Featured projects

TL;DR: This case study demonstrates how LinkedIn re-architected its distributed linear programming solver, DuaLip, by developing a GPU-accelerated PyTorch version to handle extreme-scale optimization challenges like web applications. This transition from a CPU-bound stack achieved order-of-magnitude speedups and efficient multi-GPU scaling while reducing engineering overhead.
Introduction
Modern internet platforms don’t just make predictions; they also make decisions. At companies like LinkedIn, these decisions power the intelligent behavior of large-scale web applications.
Behind the scenes, many of these systems reduce to a deceptively simple question:
Given millions (or billions) of options, what is the best set of actions to take under constraints?
This is where linear programming (LP) comes in as a foundational mathematical framework for optimizing an objective under constraints. At LinkedIn scale, these LPs can involve hundreds of millions of users and trillions of decision variables, with sparse but highly structured constraint matrices. Traditional LP solvers, such as simplex and interior-point methods, have historically been the workhorses of optimization. However, they rely on matrix factorizations or basis updates that become prohibitively expensive in both memory and computation at extreme scale. As a result, they often fail to handle modern web-scale problems efficiently.
The Business Challenge
Our goal was to optimize large-scale decision systems under competing objectives.
Examples include:
- Matching jobs to potential job seekers
- Balancing multiple business metrics in a ranking or recommendation system.
- Optimizing the volume of emails to be sent to users
These are inherently challenging optimization problems, where improving one metric (e.g., clicks) may hurt another (e.g., complaints). Formally, these problems are expressed as linear programs:
- Objective: maximize business value (e.g., engagement, revenue)
- Constraints: enforce limits (e.g., budget, fairness, frequency)
The key bottleneck is scalability: as the problem size grows, supporting fast, repeatable optimization in production requires implementations that are both memory- and time-efficient, while maintaining stability and solution quality.
In recent years, first-order methods have emerged as a practical alternative for solving such massive LPs. Unlike classical approaches, these methods rely only on gradient information and avoid expensive matrix factorizations, making their core operations dominated by matrix–vector multiplications. In particular, primal-dual formulations have proven especially effective: they recast the LP as a saddle-point problem and iteratively update primal and dual variables until convergence, often achieving sufficiently accurate solutions for production systems.
This line of work has led to a new generation of large-scale solvers, including systems like PDLP at Google and DuaLip at LinkedIn. DuaLip, in particular, is a distributed solver based on ridge-regularized dual ascent and first-order optimization. It exploits the decomposable structure of matching problems and uses accelerated gradient-based updates along with efficient projection operators to scale to extreme problem sizes.
While DuaLip demonstrates that first-order methods can handle web-scale LPs in production, its original implementation, built on a Scala/Spark stack, remains fundamentally CPU-bound. This limits its ability to fully leverage modern hardware accelerators. Additionally, its schema-bound, template-driven interface makes it difficult to extend to new problem formulations, slowing iteration for evolving use cases.
Motivated by these limitations, we re-architect the DuaLip solver stack in PyTorch with GPU acceleration, resulting in DuaLip-GPU as a modern, flexible, and scalable system for industrial-scale optimization.
How LinkedIn Uses PyTorch
To address these challenges, we propose DuaLip-PyTorch as a core execution engine for large-scale optimization—not just deep learning. The system is built around an operator-level array/tensor programming model (in the style of PyTorch’s define-by-run paradigm), rather than a task-level “call a solver” API.
Concretely, the hot path is expressed as an explicit dataflow over sparse matrix–vector operations and blockwise projections, orchestrated by a lightweight maximizer. This design boundary is intentional: it exposes the kernels that dominate runtime, enables flexible choices of sparse layouts and projection operators, and maps naturally to GPU execution—all without requiring changes to the core optimization loop.
Solving AI Challenges with PyTorch
PyTorch provides native GPU acceleration, flexible tensor abstractions for both sparse and dense computation, and efficient matrix-vector operations for gradient computation. Together, these capabilities allow large-scale LP solving to look structurally similar to neural network training, but with optimization-specific primitives. At LinkedIn, these features helped address three major systems and optimization challenges.
First, extreme-scale LPs containing billions to trillions of variables were implemented using sparse tensor operations and batched projection kernels, enabling efficient execution on GPUs.
Second, distributed optimization was achieved by partitioning variables across GPUs while replicating and synchronizing dual variables through collective communication patterns such as all-reduce and broadcast, allowing near-linear scaling across devices.
Third, convergence speed was improved through a combination of row normalization and scaling for better conditioning, regularization continuation strategies, and scalable first-order optimization methods including AGD and FISTA-style variants. These improvements significantly reduce solve time while maintaining accuracy.
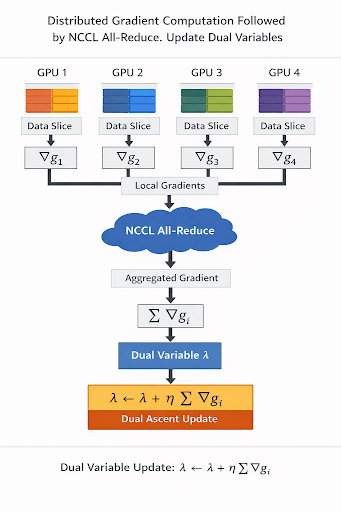
Figure 1. High-level architecture of Dualip-Pytorch
The Benefits of Using PyTorch
Using PyTorch allowed LinkedIn to:
- Achieve order-of-magnitude speedups over CPU-based systems
- Scale efficiently from single GPU to multi-GPU systems
- Support flexible, extensible LP formulations
- Reduce engineering overhead for new optimization problems
- Bridge ML and optimization into a unified stack
Most importantly, it enabled production-grade optimization at previously infeasible scales by restructuring the solver around GPU-efficient sparse linear algebra.
The dominant computation in DuaLip-Pytorch consists of repeated sparse matrix–vector multiplications and projection updates, which map naturally to high-throughput GPU execution. By expressing these operations as batched tensor kernels in PyTorch and distributing them across multiple GPUs with synchronous collective communication, the system achieved significantly lower per-iteration solve time compared to the original CPU-based implementation.
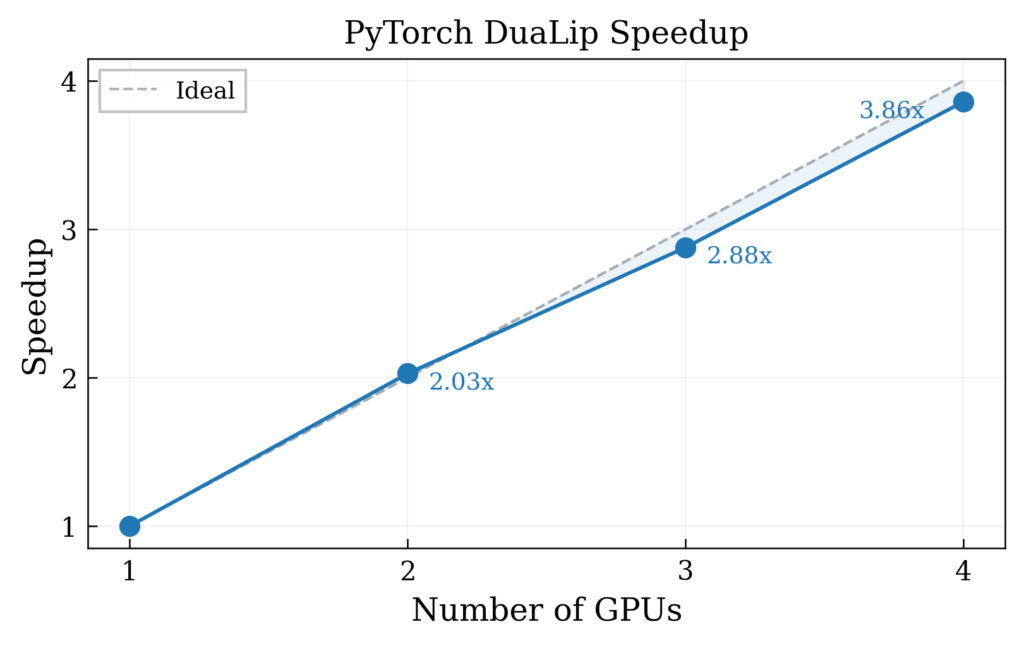
Figure 2. Speed up curve against the number of GPUs compared to the ideal (linear line). All GPUs are located on one node.
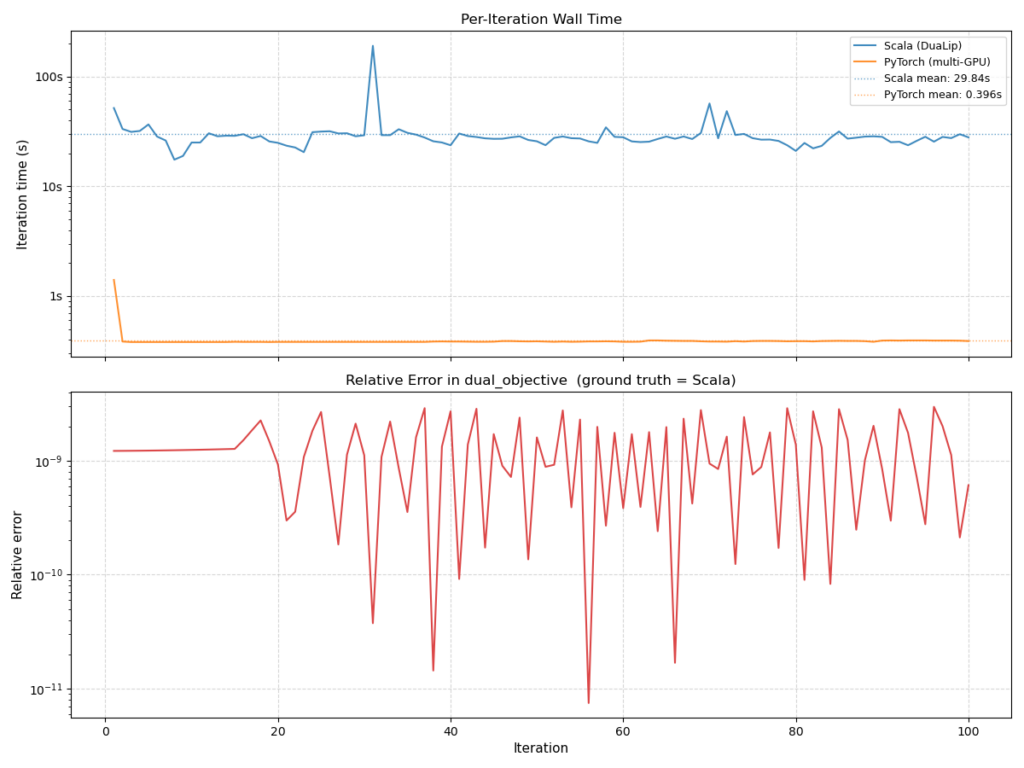
Figure 3. Scala-Pytorch comparison in terms of speed and relative error. Pytorch solver (8 GPUs) exhibits significant gain (75 times faster) in per-iteration wall clock time.
Learn More
For more information:
- DuaLip-GPU Technical Report: https://arxiv.org/abs/2603.04621
- Open-source implementation: https://github.com/linkedin/DuaLip