⚠️ Notice: Limited Maintenance
This project is no longer actively maintained. While existing releases remain available, there are no planned updates, bug fixes, new features, or security patches. Users should be aware that vulnerabilities may not be addressed.
Running TorchServe with NVIDIA MPS
In order to deploy ML models, TorchServe spins up each worker in a separate processes, thus isolating each worker from the others. Each process creates its own CUDA context to execute its kernels and access the allocated memory.
While NVIDIA GPUs in their default setting allow multiple processes to run CUDA kernels on a single device it involves the following drawback:
The execution of the kernels is generally serialized
Each processes creates its own CUDA context which occupies additional GPU memory
For these scenarios NVIDIA offers the Multi-Process Service (MPS) which:
Allows multiple processes to share the same CUDA context on the same GPU
Run their kernels in a parallel fashion
This can result in:
Increased performance when using multiple workers on the same GPU
Decreased GPU memory utilization due to the shared context
To leverage the benefits of NVIDIA MPS we need to start the MPS daemon with the following commands before starting up TorchServe itself.
sudo nvidia-smi -c 3
nvidia-cuda-mps-control -d
The first command enables the exclusive processing mode for the GPU allowing only one process (the MPS daemon) to utilize it. The second command starts the MPS daemon itself. To shutdown the daemon we can execute:
echo quit | nvidia-cuda-mps-control
For more details on MPS please refer to NVIDIA’s MPS documentation. It should be noted that MPS only allows 48 processes (for Volta GPUs) to connect to the daemon due limited hardware resources. Adding more clients/workers (to the same GPU) will lead to a failure.
Benchmarks
To show the performance of TorchServe with activated MPS and help to the decision in enabling MPS for your deployment or not we will perform some benchmarks with representative workloads.
Primarily, we want to investigate how the throughput of a worker evolves with activated MPS for different operation points. As an example work load for our benchmark we select the HuggingFace Transformers Sequence Classification example. We perform the benchmark on a g4dn.4xlarge as well as a p3.2xlarge instance on AWS. Both instance types provide one GPU per instance which will result in multiple workers to be scheduled on the same GPU. For the benchmark we concentrate on the model throughput as measured by the benchmark-ab.py tool.
First, we measure the throughput of a single worker for different batch sizes as it will show us at which point the compute resources of the GPU are fully occupied. Second, we measure the throughput with two deployed workers for the batch sizes where we expect the GPUs to have still some resources left over to share. For each benchmark we perform five runs and take the median over the runs.
We use the following config.json for the benchmark, only overwriting the number of workers and the batch size accordingly.
{
"url":"/home/ubuntu/serve/examples/Huggingface_Transformers/model_store/BERTSeqClassification",
"requests": 10000,
"concurrency": 600,
"input": "/home/ubuntu/serve/examples/Huggingface_Transformers/Seq_classification_artifacts/sample_text_captum_input.txt",
"workers": "1"
}
Please note that we set the concurrency level to 600 which will make sure that the batch aggregation inside TorchServe fills up the batches to the maximum batch size. But concurrently this will skew the latency measurements as many requests will be waiting in the queue to be processed. We will therefore neglect the latency measurements in the following.
G4 Instance
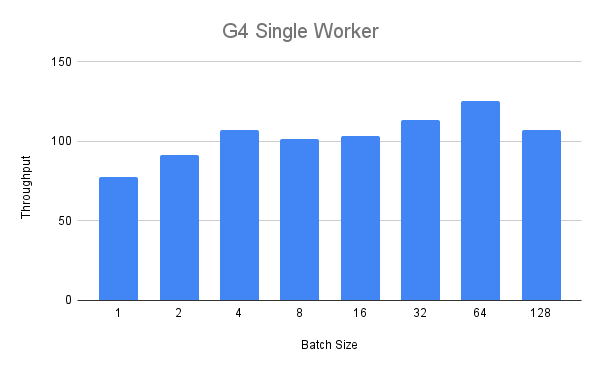
We first perform the single worker benchmark for the G4 instance. In the figure below we see that up to a batch size of four we see a steady increase of the throughput over the batch size.
Next, we increase the number of workers to two in order to compare the throughput with and without MPS running. To enable MPS for the second set of runs we first set the exclusive processing mode for the GPU and then start the MPS daemon as shown above.
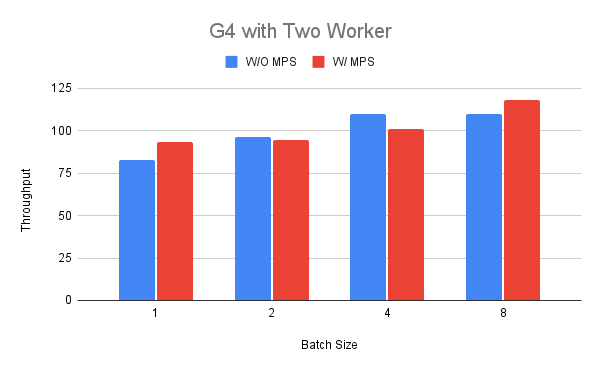
We select the batch size between one and eight according to our previous findings. In the figure we can see that the performance in terms of throughput can be better in case of batch size 1 and 8 (up to +18%) while it can be worse for others (-11%). An interpretation of this result could be that the G4 instance has not many resources to share when we run a BERT model in one of the workers.
P3 instance
Next, we will run the same experiment with the bigger p3.2xlarge instance. With a single worker we get the following throughput values:
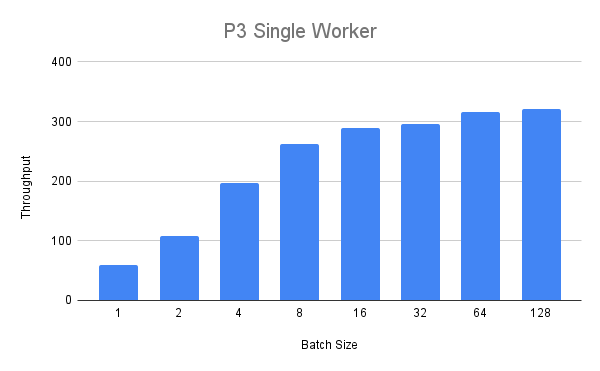
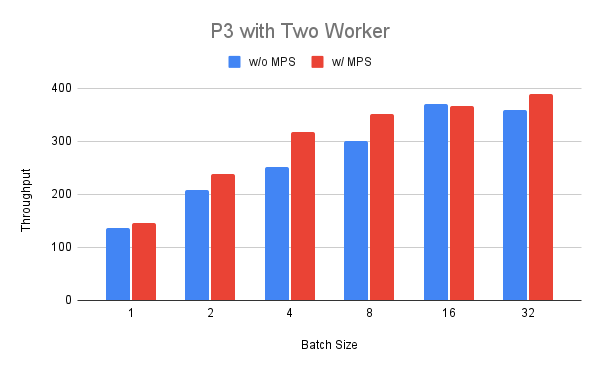
We can see that the throughput steady increases but for a batch size over eight we see diminishing returns. Finally, we deploy two workers on the P3 instance and compare running them with and without MPS. We can see that for batch size between 1 and 32 the throughput is consistently higher (up to +25%) for MPS enabled with the exception of batch size 16.
Summary
In the previous section we saw that by enabling MPS for two workers running the same model we receive mixed results. For the smaller G4 instance we only saw benefits in certain operation points while we saw more consistent improvements for the bigger P3 instance. This suggests that the benefit in terms of throughput for running a deployment with MPS are highly workload and environment dependent and need to be determined for specific situations using appropriate benchmarks and tools. It should be noted that the previous benchmark solely focused on throughput and neglected latency and memory footprint. As using MPS will only create a single CUDA context more workers can be packed to the same GPU which needs to be considered as well in the according scenarios.
