We are excited to announce the release of PyTorch® 1.13 (release note)! This includes Stable versions of BetterTransformer. We deprecated CUDA 10.2 and 11.3 and completed migration of CUDA 11.6 and 11.7. Beta includes improved support for Apple M1 chips and functorch, a library that offers composable vmap (vectorization) and autodiff transforms, being included in-tree with the PyTorch release. This release is composed of over 3,749 commits and 467 contributors since 1.12.1. We want to sincerely thank our dedicated community for your contributions.
Summary:
- The BetterTransformer feature set supports fastpath execution for common Transformer models during Inference out-of-the-box, without the need to modify the model. Additional improvements include accelerated add+matmul linear algebra kernels for sizes commonly used in Transformer models and Nested Tensors is now enabled by default.
- Timely deprecating older CUDA versions allows us to proceed with introducing the latest CUDA version as they are introduced by Nvidia®, and hence allows support for C++17 in PyTorch and new NVIDIA Open GPU Kernel Modules.
- Previously, functorch was released out-of-tree in a separate package. After installing PyTorch, a user will be able to
import functorchand use functorch without needing to install another package. - PyTorch is offering native builds for Apple® silicon machines that use Apple’s new M1 chip as a beta feature, providing improved support across PyTorch’s APIs.
Along with 1.13, we are also releasing major updates to the PyTorch libraries, more details can be found in this blog.
Stable Features
(Stable) BetterTransformer API
The BetterTransformer feature set, first released in PyTorch 1.12, is stable. PyTorch BetterTransformer supports fastpath execution for common Transformer models during Inference out-of-the-box, without the need to modify the model. To complement the improvements in Better Transformer, we have also accelerated add+matmul linear algebra kernels for sizes commonly used in Transformer models.
Reflecting the performance benefits for many NLP users, Nested Tensors use for Better Transformer is now enabled by default. To ensure compatibility, a mask check is performed to ensure a contiguous mask is supplied. In Transformer Encoder, the mask check for src_key_padding_mask may be suppressed by setting mask_check=False. This accelerates processing for users than can guarantee that only aligned masks are provided. Finally, better error messages are provided to diagnose incorrect inputs, together with improved diagnostics why fastpath execution cannot be used.
Better Transformer is directly integrated into the PyTorch TorchText library, enabling TorchText users to transparently and automatically take advantage of BetterTransformer speed and efficiency performance. (Tutorial)
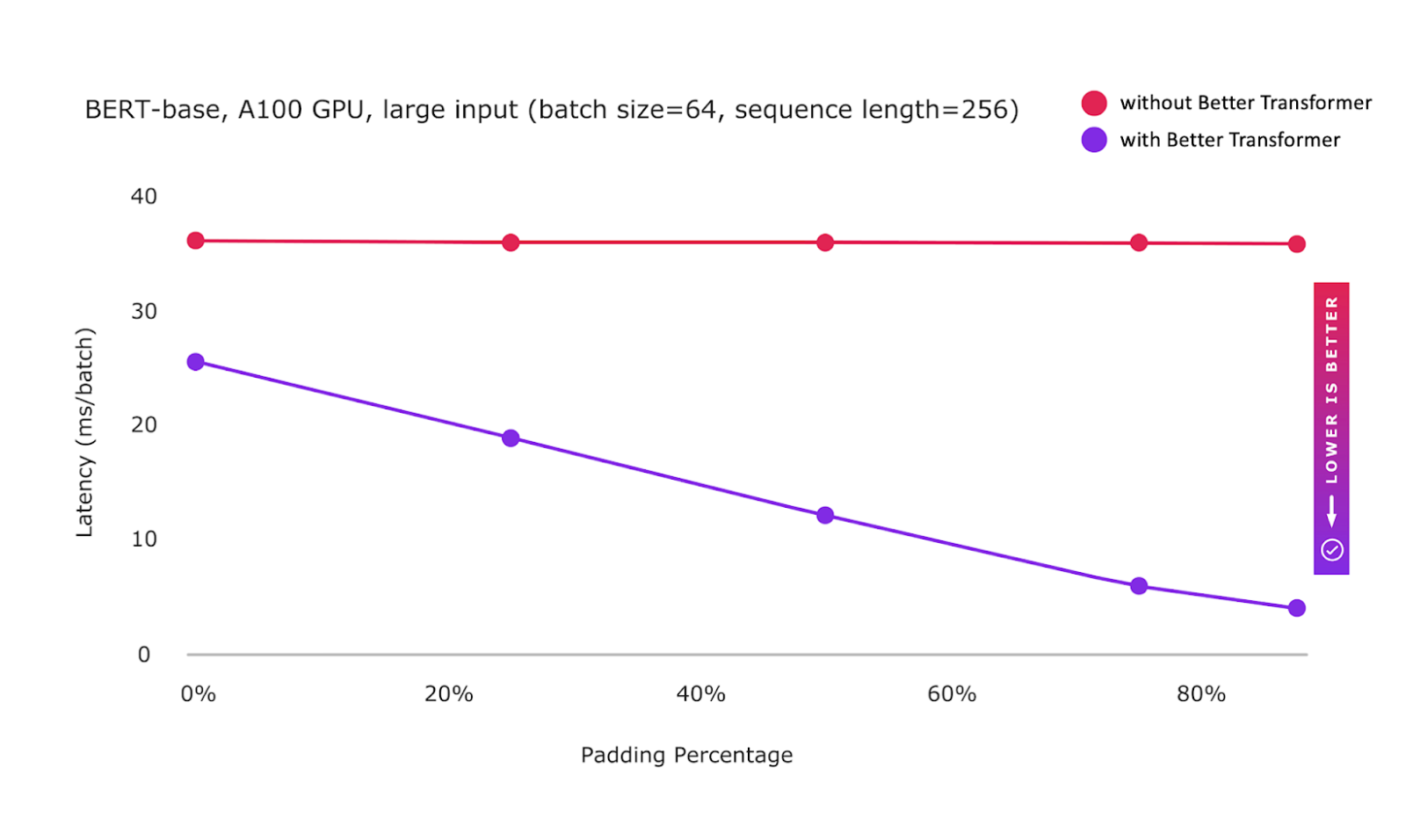
Figure: BetterTransformer fastpath execution is now stable and enables sparsity optimization using Nested Tensor representation as default
Introduction of CUDA 11.6 and 11.7 and deprecation of CUDA 10.2 and 11.3
Timely deprecating older CUDA versions allows us to proceed with introducing the latest CUDA version as they are introduced by Nvidia®, and hence allows developers to use the latest features of CUDA and benefit from correctness fixes provided by the latest version.
Decommissioning of CUDA 10.2. CUDA 11 is the first CUDA version to support C++17. Hence decommissioning legacy CUDA 10.2 was a major step in adding support for C++17 in PyTorch. It also helps to improve PyTorch code by eliminating legacy CUDA 10.2 specific instructions.
Decommissioning of CUDA 11.3 and introduction of CUDA 11.7 brings compatibility support for the new NVIDIA Open GPU Kernel Modules and another significant highlight is the lazy loading support. CUDA 11.7 is shipped with cuDNN 8.5.0 which contains a number of optimizations accelerating transformer-based models, 30% reduction in library size , and various improvements in the runtime fusion engine. Learn more on CUDA 11.7 with our release notes.
Beta Features
(Beta) functorch
Inspired by Google® JAX, functorch is a library that offers composable vmap (vectorization) and autodiff transforms. It enables advanced autodiff use cases that would otherwise be tricky to express in PyTorch. Examples include:
- model ensembling
- efficiently computing jacobians and hessians
- computing per-sample-gradients (or other per-sample quantities)
We’re excited to announce that, as a first step towards closer integration with PyTorch, functorch has moved to inside the PyTorch library and no longer requires the installation of a separate functorch package. After installing PyTorch via conda or pip, you’ll be able to `import functorch’ in your program. Learn more with our detailed instructions, nightly and release notes.
(Beta) Intel® VTune™ Profiler’s Instrumentation and Tracing Technology APIs (ITT) integration
PyTorch users are able to visualize op-level timeline of PyTorch scripts execution in Intel® VTune™ Profiler when they need to analyze per-op performance with low-level performance metrics on Intel platforms.
with torch.autograd.profiler.emit_itt():
for i in range(10):
torch.itt.range_push('step_{}'.format(i))
model(input)
torch.itt.range_pop()
Learn more with our tutorial.
(Beta) NNC: Add BF16 and Channels last support
TorchScript graph-mode inference performance on x86 CPU is boosted by adding channels last and BF16 support to NNC. PyTorch users may benefit from channels last optimization on most popular x86 CPUs and benefit from BF16 optimization on Intel Cooper Lake Processor and Sapphire Rapids Processor. >2X geomean performance boost is observed on broad vision models with these two optimizations on Intel Cooper Lake Processor.
The performance benefit can be obtained with existing TorchScript, channels last and BF16 Autocast APIs. See code snippet below. We will migrate the optimizations in NNC to the new PyTorch DL Compiler TorchInductor.
import torch
import torchvision.models as models
model = models.resnet50(pretrained=True)
# Convert the model to channels-last
model = model.to(memory_format=torch.channels_last)
model.eval()
data = torch.rand(1, 3, 224, 224)
# Convert the data to channels-lastdata = data.to(memory_format=torch.channels_last)
# Enable autocast to run with BF16
with torch.cpu.amp.autocast(), torch.no_grad():
# Trace the model
model = torch.jit.trace(model, torch.rand(1, 3, 224, 224))
model = torch.jit.freeze(model)
# Run the traced model
model(data)
(Beta) Support for M1 Devices
Since v1.12, PyTorch has been offering native builds for Apple® silicon machines that use Apple’s new M1 chip as a prototype feature. In this release, we bring this feature to beta, providing improved support across PyTorch’s APIs.
We now run tests for all submodules except torch.distributed on M1 macOS 12.6 instances. With this improved testing, we were able to fix features such as cpp extension and convolution correctness for certain inputs.
To get started, just install PyTorch v1.13 on your Apple silicon Mac running macOS 12 or later with a native version (arm64) of Python. Learn more with our release notes.
Prototype Features
(Prototype) Arm® Compute Library (ACL) backend support for AWS Graviton
We achieved substantial improvements for CV and NLP inference on aarch64 cpu with Arm Compute Library (acl) to enable acl backend for pytorch and torch-xla modules. Highlights include:
- Enabled mkldnn + acl as the default backend for aarch64 torch wheel.
- Enabled mkldnn matmul operator for aarch64 bf16 device.
- Brought TensorFlow xla+acl feature into torch-xla. We enhanced the TensorFlow xla with Arm Compute Library runtime for aarch64 cpu. These changes are included in TensorFlow master and then the upcoming TF 2.10. Once the torch-xla repo is updated for the tensorflow commit, it will have compiling support for torch-xla. We observed ~2.5-3x improvement for MLPerf Bert inference compared to the torch 1.12 wheel on Graviton3.
(Prototype) CUDA Sanitizer
When enabled, the sanitizer begins to analyze low-level CUDA operations invoked as a result of the user’s PyTorch code to detect data race errors caused by unsynchronized data access from different CUDA streams. The errors found are then printed along with stack traces of faulty accesses, much like Thread Sanitizer does. An example of a simple error and the output produced by the sanitizer can be viewed here. It will be especially useful for machine learning applications, where corrupted data can be easy to miss for a human and the errors may not always manifest themselves; the sanitizer will always be able to detect them.
(Prototype) Limited Python 3.11 support
Binaries for Linux with Python 3.11 support are available to download via pip. Please follow the instructions on the get started page. Please note that Python 3.11 support is only a preview. In particular, features including Distributed, Profiler, FX and JIT might not be fully functional yet.