


Note
Click here to download the full example code
Online ASR with Emformer RNN-T¶
Author: Jeff Hwang, Moto Hira
This tutorial shows how to use Emformer RNN-T and streaming API to perform online speech recognition.
Note
This tutorial requires FFmpeg libraries (>=4.1, <4.4) and SentencePiece.
There are multiple ways to install FFmpeg libraries.
If you are using Anaconda Python distribution,
conda install 'ffmpeg<4.4' will install
the required FFmpeg libraries.
You can install SentencePiece by running pip install sentencepiece.
1. Overview¶
Performing online speech recognition is composed of the following steps
Build the inference pipeline Emformer RNN-T is composed of three components: feature extractor, decoder and token processor.
Format the waveform into chunks of expected sizes.
Pass data through the pipeline.
2. Preparation¶
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
1.13.0
0.13.0
import IPython
try:
from torchaudio.io import StreamReader
except ModuleNotFoundError:
try:
import google.colab
print(
"""
To enable running this notebook in Google Colab, install the requisite
third party libraries by running the following code block:
!add-apt-repository -y ppa:savoury1/ffmpeg4
!apt-get -qq install -y ffmpeg
"""
)
except ModuleNotFoundError:
pass
raise
3. Construct the pipeline¶
Pre-trained model weights and related pipeline components are
bundled as torchaudio.pipelines.RNNTBundle.
We use torchaudio.pipelines.EMFORMER_RNNT_BASE_LIBRISPEECH,
which is a Emformer RNN-T model trained on LibriSpeech dataset.
bundle = torchaudio.pipelines.EMFORMER_RNNT_BASE_LIBRISPEECH
feature_extractor = bundle.get_streaming_feature_extractor()
decoder = bundle.get_decoder()
token_processor = bundle.get_token_processor()
0%| | 0.00/3.81k [00:00<?, ?B/s]
100%|##########| 3.81k/3.81k [00:00<00:00, 3.16MB/s]
0%| | 0.00/293M [00:00<?, ?B/s]
13%|#3 | 38.9M/293M [00:00<00:00, 407MB/s]
28%|##7 | 81.3M/293M [00:00<00:00, 429MB/s]
42%|####1 | 122M/293M [00:00<00:00, 418MB/s]
55%|#####5 | 162M/293M [00:00<00:00, 419MB/s]
70%|######9 | 204M/293M [00:00<00:00, 426MB/s]
84%|########4 | 247M/293M [00:00<00:00, 432MB/s]
99%|#########8| 289M/293M [00:00<00:00, 438MB/s]
100%|##########| 293M/293M [00:00<00:00, 428MB/s]
0%| | 0.00/295k [00:00<?, ?B/s]
100%|##########| 295k/295k [00:00<00:00, 98.4MB/s]
Streaming inference works on input data with overlap. Emformer RNN-T model treats the newest portion of the input data as the “right context” — a preview of future context. In each inference call, the model expects the main segment to start from this right context from the previous inference call. The following figure illustrates this.
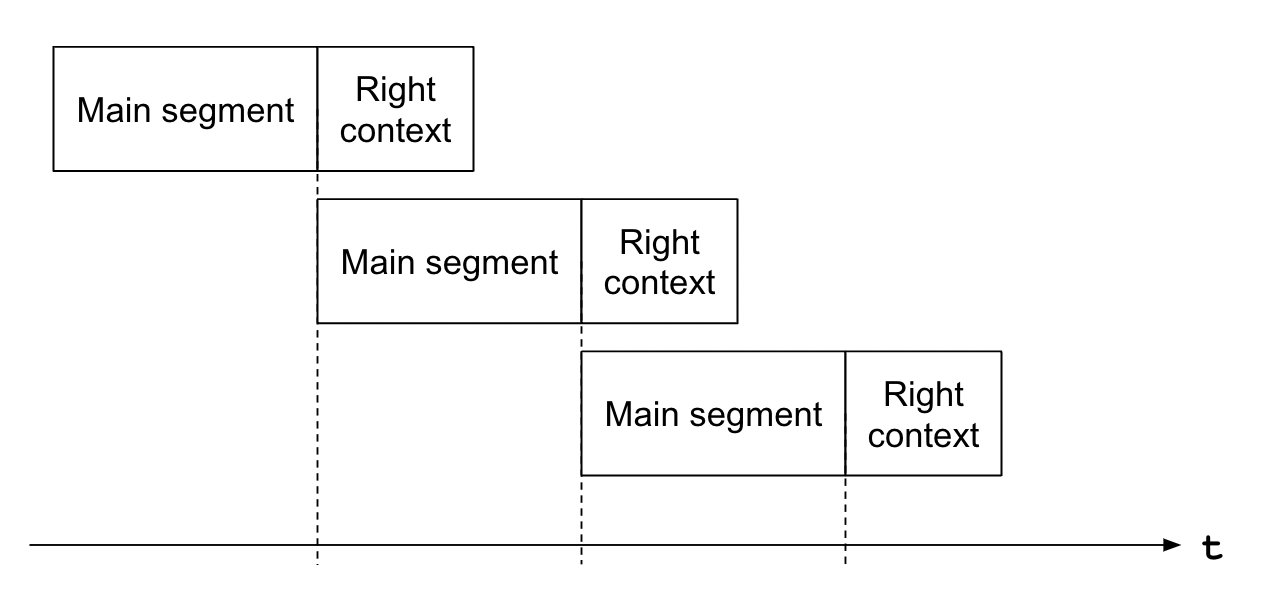
The size of main segment and right context, along with the expected sample rate can be retrieved from bundle.
sample_rate = bundle.sample_rate
segment_length = bundle.segment_length * bundle.hop_length
context_length = bundle.right_context_length * bundle.hop_length
print(f"Sample rate: {sample_rate}")
print(f"Main segment: {segment_length} frames ({segment_length / sample_rate} seconds)")
print(f"Right context: {context_length} frames ({context_length / sample_rate} seconds)")
Sample rate: 16000
Main segment: 2560 frames (0.16 seconds)
Right context: 640 frames (0.04 seconds)
4. Configure the audio stream¶
Next, we configure the input audio stream using torchaudio.io.StreamReader.
For the detail of this API, please refer to the StreamReader Basic Usage.
The following audio file was originally published by LibriVox project, and it is in the public domain.
https://librivox.org/great-pirate-stories-by-joseph-lewis-french/
It was re-uploaded for the sake of the tutorial.
src = "https://download.pytorch.org/torchaudio/tutorial-assets/greatpiratestories_00_various.mp3"
streamer = StreamReader(src)
streamer.add_basic_audio_stream(frames_per_chunk=segment_length, sample_rate=bundle.sample_rate)
print(streamer.get_src_stream_info(0))
print(streamer.get_out_stream_info(0))
StreamReaderSourceAudioStream(media_type='audio', codec='mp3', codec_long_name='MP3 (MPEG audio layer 3)', format='fltp', bit_rate=128000, num_frames=0, bits_per_sample=0, metadata={}, sample_rate=44100.0, num_channels=2)
StreamReaderOutputStream(source_index=0, filter_description='aresample=16000,aformat=sample_fmts=fltp')
As previously explained, Emformer RNN-T model expects input data with overlaps; however, Streamer iterates the source media without overlap, so we make a helper structure that caches a part of input data from Streamer as right context and then appends it to the next input data from Streamer.
The following figure illustrates this.
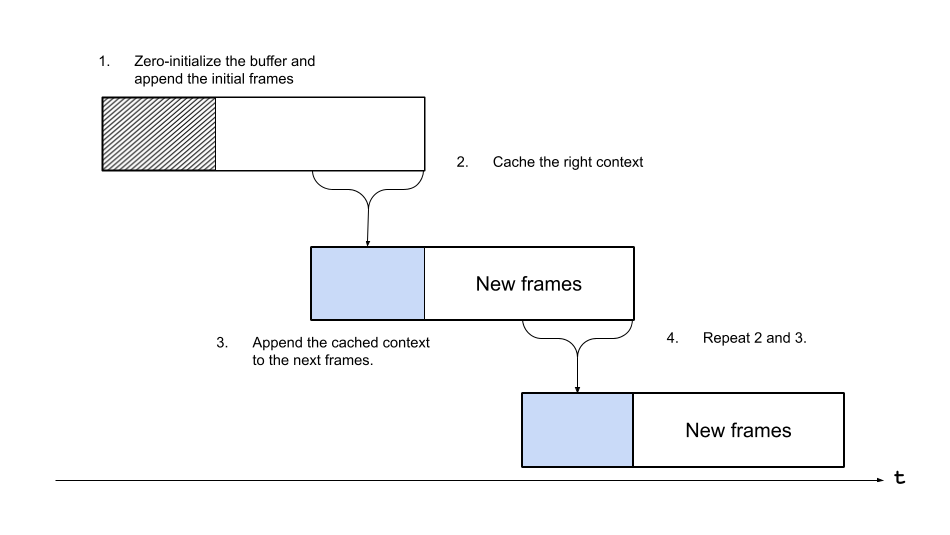
class ContextCacher:
"""Cache the end of input data and prepend the next input data with it.
Args:
segment_length (int): The size of main segment.
If the incoming segment is shorter, then the segment is padded.
context_length (int): The size of the context, cached and appended.
"""
def __init__(self, segment_length: int, context_length: int):
self.segment_length = segment_length
self.context_length = context_length
self.context = torch.zeros([context_length])
def __call__(self, chunk: torch.Tensor):
if chunk.size(0) < self.segment_length:
chunk = torch.nn.functional.pad(chunk, (0, self.segment_length - chunk.size(0)))
chunk_with_context = torch.cat((self.context, chunk))
self.context = chunk[-self.context_length :]
return chunk_with_context
5. Run stream inference¶
Finally, we run the recognition.
First, we initialize the stream iterator, context cacher, and state and hypothesis that are used by decoder to carry over the decoding state between inference calls.
cacher = ContextCacher(segment_length, context_length)
state, hypothesis = None, None
Next we, run the inference.
For the sake of better display, we create a helper function which processes the source stream up to the given times and call it repeatedly.
stream_iterator = streamer.stream()
@torch.inference_mode()
def run_inference(num_iter=200):
global state, hypothesis
chunks = []
for i, (chunk,) in enumerate(stream_iterator, start=1):
segment = cacher(chunk[:, 0])
features, length = feature_extractor(segment)
hypos, state = decoder.infer(features, length, 10, state=state, hypothesis=hypothesis)
hypothesis = hypos[0]
transcript = token_processor(hypothesis[0], lstrip=False)
print(transcript, end="", flush=True)
chunks.append(chunk)
if i == num_iter:
break
return IPython.display.Audio(torch.cat(chunks).T.numpy(), rate=bundle.sample_rate)
run_inference()
forward great pirate's this is aver's recording all thects recordings are in the public dum for more information or please visit liberg recording by james christopher great pirite stories by various edited by josey embodies the romance of theed expression it is a sad but inevable comment on our civilization that so far as the sea is concerned
run_inference()
it is developed from its infancy down to a century or so ago under one phase or another of pircy if men were savages on land they were doubly so at sea and all the years oftime adventure years that added to theap world there was little left to discover could not wholly eradate theat germ it went out gradually with the settlement of the farmed colonies great britain foremost of sea powers must be credit both directly and indirely for theation of crime and disord on the high seas than any other
run_inference()
force but the conquest was not complete till the advent the sea rover into the farthest corners of his domini it is said that he survised even to day in certain spots in the chinese but he is certainly an innocuous rolle a pir of any sort would be as great a curiosity to day if he could be caught and exhibited as a fab's the fact remains and will always persist that in theore of the sea he is far away the most picturesque figure in the more genuine and gross his character the higher degree of interest as he inspire there
run_inference()
may be a certain perversity in this for the pirate was unquestionably a bad man at his best or worst consid his surrene's andtily the worst man that ever lived there is little to soften the dark yet glowing picture of his explox but again it must be remembered that not only does the note of distant subdu and even lend a certain enchantment to the scene but the effective contrast between our peaceful times andributes much to deepen our interest in him perhaps it is this latter added to that death waspen breast that
run_inference()
glows at the tale of adventure which makes them the kind of hero of romance that is today he is undeni redoubtable historical figure it is a curious fact that commerce was crad in the lapane the constant danger of the deeps in this form only made heartier marin of the merchras actually stimating and strenuing maritime enterprise bucco turned for piry thus became the high romance of the sea the great centuries ofton venture it went hand in hand with disco
run_inference()
very they were in fact almost insepar most of mighty mariners from the days of leafou through those of the redoubtable sir francis drakeke down to our owns answered to the roll it was a bold hearty world this avarice up to the advent our giant steam every foot of which was won by fierce conquest of one sort or another out of this pass the pir emerges are romantic even at times heroic figure this final niche despite his crimes cannot altogether be denied a heroi is and all remained
run_inference()
so long as tales of the are told so have him in these pages joseth lewich and of four recording by james christopher jist christ christopher yah come
Tag: torchaudio.io
Total running time of the script: ( 0 minutes 58.257 seconds)
