Code available at: https://github.com/facebookresearch/ads_model_kernel_library
In this post, we present the design of TLX Block Attention — a Triton kernel targeting NVIDIA Blackwell GPUs that exploits compile-time knowledge of a block-diagonal attention pattern to eliminate entire categories of algorithmic overhead present in general-purpose attention implementations. On NVIDIA B200 GPUs, the kernel achieves a ~1.85× forward and ~2.50× backward speedup over Flash Attention v2, and a ~3.5× speedup for the combined attention-and-rotary backward pass when rotary embeddings are fused into the attention epilogue.
This work is built on TLX (Triton Language Extensions) — a set of low-level extensions to the Triton compiler that expose hardware-native control over warp specialization, asynchronous tensor core operations, and memory hierarchy management on NVIDIA Blackwell GPUs. TLX bridges the gap between Triton’s high-level Python productivity and the fine-grained hardware control traditionally requiring raw CUDA or CUTLASS. For more on TLX, see the triton-ext repository
───────────────────────────────────────
1. Introduction
Self-attention is a mechanism that lets a model weigh how relevant each element in a sequence is to every other element — essentially asking “which parts of this input should inform my understanding of each other part?” It’s the core building block of Transformer architectures and is what allows these models to capture rich, context-dependent relationships in data. A good intuition might be: how do one’s past decisions inform present and future ones?
Block-diagonal self-attention — where the sequence is partitioned into fixed-size groups that attend only within themselves — is a widely-used pattern in recommendation and feature-interaction models (BlockBERT, Qiu et al., EMNLP 2020) [1]. In our ads ranking stack, production workloads typically run batch sizes of 1152 with sequences up to ~4k tokens, head dimensions of 64 or 128, and ~70% sparsity in the attention structure with increasing sequence lengths. As these models grow deeper and wider, attention cost becomes the dominant bottleneck.
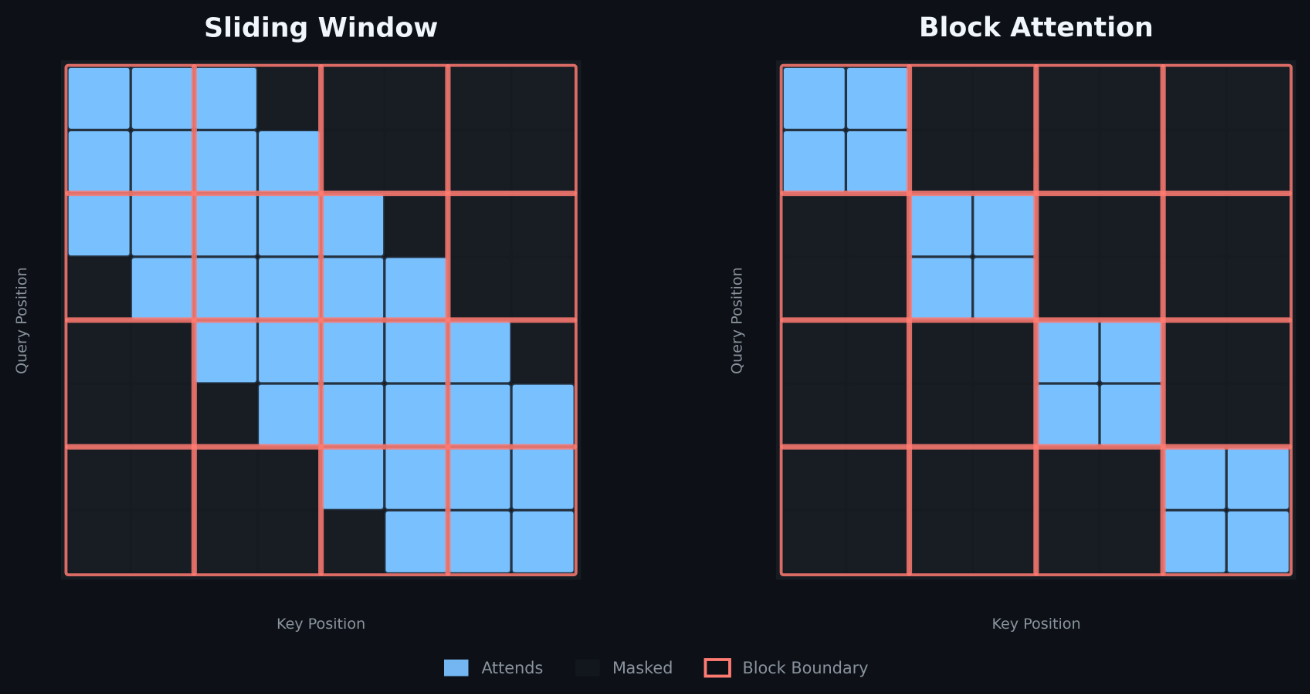 Today these workloads run on general-purpose kernels like Flash Attention v2 with block masking or sliding window. FlexAttention (FA4) [7] supports block-sparse patterns but operates at a minimum tile size of 256 — incompatible with the 64-token blocks these models require. Flash Attention v2 with block masking remains the strongest available baseline at this tile size, but leaves significant performance on the table. Flash Attention’s tiled iteration, online softmax correction, logsumexp bookkeeping, and auxiliary kernel launches are essential for arbitrary-length causal attention — but pure overhead when the pattern is block-diagonal and known at compile time.
Today these workloads run on general-purpose kernels like Flash Attention v2 with block masking or sliding window. FlexAttention (FA4) [7] supports block-sparse patterns but operates at a minimum tile size of 256 — incompatible with the 64-token blocks these models require. Flash Attention v2 with block masking remains the strongest available baseline at this tile size, but leaves significant performance on the table. Flash Attention’s tiled iteration, online softmax correction, logsumexp bookkeeping, and auxiliary kernel launches are essential for arbitrary-length causal attention — but pure overhead when the pattern is block-diagonal and known at compile time.
The central thesis of this work: when you know your attention pattern at compile time, you can build something much faster. We exploit the fixed constraint that every Q tile attends to exactly one K/V tile, propagating this knowledge through the entire algorithm to collapse multi-iteration accumulators into single GEMMs, eliminate correction stages, and remove auxiliary kernel launches.
───────────────────────────────────────
2. Why Block Attention?
2.1 The Fixed-Block Constraint and Its Cascade of Simplifications
Standard Flash Attention [2] handles sequences of arbitrary length by iterating a Q tile over multiple K/V tiles, maintaining running statistics (row-wise max and log-sum-exp) and applying a correction factor at each step to preserve numerical stability:
Listing 1: Standard Flash Attention inner loop showing multi-tile iteration and online softmax correction.
# Flash Attention inner loop (standard)
for k_tile in K_tiles:
S = Q @ k_tile.T # partial scores
m_new = max(m_old, rowmax(S))
alpha = exp(m_old - m_new) # correction factor
O = alpha * O + exp(S - m_new) @ v_tile
l = alpha * l + rowsum(exp(S - m_new))
O = O / l # final normalization
# Store L = m + log(l) to HBM for backward
This is correct and elegant for arbitrary sequences. But for block-diagonal attention with a fixed 64-token block size, the entire Q-tile-over-K-tiles loop is reduced to a single iteration. Every Q tile and its corresponding K/V tile are the same tile. That single constraint cascades through the algorithm:
- No multi-tile iteration. The score matrix S = Q · Kᵀ ∈ ℝ^{64×64} is complete after one GEMM. There is no loop to maintain state across.
- No online softmax correction. Since there is only one tile, the row-wise max and sum computed over S are globally correct immediately. The correction factor α = exp(m_old − m_new) is identically 1 and can be dropped entirely.
- No logsumexp (L) storage. Flash Attention stores the per-row log-sum-exp L to HBM so that the backward pass can recompute softmax. With a single tile, the backward pass can recompute P = softmax(S) directly from Q, K, V without any auxiliary tensor — eliminating an entire HBM write and read per forward/backward pair.
- No Di preprocessing kernel. The standard Flash Attention backward launches a separate kernel to compute Di = rowsum(dO ⊙ O) before the main backward pass. In TLX Block Attention, Di is computed inline within the dP/dS backward stage, eliminating a kernel launch and its associated memory traffic.
- No output accumulation with rescaling. With a single tile, the output O = P · V is a fresh result from a single GEMM, not an accumulation of multiple rescaled partial results. This enables
use_acc=Falseon all async_dot calls — telling the tensor core hardware that the TMEM accumulator need not be preserved across calls, allowing it to be freely reused.
Listing 2: use_acc=False signals to the hardware that no cross-tile accumulation is needed, enabling TMEM reuse.
# From the kernel: use_acc=False signals no accumulation needed
tlx.async_dot(
q_tile[buff_idx],
k_tile_T,
TMEMqk[tmem_idx],
use_acc=False, # Fresh result — no accumulation
mBarriers=[qk_SMEM_free[buff_idx], qk_TMEM_full[tmem_idx]],
)
2.2 Comparison with Standard Flash Attention
The following table summarizes the algorithmic differences:
| Aspect | Standard Flash Attention | TLX Block Attention |
| K tiles per Q tile | Many (full sequence) | Exactly 1 (same block) |
| Score matrix | Multiple tiles accumulated | Single [64, 64] — complete |
| Logsumexp L tensor | Stored to HBM for backward | Not needed |
| Running max/sum | Maintained across tiles | Computed once, consumed in-register |
| Correction factor α | Required every iteration | Not needed (dropped) |
| Output accumulation | Incremental with rescaling | Single P·V GEMM |
| use_acc mode | True (accumulate across tiles) | False (fresh result) |
| Di preprocessing | Separate kernel launch | Computed inline |
Table 1: Algorithmic differences between standard Flash Attention and TLX Block Attention.
These are not micro-optimizations — they represent the elimination of entire algorithmic stages. The backward pass in particular benefits substantially: the absence of a stored L tensor removes a round-trip through HBM per batch × heads × sequence, and inline Di computation removes a kernel launch with its associated driver overhead and memory bandwidth.
───────────────────────────────────────
3. Kernel Architecture: A Warp-Specialized Pipeline
3.1 TLX
We chose Triton as the authoring framework because it provides a Python-native, tile-oriented programming model that maps naturally to the warp-specialized pipeline structure described below — while avoiding the boilerplate of raw CUDA or CUTLASS and remaining portable across compiler evolution. Triton’s TLX (Triton Language Extensions) further expose Blackwell-specific primitives like async_dot, local_trans, and explicit TMEM/SMEM barrier management at a level of abstraction that balances hardware control with developer productivity. In our experience, TLX delivers performance on par with (and often exceeding) lower-level alternatives while enabling significantly faster iteration due to its Python-native simplicity.
Specifically, this kernel relies on several TLX primitives that go beyond base Triton: tlx.async_dot for issuing warp-specialized tcgen05 MMA operations with explicit accumulator control; tlx.async_descriptor_load for TMA-driven SMEM fills; tlx.local_trans for TMEM-to-register transfers; and the mBarrier synchronization model that coordinates the producer-consumer pipeline across warp groups. These extensions are available in the triton-ext repository.
3.2 Warp Specialization
TLX Block Attention uses warp specialization [8] — different warps within the same CTA are permanently assigned to different hardware units and execute different code paths throughout the kernel’s lifetime. This contrasts with the traditional CUDA model where all warps execute the same code and diverge only through conditionals.
| Stage | Warps | Registers | Hardware Unit | Role |
| Load | 1 | 48 | TMA engine | async_descriptor_load for Q, K, V |
| QK MMA | 1 | 48 | tcgen05 tensor cores | async_dot(Q, Kᵀ) → TMEMqk |
| Softmax | 4 | 120 | CUDA cores + SFU | mask / scale / exp2 / normalize → P to SMEM |
| PV MMA | 1 | 48 | tcgen05 tensor cores | async_dot(P, V) → TMEMpv |
| Epilogue | 8 | 200 | CUDA cores + L2 + TMA engine | TMEM → registers → BF16 → SMEM → TMAl store |
| Total | 15 | — | — | 480 threads per CTA |
Table 2: Forward pipeline stage configuration. Register allocations are deliberately asymmetric — hardware-accelerated stages receive minimal registers; CUDA core stages receive the most.
Fig. 1 — Forward pipeline warp timeline (conceptual, one iteration):
Time →
Load [─ TMA Q,K ─][─ TMA V ─]
QK MMA [── async_dot Q·Kᵀ ──]
Softmax [── exp2/normalize → P ──]
PV MMA [── async_dot P·V ──]
Epilogue [── local_load → BF16 → store ──]

Each stage’s output signals a barrier that unblocks the next stage, creating a producer-consumer pipeline across hardware units. While the Epilogue warp writes tile i to global memory, the MMA warps are computing tile i+1, and the Load warp is fetching tile i+2 via TMA — three tiles in flight simultaneously.
3.3 The Roofline Context
At BLOCK_D=64, HEAD_DIM=128, arithmetic intensity is ~33 FLOP/byte — well below the B200’s ridge point of ~281 FLOP/byte [4]. The kernel is memory-bandwidth bound by design. This is why latency hiding via TMA and minimizing unnecessary memory traffic (the eliminated L tensor, the fused rotary) are the dominant optimization levers.
3.4 Buffer Management
To keep hardware units continuously busy, the kernel uses triple-buffered SMEM (3 slots) and double-buffered TMEM (2 slots), consuming ~169 KB of the 256 KB SMEM budget. With three SMEM slots, the Load warp can prefetch tile i+2 while the MMA warp processes tile i+1 and the Epilogue warp drains tile i. The backward kernel drops to double-buffered SMEM (~162 KB) to accommodate additional gradient tiles within the same 256 KB budget.
───────────────────────────────────────
4. The Backward Pass: Gradients Without the Logsumexp Tensor
In standard Flash Attention, the backward pass requires the forward pass to save the logsumexp tensor (L) to High Bandwidth Memory (HBM). This tensor is necessary to reconstruct the attention probabilities (P) during the backward pass. Furthermore, standard attention requires a separate preprocessing kernel to compute Δᵢ (row-wise sum of dO ⊙ out).
Because block-diagonal attention computes the entire 64×64 score matrix in a single tile, we can bypass both requirements completely. The backward kernel does not read any logsumexp tensor, nor does it require a separate preprocessing step. Instead, it fully recomputes S = Q · Kᵀ and P = softmax(S) inline — a cheap operation when the tile fits in a single pass.
This cascade of simplifications allows us to build a fully fused, 7-stage warp-specialized backward pipeline:
| Stage | Warps | Registers | Hardware Unit | Role |
| Load | 1 | 48 | TMA engine | Loads Q, K, V, dO (+ sin/cos for rotary) |
| QK MMA | 1 | 48 | tcgen05 tensor cores | Recomputes S = Q · Kᵀ |
| Softmax/P | 4 | 120 | CUDA cores + SFU | Recomputes P = softmax(S) |
| dV MMA | 1 | 48 | tcgen05 tensor cores | dV = Pᵀ · dO |
| dP/dS | 4 | 120 | TC + CUDA cores | dP = dO · Vᵀ, Δᵢ, dS |
| dQ/dK MMA | 1 | 48 | tcgen05 tensor cores | dQ = dS · K, dK = dSᵀ · Q |
| Epilogue | 8 | 200 | CUDA cores + L2 + TMA engine | Stores dQ, dK, dV (+ fused rotary) |
| Total | 20 | — | — | 640 threads per CTA |
Table 4: 7-stage backward pipeline configuration.
The backward pass is inherently more complex than the forward pass. It requires 20 warps (640 threads per CTA) to balance the intense computational requirements. Most notably, it fully saturates the 256 KB Tensor Memory on the SM. The five distinct TMEM buffers — TMEMqk, TMEMdv, TMEMdp, TMEMdq, and TMEMdk — collectively hit 100% TMEM utilization. To accommodate this, the backward kernel drops from triple-buffered SMEM in the forward pass to double-buffered SMEM (~162 KB / 256 KB, 63%), while keeping double-buffered TMEM.
───────────────────────────────────────
5. Scheduling for Variable-Length Sequences
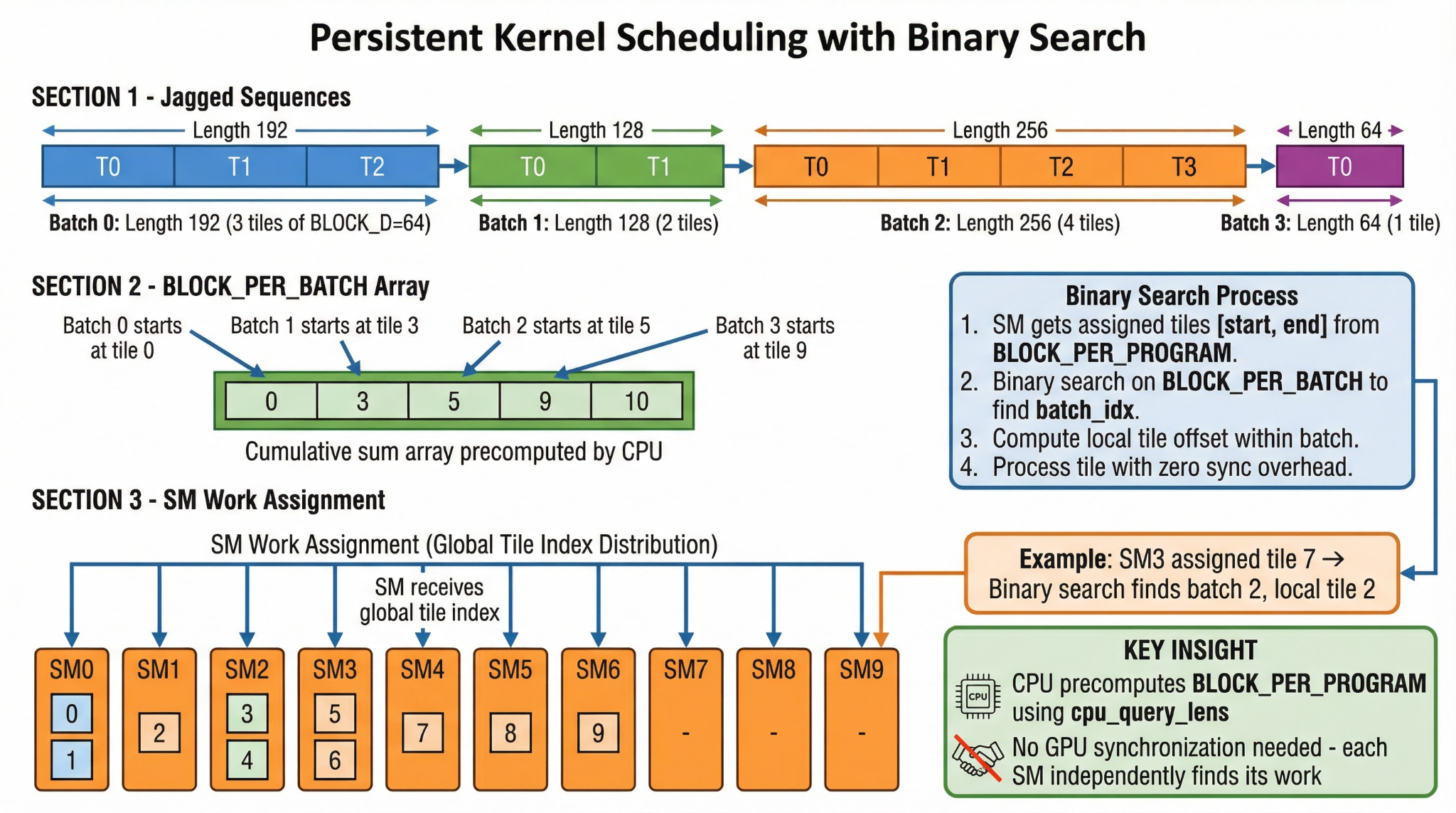 Real-world recommendation and feature interaction models do not process neatly uniform sequence lengths. Instead, traffic is dominated by jagged, variable-length sequences packed into a single flattened buffer. Naively mapping one CTA per sequence would leave SMs idle when short sequences finish early while others process long sequences — a severe workload imbalance.
Real-world recommendation and feature interaction models do not process neatly uniform sequence lengths. Instead, traffic is dominated by jagged, variable-length sequences packed into a single flattened buffer. Naively mapping one CTA per sequence would leave SMs idle when short sequences finish early while others process long sequences — a severe workload imbalance.
To maximize SM occupancy, the kernel launches min(NUM_SMS, total_blocks) persistent programs — exactly one persistent thread block per SM. Workload is balanced across two precomputed arrays:
- BLOCK_PER_BATCH: A prefix-sum of the number of 64-token tiles per sequence.
- BLOCK_PER_PROGRAM: The balanced tile ranges assigned to each SM — computed using closed-form divmod arithmetic rather than cumulative sums.
To eliminate GPU synchronization overhead, when CPU-side offset tensors are available (cpu_offsets), all scalar scheduling arithmetic (tile counts, divmod, prefix sums) is computed on the CPU before the kernel launches — zero GPU sync points.
Inside the kernel, each SM must determine which sequence (batch index) a given global tile index belongs to. This uses a branchless binary search that executes in exactly 32 iterations (sufficient for any reasonable batch size) with zero thread synchronization.
───────────────────────────────────────
6. Fused Rotary Backward: Higher Precision at Higher Speed
For self attention layers, self attention is preceded by projection + sinusoidals [6]. In the backward pass this becomes attention backward -> sinusoidals which conventionally happen with 2 different kernel launches.
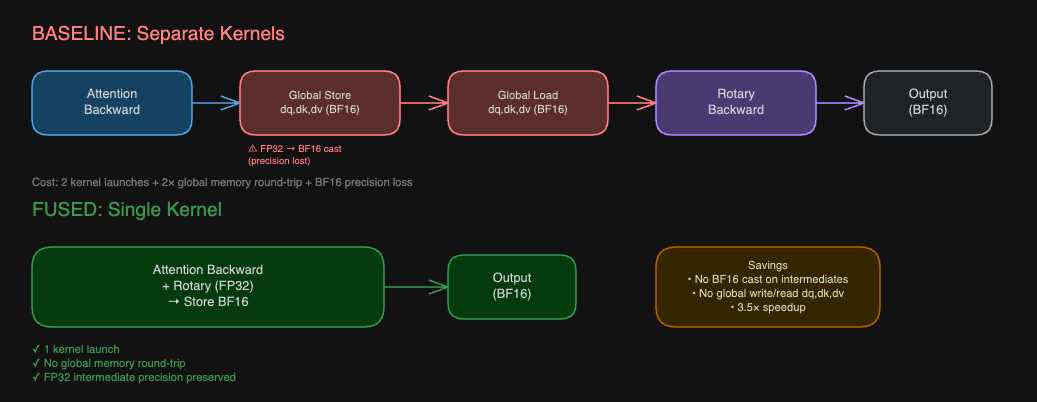 6.1 Baseline: Two-Kernel Backward Pass
6.1 Baseline: Two-Kernel Backward Pass
The conventional backward pass requires two separate kernel launches:
- Attention Backward Kernel — accumulates dQ, dK, dV in FP32 via tensor cores, then truncates to BF16 on store to global memory.
- Rotary Backward Kernel — reloads the BF16 gradients from global memory, applies the rotary conjugate R(−θ), and stores the final BF16 result.
This separation has three costs:
| Problem | Impact |
| Precision loss | FP32 gradients are truncated to BF16 before the rotary transform — then truncated again on final store. Two quantization points, each injecting ~0.4% relative error (BF16 has only 7 mantissa bits). Downstream projection GEMMs amplify the accumulated error. |
| Memory bandwidth waste | dQ, dK, dV are written then immediately re-read — a full round-trip on a [total_seq_len, 1152] tensor (head_dim=128, 3 KV heads). With sequence lengths in the millions, this traffic is substantial. |
| Kernel launch overhead | Two separate dispatches where one suffices. |
6.2 Fused Approach
The attention backward kernel already dedicates a single warp group to the gradient store epilogue. We take advantage of this by injecting the rotary conjugate into that epilogue, while gradients are still in FP32 registers:
- Tensor cores store dQ, dK, dV in FP32 (TMEM).
- Load FP32 values into registers.
- Apply R(−θ) in full FP32 precision — a lightweight sin/cos load + element-wise multiply.
- Cast to BF16 and issue a single global store.
The per-step comparison:
| Aspect | Baseline (Separate) | Fused Kernel |
| Attention backward computation | FP32 | FP32 |
| Intermediate storage | BF16 → global memory | FP32 registers |
| Rotary sin/cos operations | BF16 | FP32 |
| BF16 quantization points | 2 | 1 (final store only) |
| Global memory round-trips | 2 | 0 |
| Kernel launches | 2 | 1 |
Fused rotary conjugate in the backward epilogue. The interleave operation applies R(−θ) to paired [cos, sin] components while still in FP32.
# Apply rotary conjugate to dV (neg_sin handles the conjugate)
dv0, dv1 = dvLocal.reshape(BLOCK_D, HALF_DIM, 2).split()
dvLocal = tl.interleave(
dv0 * cos_local - dv1 * neg_sin,
dv1 * cos_local + dv0 * neg_sin,
)
───────────────────────────────────────
7. Performance Results
All benchmarks were conducted on NVIDIA B200 GPUs (x86 cpu) with BF16 precision. The primary configuration uses B=1152 sequences, HEAD_DIM=128, H=4 heads, max_seq_len=2000, and sparsity=0.7 – discrete uniform (representative of production traffic distributions).
7.1 Kernel-Level Speedup
| Pass | Flash Attention v2 with block attention (ms) | TLX Block Attention (ms) | Speedup |
| Forward | 1.81 | 0.98 | 1.85× |
| Backward | 5.89 | 2.36 | 2.50× |
| Total | 7.70 | 3.33 | 2.31× |
Table 5: Kernel-level performance comparison (B=1152, D=128, H=4, BF16, B200, max_seq_len=2000, sparsity=0.7).
The backward speedup (2.50×) is larger than the forward speedup (1.85×) primarily because the backward pass benefits from two independent simplifications: (1) eliminated logsumexp storage and Di preprocessing, and (2) inline P recomputation that avoids the L-tensor HBM round-trip that standard Flash Attention backward requires.
7.2 Scaling Across Workloads
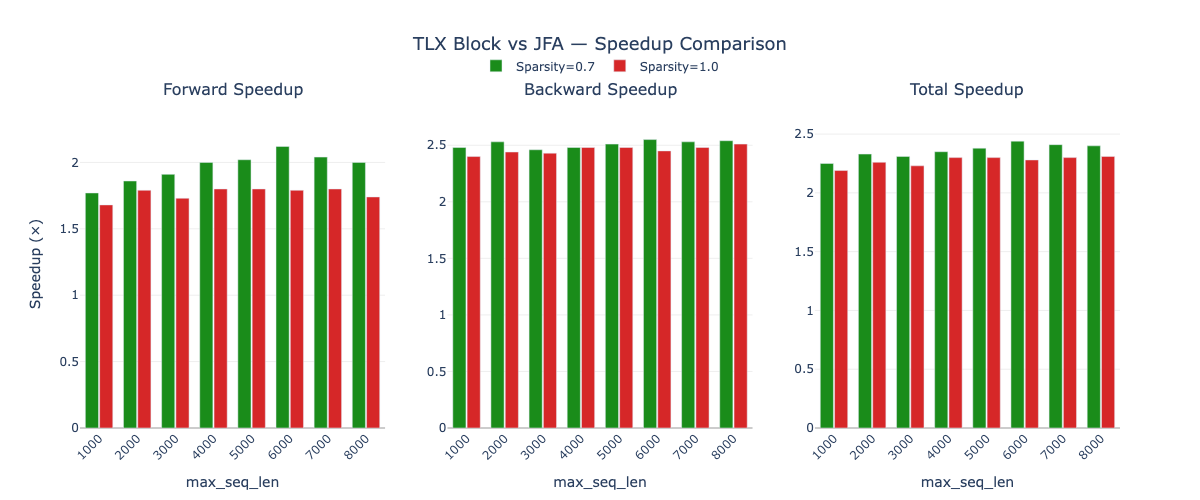
Table 6: Scaling performance across sequence lengths and sparsity ratios. Speedups are consistent regardless of distribution shape (batch=1152, for >7000 batch=768). Kernel speed up over flash attention v2 (jfa).
7.3 Fused Rotary Backward
The impact of fusing rotary backward into the attention epilogue is particularly striking:
| Configuration | Time (ms) |
| Attention backward (standalone) | 1.556 |
| Rotary backward (standalone) | 4.880 |
| Unfused total | 6.436 |
| Fused attention_rotary backward | 1.819 |
| Speedup | 3.54× |
Table 7: Fused vs. unfused rotary backward timing breakdown. The standalone rotary kernel dominates the unfused total. seq_len=1735537, heads=3, head_dim=128, batch=1152.
The standalone rotary backward is more than 3× more expensive than the attention backward itself — it is purely memory-bandwidth bound, reading and writing [M, D] tensors with no meaningful compute. Fusing it into the attention epilogue amortizes this bandwidth cost over the existing TMEM → register pipeline, reducing the combined operation from 6.436 ms to 1.819 ms.
End-to-end, integrating this kernel into self-attention layers results in a +30.6% Model FLOPs Utilization (MFU) gain on those layers.
7.4 Numerical Accuracy
Fusing the rotary backward into the FP32 epilogue also yields measurable accuracy improvements. Comparing against a high-precision PyTorch reference, TLX Block Attention reduces the maximum gradient error in the query gradients (dQ) by over 2×:
| Metric | Flash Attention v2 | TLX Block Attention | More Accurate |
| Max dQ diff | 0.2559 | 0.1201 | TLX |
| Max dK diff | 0.1689 | 0.1689 | Tie |
| Max dV diff | 0.0112 | 0.0112 | Tie |
| Avg dQ diff | 0.000309 | 0.000220 | TLX |
Table 8: Gradient numerical accuracy against a PyTorch reference implementation. TLX Block Attention reduces max dQ error by 53% due to the single-quantization-point fused rotary path.
dQ benefits most because the query gradient (dQ = dS · K) flows through the fused rotary conjugate with 1 quantization point instead of 2. dK also passes through the rotary conjugate (RoPE rotates both Q and K), but its maximum absolute error happens to be dominated by the MMA accumulation itself rather than the rotary memory round-trip, so the per-element improvement from eliminating the intermediate BF16 cast does not surface at the maximum.
───────────────────────────────────────
8. Applicability
If your model uses block-diagonal attention — where each token attends only to others within a fixed local group — this kernel is a direct fit.
- Training on NVIDIA Blackwell GPUs. The kernel uses tcgen05 MMA instructions, TMEM allocation, and Blackwell-era TMA descriptors — none of which exist on Ampere or Hopper. The async_dot / local_trans / tlx APIs target the Blackwell architecture (sm_100+) specifically.
- HEAD_DIM ∈ {64, 128}. These are the supported head dimensions; other values require recompilation and potentially new SMEM/TMEM budget calculations.
───────────────────────────────────────
9. Conclusion
TLX Block Attention demonstrates the compounding power of a single architectural constraint. By recognizing that a broad class of feature interaction and sequence models only require strict block-diagonal attention, a cascade of simplifications becomes possible.
Eliminating cross-block attention means no multi-tile accumulation. No multi-tile accumulation means no online softmax correction factors. No online softmax correction means the logsumexp tensor can be discarded entirely in the backward pass. No separate logsumexp tensor frees enough register and memory bandwidth budget to fully fuse the rotary embeddings directly into the backward epilogue, which independently improves both speed and numerical accuracy.
The result is a warp-specialized kernel perfectly tailored for the Blackwell architecture’s TMA and TMEM hardware primitives: 15 warps in the forward pass, 20 in the backward, each warp group permanently assigned to the hardware unit that matches its bottleneck. This design achieves 2.3× kernel-level speedups over Flash Attention v2, a 3.5× combined backward speedup when rotary is fused, and a +30.6% MFU gain on production self-attention layers.
The kernel is open-source at github.com/facebookresearch/ads_model_kernel_library — try it on your own block-sparse attention workloads and let us know what you find.
───────────────────────────────────────
Acknowledgements
The authors thank the Triton [5] and PyTorch teams for their continued development of the tlx Blackwell extension that made this kernel possible. Special thanks to the broader GPU kernel research community whose work on Flash Attention, warp-specialized pipelines, and persistent kernel scheduling provided the foundation for these optimizations.
───────────────────────────────────────
References
- Qiu, J., Ma, H., Levy, O., Yih, S. W., Wang, S., & Tang, J. (2020). BlockBERT: Efficient Attention Using Block Structures. EMNLP Findings 2020. https://arxiv.org/abs/1911.02972
- Dao, T., Fu, D. Y., Ermon, S., Rudra, A., & Ré, C. (2022). FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022. https://arxiv.org/abs/2205.14135
- Dao, T. (2024). FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. ICLR 2024. https://arxiv.org/abs/2307.08691
- NVIDIA Corporation. (2024). NVIDIA Blackwell Architecture Technical Brief. https://resources.nvidia.com/en-us-blackwell-architecture
- Tillet, P., Kung, H. T., & Cox, D. (2019). Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations. MAPL 2019. https://www.eecs.harvard.edu/~htk/publication/2019-mapl-tillet-kung-cox.pdf
- Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., & Liu, Y. (2021). RoFormer: Enhanced Transformer with Rotary Position Embedding. https://arxiv.org/abs/2104.09864
- He, H. & Guessous, D. (2024). FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention. PyTorch Blog. https://pytorch.org/blog/flexattention/
- Yu, H., Ren, M., Maher, B., Nay, S., Zhu, G., & Jiang, S. (2024). Enabling Advanced GPU Features in PyTorch – Warp Specialization. PyTorch Blog. https://pytorch.org/blog/warp-specialization/