PyTorch/XLA SPMD User Guide¶
In this user guide, we discuss how GSPMD is integrated in PyTorch/XLA, and provide a design overview to illustrate how the SPMD sharding annotation API and its constructs work.
What is PyTorch/XLA SPMD?¶
GSPMD is an automatic parallelization system for common ML workloads. The XLA compiler will transform the single device program into a partitioned one with proper collectives, based on the user provided sharding hints. This feature allows developers to write PyTorch programs as if they are on a single large device without any custom sharded computation ops and/or collective communications to scale.
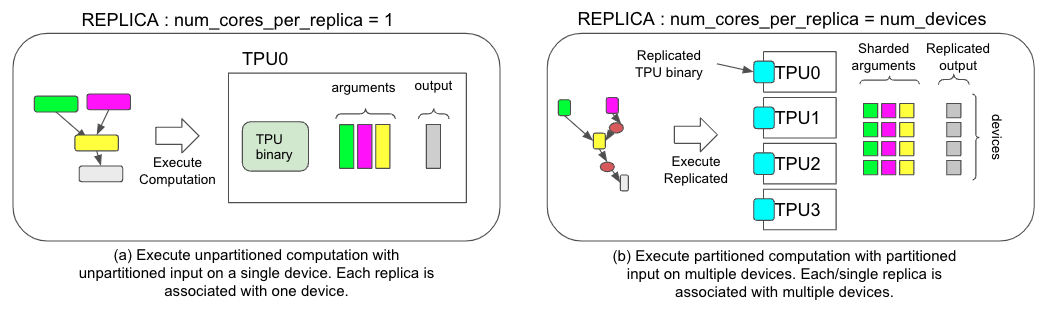
*Figure 1. Comparison of two different execution strategies, (a) for non-SPMD and (b) for SPMD.*
How to use PyTorch/XLA SPMD?¶
Here is an simple example of using SPMD
import numpy as np
import torch
import torch_xla.core.xla_model as xm
import torch_xla.runtime as xr
import torch_xla.distributed.spmd as xs
from torch_xla.distributed.spmd import Mesh
# Enable XLA SPMD execution mode.
xr.use_spmd()
# Device mesh, this and partition spec as well as the input tensor shape define the individual shard shape.
num_devices = xr.global_runtime_device_count()
mesh_shape = (num_devices, 1)
device_ids = np.array(range(num_devices))
mesh = Mesh(device_ids, mesh_shape, ('data', 'model'))
t = torch.randn(8, 4).to(xm.xla_device())
# Mesh partitioning, each device holds 1/8-th of the input
partition_spec = ('data', 'model')
xs.mark_sharding(t, mesh, partition_spec)
Let’s explain these concepts one by one
SPMD Mode¶
In order to use SPMD, you need to enable it via xr.use_spmd(). In SPMD
mode there is only one logical device. Distributed computation and
collective is handled by the mark_sharding. Note that user can not mix
SPMD with other distributed libraries.
Mesh¶
For a given cluster of devices, a physical mesh is a representation of the interconnect topology.
mesh_shapeis a tuple that will be multiplied to the total number of physical devices.device_idsis almost alwaysnp.array(range(num_devices)).Users are also encouraged to give each mesh dimension a name. In the above example, the first mesh dimension is the
datadimension and the second mesh dimension is themodeldimension.
You can also check more mesh info via
>>> mesh.shape()
OrderedDict([('data', 4), ('model', 1)])
Partition Spec¶
partition_spec has the same rank as the input tensor. Each dimension
describes how the corresponding input tensor dimension is sharded across
the device mesh. In the above example tensor t‘s fist dimension is
being sharded at data dimension and the second dimension is being
sharded at model dimension.
User can also shard tensor that has different dimensions from the mesh shape.
t1 = torch.randn(8, 8, 16).to(device)
t2 = torch.randn(8).to(device)
# First dimension is being replicated.
xs.mark_sharding(t1, mesh, (None, 'data', 'model'))
# First dimension is being sharded at data dimension.
# model dimension is used for replication when omitted.
xs.mark_sharding(t2, mesh, ('data',))
# First dimension is sharded across both mesh axes.
xs.mark_sharding( t2, mesh, (('data', 'model'),))
