Note
Go to the end to download the full example code
Torch Export with Cudagraphs
CUDA Graphs allow multiple GPU operations to be launched through a single CPU operation, reducing launch overheads and improving GPU utilization. Torch-TensorRT provides a simple interface to enable CUDA graphs. This feature allows users to easily leverage the performance benefits of CUDA graphs without managing the complexities of capture and replay manually.
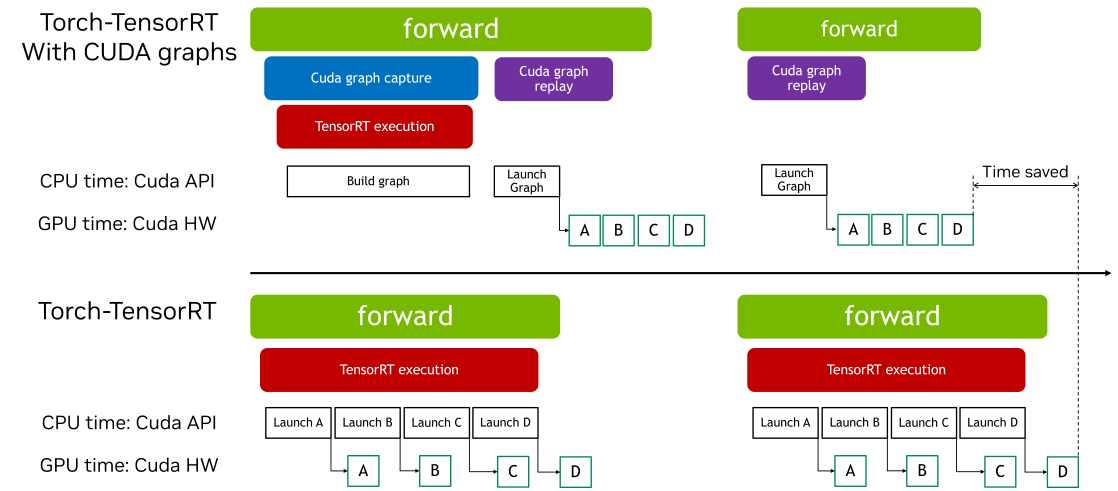
This interactive script is intended as an overview of the process by which the Torch-TensorRT Cudagraphs integration can be used in the ir=”dynamo” path. The functionality works similarly in the torch.compile path as well.
Imports and Model Definition
import torch
import torch_tensorrt
import torchvision.models as models
Compilation with torch_tensorrt.compile Using Default Settings
# We begin by defining and initializing a model
model = models.resnet18(pretrained=True).eval().to("cuda")
# Define sample inputs
inputs = torch.randn((16, 3, 224, 224)).cuda()
# Next, we compile the model using torch_tensorrt.compile
# We use the `ir="dynamo"` flag here, and `ir="torch_compile"` should
# work with cudagraphs as well.
opt = torch_tensorrt.compile(
model,
ir="dynamo",
inputs=torch_tensorrt.Input(
min_shape=(1, 3, 224, 224),
opt_shape=(8, 3, 224, 224),
max_shape=(16, 3, 224, 224),
dtype=torch.float,
name="x",
),
)
Inference using the Cudagraphs Integration
# We can enable the cudagraphs API with a context manager
with torch_tensorrt.runtime.enable_cudagraphs(opt) as cudagraphs_module:
out_trt = cudagraphs_module(inputs)
# Alternatively, we can set the cudagraphs mode for the session
torch_tensorrt.runtime.set_cudagraphs_mode(True)
out_trt = opt(inputs)
# We can also turn off cudagraphs mode and perform inference as normal
torch_tensorrt.runtime.set_cudagraphs_mode(False)
out_trt = opt(inputs)
# If we provide new input shapes, cudagraphs will re-record the graph
inputs_2 = torch.randn((8, 3, 224, 224)).cuda()
inputs_3 = torch.randn((4, 3, 224, 224)).cuda()
with torch_tensorrt.runtime.enable_cudagraphs(opt) as cudagraphs_module:
out_trt_2 = cudagraphs_module(inputs_2)
out_trt_3 = cudagraphs_module(inputs_3)
Cuda graphs with module that contains graph breaks
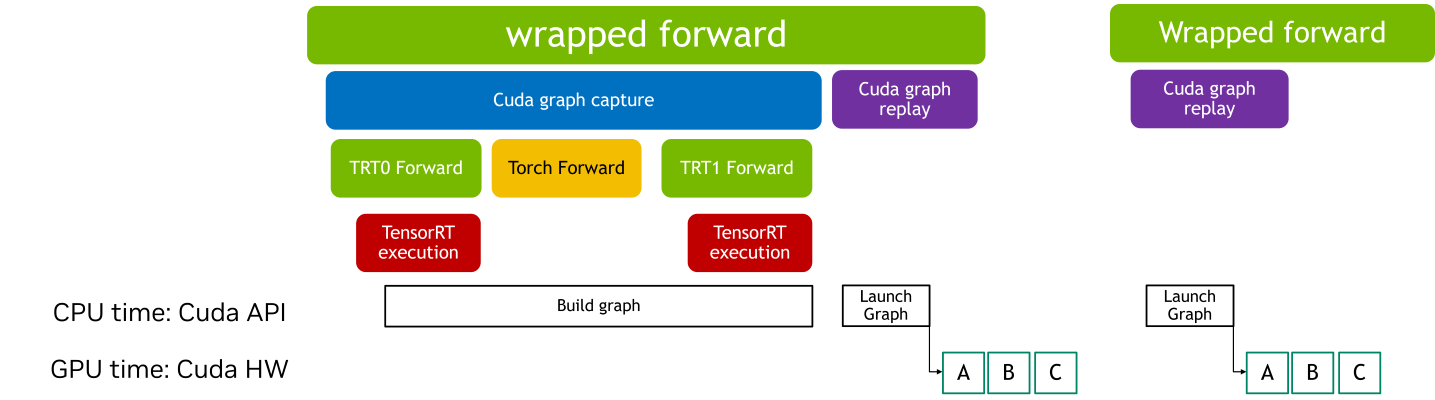
When CUDA Graphs are applied to a TensorRT model that contains graph breaks, each break introduces additional overhead. This occurs because graph breaks prevent the entire model from being executed as a single, continuous optimized unit. As a result, some of the performance benefits typically provided by CUDA Graphs, such as reduced kernel launch overhead and improved execution efficiency, may be diminished.
Using a wrapped runtime module with CUDA Graphs allows you to encapsulate sequences of operations into graphs that can be executed efficiently, even in the presence of graph breaks. If TensorRT module has graph breaks, CUDA Graph context manager returns a wrapped_module. And this module captures entire execution graph, enabling efficient replay during subsequent inferences by reducing kernel launch overheads and improving performance.
Note that initializing with the wrapper module involves a warm-up phase where the module is executed several times. This warm-up ensures that memory allocations and initializations are not recorded in CUDA Graphs, which helps maintain consistent execution paths and optimize performance.
class SampleModel(torch.nn.Module):
def forward(self, x):
return torch.relu((x + 2) * 0.5)
model = SampleModel().eval().cuda()
input = torch.randn((1, 3, 224, 224)).to("cuda")
# The 'torch_executed_ops' compiler option is used in this example to intentionally introduce graph breaks within the module.
# Note: The Dynamo backend is required for the CUDA Graph context manager to handle modules in an Ahead-Of-Time (AOT) manner.
opt_with_graph_break = torch_tensorrt.compile(
model,
ir="dynamo",
inputs=[input],
min_block_size=1,
pass_through_build_failures=True,
torch_executed_ops={"torch.ops.aten.mul.Tensor"},
)
If module has graph breaks, whole submodules are recorded and replayed by cuda graphs
with torch_tensorrt.runtime.enable_cudagraphs(
opt_with_graph_break
) as cudagraphs_module:
cudagraphs_module(input)
Total running time of the script: ( 0 minutes 0.000 seconds)
