ExecuTorch Runtime Overview
This document discusses the design of the ExecuTorch runtime, which executes
ExecuTorch program files on edge devices like smartphones, wearables, and
embedded devices. The code for the main execution API is under
executorch/runtime/executor/.
Before reading this document we recommend that you read How ExecuTorch Works.
At the highest level, the ExecuTorch runtime is responsible for:
Loading binary
.pteprogram files that were generated by theto_executorch()step of the model-lowering process.Executing the series of instructions that implement a lowered model.
Note that as of late 2023, the ExecuTorch runtime only supports model inference, and does not yet support training.
This diagram shows the high-level flow of, and components involved with, exporting and executing an ExecuTorch program:
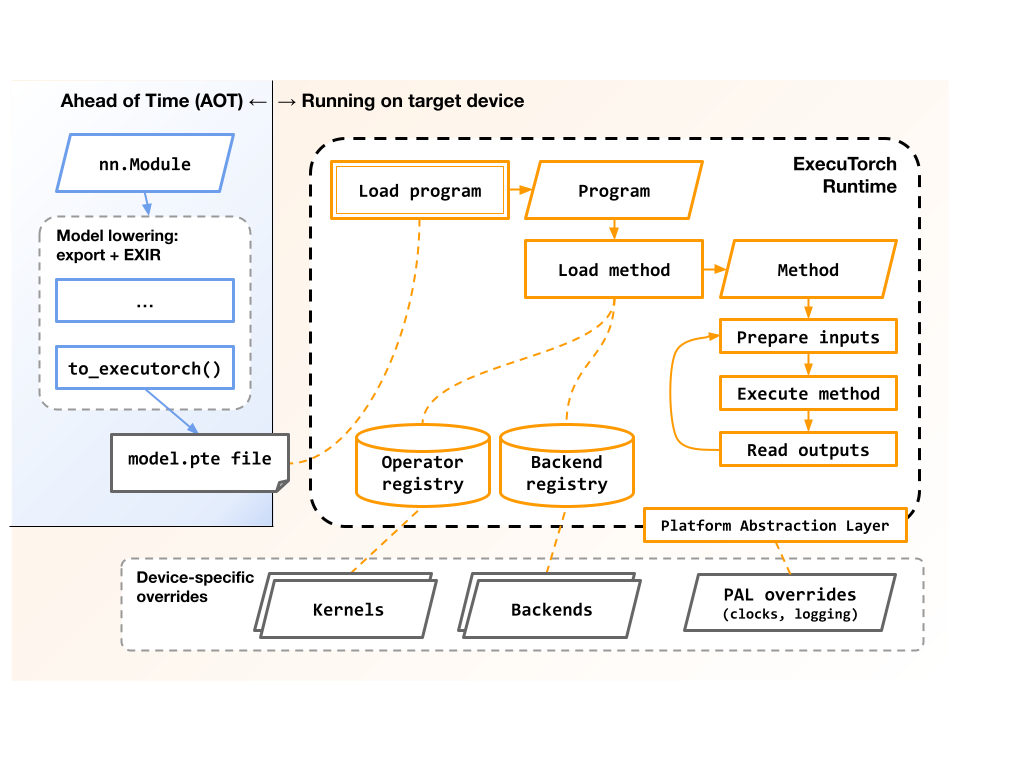
The runtime is also responsible for:
Managing the memory used during load and execution, potentially across multiple memory banks like SRAM and DRAM.
Mapping symbolic operator names like
"aten::add.out"to concrete C++ functions or kernels that implement the semantics of those operators.Dispatching predetermined sections of the model to backend delegates for acceleration.
Optionally gathering profiling data during load and execution.
Design Goals
The ExecuTorch runtime was designed to run on a wide variety of edge devices, from modern smartphone CPUs to resource-constrained microcontrollers and DSPs. It has first-class support for delegating execution to one or more backends to take advantage of architecture-specific optimizations and modern heterogeneous architectures. It is small and portable enough to run directly in bare-metal embedded environments with no operating systems, dynamic memory, or threads.
Low Execution Overhead
Memory
The core runtime library is less than 50kB when built without kernels or backends.
Constant tensors point directly into the
.ptefile data, avoiding copies of that data. The alignment of these data chunks can be adjusted at.ptecreation time.Backend delegates can choose to unload their precompiled data after model initialization, reducing peak memory usage.
Mutable tensor memory layout is planned ahead of time and packed into a small set of user-allocated buffers, providing fine-grained control over memory location. This is especially useful on systems with heterogeneous memory hierarchies, allowing placement onto (e.g.) SRAM or DRAM close to the core that will operate on the data.
CPU
Model execution is a simple loop over an array of instructions, most of which are function pointers to kernels and backend delegates. This keeps the execution overhead small, on the order of microseconds to nanoseconds per operation.
The implementation of an operation (like “add” or “conv3d”) can be fully customized for a particular target system without needing to modify the original model or generated
.ptefile.
Familiar PyTorch Semantics
ExecuTorch is a first-class component of the PyTorch stack, and reuses APIs and semantics whenever possible.
The C++ types used by ExecuTorch are source-compatible with the corresponding types from core PyTorch’s
c10::andat::libraries, and ExecuTorch providesaten_bridgeto convert between the two. This can be helpful for projects that already use PyTorch C++ types.The semantics of operators like
aten::addandaten::sigmoidare identical between ExecuTorch and core PyTorch. ExecuTorch provides a testing framework to ensure this, and to help test future implementations of these operators.
Portable Code and Architecture
The ExecuTorch runtime is implemented with portability in mind, so that users can build it for a wide variety of target systems.
C++ Language Considerations
The code is C++17-compatible to work with older toolchains.
The runtime does not use exceptions or RTTI, although it is not antagonistic to them.
The code is compatible with GCC and Clang, and has also been built with several proprietary embedded toolchains.
The repo provides CMake build system to make integration easier.
Operating System Considerations
The runtime makes no direct system calls. All access to memory, files, logging,
and clocks are abstracted through the Runtime Platform Abstraction Layer
(PAL) and injected interfaces like
DataLoader and MemoryAllocator. See the runtime api reference to learn more.
Applications can control all memory allocation through the MemoryManager,
MemoryAllocator, HierarchicalAllocator, and DataLoader classes. The core
runtime makes no direct calls to malloc() or new, or to types like
std::vector that allocate under the hood. This makes it possible to:
Run in environments without a heap, but still use the heap if desired.
Avoid synchronization on the heap during model load and execution.
Control which memory region to use for different types of data. For example, one set of mutable tensors could live in SRAM while another set lived in DRAM.
Easily monitor how much memory the runtime uses.
However, please note that specific kernel or backend implementations may use arbitrary runtime or operating system features. Users should double-check the docs for the kernel and backend libraries that they use.
Threading Considerations
The core runtime does no threading or locking, and does not use thread local variables. But, it plays well with higher-level synchronization.
Each
Programinstance is immutable and therefore fully thread-safe. Multiple threads may concurrently access a singlePrograminstance.Each
Methodinstance is mutable but self-contained, and therefore conditionally thread-safe. Multiple threads can concurrently access and execute independentMethodinstances, but access and execution of a single instance must be serialized.
However, please note:
There are two global tables that may be read during
Program::load_method(): the kernel registration table and the backend registration table.In practice, these tables are only modified at process/system load time, and are effectively frozen before the first
Programis loaded. But some applications may need to be aware of these tables, especially if they manually mutate them after process/system load time.
Specific kernel or backend implementations may have their own threading restrictions. Users should double-check the docs for the kernel and backend libraries that they use.
