LLMs for a specific domain task, LLMs may give inaccurate answers since the domain specific knowledge may not be readily available.
Retrieval Augmented Generation (RAG) is a technique used to address these limitations. RAG enhances the accuracy of an LLM by augmenting the LLM with up-to-date, relevant information given the query. RAG achieves this by splitting the data sources into chunks of the specified size, indexing these chunks, & retrieving the relevant chunks based on the query. The information obtained is used as context to augment the query sent to the LLM.
LangChain is a popular framework for building LLM applications with RAG.
While LLM inference demands expensive ML accelerators, RAG endpoint can be deployed on cost-effective CPUs still meeting the use case latency requirements. Additionally, offloading the RAG endpoint to CPUs allows one to achieve microservice architecture that decouples the LLM and business infrastructure and scale them independently. In the below sections, we demonstrate how you can deploy RAG on linux-aarch64 based AWS Graviton. Further, we also show how you can get improved throughput from your RAG endpoint usingtorch.compile.There are 2 steps in a basic RAG workflow
Indexing
The context being provided in this example is a web URL. We load the content in the URL, also recursively including the child pages. The documents are split into smaller chunks for efficient processing. These chunks are encoded using an embedding model and stored in a vector database, thereby enabling efficient search and retrieval. We use torch.compile on the embedding model to speed up inference. You can read more about using torch.compile with AWS Graviton here
from bs4 import BeautifulSoup as Soup
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
import torch
# Enable AWS Graviton specific torch.compile optimizations
import torch._inductor.config as config
config.cpp.weight_prepack=True
config.freezing=True
class CustomEmbedding(HuggingFaceEmbeddings):
tokenizer: Any
def __init__(self, tokenizer: Any, **kwargs: Any):
"""Initialize the sentence_transformer."""
super().__init__(**kwargs)
# Load model from HuggingFace Hub
self.tokenizer = tokenizer
self.client = AutoModel.from_pretrained('sentence-transformers/all-mpnet-base-v2')
self.client = torch.compile(self.client)
class Config:
arbitrary_types_allowed = True
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Compute doc embeddings using a HuggingFace transformer model.
Args:
texts: The list of texts to embed.
Returns:
List of embeddings, one for each text.
"""
import sentence_transformers
texts = list(map(lambda x: x.replace("\n", " "), texts))
# Tokenize sentences
encoded_input = self.tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
embeddings = self.client(
**encoded_input
)
embeddings = embeddings.pooler_output.detach().numpy()
return embeddings.tolist()
# 1. Load the url and its child pages
url="https://huggingface.co/blog/llama3"
loader = RecursiveUrlLoader(
url=url, max_depth=3, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# 2. Split the document into chunks with a specified chunk size
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
all_splits = text_splitter.split_documents(docs)
# 3. Store the document into a vector store with a specific embedding model
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-mpnet-base-v2')
model = CustomEmbedding(tokenizer)
vectorstore = FAISS.from_documents(all_splits, model)
Retrieval
For every query sent by the user , we do a similarity search for the query in the vector database and get the N (here N=5) closest chunks of documents.
docs = vectorstore.similarity_search(query, k=5)
Prompt Engineering
Typical implementations of RAG with LLM , use langchain to chain RAG and LLM pipeline and call an invoke method on the chain with the query.
The published example of Llama endpoint with TorchServe expects a text prompt as the input and uses HuggingFace APIs to process the query. To make the RAG design compatible, we need to return a text prompt from the RAG endpoint.
This section describes how we can engineer the prompt that the Llama endpoint expects, including the relevant context. Under the hood, LangChain has a PromptTemplate for Llama . By executing the code above with the following debug statements, we can determine the prompt being sent to Llama.
import langchain
langchain.debug = True
We extract the text from the docs returned in the retrieval section and prompt engineer the final prompt to Llama as follows
from langchain.prompts import PromptTemplate
from langchain_core.prompts import format_document
question="What's new with Llama 3?"
doc_prompt = PromptTemplate.from_template("{page_content}")
context = ""
for doc in docs:
context += f"\n{format_document(doc, doc_prompt)}\n"
prompt = f"Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer."\
f"\n\n{context}\n\nQuestion: {question}"\
f"\nHelpful Answer:"
AWS Graviton specific optimizations
To take advantage of the performance optimizations on AWS Graviton for RAG, we can set the following optimizations; details on the optimizations are mentioned in this blog . There is also a tutorial which talks about these optimizations
export TORCH_MKLDNN_MATMUL_MIN_DIM=1024
export LRU_CACHE_CAPACITY=1024
export THP_MEM_ALLOC_ENABLE=1
export DNNL_DEFAULT_FPMATH_MODE=BF16
To accurately measure the performance gain using torch.compile compared to PyTorch eager, we also set
export OMP_NUM_THREADS=1
Deploying RAG
Although TorchServe provides Multi-Model Endpoint support on the same compute instance, we deploy the RAG endpoint on AWS Graviton. Since the computations for RAG are not that compute intensive, we can use a CPU instance for deployment to provide a cost effective solution.
To deploy RAG with TorchServe, we need the following:
requirements.txt
langchain
Langchain_community
sentence-transformers
faiss-cpu
bs4
This can be used along with install_py_dep_per_model=true in config.properties to dynamically install the required libraries
rag-config.yaml
We pass the parameters used for indexing and retrieval in rag-config.yaml which is used to create the MAR file. By making these parameters configurable, we can have multiple RAG endpoints for different tasks by using different yaml files.
# TorchServe frontend parameters
minWorkers: 1
maxWorkers: 1
responseTimeout: 120
handler:
url_to_scrape: "https://huggingface.co/blog/llama3"
chunk_size: 1000
chunk_overlap: 0
model_path: "model/models--sentence-transformers--all-mpnet-base-v2/snapshots/84f2bcc00d77236f9e89c8a360a00fb1139bf47d"
rag_handler.py
We define a handler file with a class which derives from the BaseHandler. This class needs to define four methods: initialize, preprocess, inference and postprocess. The indexing portion is defined in the initialize method. The retrieval portion is in the inference method and the prompt engineering portion in the postprocess method. We use the timed function to determine the time taken to process each of these methods.
import torch
import transformers
from bs4 import BeautifulSoup as Soup
from hf_custom_embeddings import CustomEmbedding
from langchain.prompts import PromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import format_document
from ts.torch_handler.base_handler import BaseHandler
class RAGHandler(BaseHandler):
"""
RAG handler class retrieving documents from a url, encoding & storing in a vector database.
For a given query, it returns the closest matching documents.
"""
def __init__(self):
super(RAGHandler, self).__init__()
self.vectorstore = None
self.initialized = False
self.N = 5
@torch.inference_mode
def initialize(self, ctx):
url = ctx.model_yaml_config["handler"]["url_to_scrape"]
chunk_size = ctx.model_yaml_config["handler"]["chunk_size"]
chunk_overlap = ctx.model_yaml_config["handler"]["chunk_overlap"]
model_path = ctx.model_yaml_config["handler"]["model_path"]
loader = RecursiveUrlLoader(
url=url, max_depth=3, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# Split the document into chunks with a specified chunk size
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
all_splits = text_splitter.split_documents(docs)
# Store the document into a vector store with a specific embedding model
self.vectorstore = FAISS.from_documents(
all_splits, CustomEmbedding(model_path=model_path)
)
def preprocess(self, requests):
assert len(requests) == 1, "Expecting batch_size = 1"
inputs = []
for request in requests:
input_text = request.get("data") or request.get("body")
if isinstance(input_text, (bytes, bytearray)):
input_text = input_text.decode("utf-8")
inputs.append(input_text)
return inputs[0]
@torch.inference_mode
def inference(self, data, *args, **kwargs):
searchDocs = self.vectorstore.similarity_search(data, k=self.N)
return (searchDocs, data)
def postprocess(self, data):
docs, question = data[0], data[1]
doc_prompt = PromptTemplate.from_template("{page_content}")
context = ""
for doc in docs:
context += f"\n{format_document(doc, doc_prompt)}\n"
prompt = (
f"Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer."
f"\n\n{context}\n\nQuestion: {question}"
f"\nHelpful Answer:"
)
return [prompt]
Benchmarking Performance
We use ab tool to measure the performance of the RAG endpoint
python benchmarks/auto_benchmark.py --input /home/ubuntu/serve/examples/usecases/RAG_based_LLM_serving
benchmark_profile.yaml --skip true
We repeat the runs with combinations of OMP_NUM_THREADS and PyTorch Eager/ torch.compile
Results
We observe the following throughput on the AWS EC2 m7g.4xlarge instance

We observe that using torch.compile improves the RAG endpoint throughput by 35%. The scale of the throughput (Eager or Compile) shows that deploying RAG on a CPU device is practical for use with a LLM deployed on a GPU instance. The RAG endpoint is not going to be a bottleneck in an LLM deployment,
RAG + LLM Deployment
The system architecture for the end-to-end solution using RAG based LLM serving is shown in Figure 2.
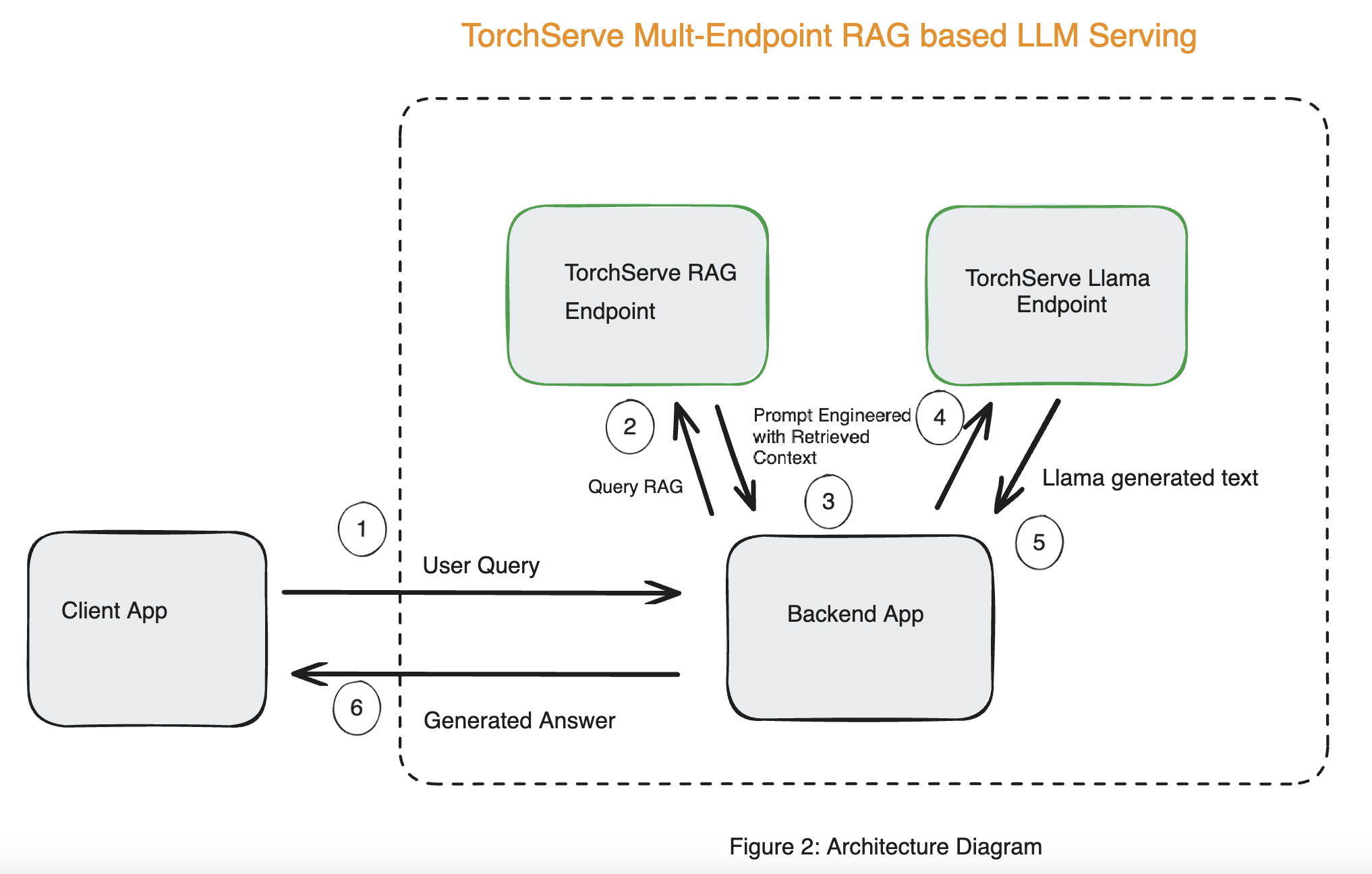
The steps for full deployment are mentioned in Deployment Guide
The code snippet which can chain the RAG endpoint with Llama endpoint is shown below
import requests
prompt="What's new with Llama 3.1?"
RAG_EP = "http://<RAG Endpoint IP Address>:8080/predictions/rag"
LLAMA_EP = "http://<LLAMA Endpoint IP Address>:8080/predictions/llama3-8b-instruct"
# Get response from RAG
response = requests.post(url=RAG_EP, data=prompt)
# Get response from Llama
response = requests.post(url=LLAMA_EP, data=response.text.encode('utf-8'))
print(f"Question: {prompt}")
print(f"Answer: {response.text}")
Sample Outputs
Question: What's new with Llama 3.1?
Answer: Llama 3.1 has a large context length of 128K tokens, multilingual capabilities, tool usage capabilities, a very large dense model of 405 billion parameters, and a more permissive license. It also introduces six new open LLM models based on the Llama 3 architecture, and continues to use Grouped-Query Attention (GQA) for efficient representation. The new tokenizer expands the vocabulary size to 128,256, and the 8B version of the model now uses GQA. The license allows using model outputs to improve other LLMs.
Question: What's new with Llama 2?
Answer: There is no mention of Llama 2 in the provided context. The text only discusses Llama 3.1 and its features. Therefore, it is not possible to determine what is new with Llama 2. I don't know.
Conclusion
In this blog, we show how to deploy a RAG Endpoint using TorchServe, increase throughput using torch.compile and improve the response generated by the Llama Endpoint. Using the architecture described in Figure 2, we can reduce hallucinations of the LLM.
We also show how the RAG endpoint can be deployed on CPU using AWS Graviton, while the Llama endpoint is still deployed on a GPU. This kind of microservices-based RAG solution efficiently utilizes compute resources, resulting in potential cost savings for customers.
