torchaudio.pipelines
The torchaudio.pipelines module packages pre-trained models with support functions and meta-data into simple APIs tailored to perform specific tasks.
When using pre-trained models to perform a task, in addition to instantiating the model with pre-trained weights, the client code also needs to build pipelines for feature extractions and post processing in the same way they were done during the training. This requires to carrying over information used during the training, such as the type of transforms and the their parameters (for example, sampling rate the number of FFT bins).
To make this information tied to a pre-trained model and easily accessible, torchaudio.pipelines module uses the concept of a Bundle class, which defines a set of APIs to instantiate pipelines, and the interface of the pipelines.
The following figure illustrates this.

A pre-trained model and associated pipelines are expressed as an instance of Bundle. Different instances of same Bundle share the interface, but their implementations are not constrained to be of same types. For example, SourceSeparationBundle defines the interface for performing source separation, but its instance CONVTASNET_BASE_LIBRI2MIX instantiates a model of ConvTasNet while HDEMUCS_HIGH_MUSDB instantiates a model of HDemucs. Still, because they share the same interface, the usage is the same.
Note
Under the hood, the implementations of Bundle use components from other torchaudio modules, such as torchaudio.models and torchaudio.transforms, or even third party libraries like SentencPiece and DeepPhonemizer. But this implementation detail is abstracted away from library users.
RNN-T Streaming/Non-Streaming ASR
Interface
RNNTBundle defines ASR pipelines and consists of three steps: feature extraction, inference, and de-tokenization.

Dataclass that bundles components for performing automatic speech recognition (ASR, speech-to-text) inference with an RNN-T model. |
|
Interface of the feature extraction part of RNN-T pipeline |
|
Interface of the token processor part of RNN-T pipeline |
Tutorials using RNNTBundle

Pretrained Models
ASR pipeline based on Emformer-RNNT, pretrained on LibriSpeech dataset [Panayotov et al., 2015], capable of performing both streaming and non-streaming inference. |
wav2vec 2.0 / HuBERT / WavLM - SSL
Interface
Wav2Vec2Bundle instantiates models that generate acoustic features that can be used for downstream inference and fine-tuning.

Data class that bundles associated information to use pretrained |
Pretrained Models
Wav2vec 2.0 model ("base" architecture), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), not fine-tuned. |
|
Wav2vec 2.0 model ("large" architecture), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), not fine-tuned. |
|
Wav2vec 2.0 model ("large-lv60k" architecture), pre-trained on 60,000 hours of unlabeled audio from Libri-Light dataset [Kahn et al., 2020], not fine-tuned. |
|
Wav2vec 2.0 model ("base" architecture), pre-trained on 56,000 hours of unlabeled audio from multiple datasets ( Multilingual LibriSpeech [Pratap et al., 2020], CommonVoice [Ardila et al., 2020] and BABEL [Gales et al., 2014]), not fine-tuned. |
|
XLS-R model with 300 million parameters, pre-trained on 436,000 hours of unlabeled audio from multiple datasets ( Multilingual LibriSpeech [Pratap et al., 2020], CommonVoice [Ardila et al., 2020], VoxLingua107 [Valk and Alumäe, 2021], BABEL [Gales et al., 2014], and VoxPopuli [Wang et al., 2021]) in 128 languages, not fine-tuned. |
|
XLS-R model with 1 billion parameters, pre-trained on 436,000 hours of unlabeled audio from multiple datasets ( Multilingual LibriSpeech [Pratap et al., 2020], CommonVoice [Ardila et al., 2020], VoxLingua107 [Valk and Alumäe, 2021], BABEL [Gales et al., 2014], and VoxPopuli [Wang et al., 2021]) in 128 languages, not fine-tuned. |
|
XLS-R model with 2 billion parameters, pre-trained on 436,000 hours of unlabeled audio from multiple datasets ( Multilingual LibriSpeech [Pratap et al., 2020], CommonVoice [Ardila et al., 2020], VoxLingua107 [Valk and Alumäe, 2021], BABEL [Gales et al., 2014], and VoxPopuli [Wang et al., 2021]) in 128 languages, not fine-tuned. |
|
HuBERT model ("base" architecture), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), not fine-tuned. |
|
HuBERT model ("large" architecture), pre-trained on 60,000 hours of unlabeled audio from Libri-Light dataset [Kahn et al., 2020], not fine-tuned. |
|
HuBERT model ("extra large" architecture), pre-trained on 60,000 hours of unlabeled audio from Libri-Light dataset [Kahn et al., 2020], not fine-tuned. |
|
WavLM Base model ("base" architecture), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015], not fine-tuned. |
|
WavLM Base+ model ("base" architecture), pre-trained on 60,000 hours of Libri-Light dataset [Kahn et al., 2020], 10,000 hours of GigaSpeech [Chen et al., 2021], and 24,000 hours of VoxPopuli [Wang et al., 2021], not fine-tuned. |
|
WavLM Large model ("large" architecture), pre-trained on 60,000 hours of Libri-Light dataset [Kahn et al., 2020], 10,000 hours of GigaSpeech [Chen et al., 2021], and 24,000 hours of VoxPopuli [Wang et al., 2021], not fine-tuned. |
wav2vec 2.0 / HuBERT - Fine-tuned ASR
Interface
Wav2Vec2ASRBundle instantiates models that generate probability distribution over pre-defined labels, that can be used for ASR.

Data class that bundles associated information to use pretrained |
Tutorials using Wav2Vec2ASRBundle
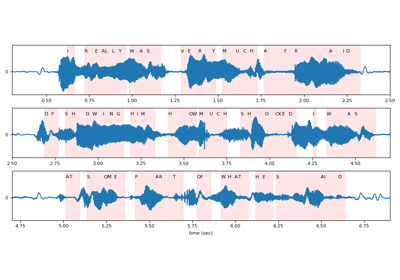
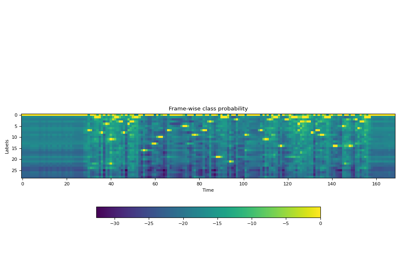
Pretrained Models
Wav2vec 2.0 model ("base" architecture with an extra linear module), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), and fine-tuned for ASR on 10 minutes of transcribed audio from Libri-Light dataset [Kahn et al., 2020] ("train-10min" subset). |
|
Wav2vec 2.0 model ("base" architecture with an extra linear module), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), and fine-tuned for ASR on 100 hours of transcribed audio from "train-clean-100" subset. |
|
Wav2vec 2.0 model ("base" architecture with an extra linear module), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), and fine-tuned for ASR on the same audio with the corresponding transcripts. |
|
Wav2vec 2.0 model ("large" architecture with an extra linear module), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), and fine-tuned for ASR on 10 minutes of transcribed audio from Libri-Light dataset [Kahn et al., 2020] ("train-10min" subset). |
|
Wav2vec 2.0 model ("large" architecture with an extra linear module), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), and fine-tuned for ASR on 100 hours of transcribed audio from the same dataset ("train-clean-100" subset). |
|
Wav2vec 2.0 model ("large" architecture with an extra linear module), pre-trained on 960 hours of unlabeled audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"), and fine-tuned for ASR on the same audio with the corresponding transcripts. |
|
Wav2vec 2.0 model ("large-lv60k" architecture with an extra linear module), pre-trained on 60,000 hours of unlabeled audio from Libri-Light dataset [Kahn et al., 2020], and fine-tuned for ASR on 10 minutes of transcribed audio from the same dataset ("train-10min" subset). |
|
Wav2vec 2.0 model ("large-lv60k" architecture with an extra linear module), pre-trained on 60,000 hours of unlabeled audio from Libri-Light dataset [Kahn et al., 2020], and fine-tuned for ASR on 100 hours of transcribed audio from LibriSpeech dataset [Panayotov et al., 2015] ("train-clean-100" subset). |
|
Wav2vec 2.0 model ("large-lv60k" architecture with an extra linear module), pre-trained on 60,000 hours of unlabeled audio from Libri-Light [Kahn et al., 2020] dataset, and fine-tuned for ASR on 960 hours of transcribed audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"). |
|
wav2vec 2.0 model ("base" architecture), pre-trained on 10k hours of unlabeled audio from VoxPopuli dataset [Wang et al., 2021] ("10k" subset, consisting of 23 languages), and fine-tuned for ASR on 282 hours of transcribed audio from "de" subset. |
|
wav2vec 2.0 model ("base" architecture), pre-trained on 10k hours of unlabeled audio from VoxPopuli dataset [Wang et al., 2021] ("10k" subset, consisting of 23 languages), and fine-tuned for ASR on 543 hours of transcribed audio from "en" subset. |
|
wav2vec 2.0 model ("base" architecture), pre-trained on 10k hours of unlabeled audio from VoxPopuli dataset [Wang et al., 2021] ("10k" subset, consisting of 23 languages), and fine-tuned for ASR on 166 hours of transcribed audio from "es" subset. |
|
wav2vec 2.0 model ("base" architecture), pre-trained on 10k hours of unlabeled audio from VoxPopuli dataset [Wang et al., 2021] ("10k" subset, consisting of 23 languages), and fine-tuned for ASR on 211 hours of transcribed audio from "fr" subset. |
|
wav2vec 2.0 model ("base" architecture), pre-trained on 10k hours of unlabeled audio from VoxPopuli dataset [Wang et al., 2021] ("10k" subset, consisting of 23 languages), and fine-tuned for ASR on 91 hours of transcribed audio from "it" subset. |
|
HuBERT model ("large" architecture), pre-trained on 60,000 hours of unlabeled audio from Libri-Light dataset [Kahn et al., 2020], and fine-tuned for ASR on 960 hours of transcribed audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"). |
|
HuBERT model ("extra large" architecture), pre-trained on 60,000 hours of unlabeled audio from Libri-Light dataset [Kahn et al., 2020], and fine-tuned for ASR on 960 hours of transcribed audio from LibriSpeech dataset [Panayotov et al., 2015] (the combination of "train-clean-100", "train-clean-360", and "train-other-500"). |
wav2vec 2.0 / HuBERT - Forced Alignment
Interface
Wav2Vec2FABundle bundles pre-trained model and its associated dictionary. Additionally, it supports appending star token dimension.

Data class that bundles associated information to use pretrained |
|
Interface of the tokenizer |
|
Interface of the aligner |
Tutorials using Wav2Vec2FABundle
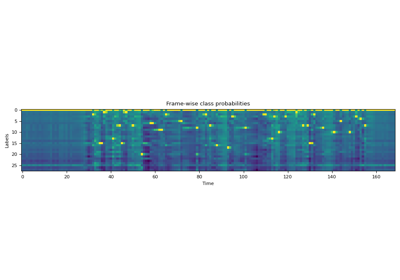
Pertrained Models
Trained on 31K hours of data in 1,130 languages from Scaling Speech Technology to 1,000+ Languages [Pratap et al., 2023]. |
Tacotron2 Text-To-Speech
Tacotron2TTSBundle defines text-to-speech pipelines and consists of three steps: tokenization, spectrogram generation and vocoder. The spectrogram generation is based on Tacotron2 model.

TextProcessor can be rule-based tokenization in the case of characters, or it can be a neural-netowrk-based G2P model that generates sequence of phonemes from input text.
Similarly Vocoder can be an algorithm without learning parameters, like Griffin-Lim, or a neural-network-based model like Waveglow.
Interface
Data class that bundles associated information to use pretrained Tacotron2 and vocoder. |
|
Interface of the text processing part of Tacotron2TTS pipeline |
|
Interface of the vocoder part of Tacotron2TTS pipeline |
Tutorials using Tacotron2TTSBundle
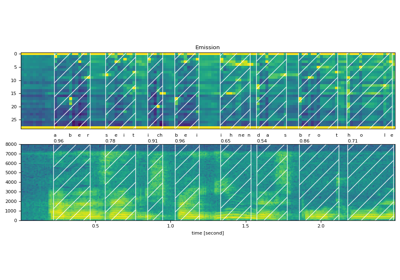
Pretrained Models
Phoneme-based TTS pipeline with |
|
Character-based TTS pipeline with |
|
Phoneme-based TTS pipeline with |
|
Character-based TTS pipeline with |
Source Separation
Interface
SourceSeparationBundle instantiates source separation models which take single channel audio and generates multi-channel audio.

Dataclass that bundles components for performing source separation. |
Tutorials using SourceSeparationBundle
Pretrained Models
Pre-trained Source Separation pipeline with ConvTasNet [Luo and Mesgarani, 2019] trained on Libri2Mix dataset [Cosentino et al., 2020]. |
|
Pre-trained music source separation pipeline with Hybrid Demucs [Défossez, 2021] trained on both training and test sets of MUSDB-HQ [Rafii et al., 2019] and an additional 150 extra songs from an internal database that was specifically produced for Meta. |
|
Pre-trained music source separation pipeline with Hybrid Demucs [Défossez, 2021] trained on the training set of MUSDB-HQ [Rafii et al., 2019]. |
Squim Objective
Interface
SquimObjectiveBundle defines speech quality and intelligibility measurement (SQUIM) pipeline that can predict objecive metric scores given the input waveform.
Data class that bundles associated information to use pretrained |
Pretrained Models
SquimObjective pipeline trained using approach described in [Kumar et al., 2023] on the DNS 2020 Dataset [Reddy et al., 2020]. |
Squim Subjective
Interface
SquimSubjectiveBundle defines speech quality and intelligibility measurement (SQUIM) pipeline that can predict subjective metric scores given the input waveform.
Data class that bundles associated information to use pretrained |
Pretrained Models
SquimSubjective pipeline trained as described in [Manocha and Kumar, 2022] and [Kumar et al., 2023] on the BVCC [Cooper and Yamagishi, 2021] and DAPS [Mysore, 2014] datasets. |
