Distilling Llama3.1 8B into Llama3.2 1B using Knowledge Distillation
This guide will teach you about knowledge distillation (KD) and show you how you can use torchtune to distill a Llama3.1 8B model into Llama3.2 1B. If you already know what knowledge distillation is and want to get straight to running your own distillation in torchtune, you can jump to the KD recipe in torchtune tutorial.
What KD is and how it can help improve model performance
An overview of KD components in torchtune
How to distill from a teacher to student model using torchtune
How to experiment with different KD configurations
Be familiar with torchtune
Make sure to install torchtune
Make sure you have downloaded the Llama3 model weights
Be familiar with LoRA
What is Knowledge Distillation?
Knowledge Distillation is a widely used compression technique that transfers knowledge from a larger (teacher) model to a smaller (student) model. Larger models have more parameters and capacity for knowledge, however, this larger capacity is also more computationally expensive to deploy. Knowledge distillation can be used to compress the knowledge of a larger model into a smaller model. The idea is that performance of smaller models can be improved by learning from larger model’s outputs.
How does Knowledge Distillation work?
Knowledge is transferred from the teacher to student model by training it on a transfer set where the student is trained to imitate the token-level probability distributions of the teacher. The diagram below is a simplified representation of how KD works.
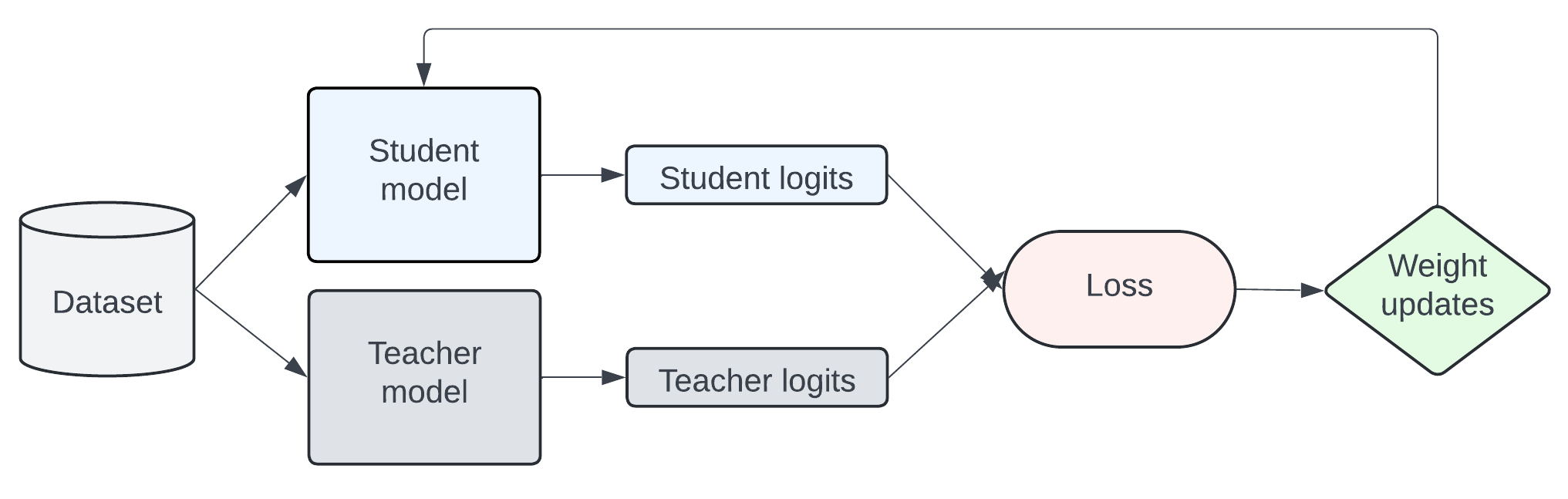
The total loss can be configured in many ways. The default KD config in torchtune combines the cross-entropy (CE) loss with the forward Kullback-Leibler (KL) divergence loss, which is used in standard KD approaches. Forward KL divergence aims to minimize the difference by forcing the student’s distribution to align with all of the teacher’s distributions. However, aligning the student distribution to the whole teacher distribution may not be effective and there are multiple papers, such as MiniLLM, DistiLLM, and Generalized KD, that introduce new KD losses to address the limitations. For this tutorial, let’s take a look at the implementation of the forward KL divergence loss.
import torch
import torch.nn.functional as F
class ForwardKLLoss(torch.nn.Module):
def __init__(self, ignore_index: int = -100)
super().__init__()
self.ignore_index = ignore_index
def forward(self, student_logits, teacher_logits, labels) -> torch.Tensor:
# Implementation from https://github.com/jongwooko/distillm
# Computes the softmax of the teacher logits
teacher_prob = F.softmax(teacher_logits, dim=-1, dtype=torch.float32)
# Computes the student log softmax probabilities
student_logprob = F.log_softmax(student_logits, dim=-1, dtype=torch.float32)
# Computes the forward KL divergence
prod_probs = teacher_prob * student_logprob
# Compute the sum
x = torch.sum(prod_probs, dim=-1).view(-1)
# We don't want to include the ignore labels in the average
mask = (labels != self.ignore_index).int()
# Loss is averaged over non-ignored targets
return -torch.sum(x * mask.view(-1), dim=0) / torch.sum(mask.view(-1), dim=0)
There are some details omitted to simplify the computation, but if you’d like to know more,
you can see the implementation in ForwardKLLoss.
By default, the KD configs use ForwardKLWithChunkedOutputLoss to reduce memory.
The current implementation only supports student and teacher models that have the same output
logit shape and same tokenizer.
KD recipe in torchtune
With torchtune, we can easily apply knowledge distillation to Llama3, as well as other LLM model families. Let’s take a look at how you could distill a model using torchtune’s KD recipe.
First, make sure that you have downloaded all the model weights. For this example, we’ll use the Llama3.1-8B as teacher and Llama3.2-1B as student.
tune download meta-llama/Meta-Llama-3.1-8B-Instruct --output-dir /tmp/Meta-Llama-3.1-8B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
tune download meta-llama/Llama-3.2-1B-Instruct --output-dir /tmp/Llama-3.2-1B-Instruct --ignore-patterns "original/consolidated.00.pth" --hf_token <HF_TOKEN>
Then, we will fine-tune the teacher model using LoRA. Based on our experiments and previous work, we’ve found that KD performs better when the teacher model is already fine-tuned on the target dataset.
tune run lora_finetune_single_device --config llama3_1/8B_lora_single_device
Finally, we can run the following command to distill the fine-tuned 8B model into the 1B model on a single GPU.
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device
Ablation studies
In the previous example, we used the LoRA fine-tuned 8B teacher model and baseline 1B student model,
but we may want to experiment a bit with different configurations and hyperparameters.
For this tutorial, we are going to fine-tune on the alpaca_cleaned_dataset
and evaluate the models on truthfulqa_mc2,
hellaswag
and commonsense_qa tasks
through the EleutherAI LM evaluation harness.
Let’s take a look at the effects of:
Using a fine-tuned teacher model
Using a fine-tuned student model
Hyperparameter tuning of kd_ratio and learning rate
Teacher and student models with closer number of parameters
Using a fine-tuned teacher model
The default settings in the config uses the fine-tuned teacher model. Now, let’s take a look at the
effects of not fine-tuning the teacher model first. To change the teacher model, you can modify the
teacher_checkpointer in the config:
teacher_checkpointer:
_component_: torchtune.training.FullModelHFCheckpointer
checkpoint_dir: /tmp/Meta-Llama-3.1-8B-Instruct/
checkpoint_files: [
model-00001-of-00004.safetensors,
model-00002-of-00004.safetensors,
model-00003-of-00004.safetensors,
model-00004-of-00004.safetensors
]
In the table below, we can see that standard fine-tuning of the 1B model achieves better accuracy than the baseline 1B model. By using the fine-tuned 8B teacher model, we see comparable results for truthfulqa and improvement for hellaswag and commonsense. When using the baseline 8B as a teacher, we see improvement across all metrics, but lower than the other configurations.
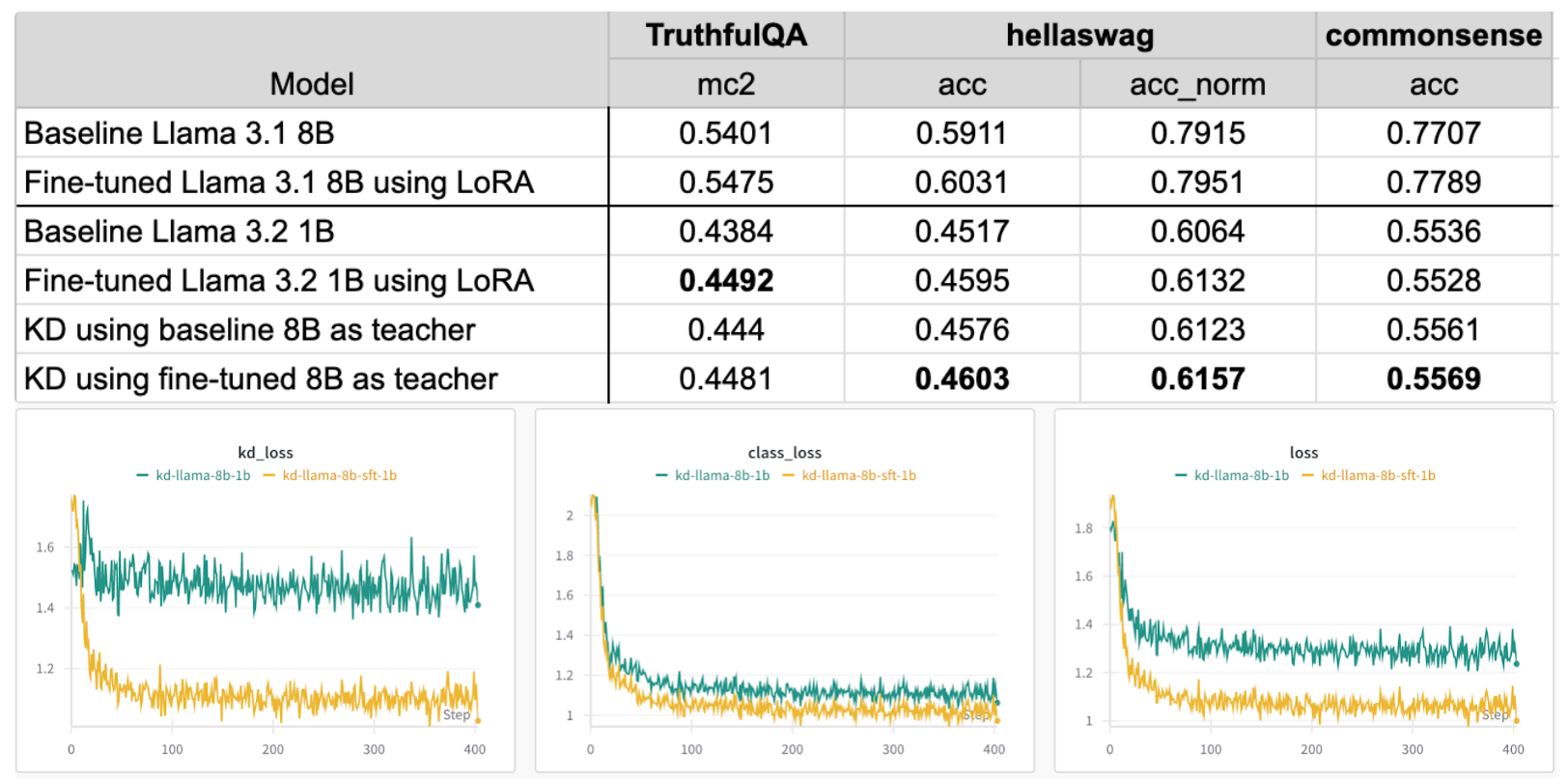
Taking a look at the losses, using the baseline 8B as teacher results in a higher loss than using the fine-tuned teacher model. The KD loss also remains relatively constant, suggesting that the teacher model should have the same distributions as the transfer dataset.
Using a fine-tuned student model
For these experiments, let’s take a look at the effects of KD when the student model is already fine-tuned. In these experiments, we look at different combinations of baseline and fine-tuned 8B and 1B models. To change the student model, you can first fine-tune the 1B model then modify the student model checkpointer in the config:
checkpointer:
_component_: torchtune.training.FullModelHFCheckpointer
checkpoint_dir: /tmp/Llama-3.2-1B-Instruct/
checkpoint_files: [
hf_model_0001_0.pt
]
Using the fine-tuned student model boosts accuracy even further for truthfulqa, but the accuracy drops for hellaswag and commonsense. Using a fine-tuned teacher model and baseline student model achieved the best results on hellaswag and commonsense dataset. Based on these findings, the best configuration will change depending on which evaluation dataset and metric you are optimizing for.
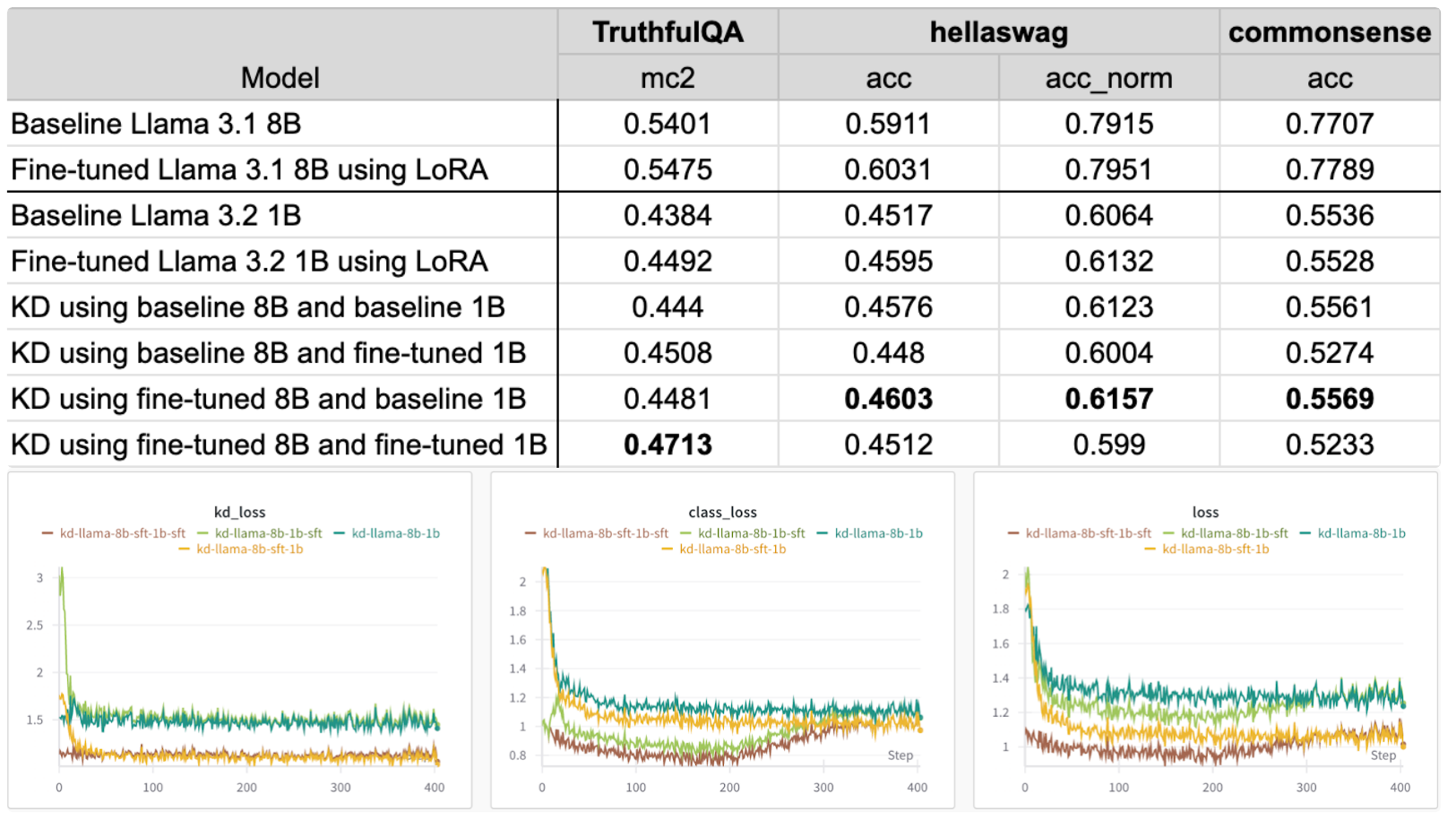
Based on the loss graphs, using a fine-tuned teacher model results in a lower loss irrespective of whether the student model is fine-tuned or not. It’s also interesting to note that the class loss starts to increase when using a fine-tuned student model.
Hyperparameter tuning: learning rate
By default, the config has the learning rate as
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device optimizer.lr=1e-3
Based on the results, the optimal learning rate changes depending on which metric you are optimizing for.
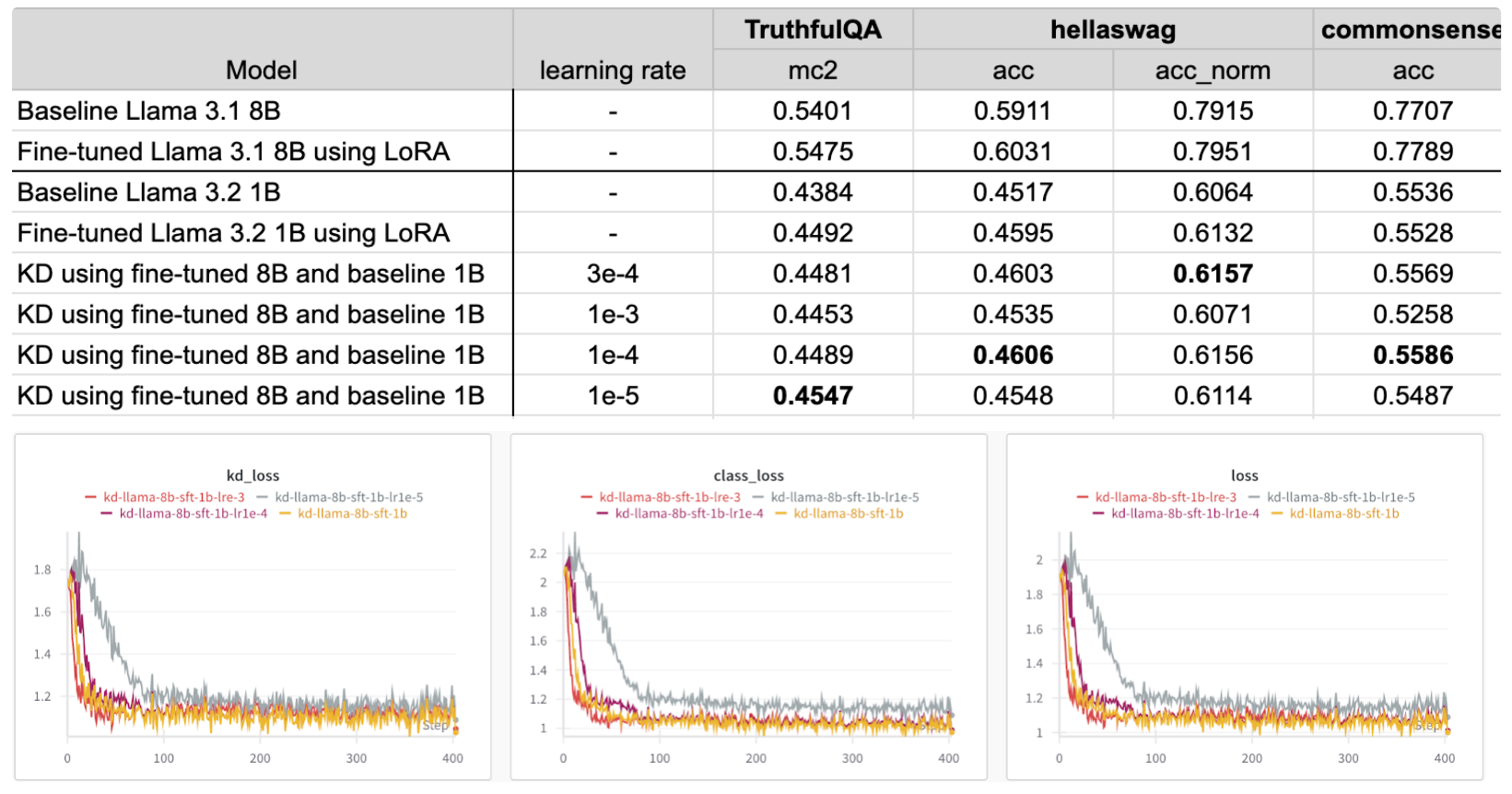
Based on the loss graphs, all learning rates result in similar losses except for
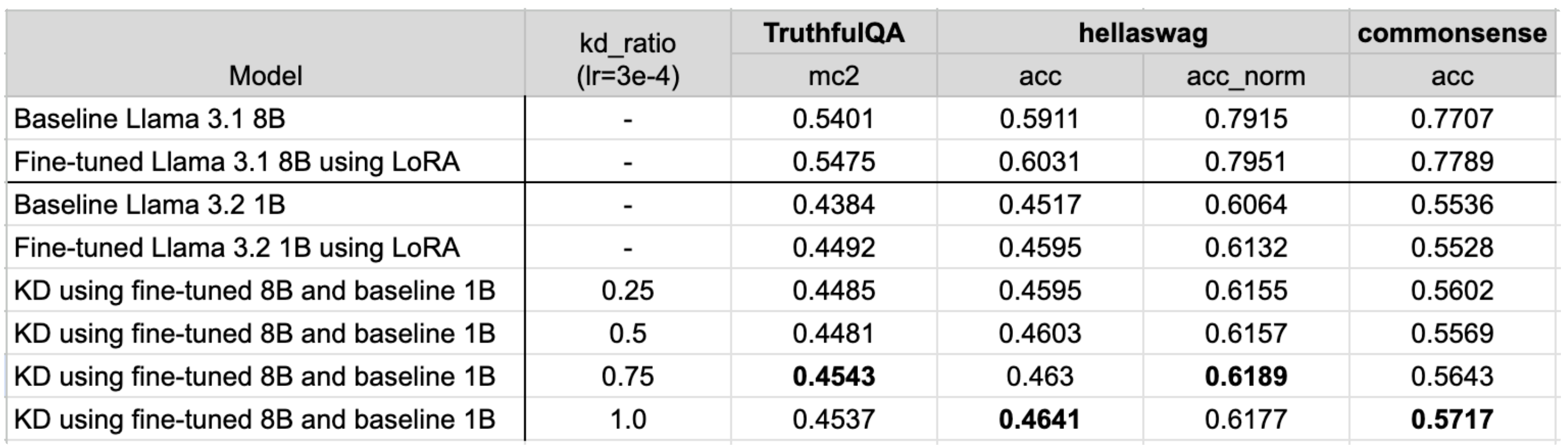
Hyperparameter tuning: KD ratio
In the config, we have the kd_ratio as 0.5, which gives even weightings to both the class and KD loss. In these experiments,
we look at the effects of different KD ratios, where 0 only uses the class loss and 1 only uses the KD loss.
Similar to changing the learning rate, the KD ratio can be adjusted using:
tune run knowledge_distillation_single_device --config llama3_2/knowledge_distillation_single_device kd_ratio=0.25
Overall, the evaluation results are slightly better for higher KD ratios.
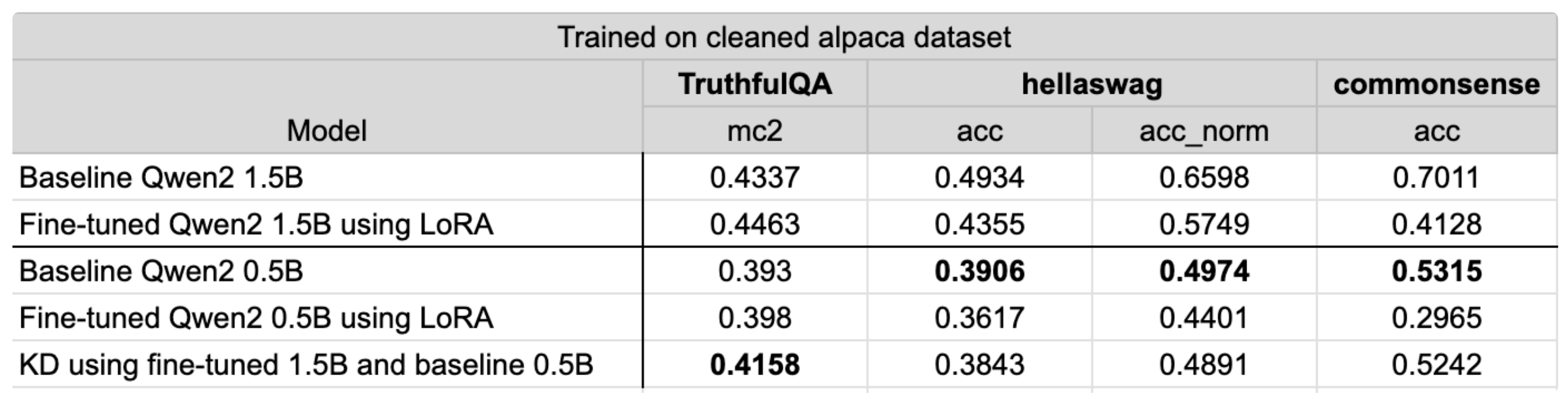
Qwen2 1.5B to 0.5B
The KD recipe can also be applied to different model families. Here we look at the effect of KD when the number of parameters between the teacher and student models are closer. For this experiment, we used Qwen2 1.5B and Qwen2 0.5B, the configs for which can be found in qwen2/knowledge_distillation_single_device config. Here we see that training on the alpaca cleaned dataset only improves truthful_qa performance and drops the metrics for the other evaluation tasks. For truthful_qa, KD improves the student model performance by 5.8% whereas fine-tuning improves performance by 1.3%.