


Note
Click here to download the full example code
Text-to-Speech with Tacotron2
Author: Yao-Yuan Yang, Moto Hira
import IPython
import matplotlib
import matplotlib.pyplot as plt
Overview
This tutorial shows how to build text-to-speech pipeline, using the pretrained Tacotron2 in torchaudio.
The text-to-speech pipeline goes as follows:
Text preprocessing
First, the input text is encoded into a list of symbols. In this tutorial, we will use English characters and phonemes as the symbols.
Spectrogram generation
From the encoded text, a spectrogram is generated. We use
Tacotron2model for this.Time-domain conversion
The last step is converting the spectrogram into the waveform. The process to generate speech from spectrogram is also called Vocoder. In this tutorial, three different vocoders are used,
WaveRNN,GriffinLim, and Nvidia’s WaveGlow.
The following figure illustrates the whole process.
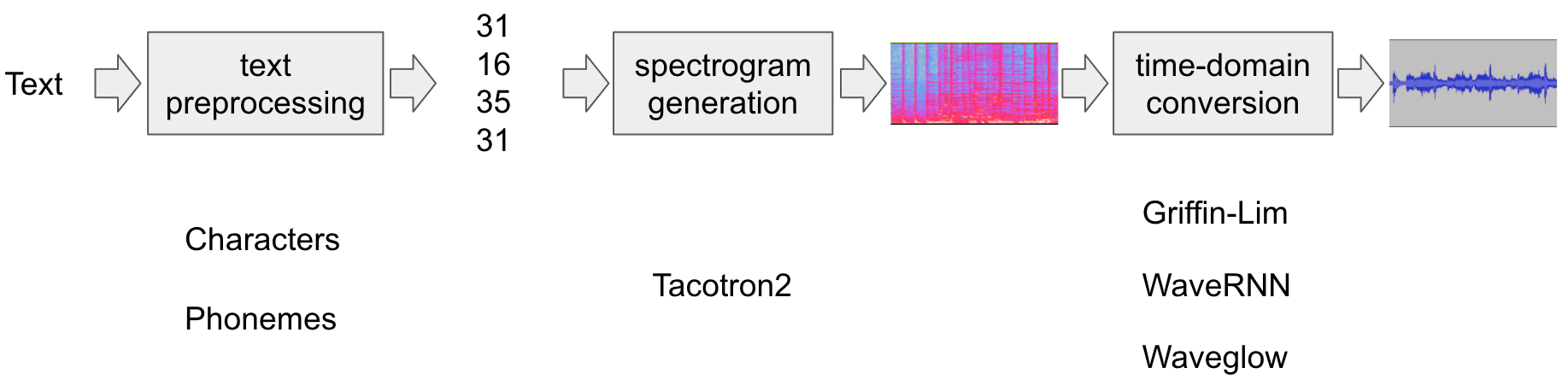
All the related components are bundled in torchaudio.pipelines.Tacotron2TTSBundle,
but this tutorial will also cover the process under the hood.
Preparation
First, we install the necessary dependencies. In addition to
torchaudio, DeepPhonemizer is required to perform phoneme-based
encoding.
%%bash
pip3 install deep_phonemizer
import torch
import torchaudio
matplotlib.rcParams["figure.figsize"] = [16.0, 4.8]
torch.random.manual_seed(0)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(torch.__version__)
print(torchaudio.__version__)
print(device)
1.13.0
0.13.0
cpu
Text Processing
Character-based encoding
In this section, we will go through how the character-based encoding works.
Since the pre-trained Tacotron2 model expects specific set of symbol
tables, the same functionalities available in torchaudio. This
section is more for the explanation of the basis of encoding.
Firstly, we define the set of symbols. For example, we can use
'_-!\'(),.:;? abcdefghijklmnopqrstuvwxyz'. Then, we will map the
each character of the input text into the index of the corresponding
symbol in the table.
The following is an example of such processing. In the example, symbols that are not in the table are ignored.
[19, 16, 23, 23, 26, 11, 34, 26, 29, 23, 15, 2, 11, 31, 16, 35, 31, 11, 31, 26, 11, 30, 27, 16, 16, 14, 19, 2]
As mentioned in the above, the symbol table and indices must match
what the pretrained Tacotron2 model expects. torchaudio provides the
transform along with the pretrained model. For example, you can
instantiate and use such transform as follow.
tensor([[19, 16, 23, 23, 26, 11, 34, 26, 29, 23, 15, 2, 11, 31, 16, 35, 31, 11,
31, 26, 11, 30, 27, 16, 16, 14, 19, 2]])
tensor([28], dtype=torch.int32)
The processor object takes either a text or list of texts as inputs.
When a list of texts are provided, the returned lengths variable
represents the valid length of each processed tokens in the output
batch.
The intermediate representation can be retrieved as follow.
['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!', ' ', 't', 'e', 'x', 't', ' ', 't', 'o', ' ', 's', 'p', 'e', 'e', 'c', 'h', '!']
Phoneme-based encoding
Phoneme-based encoding is similar to character-based encoding, but it uses a symbol table based on phonemes and a G2P (Grapheme-to-Phoneme) model.
The detail of the G2P model is out of scope of this tutorial, we will just look at what the conversion looks like.
Similar to the case of character-based encoding, the encoding process is
expected to match what a pretrained Tacotron2 model is trained on.
torchaudio has an interface to create the process.
The following code illustrates how to make and use the process. Behind
the scene, a G2P model is created using DeepPhonemizer package, and
the pretrained weights published by the author of DeepPhonemizer is
fetched.
0%| | 0.00/63.6M [00:00<?, ?B/s]
0%| | 64.0k/63.6M [00:00<03:03, 363kB/s]
0%| | 264k/63.6M [00:00<01:21, 815kB/s]
2%|1 | 1.14M/63.6M [00:00<00:23, 2.78MB/s]
6%|6 | 3.82M/63.6M [00:00<00:08, 7.80MB/s]
11%|# | 6.87M/63.6M [00:00<00:05, 11.4MB/s]
16%|#5 | 10.0M/63.6M [00:01<00:04, 13.7MB/s]
21%|## | 13.2M/63.6M [00:01<00:03, 15.2MB/s]
26%|##5 | 16.4M/63.6M [00:01<00:03, 16.4MB/s]
31%|### | 19.7M/63.6M [00:01<00:02, 17.1MB/s]
36%|###6 | 23.0M/63.6M [00:01<00:02, 17.7MB/s]
41%|####1 | 26.3M/63.6M [00:01<00:02, 18.2MB/s]
47%|####6 | 29.6M/63.6M [00:02<00:01, 18.5MB/s]
52%|#####1 | 33.0M/63.6M [00:02<00:01, 18.8MB/s]
57%|#####7 | 36.4M/63.6M [00:02<00:01, 19.0MB/s]
62%|######2 | 39.7M/63.6M [00:02<00:01, 19.2MB/s]
68%|######7 | 43.1M/63.6M [00:02<00:01, 19.3MB/s]
73%|#######2 | 46.2M/63.6M [00:03<00:00, 19.0MB/s]
77%|#######6 | 49.0M/63.6M [00:03<00:00, 20.9MB/s]
81%|######## | 51.4M/63.6M [00:03<00:00, 18.9MB/s]
86%|########6 | 54.8M/63.6M [00:03<00:00, 22.4MB/s]
90%|########9 | 57.1M/63.6M [00:03<00:00, 19.4MB/s]
94%|#########4| 60.1M/63.6M [00:03<00:00, 18.8MB/s]
99%|#########9| 63.3M/63.6M [00:03<00:00, 21.9MB/s]
100%|##########| 63.6M/63.6M [00:03<00:00, 16.7MB/s]
tensor([[54, 20, 65, 69, 11, 92, 44, 65, 38, 2, 11, 81, 40, 64, 79, 81, 11, 81,
20, 11, 79, 77, 59, 37, 2]])
tensor([25], dtype=torch.int32)
Notice that the encoded values are different from the example of character-based encoding.
The intermediate representation looks like the following.
['HH', 'AH', 'L', 'OW', ' ', 'W', 'ER', 'L', 'D', '!', ' ', 'T', 'EH', 'K', 'S', 'T', ' ', 'T', 'AH', ' ', 'S', 'P', 'IY', 'CH', '!']
Spectrogram Generation
Tacotron2 is the model we use to generate spectrogram from the
encoded text. For the detail of the model, please refer to the
paper.
It is easy to instantiate a Tacotron2 model with pretrained weight, however, note that the input to Tacotron2 models need to be processed by the matching text processor.
torchaudio.pipelines.Tacotron2TTSBundle bundles the matching
models and processors together so that it is easy to create the pipeline.
For the available bundles, and its usage, please refer to
Tacotron2TTSBundle.
bundle = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH
processor = bundle.get_text_processor()
tacotron2 = bundle.get_tacotron2().to(device)
text = "Hello world! Text to speech!"
with torch.inference_mode():
processed, lengths = processor(text)
processed = processed.to(device)
lengths = lengths.to(device)
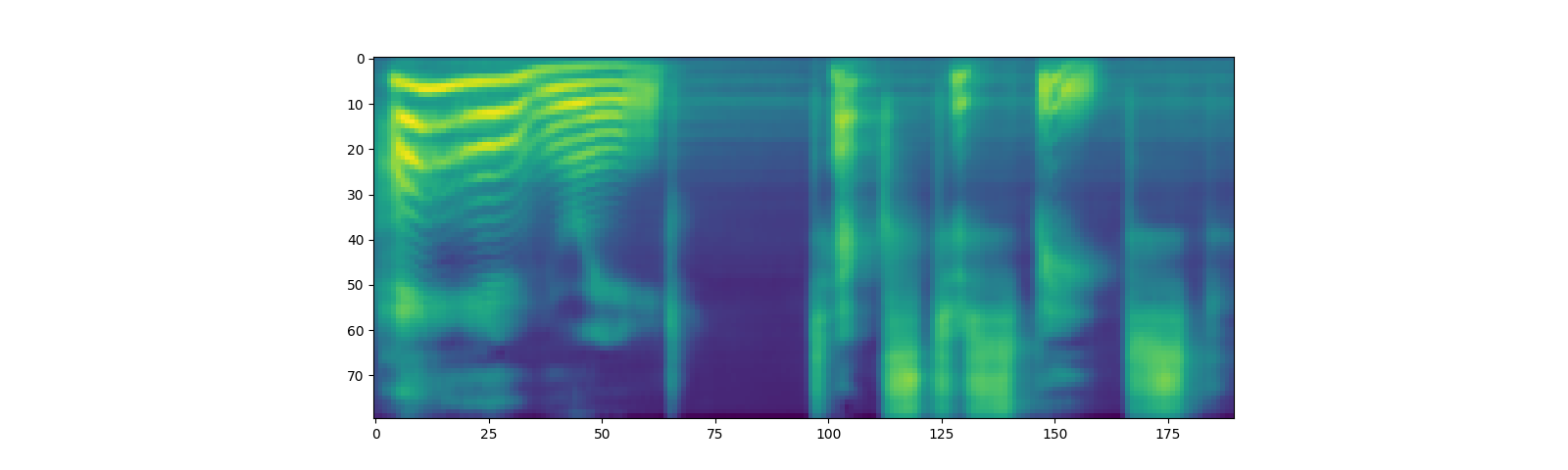
spec, _, _ = tacotron2.infer(processed, lengths)
_ = plt.imshow(spec[0].cpu().detach())
Downloading: "https://download.pytorch.org/torchaudio/models/tacotron2_english_phonemes_1500_epochs_wavernn_ljspeech.pth" to /root/.cache/torch/hub/checkpoints/tacotron2_english_phonemes_1500_epochs_wavernn_ljspeech.pth
0%| | 0.00/107M [00:00<?, ?B/s]
36%|###6 | 38.9M/107M [00:00<00:00, 408MB/s]
73%|#######3 | 78.6M/107M [00:00<00:00, 413MB/s]
100%|##########| 107M/107M [00:00<00:00, 411MB/s]
Note that Tacotron2.infer method perfoms multinomial sampling,
therefor, the process of generating the spectrogram incurs randomness.
torch.Size([80, 155])
torch.Size([80, 167])
torch.Size([80, 164])
Waveform Generation
Once the spectrogram is generated, the last process is to recover the waveform from the spectrogram.
torchaudio provides vocoders based on GriffinLim and
WaveRNN.
WaveRNN
Continuing from the previous section, we can instantiate the matching WaveRNN model from the same bundle.
bundle = torchaudio.pipelines.TACOTRON2_WAVERNN_PHONE_LJSPEECH
processor = bundle.get_text_processor()
tacotron2 = bundle.get_tacotron2().to(device)
vocoder = bundle.get_vocoder().to(device)
text = "Hello world! Text to speech!"
with torch.inference_mode():
processed, lengths = processor(text)
processed = processed.to(device)
lengths = lengths.to(device)
spec, spec_lengths, _ = tacotron2.infer(processed, lengths)
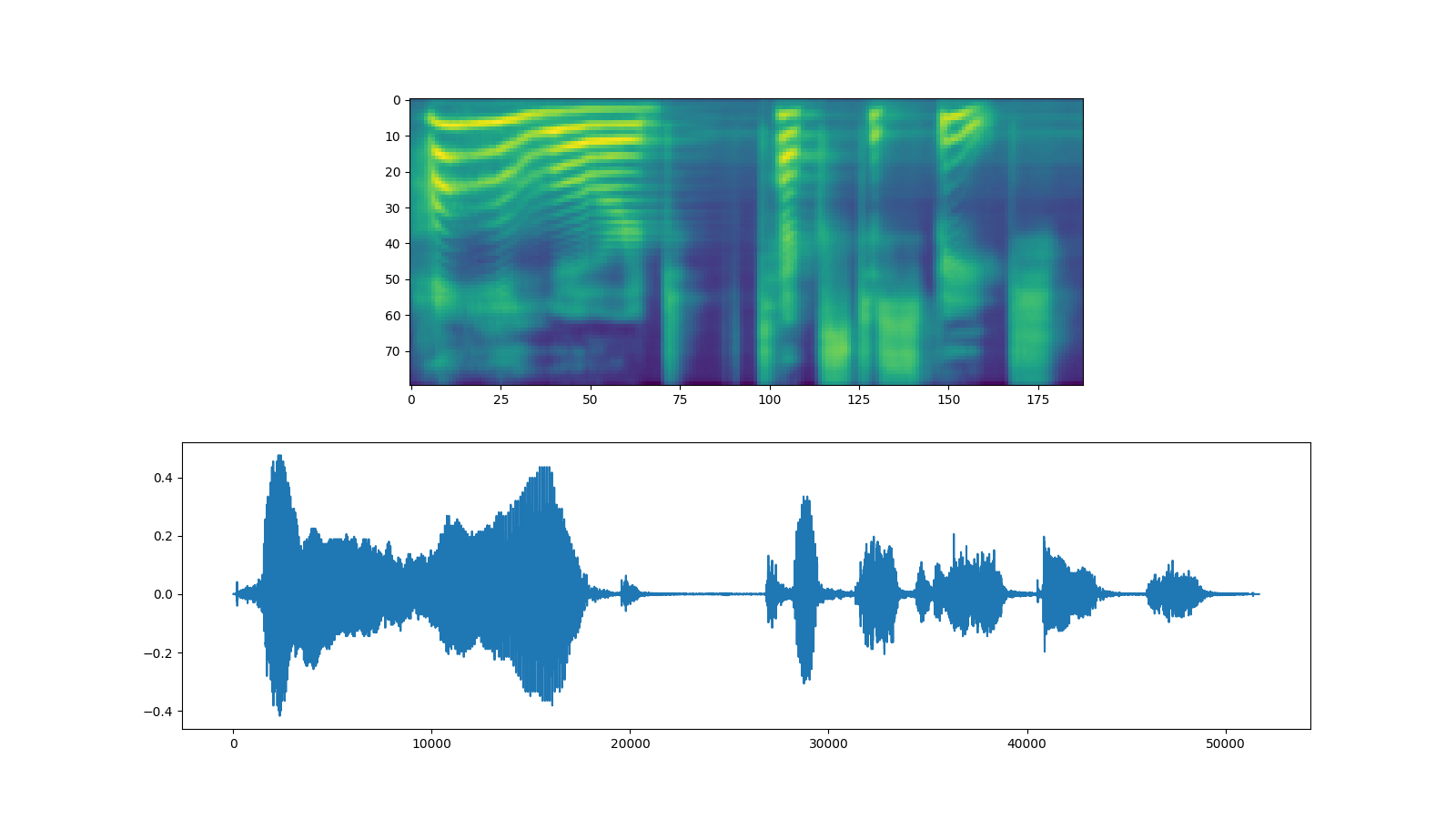
waveforms, lengths = vocoder(spec, spec_lengths)
fig, [ax1, ax2] = plt.subplots(2, 1, figsize=(16, 9))
ax1.imshow(spec[0].cpu().detach())
ax2.plot(waveforms[0].cpu().detach())
IPython.display.Audio(waveforms[0:1].cpu(), rate=vocoder.sample_rate)
Downloading: "https://download.pytorch.org/torchaudio/models/wavernn_10k_epochs_8bits_ljspeech.pth" to /root/.cache/torch/hub/checkpoints/wavernn_10k_epochs_8bits_ljspeech.pth
0%| | 0.00/16.7M [00:00<?, ?B/s]
100%|##########| 16.7M/16.7M [00:00<00:00, 398MB/s]
Griffin-Lim
Using the Griffin-Lim vocoder is same as WaveRNN. You can instantiate
the vocode object with
get_vocoder()
method and pass the spectrogram.
bundle = torchaudio.pipelines.TACOTRON2_GRIFFINLIM_PHONE_LJSPEECH
processor = bundle.get_text_processor()
tacotron2 = bundle.get_tacotron2().to(device)
vocoder = bundle.get_vocoder().to(device)
with torch.inference_mode():
processed, lengths = processor(text)
processed = processed.to(device)
lengths = lengths.to(device)
spec, spec_lengths, _ = tacotron2.infer(processed, lengths)
waveforms, lengths = vocoder(spec, spec_lengths)
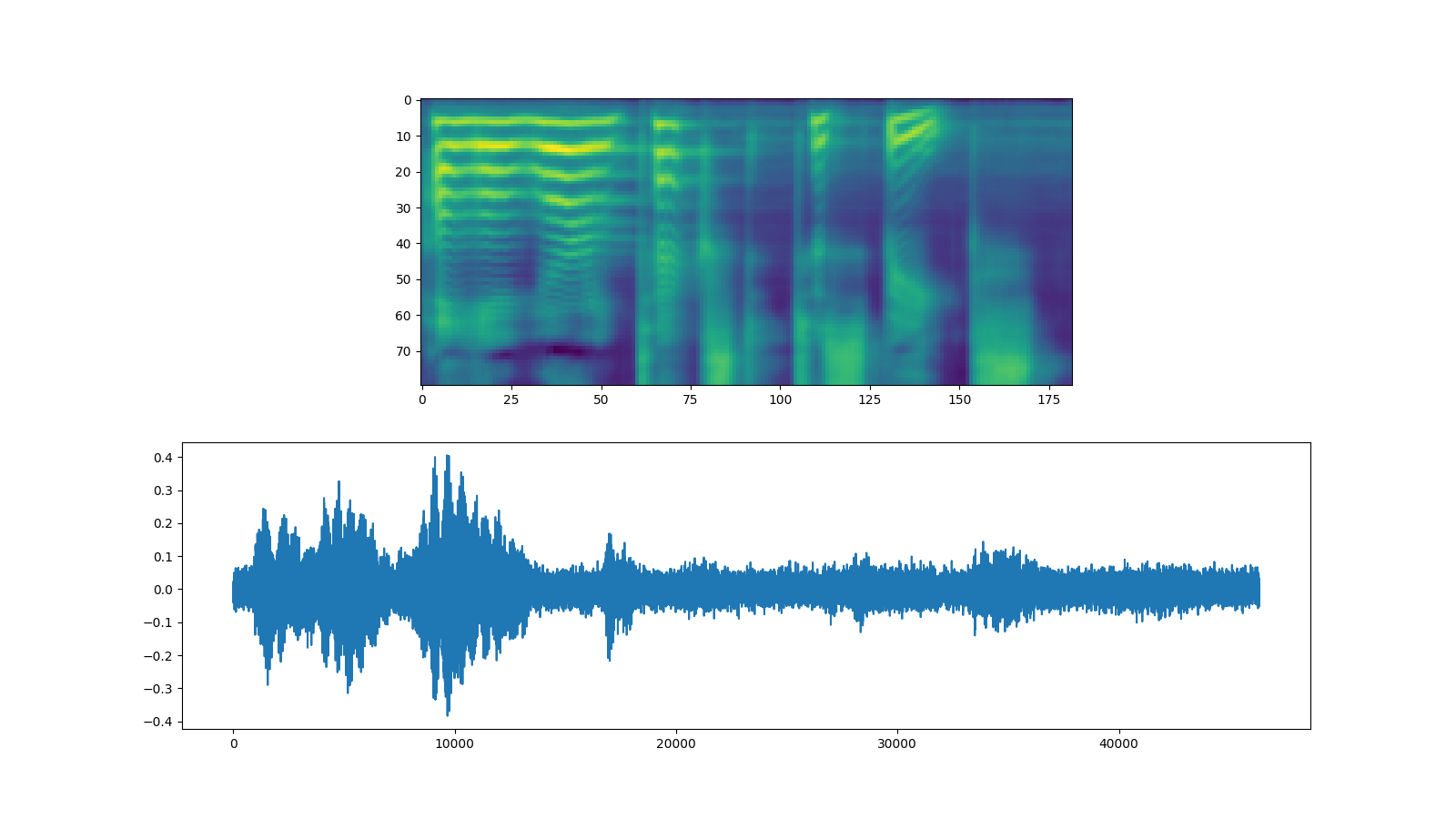
fig, [ax1, ax2] = plt.subplots(2, 1, figsize=(16, 9))
ax1.imshow(spec[0].cpu().detach())
ax2.plot(waveforms[0].cpu().detach())
IPython.display.Audio(waveforms[0:1].cpu(), rate=vocoder.sample_rate)
Downloading: "https://download.pytorch.org/torchaudio/models/tacotron2_english_phonemes_1500_epochs_ljspeech.pth" to /root/.cache/torch/hub/checkpoints/tacotron2_english_phonemes_1500_epochs_ljspeech.pth
0%| | 0.00/107M [00:00<?, ?B/s]
39%|###9 | 41.9M/107M [00:00<00:00, 440MB/s]
79%|#######9 | 85.4M/107M [00:00<00:00, 449MB/s]
100%|##########| 107M/107M [00:00<00:00, 446MB/s]
Waveglow
Waveglow is a vocoder published by Nvidia. The pretrained weights are
published on Torch Hub. One can instantiate the model using torch.hub
module.
# Workaround to load model mapped on GPU
# https://stackoverflow.com/a/61840832
waveglow = torch.hub.load(
"NVIDIA/DeepLearningExamples:torchhub",
"nvidia_waveglow",
model_math="fp32",
pretrained=False,
)
checkpoint = torch.hub.load_state_dict_from_url(
"https://api.ngc.nvidia.com/v2/models/nvidia/waveglowpyt_fp32/versions/1/files/nvidia_waveglowpyt_fp32_20190306.pth", # noqa: E501
progress=False,
map_location=device,
)
state_dict = {key.replace("module.", ""): value for key, value in checkpoint["state_dict"].items()}
waveglow.load_state_dict(state_dict)
waveglow = waveglow.remove_weightnorm(waveglow)
waveglow = waveglow.to(device)
waveglow.eval()
with torch.no_grad():
waveforms = waveglow.infer(spec)
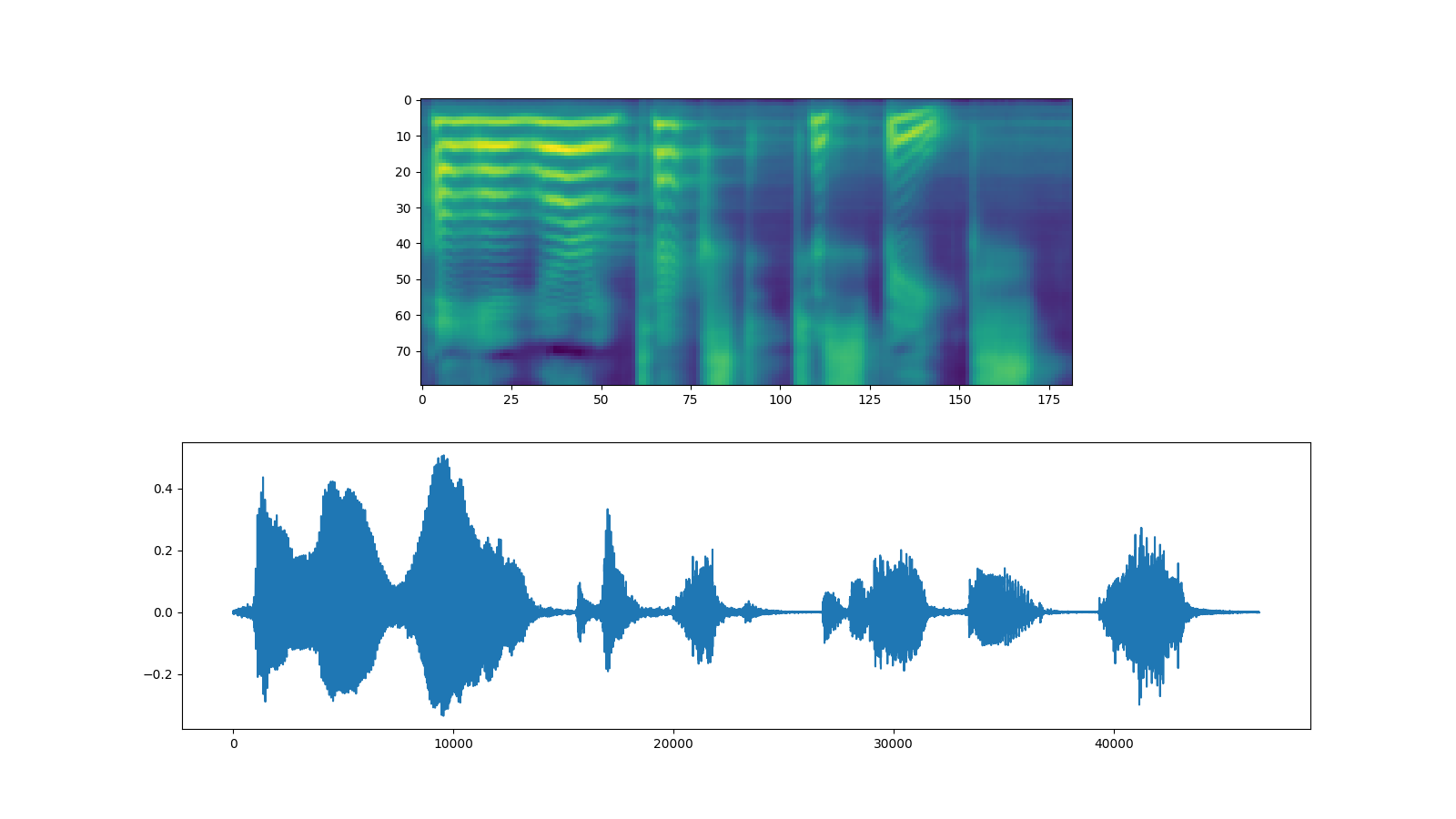
fig, [ax1, ax2] = plt.subplots(2, 1, figsize=(16, 9))
ax1.imshow(spec[0].cpu().detach())
ax2.plot(waveforms[0].cpu().detach())
IPython.display.Audio(waveforms[0:1].cpu(), rate=22050)
/usr/local/envs/python3.8/lib/python3.8/site-packages/torch/hub.py:267: UserWarning: You are about to download and run code from an untrusted repository. In a future release, this won't be allowed. To add the repository to your trusted list, change the command to {calling_fn}(..., trust_repo=False) and a command prompt will appear asking for an explicit confirmation of trust, or load(..., trust_repo=True), which will assume that the prompt is to be answered with 'yes'. You can also use load(..., trust_repo='check') which will only prompt for confirmation if the repo is not already trusted. This will eventually be the default behaviour
warnings.warn(
Downloading: "https://github.com/NVIDIA/DeepLearningExamples/zipball/torchhub" to /root/.cache/torch/hub/torchhub.zip
/root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub/PyTorch/Classification/ConvNets/image_classification/models/common.py:13: UserWarning: pytorch_quantization module not found, quantization will not be available
warnings.warn(
/root/.cache/torch/hub/NVIDIA_DeepLearningExamples_torchhub/PyTorch/Classification/ConvNets/image_classification/models/efficientnet.py:17: UserWarning: pytorch_quantization module not found, quantization will not be available
warnings.warn(
Downloading: "https://api.ngc.nvidia.com/v2/models/nvidia/waveglowpyt_fp32/versions/1/files/nvidia_waveglowpyt_fp32_20190306.pth" to /root/.cache/torch/hub/checkpoints/nvidia_waveglowpyt_fp32_20190306.pth
Total running time of the script: ( 2 minutes 32.893 seconds)
