


Note
Go to the end to download the full example code
Exporting to ExecuTorch Tutorial
Author: Angela Yi
ExecuTorch is a unified ML stack for lowering PyTorch models to edge devices. It introduces improved entry points to perform model, device, and/or use-case specific optimizations such as backend delegation, user-defined compiler transformations, default or user-defined memory planning, and more.
At a high level, the workflow looks as follows:
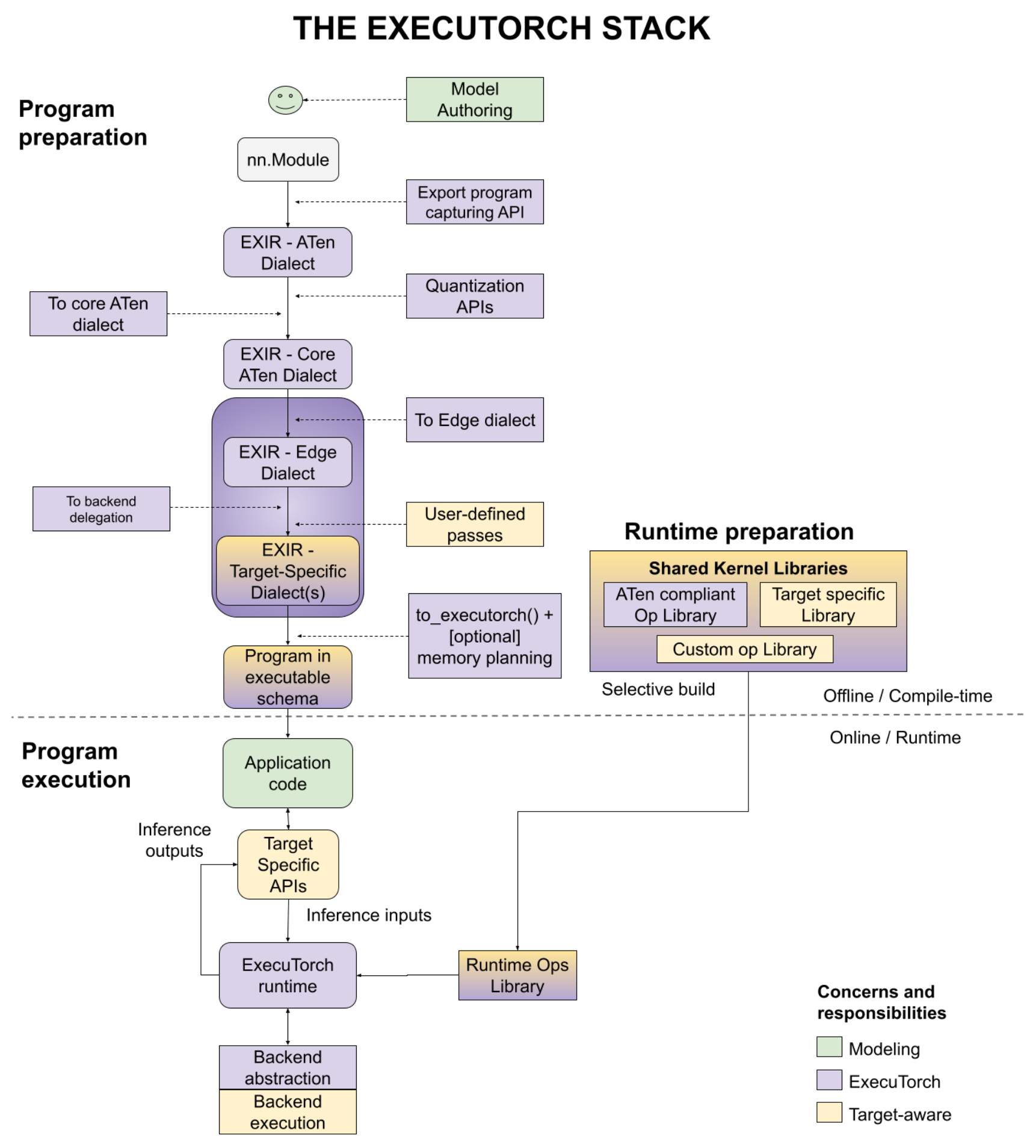
In this tutorial, we will cover the APIs in the “Program preparation” steps to lower a PyTorch model to a format which can be loaded to device and run on the ExecuTorch runtime.
Prerequisites
To run this tutorial, you’ll first need to Set up your ExecuTorch environment.
Exporting a Model
Note: The Export APIs are still undergoing changes to align better with the longer term state of export. Please refer to this issue for more details.
The first step of lowering to ExecuTorch is to export the given model (any
callable or torch.nn.Module) to a graph representation. This is done via
torch.export, which takes in an torch.nn.Module, a tuple of
positional arguments, optionally a dictionary of keyword arguments (not shown
in the example), and a list of dynamic shapes (covered later).
import torch
from torch.export import export, ExportedProgram
class SimpleConv(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv = torch.nn.Conv2d(
in_channels=3, out_channels=16, kernel_size=3, padding=1
)
self.relu = torch.nn.ReLU()
def forward(self, x: torch.Tensor) -> torch.Tensor:
a = self.conv(x)
return self.relu(a)
example_args: tuple[torch.Tensor] = (torch.randn(1, 3, 256, 256),)
aten_dialect: ExportedProgram = export(SimpleConv(), example_args, strict=True)
print(aten_dialect)
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_weight: "f32[16, 3, 3, 3]", p_conv_bias: "f32[16]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
conv2d: "f32[1, 16, 256, 256]" = torch.ops.aten.conv2d.default(x, p_conv_weight, p_conv_bias, [1, 1], [1, 1]); x = p_conv_weight = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
relu: "f32[1, 16, 256, 256]" = torch.ops.aten.relu.default(conv2d); conv2d = None
return (relu,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_weight'), target='conv.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='relu'), target=None)])
Range constraints: {}
The output of torch.export.export is a fully flattened graph (meaning the
graph does not contain any module hierarchy, except in the case of control
flow operators). Additionally, the graph is purely functional, meaning it does
not contain operations with side effects such as mutations or aliasing.
More specifications about the result of torch.export can be found
here .
The graph returned by torch.export only contains functional ATen operators
(~2000 ops), which we will call the ATen Dialect.
Expressing Dynamism
By default, the exporting flow will trace the program assuming that all input shapes are static, so if we run the program with inputs shapes that are different than the ones we used while tracing, we will run into an error:
import traceback as tb
class Basic(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x: torch.Tensor, y: torch.Tensor) -> torch.Tensor:
return x + y
example_args_2: tuple[torch.Tensor, torch.Tensor] = (
torch.randn(3, 3),
torch.randn(3, 3),
)
aten_dialect = export(Basic(), example_args_2, strict=True)
# Works correctly
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 3)))
# Errors
try:
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
except Exception:
tb.print_exc()
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 114, in <module>
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 822, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 400, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 387, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1845, in _call_impl
return inner()
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1772, in inner
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 755, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 49, in _check_input_constraints_pre_hook
_check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 356, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[0].shape[1] to be equal to 3, but got 2
- To express that some input shapes are dynamic, we can insert dynamic
shapes to the exporting flow. This is done through the
DimAPI:
from torch.export import Dim
example_args_2 = (torch.randn(3, 3), torch.randn(3, 3))
dim1_x = Dim("dim1_x", min=1, max=10)
dynamic_shapes = {"x": {1: dim1_x}, "y": {1: dim1_x}}
aten_dialect = export(
Basic(), example_args_2, dynamic_shapes=dynamic_shapes, strict=True
)
print(aten_dialect)
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[3, s0]", y: "f32[3, s0]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:100 in forward, code: return x + y
add: "f32[3, s0]" = torch.ops.aten.add.Tensor(x, y); x = y = None
return (add,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='y'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='add'), target=None)])
Range constraints: {s0: VR[1, 10]}
Note that that the inputs arg0_1 and arg1_1 now have shapes (3, s0),
with s0 being a symbol representing that this dimension can be a range
of values.
Additionally, we can see in the Range constraints that value of s0 has
the range [1, 10], which was specified by our dynamic shapes.
Now let’s try running the model with different shapes:
# Works correctly
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 3)))
print(aten_dialect.module()(torch.ones(3, 2), torch.ones(3, 2)))
# Errors because it violates our constraint that input 0, dim 1 <= 10
try:
print(aten_dialect.module()(torch.ones(3, 15), torch.ones(3, 15)))
except Exception:
tb.print_exc()
# Errors because it violates our constraint that input 0, dim 1 == input 1, dim 1
try:
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 2)))
except Exception:
tb.print_exc()
tensor([[2., 2., 2.],
[2., 2., 2.],
[2., 2., 2.]])
tensor([[2., 2.],
[2., 2.],
[2., 2.]])
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 148, in <module>
print(aten_dialect.module()(torch.ones(3, 15), torch.ones(3, 15)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 822, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 400, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 387, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1845, in _call_impl
return inner()
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1772, in inner
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 755, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 49, in _check_input_constraints_pre_hook
_check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 344, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[0].shape[1] to be <= 10, but got 15
Traceback (most recent call last):
File "/pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py", line 154, in <module>
print(aten_dialect.module()(torch.ones(3, 3), torch.ones(3, 2)))
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 822, in call_wrapped
return self._wrapped_call(self, *args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 400, in __call__
raise e
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph_module.py", line 387, in __call__
return super(self.cls, obj).__call__(*args, **kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1739, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1845, in _call_impl
return inner()
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1772, in inner
args_kwargs_result = hook(self, args, kwargs) # type: ignore[misc]
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_dynamo/eval_frame.py", line 755, in _fn
return fn(*args, **kwargs)
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py", line 49, in _check_input_constraints_pre_hook
_check_input_constraints_for_graph(
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_export/utils.py", line 308, in _check_input_constraints_for_graph
raise RuntimeError(
RuntimeError: Expected input at *args[1].shape[1] to be equal to 3, but got 2
Addressing Untraceable Code
As our goal is to capture the entire computational graph from a PyTorch program, we might ultimately run into untraceable parts of programs. To address these issues, the torch.export documentation, or the torch.export tutorial would be the best place to look.
Performing Quantization
To quantize a model, we first need to capture the graph with
torch.export.export_for_training, perform quantization, and then
call torch.export. torch.export.export_for_training returns a
graph which contains ATen operators which are Autograd safe, meaning they are
safe for eager-mode training, which is needed for quantization. We will call
the graph at this level, the Pre-Autograd ATen Dialect graph.
Compared to
FX Graph Mode Quantization,
we will need to call two new APIs: prepare_pt2e and convert_pt2e
instead of prepare_fx and convert_fx. It differs in that
prepare_pt2e takes a backend-specific Quantizer as an argument, which
will annotate the nodes in the graph with information needed to quantize the
model properly for a specific backend.
from torch.export import export_for_training
example_args = (torch.randn(1, 3, 256, 256),)
pre_autograd_aten_dialect = export_for_training(SimpleConv(), example_args).module()
print("Pre-Autograd ATen Dialect Graph")
print(pre_autograd_aten_dialect)
from executorch.backends.xnnpack.quantizer.xnnpack_quantizer import (
get_symmetric_quantization_config,
XNNPACKQuantizer,
)
from torch.ao.quantization.quantize_pt2e import convert_pt2e, prepare_pt2e
quantizer = XNNPACKQuantizer().set_global(get_symmetric_quantization_config())
prepared_graph = prepare_pt2e(pre_autograd_aten_dialect, quantizer) # type: ignore[arg-type]
# calibrate with a sample dataset
converted_graph = convert_pt2e(prepared_graph)
print("Quantized Graph")
print(converted_graph)
aten_dialect = export(converted_graph, example_args, strict=True)
print("ATen Dialect Graph")
print(aten_dialect)
Pre-Autograd ATen Dialect Graph
GraphModule(
(conv): Module()
)
def forward(self, x):
x, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
conv_weight = self.conv.weight
conv_bias = self.conv.bias
conv2d = torch.ops.aten.conv2d.default(x, conv_weight, conv_bias, [1, 1], [1, 1]); x = conv_weight = conv_bias = None
relu = torch.ops.aten.relu.default(conv2d); conv2d = None
return pytree.tree_unflatten((relu,), self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/ao/quantization/utils.py:408: UserWarning: must run observer before calling calculate_qparams. Returning default values.
warnings.warn(
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/ao/quantization/observer.py:1333: UserWarning: must run observer before calling calculate_qparams. Returning default scale and zero point
warnings.warn(
Quantized Graph
GraphModule(
(conv): Module()
)
def forward(self, x):
x, = fx_pytree.tree_flatten_spec(([x], {}), self._in_spec)
_frozen_param0 = self._frozen_param0
dequantize_per_tensor_default = torch.ops.quantized_decomposed.dequantize_per_tensor.default(_frozen_param0, 1.0, 0, -127, 127, torch.int8); _frozen_param0 = None
conv_bias = self.conv.bias
quantize_per_tensor_default_1 = torch.ops.quantized_decomposed.quantize_per_tensor.default(x, 1.0, 0, -128, 127, torch.int8); x = None
dequantize_per_tensor_default_1 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default_1, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default_1 = None
conv2d = torch.ops.aten.conv2d.default(dequantize_per_tensor_default_1, dequantize_per_tensor_default, conv_bias, [1, 1], [1, 1]); dequantize_per_tensor_default_1 = dequantize_per_tensor_default = conv_bias = None
relu = torch.ops.aten.relu.default(conv2d); conv2d = None
quantize_per_tensor_default_2 = torch.ops.quantized_decomposed.quantize_per_tensor.default(relu, 1.0, 0, -128, 127, torch.int8); relu = None
dequantize_per_tensor_default_2 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default_2, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default_2 = None
return pytree.tree_unflatten((dequantize_per_tensor_default_2,), self._out_spec)
# To see more debug info, please use `graph_module.print_readable()`
ATen Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_bias: "f32[16]", b__frozen_param0: "i8[16, 3, 3, 3]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
dequantize_per_tensor: "f32[16, 3, 3, 3]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(b__frozen_param0, 1.0, 0, -127, 127, torch.int8); b__frozen_param0 = None
# File: <eval_with_key>.204:9 in forward, code: quantize_per_tensor_default_1 = torch.ops.quantized_decomposed.quantize_per_tensor.default(x, 1.0, 0, -128, 127, torch.int8); x = None
quantize_per_tensor: "i8[1, 3, 256, 256]" = torch.ops.quantized_decomposed.quantize_per_tensor.default(x, 1.0, 0, -128, 127, torch.int8); x = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
dequantize_per_tensor_1: "f32[1, 3, 256, 256]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor = None
conv2d: "f32[1, 16, 256, 256]" = torch.ops.aten.conv2d.default(dequantize_per_tensor_1, dequantize_per_tensor, p_conv_bias, [1, 1], [1, 1]); dequantize_per_tensor_1 = dequantize_per_tensor = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
relu: "f32[1, 16, 256, 256]" = torch.ops.aten.relu.default(conv2d); conv2d = None
quantize_per_tensor_1: "i8[1, 16, 256, 256]" = torch.ops.quantized_decomposed.quantize_per_tensor.default(relu, 1.0, 0, -128, 127, torch.int8); relu = None
# File: <eval_with_key>.204:14 in forward, code: dequantize_per_tensor_default_2 = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_default_2, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_default_2 = None
dequantize_per_tensor_2: "f32[1, 16, 256, 256]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor_1, 1.0, 0, -128, 127, torch.int8); quantize_per_tensor_1 = None
return (dequantize_per_tensor_2,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.BUFFER: 3>, arg=TensorArgument(name='b__frozen_param0'), target='_frozen_param0', persistent=True), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='dequantize_per_tensor_2'), target=None)])
Range constraints: {}
More information on how to quantize a model, and how a backend can implement a
Quantizer can be found
here.
Lowering to Edge Dialect
After exporting and lowering the graph to the ATen Dialect, the next step
is to lower to the Edge Dialect, in which specializations that are useful
for edge devices but not necessary for general (server) environments will be
applied.
Some of these specializations include:
DType specialization
Scalar to tensor conversion
Converting all ops to the
executorch.exir.dialects.edgenamespace.
Note that this dialect is still backend (or target) agnostic.
The lowering is done through the to_edge API.
from executorch.exir import EdgeProgramManager, to_edge
example_args = (torch.randn(1, 3, 256, 256),)
aten_dialect = export(SimpleConv(), example_args, strict=True)
edge_program: EdgeProgramManager = to_edge(aten_dialect)
print("Edge Dialect Graph")
print(edge_program.exported_program())
Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_weight: "f32[16, 3, 3, 3]", p_conv_bias: "f32[16]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(x, p_conv_weight, p_conv_bias, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); x = p_conv_weight = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
aten_relu_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_relu_default(aten_convolution_default); aten_convolution_default = None
return (aten_relu_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_weight'), target='conv.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_relu_default'), target=None)])
Range constraints: {}
to_edge() returns an EdgeProgramManager object, which contains the
exported programs which will be placed on this device. This data structure
allows users to export multiple programs and combine them into one binary. If
there is only one program, it will by default be saved to the name “forward”.
class Encode(torch.nn.Module):
def forward(self, x):
return torch.nn.functional.linear(x, torch.randn(5, 10))
class Decode(torch.nn.Module):
def forward(self, x):
return torch.nn.functional.linear(x, torch.randn(10, 5))
encode_args = (torch.randn(1, 10),)
aten_encode: ExportedProgram = export(Encode(), encode_args, strict=True)
decode_args = (torch.randn(1, 5),)
aten_decode: ExportedProgram = export(Decode(), decode_args, strict=True)
edge_program = to_edge({"encode": aten_encode, "decode": aten_decode})
for method in edge_program.methods:
print(f"Edge Dialect graph of {method}")
print(edge_program.exported_program(method))
Edge Dialect graph of encode
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[1, 10]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:255 in forward, code: return torch.nn.functional.linear(x, torch.randn(5, 10))
aten_randn_default: "f32[5, 10]" = executorch_exir_dialects_edge__ops_aten_randn_default([5, 10], device = device(type='cpu'), pin_memory = False)
aten_permute_copy_default: "f32[10, 5]" = executorch_exir_dialects_edge__ops_aten_permute_copy_default(aten_randn_default, [1, 0]); aten_randn_default = None
aten_mm_default: "f32[1, 5]" = executorch_exir_dialects_edge__ops_aten_mm_default(x, aten_permute_copy_default); x = aten_permute_copy_default = None
return (aten_mm_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_mm_default'), target=None)])
Range constraints: {}
Edge Dialect graph of decode
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[1, 5]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:260 in forward, code: return torch.nn.functional.linear(x, torch.randn(10, 5))
aten_randn_default: "f32[10, 5]" = executorch_exir_dialects_edge__ops_aten_randn_default([10, 5], device = device(type='cpu'), pin_memory = False)
aten_permute_copy_default: "f32[5, 10]" = executorch_exir_dialects_edge__ops_aten_permute_copy_default(aten_randn_default, [1, 0]); aten_randn_default = None
aten_mm_default: "f32[1, 10]" = executorch_exir_dialects_edge__ops_aten_mm_default(x, aten_permute_copy_default); x = aten_permute_copy_default = None
return (aten_mm_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_mm_default'), target=None)])
Range constraints: {}
We can also run additional passes on the exported program through
the transform API. An in-depth documentation on how to write
transformations can be found
here.
Note that since the graph is now in the Edge Dialect, all passes must also
result in a valid Edge Dialect graph (specifically one thing to point out is
that the operators are now in the executorch.exir.dialects.edge namespace,
rather than the torch.ops.aten namespace.
example_args = (torch.randn(1, 3, 256, 256),)
aten_dialect = export(SimpleConv(), example_args, strict=True)
edge_program = to_edge(aten_dialect)
print("Edge Dialect Graph")
print(edge_program.exported_program())
from executorch.exir.dialects._ops import ops as exir_ops
from executorch.exir.pass_base import ExportPass
class ConvertReluToSigmoid(ExportPass):
def call_operator(self, op, args, kwargs, meta):
if op == exir_ops.edge.aten.relu.default:
return super().call_operator(
exir_ops.edge.aten.sigmoid.default, args, kwargs, meta
)
else:
return super().call_operator(op, args, kwargs, meta)
transformed_edge_program = edge_program.transform((ConvertReluToSigmoid(),))
print("Transformed Edge Dialect Graph")
print(transformed_edge_program.exported_program())
Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_weight: "f32[16, 3, 3, 3]", p_conv_bias: "f32[16]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(x, p_conv_weight, p_conv_bias, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); x = p_conv_weight = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
aten_relu_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_relu_default(aten_convolution_default); aten_convolution_default = None
return (aten_relu_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_weight'), target='conv.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_relu_default'), target=None)])
Range constraints: {}
Transformed Edge Dialect Graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_conv_weight: "f32[16, 3, 3, 3]", p_conv_bias: "f32[16]", x: "f32[1, 3, 256, 256]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:64 in forward, code: a = self.conv(x)
aten_convolution_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_convolution_default(x, p_conv_weight, p_conv_bias, [1, 1], [1, 1], [1, 1], False, [0, 0], 1); x = p_conv_weight = p_conv_bias = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:65 in forward, code: return self.relu(a)
aten_sigmoid_default: "f32[1, 16, 256, 256]" = executorch_exir_dialects_edge__ops_aten_sigmoid_default(aten_convolution_default); aten_convolution_default = None
return (aten_sigmoid_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_weight'), target='conv.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='p_conv_bias'), target='conv.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sigmoid_default'), target=None)])
Range constraints: {}
Note: if you see error like torch._export.verifier.SpecViolationError:
Operator torch._ops.aten._native_batch_norm_legit_functional.default is not
Aten Canonical,
please file an issue in https://github.com/pytorch/executorch/issues and we’re happy to help!
Delegating to a Backend
We can now delegate parts of the graph or the whole graph to a third-party
backend through the to_backend API. An in-depth documentation on the
specifics of backend delegation, including how to delegate to a backend and
how to implement a backend, can be found
here.
There are three ways for using this API:
We can lower the whole module.
We can take the lowered module, and insert it in another larger module.
We can partition the module into subgraphs that are lowerable, and then lower those subgraphs to a backend.
Lowering the Whole Module
To lower an entire module, we can pass to_backend the backend name, the
module to be lowered, and a list of compile specs to help the backend with the
lowering process.
class LowerableModule(torch.nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return torch.sin(x)
# Export and lower the module to Edge Dialect
example_args = (torch.ones(1),)
aten_dialect = export(LowerableModule(), example_args, strict=True)
edge_program = to_edge(aten_dialect)
to_be_lowered_module = edge_program.exported_program()
from executorch.exir.backend.backend_api import LoweredBackendModule, to_backend
# Import the backend
from executorch.exir.backend.test.backend_with_compiler_demo import ( # noqa
BackendWithCompilerDemo,
)
# Lower the module
lowered_module: LoweredBackendModule = to_backend( # type: ignore[call-arg]
"BackendWithCompilerDemo", to_be_lowered_module, []
)
print(lowered_module)
print(lowered_module.backend_id)
print(lowered_module.processed_bytes)
print(lowered_module.original_module)
# Serialize and save it to a file
save_path = "delegate.pte"
with open(save_path, "wb") as f:
f.write(lowered_module.buffer())
LoweredBackendModule()
BackendWithCompilerDemo
b'1version:0#op:demo::aten.sin.default, numel:1, dtype:torch.float32<debug_handle>2#'
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[1]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:347 in forward, code: return torch.sin(x)
aten_sin_default: "f32[1]" = executorch_exir_dialects_edge__ops_aten_sin_default(x); x = None
return (aten_sin_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sin_default'), target=None)])
Range constraints: {}
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/passes/infra/pass_base.py:44: FutureWarning: MemoryPlanningPass.call() is deprecated as it does not handle graphs with mutation, please use MemoryPlanningPass.run() instead
res = self.call(graph_module)
In this call, to_backend will return a LoweredBackendModule. Some
important attributes of the LoweredBackendModule are:
backend_id: The name of the backend this lowered module will run on in the runtimeprocessed_bytes: a binary blob which will tell the backend how to run this program in the runtimeoriginal_module: the original exported module
Compose the Lowered Module into Another Module
In cases where we want to reuse this lowered module in multiple programs, we can compose this lowered module with another module.
class NotLowerableModule(torch.nn.Module):
def __init__(self, bias):
super().__init__()
self.bias = bias
def forward(self, a, b):
return torch.add(torch.add(a, b), self.bias)
class ComposedModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.non_lowerable = NotLowerableModule(torch.ones(1) * 0.3)
self.lowerable = lowered_module
def forward(self, x):
a = self.lowerable(x)
b = self.lowerable(a)
ret = self.non_lowerable(a, b)
return a, b, ret
example_args = (torch.ones(1),)
aten_dialect = export(ComposedModule(), example_args, strict=True)
edge_program = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
print("Edge Dialect graph")
print(exported_program)
print("Lowered Module within the graph")
print(exported_program.graph_module.lowered_module_0.backend_id)
print(exported_program.graph_module.lowered_module_0.processed_bytes)
print(exported_program.graph_module.lowered_module_0.original_module)
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/export/_unlift.py:75: UserWarning: Attempted to insert a get_attr Node with no underlying reference in the owning GraphModule! Call GraphModule.add_submodule to add the necessary submodule, GraphModule.add_parameter to add the necessary Parameter, or nn.Module.register_buffer to add the necessary buffer
getattr_node = gm.graph.get_attr(lifted_node)
/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/fx/graph.py:1801: UserWarning: Node non_lowerable_bias target non_lowerable.bias bias of non_lowerable does not reference an nn.Module, nn.Parameter, or buffer, which is what 'get_attr' Nodes typically target
warnings.warn(
Edge Dialect graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, c_non_lowerable_bias: "f32[1]", x: "f32[1]"):
# File: /opt/conda/envs/py_3.10/lib/python3.10/site-packages/executorch/exir/lowered_backend_module.py:344 in forward, code: return executorch_call_delegate(self, *args)
lowered_module_0 = self.lowered_module_0
executorch_call_delegate: "f32[1]" = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, x); lowered_module_0 = x = None
# File: /opt/conda/envs/py_3.10/lib/python3.10/site-packages/executorch/exir/lowered_backend_module.py:344 in forward, code: return executorch_call_delegate(self, *args)
lowered_module_1 = self.lowered_module_0
executorch_call_delegate_1: "f32[1]" = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, executorch_call_delegate); lowered_module_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:401 in forward, code: return torch.add(torch.add(a, b), self.bias)
aten_add_tensor: "f32[1]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(executorch_call_delegate, executorch_call_delegate_1)
aten_add_tensor_1: "f32[1]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_add_tensor, c_non_lowerable_bias); aten_add_tensor = c_non_lowerable_bias = None
return (executorch_call_delegate, executorch_call_delegate_1, aten_add_tensor_1)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.CONSTANT_TENSOR: 4>, arg=TensorArgument(name='c_non_lowerable_bias'), target='non_lowerable.bias', persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='executorch_call_delegate'), target=None), OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='executorch_call_delegate_1'), target=None), OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
Lowered Module within the graph
BackendWithCompilerDemo
b'1version:0#op:demo::aten.sin.default, numel:1, dtype:torch.float32<debug_handle>2#'
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, x: "f32[1]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:347 in forward, code: return torch.sin(x)
aten_sin_default: "f32[1]" = executorch_exir_dialects_edge__ops_aten_sin_default(x); x = None
return (aten_sin_default,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_sin_default'), target=None)])
Range constraints: {}
Notice that there is now a torch.ops.higher_order.executorch_call_delegate node in the
graph, which is calling lowered_module_0. Additionally, the contents of
lowered_module_0 are the same as the lowered_module we created
previously.
Partition and Lower Parts of a Module
A separate lowering flow is to pass to_backend the module that we want to
lower, and a backend-specific partitioner. to_backend will use the
backend-specific partitioner to tag nodes in the module which are lowerable,
partition those nodes into subgraphs, and then create a
LoweredBackendModule for each of those subgraphs.
class Foo(torch.nn.Module):
def forward(self, a, x, b):
y = torch.mm(a, x)
z = y + b
a = z - a
y = torch.mm(a, x)
z = y + b
return z
example_args_3 = (torch.randn(2, 2), torch.randn(2, 2), torch.randn(2, 2))
aten_dialect = export(Foo(), example_args_3, strict=True)
edge_program = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
print("Edge Dialect graph")
print(exported_program)
from executorch.exir.backend.test.op_partitioner_demo import AddMulPartitionerDemo
delegated_program = to_backend(exported_program, AddMulPartitionerDemo()) # type: ignore[call-arg]
print("Delegated program")
print(delegated_program)
print(delegated_program.graph_module.lowered_module_0.original_module)
print(delegated_program.graph_module.lowered_module_1.original_module)
Edge Dialect graph
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:447 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(a, x)
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:448 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default, b); aten_mm_default = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:449 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(aten_add_tensor, a); aten_add_tensor = a = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:450 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(aten_sub_tensor, x); aten_sub_tensor = x = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:451 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default_1, b); aten_mm_default_1 = b = None
return (aten_add_tensor_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
Delegated program
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# No stacktrace found for following nodes
lowered_module_0 = self.lowered_module_0
lowered_module_1 = self.lowered_module_1
executorch_call_delegate_1 = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, a, x, b); lowered_module_1 = None
getitem_1: "f32[2, 2]" = executorch_call_delegate_1[0]; executorch_call_delegate_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:449 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(getitem_1, a); getitem_1 = a = None
# No stacktrace found for following nodes
executorch_call_delegate = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, aten_sub_tensor, x, b); lowered_module_0 = aten_sub_tensor = x = b = None
getitem: "f32[2, 2]" = executorch_call_delegate[0]; executorch_call_delegate = None
return (getitem,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='getitem'), target=None)])
Range constraints: {}
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, aten_sub_tensor: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:450 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(aten_sub_tensor, x); aten_sub_tensor = x = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:451 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default_1, b); aten_mm_default_1 = b = None
return [aten_add_tensor_1]
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='aten_sub_tensor'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:447 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_mm_default(a, x); a = x = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:448 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_add_Tensor(aten_mm_default, b); aten_mm_default = b = None
return [aten_add_tensor]
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor'), target=None)])
Range constraints: {}
Notice that there are now 2 torch.ops.higher_order.executorch_call_delegate nodes in the
graph, one containing the operations add, mul and the other containing the
operations mul, add.
Alternatively, a more cohesive API to lower parts of a module is to directly
call to_backend on it:
example_args_3 = (torch.randn(2, 2), torch.randn(2, 2), torch.randn(2, 2))
aten_dialect = export(Foo(), example_args_3, strict=True)
edge_program = to_edge(aten_dialect)
exported_program = edge_program.exported_program()
delegated_program = edge_program.to_backend(AddMulPartitionerDemo())
print("Delegated program")
print(delegated_program.exported_program())
Delegated program
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# No stacktrace found for following nodes
lowered_module_0 = self.lowered_module_0
lowered_module_1 = self.lowered_module_1
executorch_call_delegate_1 = torch.ops.higher_order.executorch_call_delegate(lowered_module_1, a, x, b); lowered_module_1 = None
getitem_1: "f32[2, 2]" = executorch_call_delegate_1[0]; executorch_call_delegate_1 = None
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:449 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = executorch_exir_dialects_edge__ops_aten_sub_Tensor(getitem_1, a); getitem_1 = a = None
# No stacktrace found for following nodes
executorch_call_delegate = torch.ops.higher_order.executorch_call_delegate(lowered_module_0, aten_sub_tensor, x, b); lowered_module_0 = aten_sub_tensor = x = b = None
getitem: "f32[2, 2]" = executorch_call_delegate[0]; executorch_call_delegate = None
return (getitem,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='getitem'), target=None)])
Range constraints: {}
Running User-Defined Passes and Memory Planning
As a final step of lowering, we can use the to_executorch() API to pass in
backend-specific passes, such as replacing sets of operators with a custom
backend operator, and a memory planning pass, to tell the runtime how to
allocate memory ahead of time when running the program.
A default memory planning pass is provided, but we can also choose a backend-specific memory planning pass if it exists. More information on writing a custom memory planning pass can be found here
from executorch.exir import ExecutorchBackendConfig, ExecutorchProgramManager
from executorch.exir.passes import MemoryPlanningPass
executorch_program: ExecutorchProgramManager = edge_program.to_executorch(
ExecutorchBackendConfig(
passes=[], # User-defined passes
memory_planning_pass=MemoryPlanningPass(), # Default memory planning pass
)
)
print("ExecuTorch Dialect")
print(executorch_program.exported_program())
ExecuTorch Dialect
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, a: "f32[2, 2]", x: "f32[2, 2]", b: "f32[2, 2]"):
# No stacktrace found for following nodes
alloc: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:447 in forward, code: y = torch.mm(a, x)
aten_mm_default: "f32[2, 2]" = torch.ops.aten.mm.out(a, x, out = alloc); alloc = None
# No stacktrace found for following nodes
alloc_1: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:448 in forward, code: z = y + b
aten_add_tensor: "f32[2, 2]" = torch.ops.aten.add.out(aten_mm_default, b, out = alloc_1); aten_mm_default = alloc_1 = None
# No stacktrace found for following nodes
alloc_2: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:449 in forward, code: a = z - a
aten_sub_tensor: "f32[2, 2]" = torch.ops.aten.sub.out(aten_add_tensor, a, out = alloc_2); aten_add_tensor = a = alloc_2 = None
# No stacktrace found for following nodes
alloc_3: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:450 in forward, code: y = torch.mm(a, x)
aten_mm_default_1: "f32[2, 2]" = torch.ops.aten.mm.out(aten_sub_tensor, x, out = alloc_3); aten_sub_tensor = x = alloc_3 = None
# No stacktrace found for following nodes
alloc_4: "f32[2, 2]" = executorch_exir_memory_alloc(((2, 2), torch.float32))
# File: /pytorch/executorch/docs/source/tutorials_source/export-to-executorch-tutorial.py:451 in forward, code: z = y + b
aten_add_tensor_1: "f32[2, 2]" = torch.ops.aten.add.out(aten_mm_default_1, b, out = alloc_4); aten_mm_default_1 = b = alloc_4 = None
return (aten_add_tensor_1,)
Graph signature: ExportGraphSignature(input_specs=[InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='a'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='x'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='b'), target=None, persistent=None)], output_specs=[OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='aten_add_tensor_1'), target=None)])
Range constraints: {}
Notice that in the graph we now see operators like torch.ops.aten.sub.out
and torch.ops.aten.div.out rather than torch.ops.aten.sub.Tensor and
torch.ops.aten.div.Tensor.
This is because between running the backend passes and memory planning passes,
to prepare the graph for memory planning, an out-variant pass is run on
the graph to convert all of the operators to their out variants. Instead of
allocating returned tensors in the kernel implementations, an operator’s
out variant will take in a prealloacated tensor to its out kwarg, and
store the result there, making it easier for memory planners to do tensor
lifetime analysis.
We also insert alloc nodes into the graph containing calls to a special
executorch.exir.memory.alloc operator. This tells us how much memory is
needed to allocate each tensor output by the out-variant operator.
Saving to a File
Finally, we can save the ExecuTorch Program to a file and load it to a device to be run.
Here is an example for an entire end-to-end workflow:
import torch
from torch.export import export, export_for_training, ExportedProgram
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.param = torch.nn.Parameter(torch.rand(3, 4))
self.linear = torch.nn.Linear(4, 5)
def forward(self, x):
return self.linear(x + self.param).clamp(min=0.0, max=1.0)
example_args = (torch.randn(3, 4),)
pre_autograd_aten_dialect = export_for_training(M(), example_args).module()
# Optionally do quantization:
# pre_autograd_aten_dialect = convert_pt2e(prepare_pt2e(pre_autograd_aten_dialect, CustomBackendQuantizer))
aten_dialect = export(pre_autograd_aten_dialect, example_args, strict=True)
edge_program = to_edge(aten_dialect)
# Optionally do delegation:
# edge_program = edge_program.to_backend(CustomBackendPartitioner)
executorch_program = edge_program.to_executorch(
ExecutorchBackendConfig(
passes=[], # User-defined passes
)
)
with open("model.pte", "wb") as file:
file.write(executorch_program.buffer)
