ExecuTorch Llama iOS Demo App
We’re excited to share that the newly revamped iOS demo app is live and includes many new updates to provide a more intuitive and smoother user experience with a chat use case! The primary goal of this app is to showcase how easily ExecuTorch can be integrated into an iOS demo app and how to exercise the many features ExecuTorch and Llama models have to offer.
This app serves as a valuable resource to inspire your creativity and provide foundational code that you can customize and adapt for your particular use case.
Please dive in and start exploring our demo app today! We look forward to any feedback and are excited to see your innovative ideas.
Key Concepts
From this demo app, you will learn many key concepts such as:
How to prepare Llama models, build the ExecuTorch library, and perform model inference across delegates
Expose the ExecuTorch library via Swift Package Manager
Familiarity with current ExecuTorch app-facing capabilities
The goal is for you to see the type of support ExecuTorch provides and feel comfortable with leveraging it for your use cases.
Supported Models
As a whole, the models that this app supports are (varies by delegate):
Llama 3.1 8B
Llama 3 8B
Llama 2 7B
Llava 1.5 (only XNNPACK)
Building the application
First it’s important to note that currently ExecuTorch provides support across several delegates. Once you identify the delegate of your choice, select the README link to get a complete end-to-end instructions for environment set-up to export the models to build ExecuTorch libraries and apps to run on device:
How to Use the App
This section will provide the main steps to use the app, along with a code snippet of the ExecuTorch API.
Swift Package Manager
ExecuTorch runtime is distributed as a Swift package providing some .xcframework as prebuilt binary targets. Xcode will download and cache the package on the first run, which will take some time.
Note: If you’re running into any issues related to package dependencies, quit Xcode entirely, delete the whole executorch repo, clean the caches by running the command below in terminal and clone the repo again.
rm -rf \
~/Library/org.swift.swiftpm \
~/Library/Caches/org.swift.swiftpm \
~/Library/Caches/com.apple.dt.Xcode \
~/Library/Developer/Xcode/DerivedData
Link your binary with the ExecuTorch runtime and any backends or kernels used by the exported ML model. It is recommended to link the core runtime to the components that use ExecuTorch directly, and link kernels and backends against the main app target.
Note: To access logs, link against the Debug build of the ExecuTorch runtime, i.e., the executorch_debug framework. For optimal performance, always link against the Release version of the deliverables (those without the _debug suffix), which have all logging overhead removed.
For more details integrating and Running ExecuTorch on Apple Platforms, checkout this link.
XCode
Open XCode and select “Open an existing project” to open
examples/demo-apps/apple_ios/LLama.Ensure that the ExecuTorch package dependencies are installed correctly, then select which ExecuTorch framework should link against which target.

Run the app. This builds and launches the app on the phone.
In app UI pick a model and tokenizer to use, type a prompt and tap the arrow buton
Copy the model to Simulator
Drag&drop the model and tokenizer files onto the Simulator window and save them somewhere inside the iLLaMA folder.
Pick the files in the app dialog, type a prompt and click the arrow-up button.
Copy the model to Device
Wire-connect the device and open the contents in Finder.
Navigate to the Files tab and drag&drop the model and tokenizer files onto the iLLaMA folder.
Wait until the files are copied.
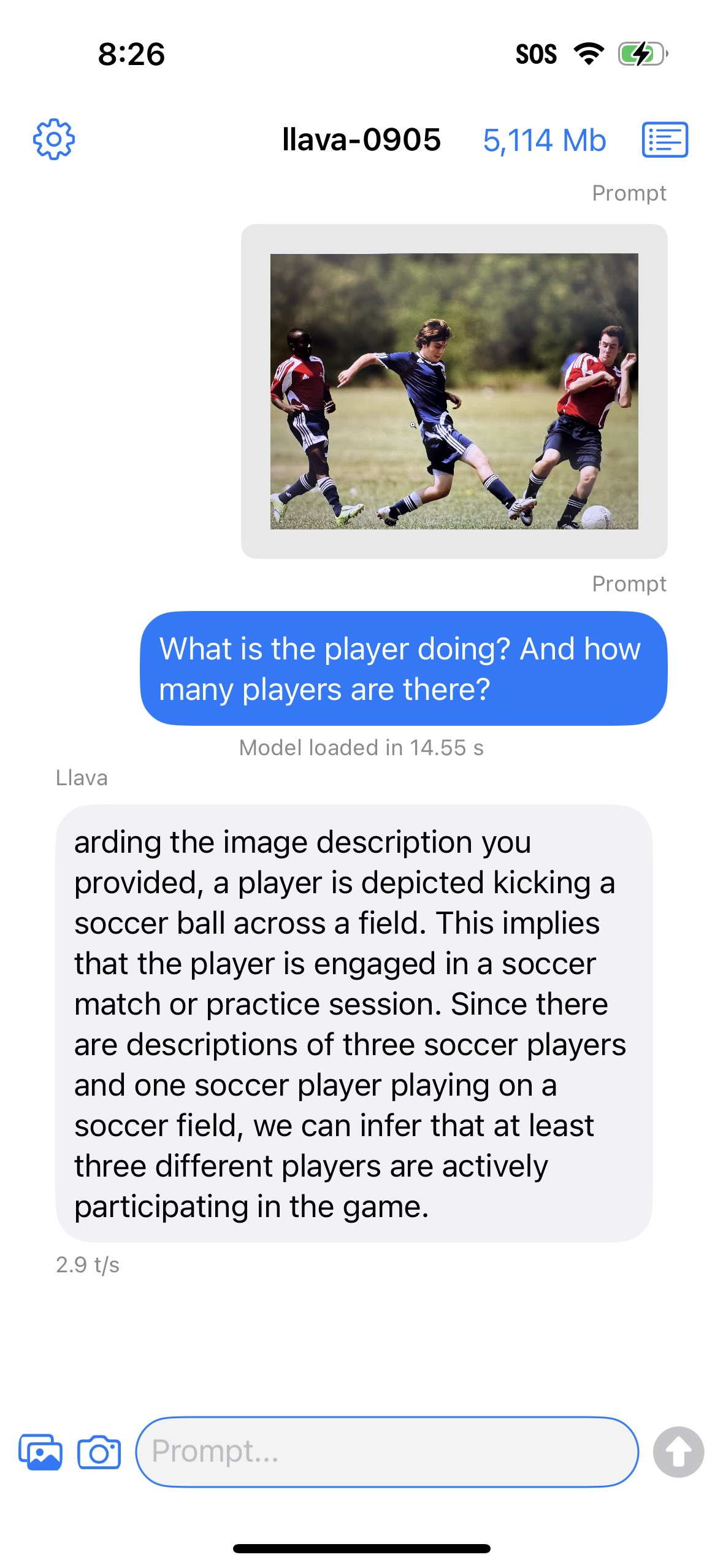
If the app successfully run on your device, you should see something like below:

For Llava 1.5 models, you can select and image (via image/camera selector button) before typing prompt and send button.
Reporting Issues
If you encountered any bugs or issues following this tutorial please file a bug/issue here on Github.
