


Note
Click here to download the full example code
Online ASR with Emformer RNN-T¶
Author: Jeff Hwang, Moto Hira
This tutorial shows how to use Emformer RNN-T and streaming API to perform online speech recognition.
Note
This tutorial requires FFmpeg libraries and SentencePiece.
Please refer to Optional Dependencies for the detail.
1. Overview¶
Performing online speech recognition is composed of the following steps
Build the inference pipeline Emformer RNN-T is composed of three components: feature extractor, decoder and token processor.
Format the waveform into chunks of expected sizes.
Pass data through the pipeline.
2. Preparation¶
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
import IPython
import matplotlib.pyplot as plt
from torchaudio.io import StreamReader
2.6.0.dev20241104
2.5.0.dev20241105
3. Construct the pipeline¶
Pre-trained model weights and related pipeline components are
bundled as torchaudio.pipelines.RNNTBundle.
We use torchaudio.pipelines.EMFORMER_RNNT_BASE_LIBRISPEECH,
which is a Emformer RNN-T model trained on LibriSpeech dataset.
bundle = torchaudio.pipelines.EMFORMER_RNNT_BASE_LIBRISPEECH
feature_extractor = bundle.get_streaming_feature_extractor()
decoder = bundle.get_decoder()
token_processor = bundle.get_token_processor()
0%| | 0.00/3.81k [00:00<?, ?B/s]
100%|##########| 3.81k/3.81k [00:00<00:00, 7.96MB/s]
0%| | 0.00/293M [00:00<?, ?B/s]
7%|7 | 20.9M/293M [00:00<00:01, 218MB/s]
14%|#4 | 41.8M/293M [00:00<00:01, 204MB/s]
34%|###3 | 99.1M/293M [00:00<00:00, 378MB/s]
53%|#####2 | 155M/293M [00:00<00:00, 457MB/s]
72%|#######2 | 212M/293M [00:00<00:00, 507MB/s]
89%|########9 | 261M/293M [00:00<00:00, 450MB/s]
100%|##########| 293M/293M [00:00<00:00, 433MB/s]
/pytorch/audio/src/torchaudio/pipelines/rnnt_pipeline.py:248: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
state_dict = torch.load(path)
0%| | 0.00/295k [00:00<?, ?B/s]
100%|##########| 295k/295k [00:00<00:00, 63.8MB/s]
Streaming inference works on input data with overlap. Emformer RNN-T model treats the newest portion of the input data as the “right context” — a preview of future context. In each inference call, the model expects the main segment to start from this right context from the previous inference call. The following figure illustrates this.
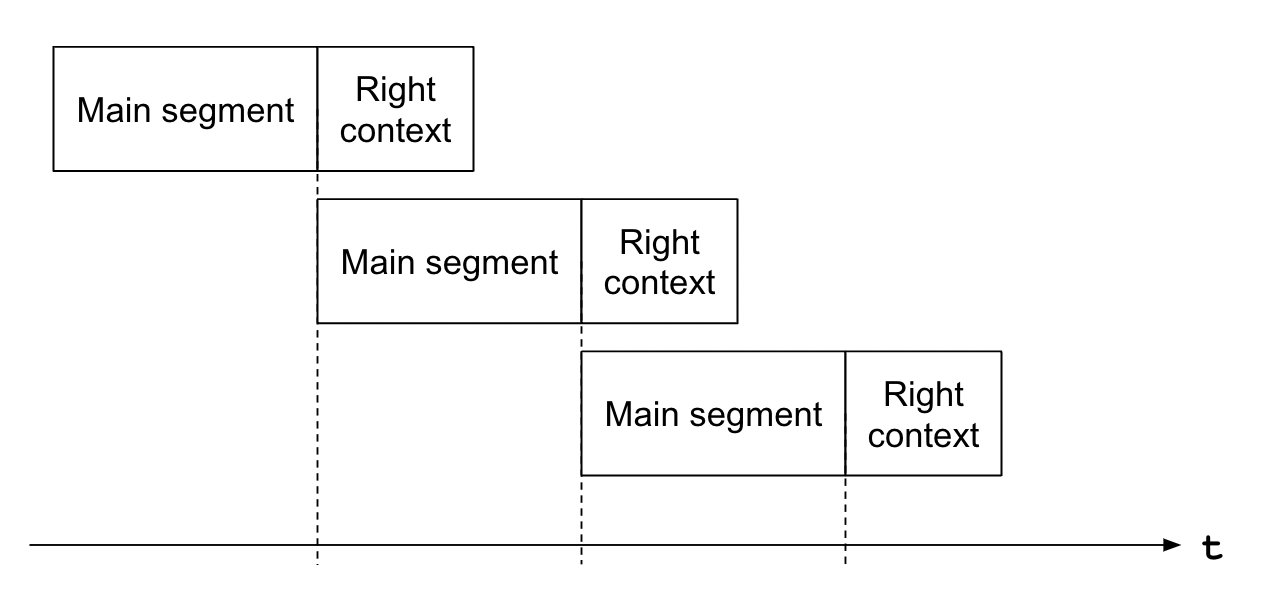
The size of main segment and right context, along with the expected sample rate can be retrieved from bundle.
sample_rate = bundle.sample_rate
segment_length = bundle.segment_length * bundle.hop_length
context_length = bundle.right_context_length * bundle.hop_length
print(f"Sample rate: {sample_rate}")
print(f"Main segment: {segment_length} frames ({segment_length / sample_rate} seconds)")
print(f"Right context: {context_length} frames ({context_length / sample_rate} seconds)")
Sample rate: 16000
Main segment: 2560 frames (0.16 seconds)
Right context: 640 frames (0.04 seconds)
4. Configure the audio stream¶
Next, we configure the input audio stream using torchaudio.io.StreamReader.
For the detail of this API, please refer to the StreamReader Basic Usage.
The following audio file was originally published by LibriVox project, and it is in the public domain.
https://librivox.org/great-pirate-stories-by-joseph-lewis-french/
It was re-uploaded for the sake of the tutorial.
src = "https://download.pytorch.org/torchaudio/tutorial-assets/greatpiratestories_00_various.mp3"
streamer = StreamReader(src)
streamer.add_basic_audio_stream(frames_per_chunk=segment_length, sample_rate=bundle.sample_rate)
print(streamer.get_src_stream_info(0))
print(streamer.get_out_stream_info(0))
SourceAudioStream(media_type='audio', codec='mp3', codec_long_name='MP3 (MPEG audio layer 3)', format='fltp', bit_rate=128000, num_frames=0, bits_per_sample=0, metadata={}, sample_rate=44100.0, num_channels=2)
OutputAudioStream(source_index=0, filter_description='aresample=16000,aformat=sample_fmts=fltp', media_type='audio', format='fltp', sample_rate=16000.0, num_channels=2)
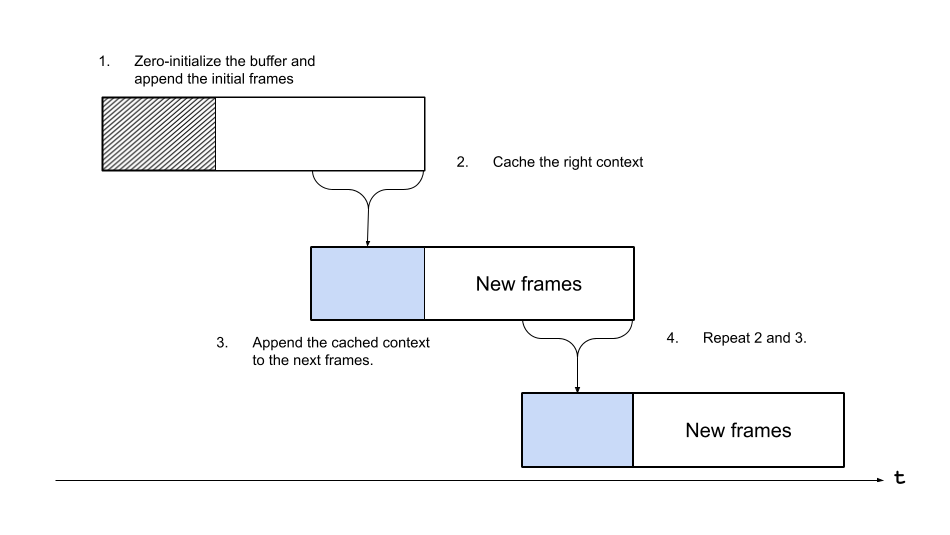
As previously explained, Emformer RNN-T model expects input data with overlaps; however, Streamer iterates the source media without overlap, so we make a helper structure that caches a part of input data from Streamer as right context and then appends it to the next input data from Streamer.
The following figure illustrates this.
class ContextCacher:
"""Cache the end of input data and prepend the next input data with it.
Args:
segment_length (int): The size of main segment.
If the incoming segment is shorter, then the segment is padded.
context_length (int): The size of the context, cached and appended.
"""
def __init__(self, segment_length: int, context_length: int):
self.segment_length = segment_length
self.context_length = context_length
self.context = torch.zeros([context_length])
def __call__(self, chunk: torch.Tensor):
if chunk.size(0) < self.segment_length:
chunk = torch.nn.functional.pad(chunk, (0, self.segment_length - chunk.size(0)))
chunk_with_context = torch.cat((self.context, chunk))
self.context = chunk[-self.context_length :]
return chunk_with_context
5. Run stream inference¶
Finally, we run the recognition.
First, we initialize the stream iterator, context cacher, and state and hypothesis that are used by decoder to carry over the decoding state between inference calls.
cacher = ContextCacher(segment_length, context_length)
state, hypothesis = None, None
Next we, run the inference.
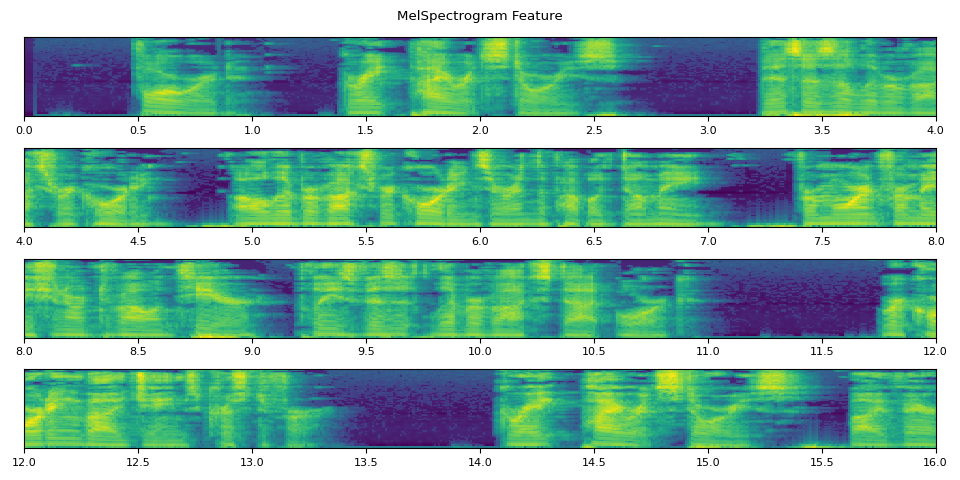
For the sake of better display, we create a helper function which processes the source stream up to the given times and call it repeatedly.
stream_iterator = streamer.stream()
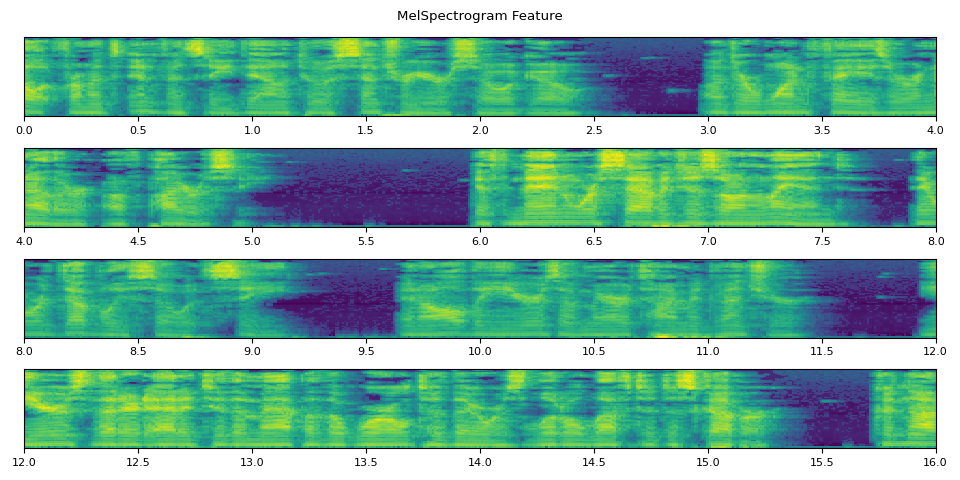
def _plot(feats, num_iter, unit=25):
unit_dur = segment_length / sample_rate * unit
num_plots = num_iter // unit + (1 if num_iter % unit else 0)
fig, axes = plt.subplots(num_plots, 1)
t0 = 0
for i, ax in enumerate(axes):
feats_ = feats[i * unit : (i + 1) * unit]
t1 = t0 + segment_length / sample_rate * len(feats_)
feats_ = torch.cat([f[2:-2] for f in feats_]) # remove boundary effect and overlap
ax.imshow(feats_.T, extent=[t0, t1, 0, 1], aspect="auto", origin="lower")
ax.tick_params(which="both", left=False, labelleft=False)
ax.set_xlim(t0, t0 + unit_dur)
t0 = t1
fig.suptitle("MelSpectrogram Feature")
plt.tight_layout()
@torch.inference_mode()
def run_inference(num_iter=100):
global state, hypothesis
chunks = []
feats = []
for i, (chunk,) in enumerate(stream_iterator, start=1):
segment = cacher(chunk[:, 0])
features, length = feature_extractor(segment)
hypos, state = decoder.infer(features, length, 10, state=state, hypothesis=hypothesis)
hypothesis = hypos
transcript = token_processor(hypos[0][0], lstrip=False)
print(transcript, end="\r", flush=True)
chunks.append(chunk)
feats.append(features)
if i == num_iter:
break
# Plot the features
_plot(feats, num_iter)
return IPython.display.Audio(torch.cat(chunks).T.numpy(), rate=bundle.sample_rate)
run_inference()
forward
forward
forward
forward
forward
forward great
forward great pir
forward great pirate
forward great pirate
forward great pirate stories
forward great pirate stories
forward great pirate stories
forward great pirate stories
forward great pirate stories
forward great pirate stories
forward great pirate stories
forward great pirate stories this
forward great pirate stories this is
forward great pirate stories this is a
forward great pirate stories this is a liber
forward great pirate stories this is a liberal
forward great pirate stories this is a liberal
forward great pirate stories this is a liberal record
forward great pirate stories this is a liberal record
forward great pirate stories this is a liberal recording
forward great pirate stories this is a liberal recording
forward great pirate stories this is a liberal recording all
forward great pirate stories this is a liberal recording all the
forward great pirate stories this is a liberal recording all the
forward great pirate stories this is a liberal recording all the votes
forward great pirate stories this is a liberal recording all the votes record
forward great pirate stories this is a liberal recording all the votes record
forward great pirate stories this is a liberal recording all the votes recordings
forward great pirate stories this is a liberal recording all the votes recordings are
forward great pirate stories this is a liberal recording all the votes recordings are in the
forward great pirate stories this is a liberal recording all the votes recordings are in the public
forward great pirate stories this is a liberal recording all the votes recordings are in the public
forward great pirate stories this is a liberal recording all the votes recordings are in the public dum
forward great pirate stories this is a liberal recording all the votes recordings are in the public dum
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or develop
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunt
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer please
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer please
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer please visit
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer please visit
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer please visit liber
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer please visit liber
forward great pirate stories this is a liberal recording all the votes recordings are in the public duma for more information or to volunteer please visit liberal
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work record
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christ
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories
run_inference()
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by jose
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lew
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french for
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french for
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy em
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the rom
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but ine
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inev
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable com
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civil
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civil
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concer
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concer
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it
run_inference()
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is develop
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its inf
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were sav
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doub
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of mar
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover
run_inference()
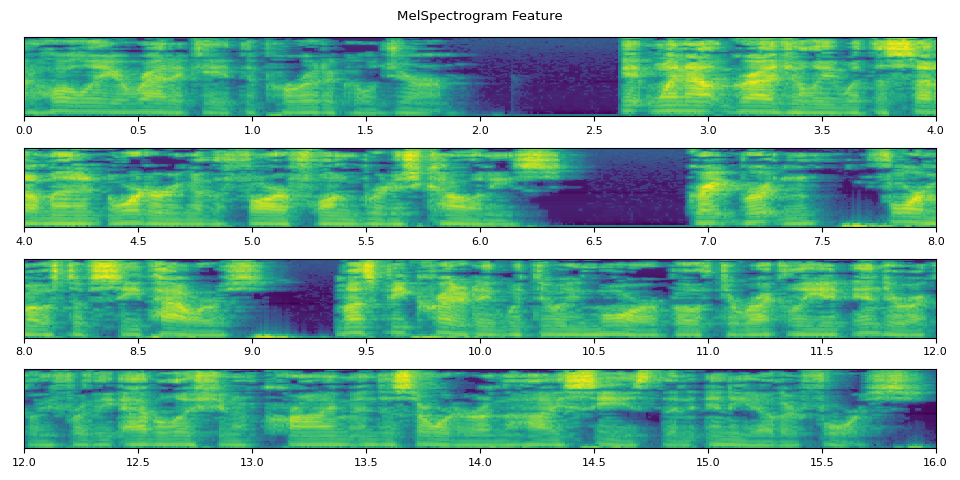
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not who
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly er
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly erad
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the par
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parot
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parentical ger
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid ger
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settle
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settle
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement order
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed brit
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british col
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colon
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great brit
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain fore
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be cred
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and ind
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indire
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the ab
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abol
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and dis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disord
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other
run_inference()
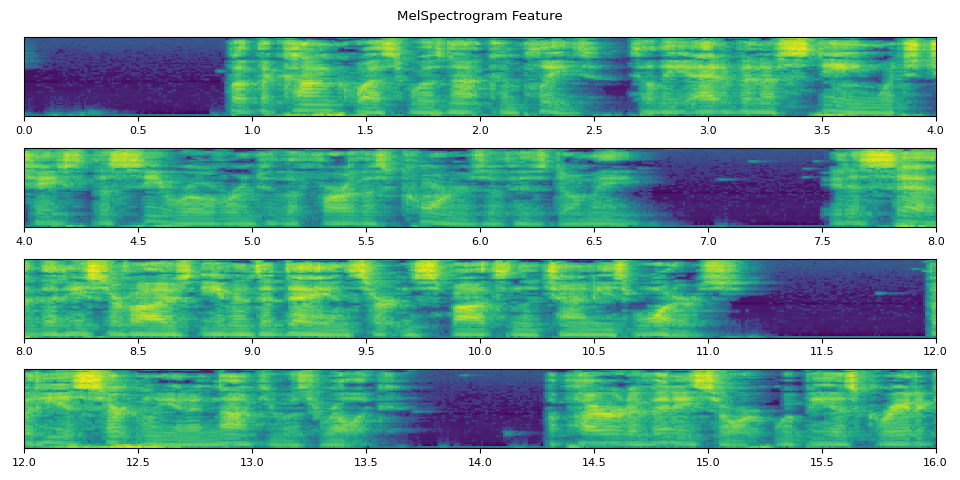
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conqu
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corn
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his dom
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his dom
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he surv
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chines
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an inc
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an inaccurate
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous rel
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous rel
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be
run_inference()
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhib
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fab
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous mon
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous mon
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always pers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most pictures
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most pictures
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more gen
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and grossest character the higher degree
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he ins
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he insp
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there
run_inference()
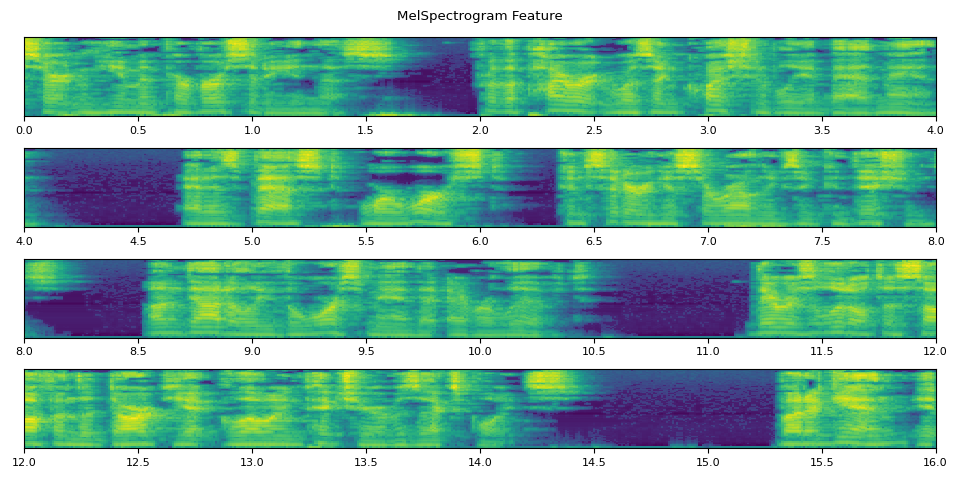
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human per
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestion
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst cons
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst consid
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surr
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions und
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubt
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soft
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his expl
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his explo
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again
run_inference()
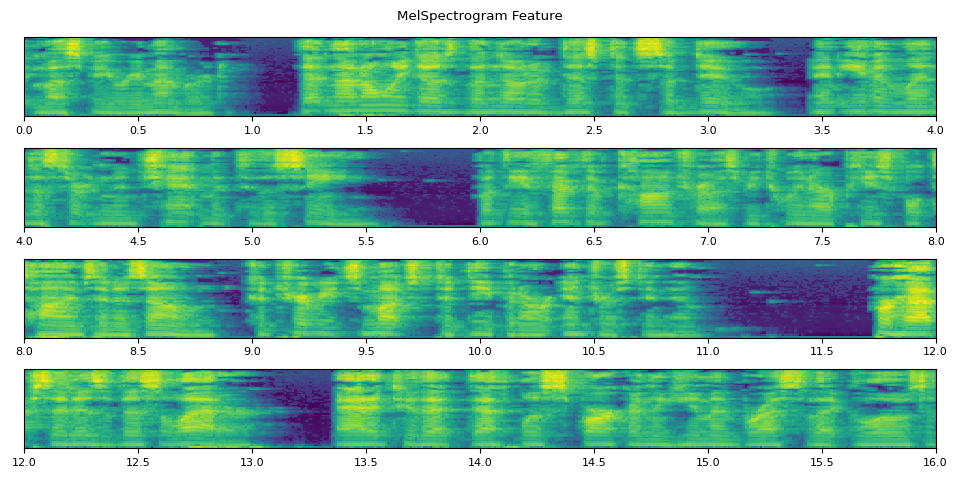
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance sub
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain en
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchant
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contr
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peace
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own cont
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deep
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that death
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that
run_inference()
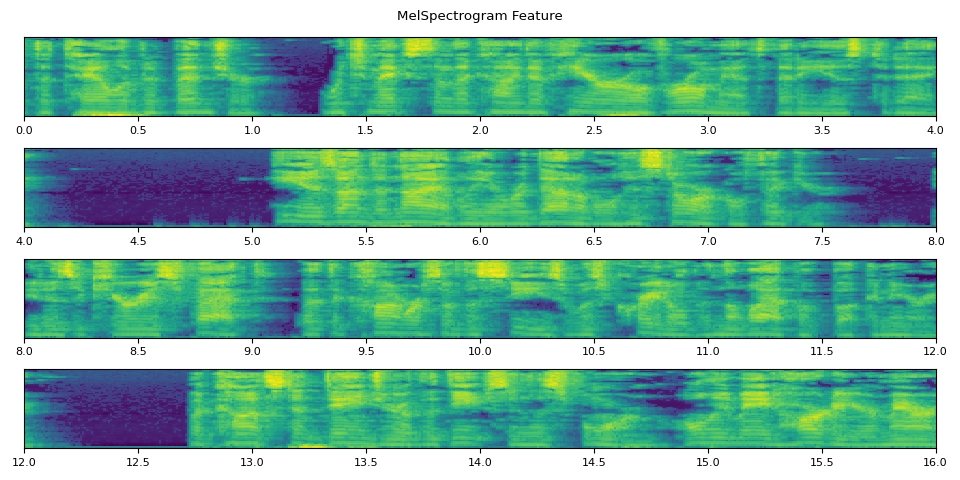
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that gl
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of rom
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is und
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is unden
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubt
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable hist
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable histor
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the comm
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the se
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was crad
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of bucc
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccane
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccane
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deep
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hard
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hard
run_inference()
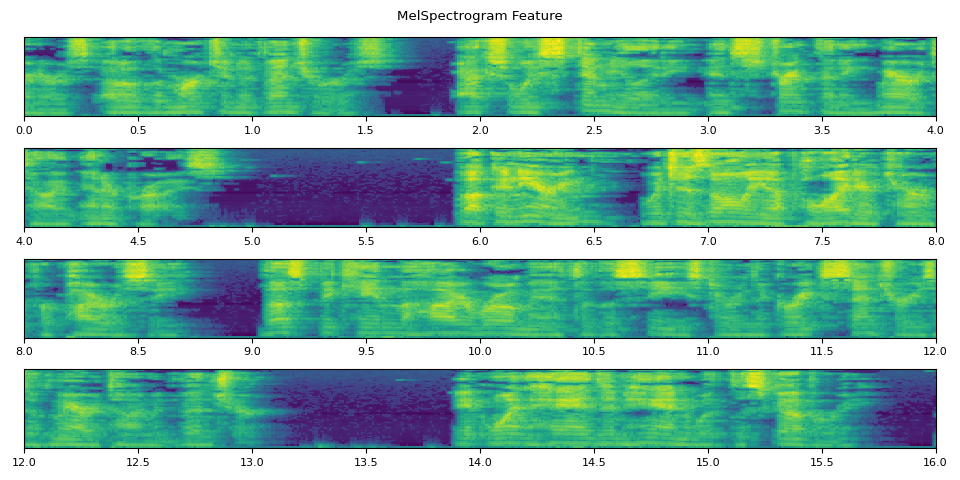
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mar
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier marin
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merch
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually st
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stim
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and stren
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening mar
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enter
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enter
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise bucc
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccane
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a pol
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high rom
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great cent
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of mar
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of marit
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with disco
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery
run_inference()
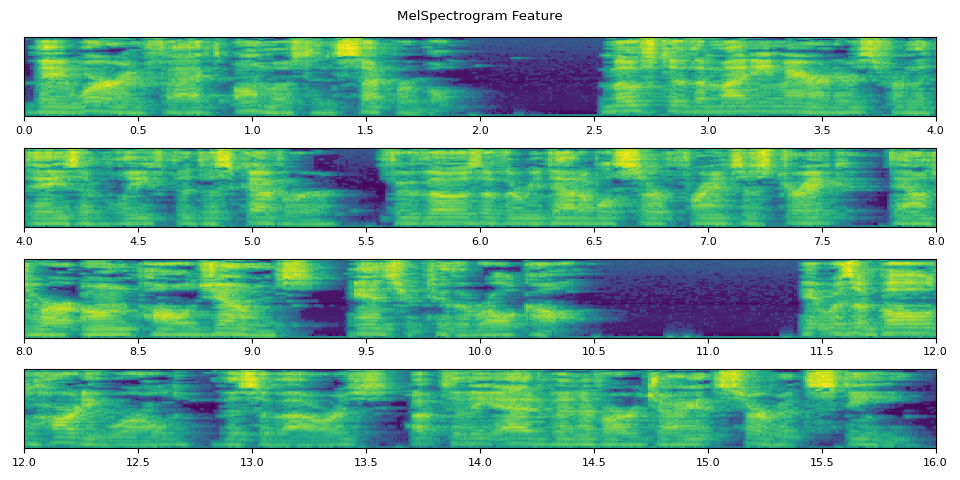
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost insepar
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost insepar
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mar
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the disco
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discovere
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the red
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubt
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir franc
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis dra
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the ro
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold heart
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this av
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avow
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our gi
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants
run_inference()
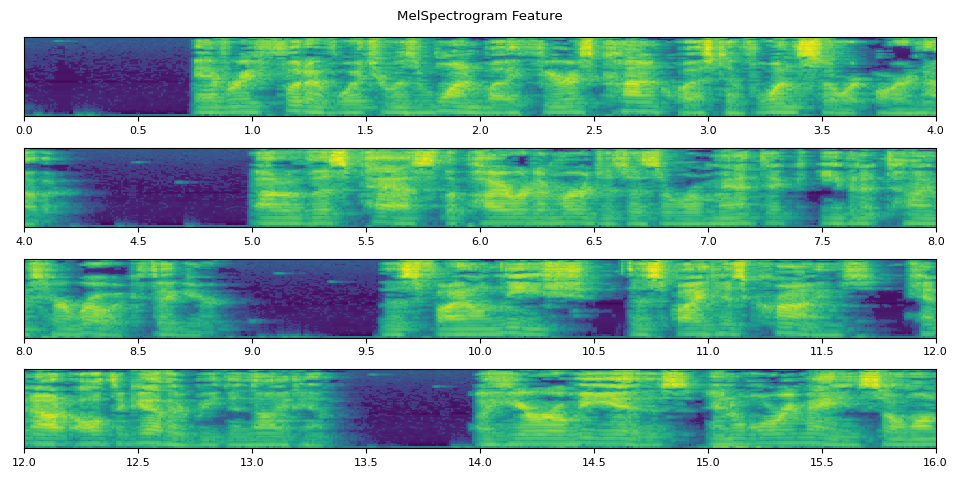
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conqu
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pir
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate em
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emer
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a rom
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a rom
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times hero
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times hero
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this fin
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final nic
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche desp
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be den
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain
run_inference()
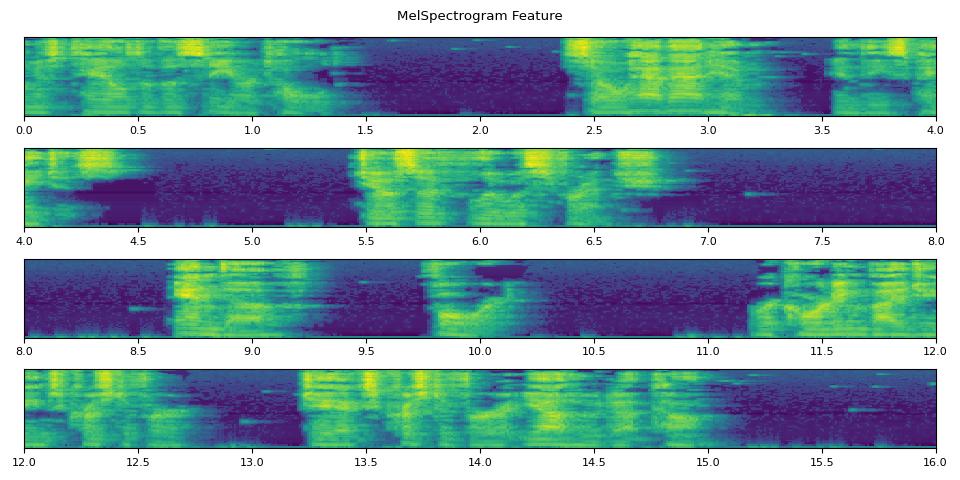
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tal
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages j
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages jose
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lew
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four record
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four record
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christ
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher j
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher j
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher j
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christ
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher james christopher
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher y
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher yah
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher yah
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher yah
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher yah
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher yah come
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher yah come
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher yah come
forward great pirate stories this is a liberal recording all the votes recordings are in the public dummy for more information or to volunteer please visit liberal stout work recording by james christopher great pirate stories by various edited by joseph lewis french forard piracy embodies the romance of the sea in its highest expression it is a sad but inevitable commentary on our civilisation that so far as the sea is concerned it is developed from its infancy down to a century or so ago under one phase or another of piracy if men were savages on land they were doubly so at sea and all the years of maritime adventure years that had added to the map of the world till there was little left to discover could not wholly eradicate the parotid germ it went out gradually with the settlement ordering of the far formed british colonies great britain foremost of sea powers must be credited with doing more both directly and indirectly for the abolition of crime and disorder on the high seas than any other force but the conquest was not complete till the advent of steam which chased the sea rover into the farthest corners of his domain it is said that he survives even to day in certain spots in the chinese waters but he is certainly an innocuous relic a pirate of any sort would be as great a curiosity to day if he could be caught and exhibited as a fabulous monster the fact remains and will always persist that in the war of the sea he is far and away the most picturesque figure in the more genuine and gross character the higher degree of interest as he inspire there may be a certain human perversity in this for the pirate was unquestionably a bad man at his best or worst considering his surroundings and conditions undoubtedly the worst man that ever lived there is little to soften the dark yet glowing picture of his exploits but again it must be remembered that not only does the note of distance subdue and even lend a certain enchantment to the scene but the effect of contrast between our peaceful times and his own contributes much to deepen our interest in him perhaps it is this latter added to that deathless spark on the human breast that glows at the tale of adventure which makes them the kind of hero of romance that he is today he is undeniably a redoubtable historical figure it is a curious fact that the commerce of the seas was cradled in the lap of buccaneering the constant danger of the deeps in this form only made hardier mariners out of the merchant adventurers actually stimulating and strengthening maritime enterprise buccaneering which is only a politer term for piracy thus became the high romance of the sea during the great centuries of maritime adventure it went hand in hand with discovery they were in fact almost inseparable most of the mighty mariners from the days of leif the discoverer through those of the redoubtable sir francis drake down to her own paul jones answered to the roll call it was a bold hearty world this avowal up to the advent of our giant servants steam every foot of which was won by fierce conquest of one sort or another out of this pass the pirate emerges as a romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied him a hero he is and will remain so long as tales of the sea are told so have at him in these pages joseph lewis and of four recording by james christopher jist christopher yah come
Tag: torchaudio.io
Total running time of the script: ( 1 minutes 20.938 seconds)
