Quantization Overview
Quantization is a process that reduces the precision of computations and lowers memory footprint in the model. To learn more, please visit the ExecuTorch concepts page. This is particularly useful for edge devices including wearables, embedded devices and microcontrollers, which typically have limited resources such as processing power, memory, and battery life. By using quantization, we can make our models more efficient and enable them to run effectively on these devices.
In terms of flow, quantization happens early in the ExecuTorch stack:
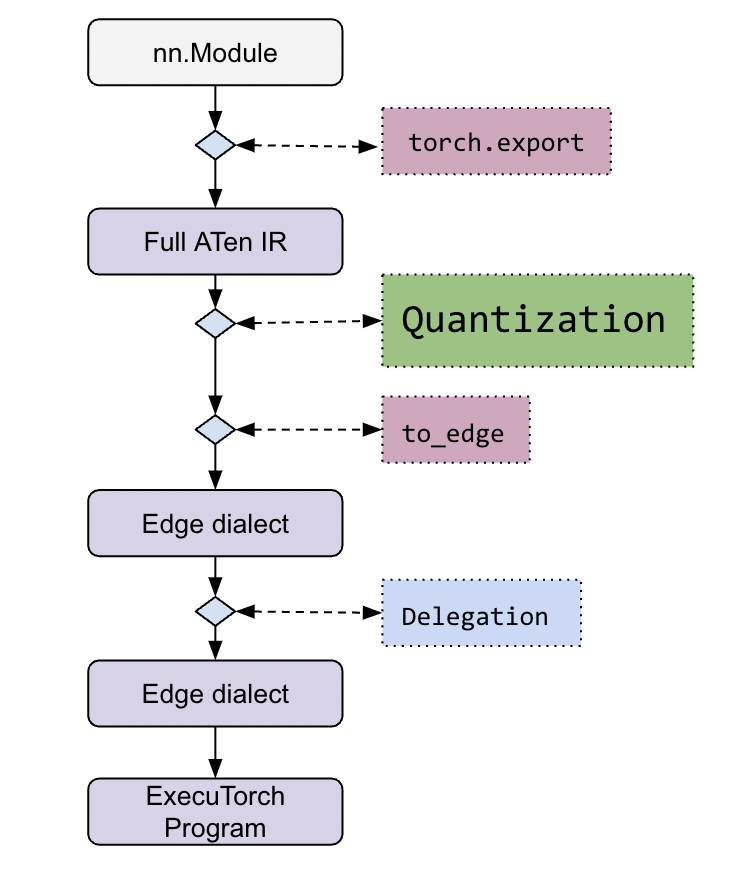
A more detailed workflow can be found in the ExecuTorch tutorial.
Quantization is usually tied to execution backends that have quantized operators implemented. Thus each backend is opinionated about how the model should be quantized, expressed in a backend specific Quantizer class. Quantizer provides API for modeling users in terms of how they want their model to be quantized and also passes on the user intention to quantization workflow.
Backend developers will need to implement their own Quantizer to express how different operators or operator patterns are quantized in their backend. This is accomplished via Annotation API provided by quantization workflow. Since Quantizer is also user facing, it will expose specific APIs for modeling users to configure how they want the model to be quantized. Each backend should provide their own API documentation for their Quantizer.
Modeling users will use the Quantizer specific to their target backend to quantize their model, e.g. XNNPACKQuantizer.
For an example quantization flow with XNPACKQuantizer, more documentation and tutorials, please see Performing Quantization section in ExecuTorch tutorial.
Source Quantization: Int8DynActInt4WeightQuantizer
In addition to export based quantization (described above), ExecuTorch wants to highlight source based quantizations, accomplished via torchao. Unlike export based quantization, source based quantization directly modifies the model prior to export. One specific example is Int8DynActInt4WeightQuantizer.
This scheme represents 4-bit weight quantization with 8-bit dynamic quantization of activation during inference.
Imported with from torchao.quantization.quant_api import Int8DynActInt4WeightQuantizer, this class uses a quantization instance constructed with a specified dtype precision and groupsize, to mutate a provided nn.Module.
# Source Quant
from torchao.quantization.quant_api import Int8DynActInt4WeightQuantizer
model = Int8DynActInt4WeightQuantizer(precision=torch_dtype, groupsize=group_size).quantize(model)
# Export to ExecuTorch
from executorch.exir import to_edge
from torch.export import export
exported_model = export(model, ...)
et_program = to_edge(exported_model, ...).to_executorch(...)
