


Note
Click here to download the full example code
AudioEffector Usages
Author: Moto Hira
This tutorial shows how to use torchaudio.io.AudioEffector to
apply various effects and codecs to waveform tensor.
Note
This tutorial requires FFmpeg libraries. Please refer to FFmpeg dependency for the detail.
Overview
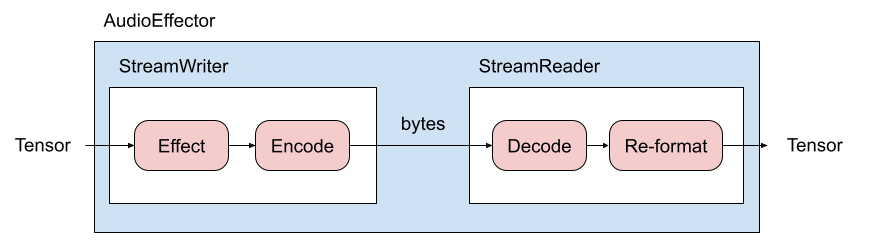
AudioEffector combines in-memory encoding,
decoding and filtering that are provided by
StreamWriter and
StreamReader.
The following figure illustrates the process.
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
2.6.0.dev20241104
2.5.0.dev20241105
from torchaudio.io import AudioEffector, CodecConfig
import matplotlib.pyplot as plt
from IPython.display import Audio
libavcodec (60, 3, 100)
libavdevice (60, 1, 100)
libavfilter (9, 3, 100)
libavformat (60, 3, 100)
libavutil (58, 2, 100)
Usage
To use AudioEffector, instantiate it with effect and
format, then either pass the waveform to
apply() or
stream() method.
effector = AudioEffector(effect=..., format=...,)
# Apply at once
applied = effector.apply(waveform, sample_rate)
apply method applies effect and codec to the entire waveform at
once. So if the input waveform is long, and memory consumption is an
issue, one can use stream method to process chunk by chunk.
# Apply chunk by chunk
for applied_chunk = effector.stream(waveform, sample_rate):
...
Example
Gallery
def show(effect, *, stereo=False):
wf = torch.cat([waveform] * 2, dim=1) if stereo else waveform
figsize = (6.4, 2.1 if stereo else 1.2)
effector = AudioEffector(effect=effect, pad_end=False)
result = effector.apply(wf, int(sr))
num_channels = result.size(1)
f, ax = plt.subplots(num_channels, 1, squeeze=False, figsize=figsize, sharex=True)
for i in range(num_channels):
ax[i][0].specgram(result[:, i], Fs=sr)
f.set_tight_layout(True)
return Audio(result.numpy().T, rate=sr)
Original
show(effect=None)

Effects
tempo
https://ffmpeg.org/ffmpeg-filters.html#atempo
show("atempo=0.7")

show("atempo=1.8")

highpass
https://ffmpeg.org/ffmpeg-filters.html#highpass
show("highpass=frequency=1500")

lowpass
https://ffmpeg.org/ffmpeg-filters.html#lowpass
show("lowpass=frequency=1000")

allpass
https://ffmpeg.org/ffmpeg-filters.html#allpass
show("allpass")

bandpass
https://ffmpeg.org/ffmpeg-filters.html#bandpass
show("bandpass=frequency=3000")

bandreject
https://ffmpeg.org/ffmpeg-filters.html#bandreject
show("bandreject=frequency=3000")

echo
https://ffmpeg.org/ffmpeg-filters.html#aecho
show("aecho=in_gain=0.8:out_gain=0.88:delays=6:decays=0.4")

show("aecho=in_gain=0.8:out_gain=0.88:delays=60:decays=0.4")

show("aecho=in_gain=0.8:out_gain=0.9:delays=1000:decays=0.3")

chorus
https://ffmpeg.org/ffmpeg-filters.html#chorus
show("chorus=0.5:0.9:50|60|40:0.4|0.32|0.3:0.25|0.4|0.3:2|2.3|1.3")

fft filter
https://ffmpeg.org/ffmpeg-filters.html#afftfilt
# fmt: off
show(
"afftfilt="
"real='re * (1-clip(b * (b/nb), 0, 1))':"
"imag='im * (1-clip(b * (b/nb), 0, 1))'"
)

show(
"afftfilt="
"real='hypot(re,im) * sin(0)':"
"imag='hypot(re,im) * cos(0)':"
"win_size=512:"
"overlap=0.75"
)

show(
"afftfilt="
"real='hypot(re,im) * cos(2 * 3.14 * (random(0) * 2-1))':"
"imag='hypot(re,im) * sin(2 * 3.14 * (random(1) * 2-1))':"
"win_size=128:"
"overlap=0.8"
)
# fmt: on

vibrato
https://ffmpeg.org/ffmpeg-filters.html#vibrato
show("vibrato=f=10:d=0.8")

/pytorch/audio/ci_env/lib/python3.10/site-packages/IPython/lib/display.py:188: RuntimeWarning: invalid value encountered in cast
return scaled.astype("<h").tobytes(), nchan
tremolo
https://ffmpeg.org/ffmpeg-filters.html#tremolo
show("tremolo=f=8:d=0.8")

crystalizer
https://ffmpeg.org/ffmpeg-filters.html#crystalizer
show("crystalizer")

flanger
https://ffmpeg.org/ffmpeg-filters.html#flanger
show("flanger")

phaser
https://ffmpeg.org/ffmpeg-filters.html#aphaser
show("aphaser")

pulsator
https://ffmpeg.org/ffmpeg-filters.html#apulsator
show("apulsator", stereo=True)
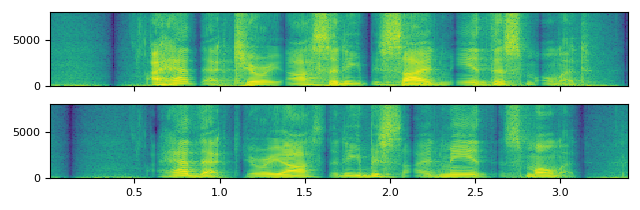
haas
https://ffmpeg.org/ffmpeg-filters.html#haas
show("haas")

Codecs
def show_multi(configs):
results = []
for config in configs:
effector = AudioEffector(**config)
results.append(effector.apply(waveform, int(sr)))
num_configs = len(configs)
figsize = (6.4, 0.3 + num_configs * 0.9)
f, axes = plt.subplots(num_configs, 1, figsize=figsize, sharex=True)
for result, ax in zip(results, axes):
ax.specgram(result[:, 0], Fs=sr)
f.set_tight_layout(True)
return [Audio(r.numpy().T, rate=sr) for r in results]
ogg
results = show_multi(
[
{"format": "ogg"},
{"format": "ogg", "encoder": "vorbis"},
{"format": "ogg", "encoder": "opus"},
]
)
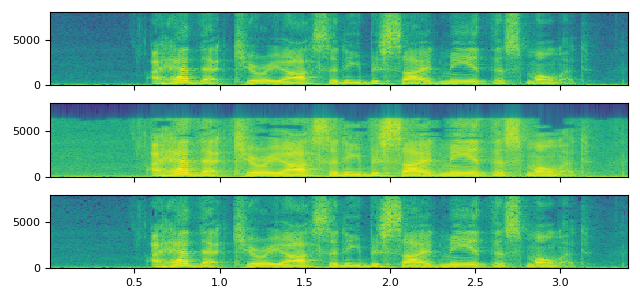
ogg - default encoder (flac)
results[0]
ogg - vorbis
results[1]
ogg - opus
results[2]
mp3
https://trac.ffmpeg.org/wiki/Encode/MP3
results = show_multi(
[
{"format": "mp3"},
{"format": "mp3", "codec_config": CodecConfig(compression_level=1)},
{"format": "mp3", "codec_config": CodecConfig(compression_level=9)},
{"format": "mp3", "codec_config": CodecConfig(bit_rate=192_000)},
{"format": "mp3", "codec_config": CodecConfig(bit_rate=8_000)},
{"format": "mp3", "codec_config": CodecConfig(qscale=9)},
{"format": "mp3", "codec_config": CodecConfig(qscale=1)},
]
)
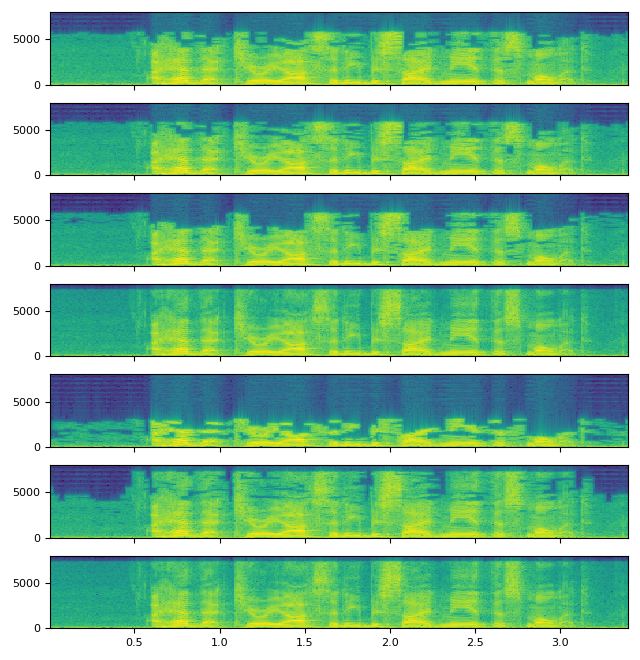
default
results[0]
compression_level=1
results[1]
compression_level=9
results[2]
bit_rate=192k
results[3]
bit_rate=8k
results[4]
qscale=9
results[5]
qscale=1
results[6]
Tag: torchaudio.io
Total running time of the script: ( 0 minutes 3.061 seconds)
