⚠️ Notice: Limited Maintenance
This project is no longer actively maintained. While existing releases remain available, there are no planned updates, bug fixes, new features, or security patches. Users should be aware that vulnerabilities may not be addressed.
Serving large models with Torchserve
This document explain how Torchserve supports large model serving, here large model refers to the models that are not able to fit into one gpu so they need be split in multiple partitions over multiple gpus. This page is split into the following sections:
How it works?
For GPU inference of smaller models TorchServe executes a single process per worker which gets assigned a single GPU.
For large model inference the model needs to be split over multiple GPUs.
There are different modes to achieve this split which usually include pipeline parallel (PP), tensor parallel or a combination of these.
Which mode is selected and how the split is implemented depends on the implementation in the utilized framework.
TorchServe allows users to utilize any framework for their model deployment and tries to accommodate the needs of the frameworks through flexible configurations.
Some frameworks require to execute a separate process for each of the GPUs (PiPPy, Deep Speed) while others require a single process which get assigned all GPUs (vLLM).
In case multiple processes are required TorchServe utilizes torchrun to set up the distributed environment for the worker.
During the setup torchrun will start a new process for each GPU assigned to the worker.
If torchrun is utilized or not depends on the parameter parallelType which can be set in the model-config.yaml to one of the following options:
pp- for pipeline paralleltp- for tensor parallelpptp- for pipeline + tensor parallelcustom
The first three options setup the environment using torchrun while the “custom” option leaves the way of parallelization to the user and assigned the GPUs assigned to a worker to a single process. The number of assigned GPUs is determined either by the number of processes started by torchrun i.e. configured through nproc-per-node OR the parameter parallelLevel. Meaning that the parameter parallelLevel should NOT be set if nproc-per-node is set and vice versa.
By default, TorchServe uses a round-robin algorithm to assign GPUs to a worker on a host. In case of large models inference GPUs assigned to each worker is automatically calculated based on the number of GPUs specified in the model_config.yaml. CUDA_VISIBLE_DEVICES is set based this number.
For instance, suppose there are eight GPUs on a node and one worker needs 4 GPUs (ie, nproc-per-node=4 OR parallelLevel=4) on a node. In this case, TorchServe would assign CUDA_VISIBLE_DEVICES=”0,1,2,3” to worker1 and CUDA_VISIBLE_DEVICES=”4,5,6,7” to worker2.
In addition to this default behavior, TorchServe provides the flexibility for users to specify GPUs for a worker. For instance, if the user sets “deviceIds: [2,3,4,5]” in the model config YAML file, and nproc-per-node (OR parallelLevel) is set to 2, then TorchServe would assign CUDA_VISIBLE_DEVICES=”2,3” to worker1 and CUDA_VISIBLE_DEVICES=”4,5” to worker2.
Using Pippy integration as an example, the image below illustrates the internals of the TorchServe large model inference. For an example using vLLM see this example.
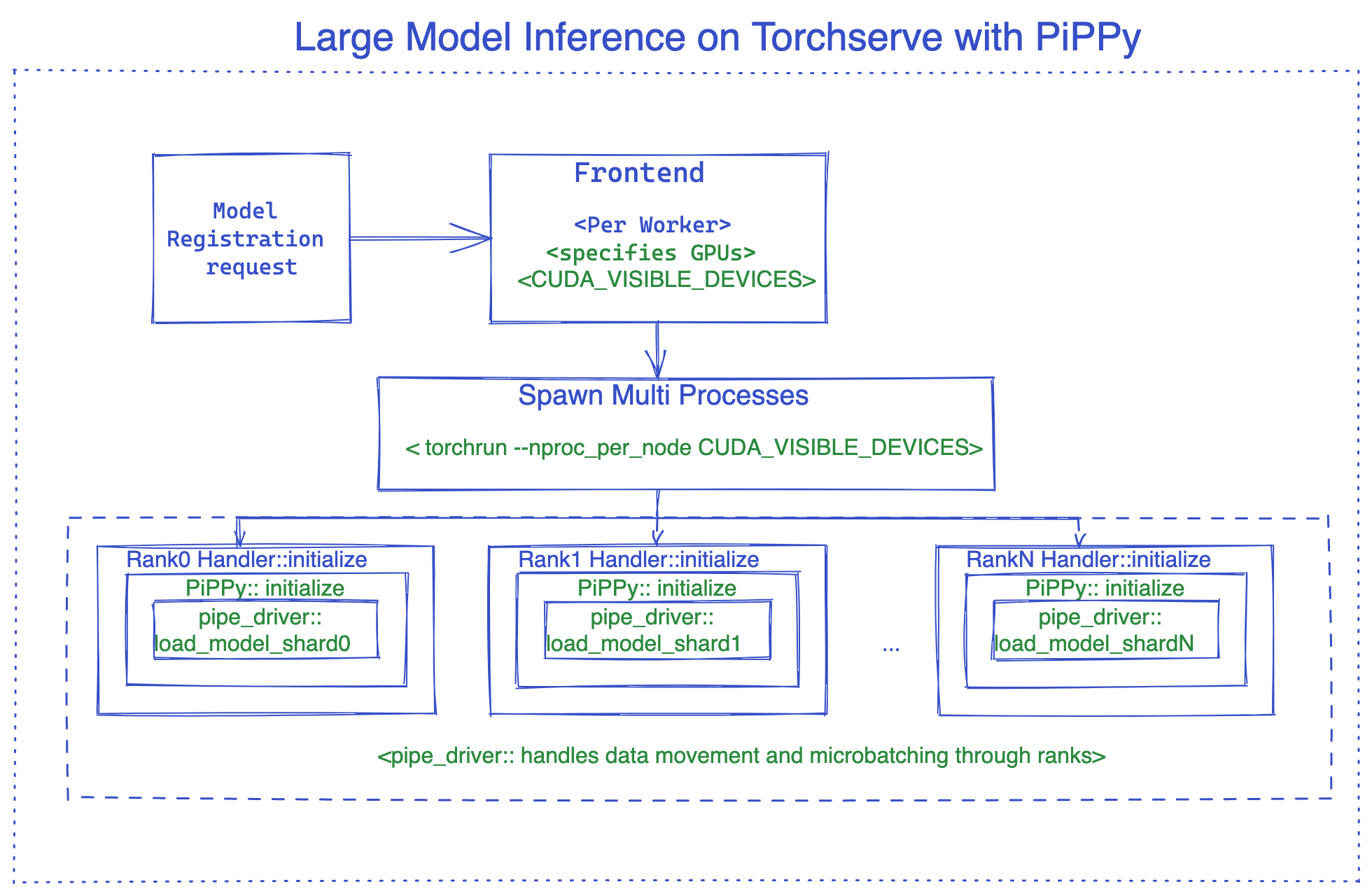
PiPPy (PyTorch Native solution for large model inference)
PiPPy provides pipeline parallelism for serving large models that would not fit into one gpu. It takes your model and splits it into equal sizes (stages) partitioned over the number devices you specify. Then uses microbatching to run your batched input for inference ( its is more optimal for batch sizes >1).
How to use PiPPy in Torchserve
To use Pippy in Torchserve, we need to use a custom handler which inherits from base_pippy_handler and put our setting in model-config.yaml.
Customer handler in Torchserve is simply a python script that defines model loading, preprocess, inference and postprocess logic specific to your workflow.
It would look like below:
Create custom_handler.py or any other descriptive name.
#DO import the necessary packages along with following
from ts.torch_handler.distributed.base_pippy_handler import BasePippyHandler
from ts.handler_utils.distributed.pt_pippy import initialize_rpc_workers, get_pipline_driver
class ModelHandler(BasePippyHandler, ABC):
def __init__(self):
super(ModelHandler, self).__init__()
self.initialized = False
def initialize(self, ctx):
model = # load your model from model_dir
self.device = self.local_rank % torch.cuda.device_count()# being used to move model inputs to (self.device)
self.model = get_pipline_driver(model,self.world_size, ctx)
Here is what your model-config.yaml needs, this config file is very flexible, you can add setting related to frontend, backend and handler.
#frontend settings
minWorkers: 1
maxWorkers: 1
maxBatchDelay: 100
responseTimeout: 120
deviceType: "gpu"
parallelType: "pp" # options depending on the solution, pp(pipeline parallelism), tp(tensor parallelism), pptp ( pipeline and tensor parallelism)
# This will be used to route input to either rank0 or all ranks from fontend based on the solution (e.g. DeepSpeed support tp, PiPPy support pp)
torchrun:
nproc-per-node: 4 # specifies the number of processes torchrun starts to serve your model, set to world_size or number of
# gpus you wish to split your model
#backend settings
pippy:
chunks: 1 # This sets the microbatch sizes, microbatch = batch size/ chunks
input_names: ['input_ids'] # input arg names to the model, this is required for FX tracing
model_type: "HF" # set the model type to HF if you are using Huggingface model other wise leave it blank or any other model you use.
rpc_timeout: 1800
num_worker_threads: 512 #set number of threads for rpc worker init.
handler:
max_length: 80 # max length of tokens for tokenizer in the handler
How to access it in the handler? here is an example:
def initialize(self, ctx):
model_type = ctx.model_yaml_config["pippy"]["model_type"]
The rest is as usual in Torchserve, basically packaging your model and starting the server.
Example of the command for packaging your model, make sure you pass model-config.yaml
torch-model-archiver --model-name bloom --version 1.0 --handler pippy_handler.py --extra-files $MODEL_CHECKPOINTS_PATH -r requirements.txt --config-file model-config.yaml --archive-format tgz
Tensor Parallel support in progress and will be added as soon as ready.
DeepSpeed
DeepSpeed-Inference is an open source project of MicroSoft. It provides model parallelism for serving large transformer based PyTorch models that would not fit into one gpu memory.
How to use DeepSpeed in TorchServe
To use DeepSpeed in TorchServe, we need to use a custom handler which inherits from base_deepspeed_handler and put our setting in model-config.yaml.
It would look like below:
Create custom_handler.py or any other descriptive name.
#DO import the necessary packages along with following
from ts.handler_utils.distributed.deepspeed import get_ds_engine
from ts.torch_handler.distributed.base_deepspeed_handler import BaseDeepSpeedHandler
class ModelHandler(BaseDeepSpeedHandler, ABC):
def __init__(self):
super(ModelHandler, self).__init__()
self.initialized = False
def initialize(self, ctx):
model = # load your model from model_dir
ds_engine = get_ds_engine(self.model, ctx)
self.model = ds_engine.module
self.initialized = True
Here is what your model-config.yaml needs, this config file is very flexible, you can add setting related to frontend, backend and handler.
#frontend settings
minWorkers: 1
maxWorkers: 1
maxBatchDelay: 100
responseTimeout: 120
deviceType: "gpu"
parallelType: "tp" # options depending on the solution, pp(pipeline parallelism), tp(tensor parallelism), pptp ( pipeline and tensor parallelism)
# This will be used to route input to either rank0 or all ranks from fontend based on the solution (e.g. DeepSpeed support tp, PiPPy support pp)
torchrun:
nproc-per-node: 4 # specifies the number of processes torchrun starts to serve your model, set to world_size or number of
# gpus you wish to split your model
#backend settings
deepspeed:
config: ds-config.json # DeepSpeed config json filename.
# Details:https://www.deepspeed.ai/docs/config-json/
handler:
max_length: 80 # max length of tokens for tokenizer in the handler
Here is an example of ds-config.json
{
"dtype": "torch.float16",
"replace_with_kernel_inject": true,
"tensor_parallel": {
"tp_size": 2
}
}
Install DeepSpeed
Method1: requirements.txt
Method2: pre-install via command (Recommended to speed up model loading)
# See https://www.deepspeed.ai/tutorials/advanced-install/
DS_BUILD_OPS=1 pip install deepspeed
The rest is as usual in Torchserve, basically packaging your model and starting the server.
Example of the command for packaging your model, make sure you pass model-config.yaml
# option 1: Using model_dir
torch-model-archiver --model-name bloom --version 1.0 --handler deepspeed_handler.py --extra-files $MODEL_CHECKPOINTS_PATH,ds-config.json -r requirements.txt --config-file model-config.yaml --archive-format tgz
# option 2: Using HF model_name
torch-model-archiver --model-name bloom --version 1.0 --handler deepspeed_handler.py --extra-files ds-config.json -r requirements.txt --config-file model-config.yaml --archive-format
DeepSpeed MII
If working with one of the supported models shown here you can take advantage of Deep Speed MII. Deep Speed MII uses Deep Speed Inference along with further advances in deep learning to minimize latency and maximize throughput. It does this for specific model types, model sizes, batch sizes and available hardware resources.
For more information on how to take advantage of Deep Speed MII on supported models, see the information here. You can also find an example of how to apply this to TorchServe here.
Serving Large Hugging Face Models Using Accelerate
If working with large Hugging Face models but have limited resources, you can use accelerate to serve these models. To achieve this, you would need to set low_cpu_mem_usage=True and set the `device_map=”auto” in the setup_config.json file.
For more information on using accelerate with large Hugging Face models, see this example.
Large Model Inference Tips
Reducing model loading latency
To reduce model latency we recommend:
Pre-installing the model parallel library such as Deepspeed on the container or host.
Pre-downloading the model checkpoints. For example, if using HuggingFace, a pretrained model can be pre-downloaded via Download_model.py
Set environment variable HUGGINGFACE_HUB_CACHE and TRANSFORMERS_CACHE
Download model to the HuggingFace cache dir via tool Download_model.py
Tune model config YAML file
You can tune the model config YAML file to get better performance in the following ways:
Update the responseTimeout if high model inference latency causes response timeout.
Update the startupTimeout if high model loading latency causes startup timeout.
Tune the torchrun parameters. The supported parameters are defined at here. For example, by default,
OMP_NUMBER_THREADSis 1. This can be modified in the YAML file.
#frontend settings
torchrun:
nproc-per-node: 4 # specifies the number of processes torchrun starts to serve your model, set to world_size or number of
# gpus you wish to split your model
OMP_NUMBER_THREADS: 2
Latency Sensitive Applications
Job Ticket
The job ticket feature is recommended for the use case of latency sensitive inference. When job ticket is enabled, TorchServe verifies the availability of a model’s active worker for processing a client’s request. If an active worker is available, the request is accepted and processed immediately without the waiting time incurred from the job queue or dynamic batching; otherwise, a 503 response is sent back to the client.
This feature helps with use cases where inference latency can be high, such as generative models, auto regressive decoder models like chatGPT. This feature helps such applications take effective actions, for example, routing the rejected request to a different server, or scaling up model server capacity, based on the business requirements. Here is an example of enabling job ticket.
minWorkers: 2
maxWorkers: 2
jobQueueSize: 2
useJobTicket: true
In this example, a model has 2 workers with job queue size 2. An inference request will be either processed by TorchServe immediately, or rejected with response code 503.
Streaming response via HTTP 1.1 chunked encoding
TorchServe’s inference API supports streaming response to allow a sequence of inference responses to be sent over HTTP 1.1 chunked encoding. This feature is only recommended for the use case when the inference latency of the full response is high and the inference intermediate results are sent to the client. An example could be LLMs for generative applications, where generating “n” number of tokens can have high latency. In this case, the user can receive each generated token once ready until the full response completes. To achieve streaming response, the backend handler calls “send_intermediate_predict_response” to send one intermediate result to the frontend, and returns the last result as the existing style. For example,
from ts.handler_utils.utils import send_intermediate_predict_response
''' Note: TorchServe v1.0.0 will deprecate
"from ts.protocol.otf_message_handler import send_intermediate_predict_response".
Please replace it with "from ts.handler_utils.utils import send_intermediate_predict_response".
'''
def handle(data, context):
if type(data) is list:
for i in range (3):
send_intermediate_predict_response(["intermediate_response"], context.request_ids, "Intermediate Prediction success", 200, context)
return ["hello world "]
Client side receives the chunked data.
import test_utils
def test_echo_stream_inference():
test_utils.start_torchserve(no_config_snapshots=True, gen_mar=False)
test_utils.register_model('echo_stream',
'https://torchserve.pytorch.org/mar_files/echo_stream.mar')
response = requests.post(TF_INFERENCE_API + '/predictions/echo_stream', data="foo", stream=True)
assert response.headers['Transfer-Encoding'] == 'chunked'
prediction = []
for chunk in (response.iter_content(chunk_size=None)):
if chunk:
prediction.append(chunk.decode("utf-8"))
assert str(" ".join(prediction)) == "hello hello hello hello world "
test_utils.unregister_model('echo_stream')
GRPC Server Side Streaming
TorchServe GRPC API adds server side streaming of the inference API “StreamPredictions” to allow a sequence of inference responses to be sent over the same GRPC stream. This API is only recommended for use case when the inference latency of the full response is high and the inference intermediate results are sent to the client. An example could be LLMs for generative applications, where generating “n” number of tokens can have high latency. Similar to the HTTP 1.1 chunked encoding, with this feature the user can receive each generated token once ready until the full response completes. This API automatically forces the batchSize to be one.
service InferenceAPIsService {
// Check health status of the TorchServe server.
rpc Ping(google.protobuf.Empty) returns (TorchServeHealthResponse) {}
// Predictions entry point to get inference using default model version.
rpc Predictions(PredictionsRequest) returns (PredictionResponse) {}
// Streaming response for an inference request.
rpc StreamPredictions(PredictionsRequest) returns (stream PredictionResponse) {}
}
Backend handler calls “send_intermediate_predict_response” to send one intermediate result to frontend, and return the last result as the existing style. For example
from ts.handler_utils.utils import send_intermediate_predict_response
''' Note: TorchServe v1.0.0 will deprecate
"from ts.protocol.otf_message_handler import send_intermediate_predict_response".
Please replace it with "from ts.handler_utils.utils import send_intermediate_predict_response".
'''
def handle(data, context):
if type(data) is list:
for i in range (3):
send_intermediate_predict_response(["intermediate_response"], context.request_ids, "Intermediate Prediction success", 200, context)
return ["hello world "]
