Wav2Vec2Model
- class torchaudio.models.Wav2Vec2Model(feature_extractor: Module, encoder: Module, aux: Optional[Module] = None)[source]
Acoustic model used in wav2vec 2.0 [Baevski et al., 2020].
Note
To build the model, please use one of the factory functions.
wav2vec2_model(),wav2vec2_base(),wav2vec2_large(),wav2vec2_large_lv60k(),hubert_base(),hubert_large(), andhubert_xlarge().See also
torchaudio.pipelines.Wav2Vec2Bundle: Pretrained models (without fine-tuning)torchaudio.pipelines.Wav2Vec2ASRBundle: ASR pipelines with pretrained models.
- Parameters:
feature_extractor (torch.nn.Module) – Feature extractor that extracts feature vectors from raw audio Tensor.
encoder (torch.nn.Module) – Encoder that converts the audio features into the sequence of probability distribution (in negative log-likelihood) over labels.
aux (torch.nn.Module or None, optional) – Auxiliary module. If provided, the output from encoder is passed to this module.
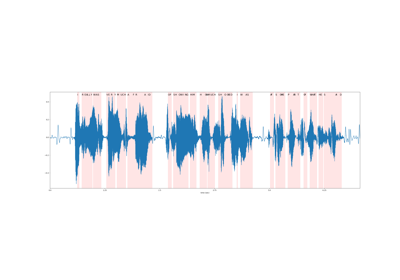
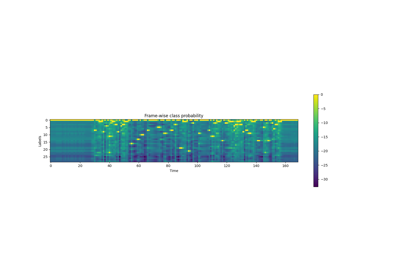
- Tutorials using
Wav2Vec2Model:
forward
- Wav2Vec2Model.forward(waveforms: Tensor, lengths: Optional[Tensor] = None) Tuple[Tensor, Optional[Tensor]][source]
Compute the sequence of probability distribution over labels.
- Parameters:
waveforms (Tensor) – Audio tensor of shape (batch, frames).
lengths (Tensor or None, optional) – Indicates the valid length of each audio in the batch. Shape: (batch, ). When the
waveformscontains audios with different durations, by providinglengthsargument, the model will compute the corresponding valid output lengths and apply proper mask in transformer attention layer. IfNone, it is assumed that all the audio inwaveformshave valid length. Default:None.
- Returns:
- Tensor
The sequences of probability distribution (in logit) over labels. Shape: (batch, frames, num labels).
- Tensor or None
If
lengthsargument was provided, a Tensor of shape (batch, ) is returned. It indicates the valid length in time axis of the output Tensor.
- Return type:
(Tensor, Optional[Tensor])
extract_features
- Wav2Vec2Model.extract_features(waveforms: Tensor, lengths: Optional[Tensor] = None, num_layers: Optional[int] = None) Tuple[List[Tensor], Optional[Tensor]][source]
Extract feature vectors from raw waveforms
This returns the list of outputs from the intermediate layers of transformer block in encoder.
- Parameters:
waveforms (Tensor) – Audio tensor of shape (batch, frames).
lengths (Tensor or None, optional) – Indicates the valid length of each audio in the batch. Shape: (batch, ). When the
waveformscontains audios with different durations, by providinglengthsargument, the model will compute the corresponding valid output lengths and apply proper mask in transformer attention layer. IfNone, it is assumed that the entire audio waveform length is valid.num_layers (int or None, optional) – If given, limit the number of intermediate layers to go through. Providing 1 will stop the computation after going through one intermediate layers. If not given, the outputs from all the intermediate layers are returned.
- Returns:
- List of Tensors
Features from requested layers. Each Tensor is of shape: (batch, time frame, feature dimension)
- Tensor or None
If
lengthsargument was provided, a Tensor of shape (batch, ) is returned. It indicates the valid length in time axis of each feature Tensor.
- Return type:
(List[Tensor], Optional[Tensor])
