torchrl.collectors package
Data collectors are somewhat equivalent to pytorch dataloaders, except that (1) they collect data over non-static data sources and (2) the data is collected using a model (likely a version of the model that is being trained).
TorchRL’s data collectors accept two main arguments: an environment (or a list of environment constructors) and a policy. They will iteratively execute an environment step and a policy query over a defined number of steps before delivering a stack of the data collected to the user. Environments will be reset whenever they reach a done state, and/or after a predefined number of steps.
Because data collection is a potentially compute heavy process, it is crucial to
configure the execution hyperparameters appropriately.
The first parameter to take into consideration is whether the data collection should
occur serially with the optimization step or in parallel. The SyncDataCollector
class will execute the data collection on the training worker. The MultiSyncDataCollector
will split the workload across an number of workers and aggregate the results that
will be delivered to the training worker. Finally, the MultiaSyncDataCollector will
execute the data collection on several workers and deliver the first batch of results
that it can gather. This execution will occur continuously and concomitantly with
the training of the networks: this implies that the weights of the policy that
is used for the data collection may slightly lag the configuration of the policy
on the training worker. Therefore, although this class may be the fastest to collect
data, it comes at the price of being suitable only in settings where it is acceptable
to gather data asynchronously (e.g. off-policy RL or curriculum RL).
For remotely executed rollouts (MultiSyncDataCollector or MultiaSyncDataCollector)
it is necessary to synchronise the weights of the remote policy with the weights
from the training worker using either the collector.update_policy_weights_() or
by setting update_at_each_batch=True in the constructor.
The second parameter to consider (in the remote settings) is the device where the
data will be collected and the device where the environment and policy operations
will be executed. For instance, a policy executed on CPU may be slower than one
executed on CUDA. When multiple inference workers run concomitantly, dispatching
the compute workload across the available devices may speed up the collection or
avoid OOM errors. Finally, the choice of the batch size and passing device (ie the
device where the data will be stored while waiting to be passed to the collection
worker) may also impact the memory management. The key parameters to control are
devices which controls the execution devices (ie the device of the policy)
and storing_device which will control the device where the environment and
data are stored during a rollout. A good heuristic is usually to use the same device
for storage and compute, which is the default behavior when only the devices argument
is being passed.
Besides those compute parameters, users may choose to configure the following parameters:
max_frames_per_traj: the number of frames after which a
env.reset()is calledframes_per_batch: the number of frames delivered at each iteration over the collector
init_random_frames: the number of random steps (steps where
env.rand_step()is being called)reset_at_each_iter: if
True, the environment(s) will be reset after each batch collectionsplit_trajs: if
True, the trajectories will be split and delivered in a padded tensordict along with a"mask"key that will point to a boolean mask representing the valid values.exploration_type: the exploration strategy to be used with the policy.
reset_when_done: whether environments should be reset when reaching a done state.
Collectors and batch size
Because each collector has its own way of organizing the environments that are run within, the data will come with different batch-size depending on how the specificities of the collector. The following table summarizes what is to be expected when collecting data:
SyncDataCollector |
MultiSyncDataCollector (n=B) |
MultiaSyncDataCollector (n=B) |
|||
|---|---|---|---|---|---|
cat_results |
NA |
“stack” |
0 |
-1 |
NA |
Single env |
[T] |
[B, T] |
[B*(T//B) |
[B*(T//B)] |
[T] |
Batched env (n=P) |
[P, T] |
[B, P, T] |
[B * P, T] |
[P, T * B] |
[P, T] |
In each of these cases, the last dimension (T for time) is adapted such
that the batch size equals the frames_per_batch argument passed to the
collector.
Warning
MultiSyncDataCollector should not be
used with cat_results=0, as the data will be stacked along the batch
dimension with batched environment, or the time dimension for single environments,
which can introduce some confusion when swapping one with the other.
cat_results="stack" is a better and more consistent way of interacting
with the environments as it will keep each dimension separate, and provide
better interchangeability between configurations, collector classes and other
components.
Whereas MultiSyncDataCollector
has a dimension corresponding to the number of sub-collectors being run (B),
MultiaSyncDataCollector doesn’t. This
is easily understood when considering that MultiaSyncDataCollector
delivers batches of data on a first-come, first-serve basis, whereas
MultiSyncDataCollector gathers data from
each sub-collector before delivering it.
Collectors and policy copies
When passing a policy to a collector, we can choose the device on which this policy will be run. This can be used to
keep the training version of the policy on a device and the inference version on another. For example, if you have two
CUDA devices, it may be wise to train on one device and execute the policy for inference on the other. If that is the
case, a update_policy_weights_() can be used to copy the parameters from one
device to the other (if no copy is required, this method is a no-op).
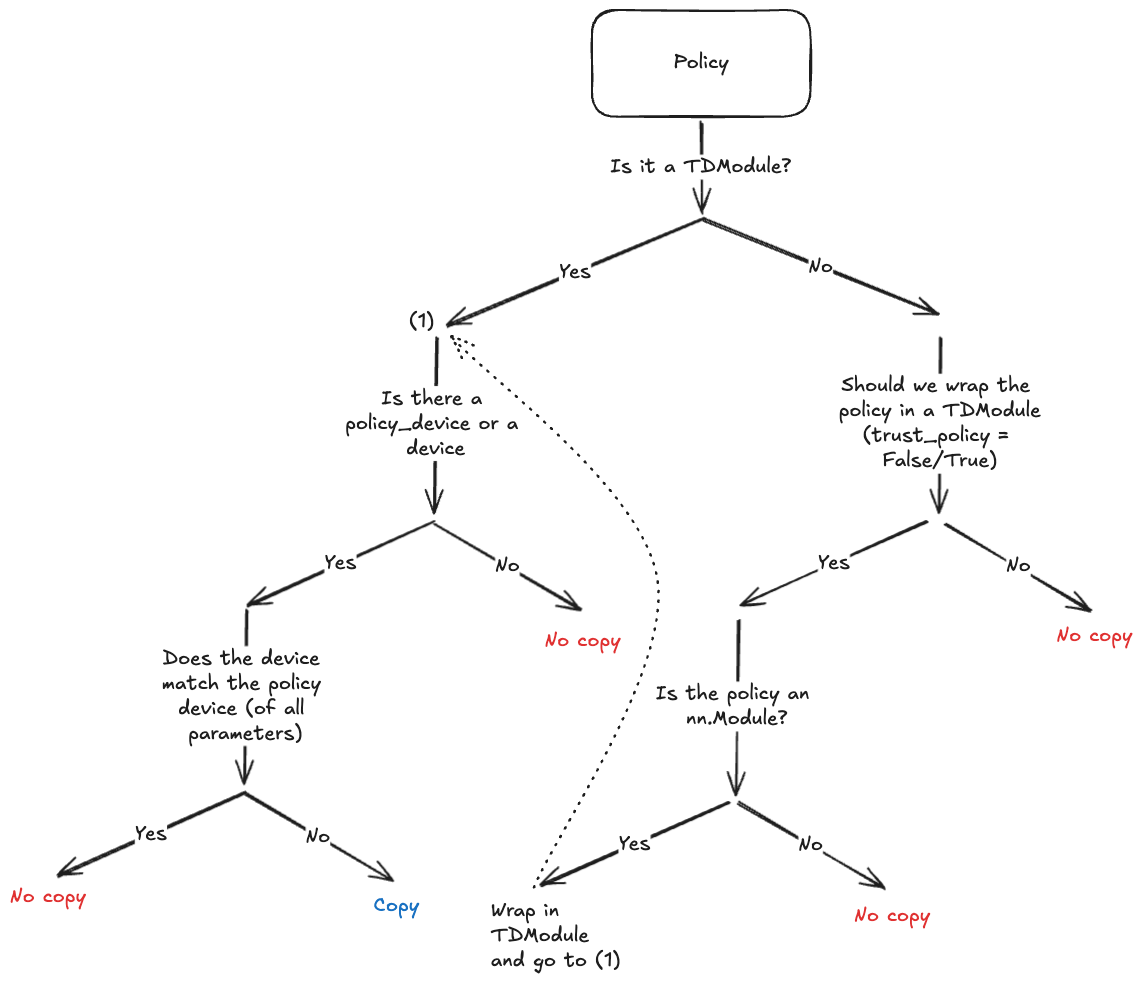
Since the goal is to avoid calling policy.to(policy_device) explicitly, the collector will do a deepcopy of the policy structure and copy the parameters placed on the new device during instantiation if necessary. Since not all policies support deepcopies (e.g., policies using CUDA graphs or relying on third-party libraries), we try to limit the cases where a deepcopy will be executed. The following chart shows when this will occur.
Collectors and replay buffers interoperability
In the simplest scenario where single transitions have to be sampled from the replay buffer, little attention has to be given to the way the collector is built. Flattening the data after collection will be a sufficient preprocessing step before populating the storage:
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N),
... transform=lambda data: data.reshape(-1))
>>> for data in collector:
... memory.extend(data)
If trajectory slices have to be collected, the recommended way to achieve this is to create
a multidimensional buffer and sample using the SliceSampler
sampler class. One must ensure that the data passed to the buffer is properly shaped, with the
time and batch dimensions clearly separated. In practice, the following configurations
will work:
>>> # Single environment: no need for a multi-dimensional buffer
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = SyncDataCollector(env, policy, frames_per_batch=N, total_frames=-1)
>>> for data in collector:
... memory.extend(data)
>>> # Batched environments: a multi-dim buffer is required
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=2),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> env = ParallelEnv(4, make_env)
>>> collector = SyncDataCollector(env, policy, frames_per_batch=N, total_frames=-1)
>>> for data in collector:
... memory.extend(data)
>>> # MultiSyncDataCollector + regular env: behaves like a ParallelEnv if cat_results="stack"
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=2),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = MultiSyncDataCollector([make_env] * 4,
... policy,
... frames_per_batch=N,
... total_frames=-1,
... cat_results="stack")
>>> for data in collector:
... memory.extend(data)
>>> # MultiSyncDataCollector + parallel env: the ndim must be adapted accordingly
>>> memory = ReplayBuffer(
... storage=LazyTensorStorage(N, ndim=3),
... sampler=SliceSampler(num_slices=4, trajectory_key=("collector", "traj_ids"))
... )
>>> collector = MultiSyncDataCollector([ParallelEnv(2, make_env)] * 4,
... policy,
... frames_per_batch=N,
... total_frames=-1,
... cat_results="stack")
>>> for data in collector:
... memory.extend(data)
Using replay buffers that sample trajectories with MultiSyncDataCollector
isn’t currently fully supported as the data batches can come from any worker and in most cases consecutive
batches written in the buffer won’t come from the same source (thereby interrupting the trajectories).
Single node data collectors
Base class for data collectors. |
|
|
Generic data collector for RL problems. |
|
Runs a given number of DataCollectors on separate processes synchronously. |
|
Runs a given number of DataCollectors on separate processes asynchronously. |
|
Runs a single DataCollector on a separate process. |
Distributed data collectors
TorchRL provides a set of distributed data collectors. These tools support
multiple backends ('gloo', 'nccl', 'mpi' with the DistributedDataCollector
or PyTorch RPC with RPCDataCollector) and launchers ('ray',
submitit or torch.multiprocessing).
They can be efficiently used in synchronous or asynchronous mode, on a single
node or across multiple nodes.
Resources: Find examples for these collectors in the dedicated folder.
Note
Choosing the sub-collector: All distributed collectors support the various single machine collectors.
One may wonder why using a MultiSyncDataCollector or a ParallelEnv
instead. In general, multiprocessed collectors have a lower IO footprint than
parallel environments which need to communicate at each step. Yet, the model specs
play a role in the opposite direction, since using parallel environments will
result in a faster execution of the policy (and/or transforms) since these
operations will be vectorized.
Note
Choosing the device of a collector (or a parallel environment): Sharing data
among processes is achieved via shared-memory buffers with parallel environment
and multiprocessed environments executed on CPU. Depending on the capabilities
of the machine being used, this may be prohibitively slow compared to sharing
data on GPU which is natively supported by cuda drivers.
In practice, this means that using the device="cpu" keyword argument when
building a parallel environment or collector can result in a slower collection
than using device="cuda" when available.
Note
Given the library’s many optional dependencies (eg, Gym, Gymnasium, and many others)
warnings can quickly become quite annoying in multiprocessed / distributed settings.
By default, TorchRL filters out these warnings in sub-processes. If one still wishes to
see these warnings, they can be displayed by setting torchrl.filter_warnings_subprocess=False.
|
A distributed data collector with torch.distributed backend. |
|
An RPC-based distributed data collector. |
|
A distributed synchronous data collector with torch.distributed backend. |
|
Delayed launcher for submitit. |
|
Distributed data collector with Ray backend. |
Helper functions
|
A util function for trajectory separation. |
