Basic Concepts
This describes the high level concepts behind TorchX and the project structure. For how to create and run an app check out the Quickstart Guide.
Project Structure
The top level modules in TorchX are:
torchx.specs: application spec (job definition) APIstorchx.components: predefined (builtin) app specstorchx.workspace: handles patching images for remote executiontorchx.cli: CLI tooltorchx.runner: given an app spec, submits the app as a job on a schedulertorchx.schedulers: backend job schedulers that the runner supportstorchx.pipelines: adapters that convert the given app spec to a “stage” in an ML pipeline platformtorchx.runtime: util and abstraction libraries you can use in authoring apps (not app spec)
Below is a UML diagram
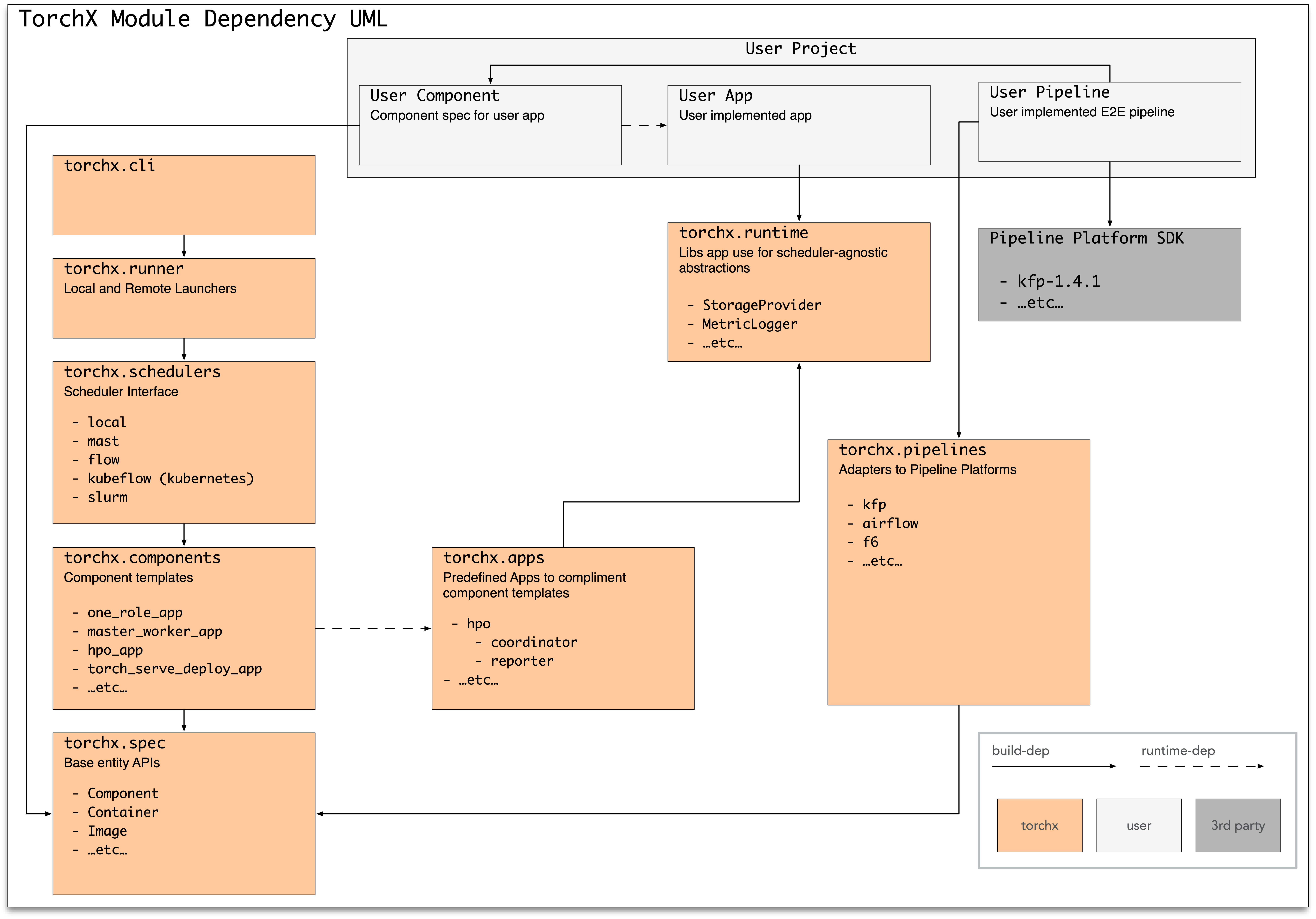
Concepts
AppDefs
In TorchX an AppDef is simply a struct with the definition of
the actual application. In scheduler lingo, this is a JobDefinition and a
similar concept in Kubernetes is the spec.yaml. To disambiguate between the
application binary (logic) and the spec, we typically refer to a TorchX
AppDef as an “app spec” or specs.AppDef. It
is the common interface understood by torchx.runner
and torchx.pipelines allowing you to run your app as a standalone job
or as a stage in an ML pipeline.
Below is a simple example of an specs.AppDef that echos “hello world”
import torchx.specs as specs
specs.AppDef(
name="echo",
roles=[
specs.Role(
name="echo",
entrypoint="/bin/echo",
image="/tmp",
args=["hello world"],
num_replicas=1
)
]
)
As you can see, specs.AppDef is a pure python dataclass that
simply encodes the name of the main binary (entrypoint), arguments to
pass to it, and a few other runtime parameters such as num_replicas and
information about the container in which to run (entrypoint=/bin/echo).
The app spec is flexible and can encode specs for a variety of app topologies.
For example, num_replicas > 1 means that the application is distributed.
Specifying multiple specs.Roles makes it possible to represent a
non-homogeneous distributed application, such as those that require a single
“coordinator” and many “workers”.
Refer to torchx.specs API Docs to learn more.
What makes app specs flexible also makes it have many fields. The good
news is that in most cases you don’t have to build an app spec from scratch.
Rather you would use a templetized app spec called components.
Components
A component in TorchX is simply a templetized spec.AppDef. You can
think of them as convenient “factory methods” for spec.AppDef.
Note
Unlike applications, components don’t map to an actual python dataclass.
Rather a factory function that returns an spec.AppDef
is called a component.
The granularity at which the app spec is templetized varies. Some components
such as the echo example above are ready-to-run, meaning that they
have hardcoded application binaries. Others such as ddp (distributed data parallel)
specs only specify the topology of the application. Below is one possible templetization
of a ddp style trainer app spec that specifies a homogeneous node topology:
import torchx.specs as specs
def ddp(jobname: str, nnodes: int, image: str, entrypoint: str, *script_args: str):
single_gpu = specs.Resources(cpu=4, gpu=1, memMB=1024)
return specs.AppDef(
name=jobname,
roles=[
specs.Role(
name="trainer",
entrypoint=entrypoint,
image=image,
resource=single_gpu,
args=script_args,
num_replicas=nnodes
)
]
)
As you can see, the level of parameterization is completely up to the component author. And the effort of creating a component is no more than writing a python function. Don’t try to over generalize components by parameterizing everything. Components are easy and cheap to create, create as many as you want based on repetitive use cases.
PROTIP 1: Since components are python functions, component composition can be achieved through python function composition rather than object composition. However we do not recommend component composition for maintainability purposes.
PROTIP 2: To define dependencies between components, use a pipelining DSL. See Pipeline Adapters section below to understand how TorchX components are used in the context of pipelines.
Before authoring your own component, browse through the library of Components that are included with TorchX to see if one fits your needs.
Runner and Schedulers
A Runner does exactly what you would expect – given an app spec it
launches the application as a job onto a cluster through a job scheduler.
There are two ways to access runners in TorchX:
CLI:
torchx run ~/app_spec.pyProgrammatically:
torchx.runner.get_runner().run(appspec)
See Schedulers for a list of schedulers that the runner can launch apps to.
Pipeline Adapters
While runners launch components as standalone jobs, torchx.pipelines
makes it possible to plug components into an ML pipeline/workflow. For a
specific target pipeline platform (e.g. kubeflow pipelines), TorchX
defines an adapter that converts a TorchX app spec to whatever the
“stage” representation is in the target platform. For instance,
torchx.pipelines.kfp adapter for kubeflow pipelines converts an
app spec to a kfp.ContainerOp (or more accurately, a kfp “component spec” yaml).
In most cases an app spec would map to a “stage” (or node) in a pipeline. However advanced components, especially those that have a mini control flow of its own (e.g. HPO), may map to a “sub-pipeline” or an “inline-pipeline”. The exact semantics of how these advanced components map to the pipeline is dependent on the target pipeline platform. For example, if the pipeline DSL allows dynamically adding stages to a pipeline from an upstream stage, then TorchX may take advantage of such feature to “inline” the sub-pipeline to the main pipeline. TorchX generally tries its best to adapt app specs to the most canonical representation in the target pipeline platform.
See Pipelines for a list of supported pipeline platforms.
Runtime
Important
torchx.runtime is by no means is a requirement to use TorchX.
If your infrastructure is fixed and you don’t need your application
to be portable across different types of schedulers and pipelines,
you can skip this section.
Your application (not the app spec, but the actual app binary) has ZERO dependencies
to TorchX (e.g. /bin/echo does not use TorchX, but a echo_torchx.py component
can be created for it).
Note
torchx.runtime is the ONLY module you should be using when
authoring your application binary!
However because TorchX essentially allows your app to run anywhere it is recommended that your application be written in a scheduler/infrastructure agnostic fashion.
This typically means adding an API layer at the touch-points with scheduler/infra. For example the following application is NOT infra agnostic
import boto3
def main(input_path: str):
s3 = boto3.session.Session().client("s3")
path = s3_input_path.split("/")
bucket = path[0]
key = "/".join(path[1:])
s3.download_file(bucket, key, "/tmp/input")
input = torch.load("/tmp/input")
# ...<rest of code omitted for brevity>...
The binary above makes an implicit assumption that the input_path
is an AWS S3 path. One way to make this trainer storage agnostic is to introduce
a FileSystem abstraction layer. For file systems, frameworks like
PyTorch Lightning already define io
layers (lightning uses fsspec
under the hood). The binary above can be rewritten to be storage agnostic with
lightning.
import pytorch_lightning.utilities.io as io
def main(input_url: str):
fs = io.get_filesystem(input_url)
with fs.open(input_url, "rb") as f:
input = torch.load(f)
# ...<rest of code omitted for brevity>...
Now main can be called as main("s3://foo/bar") or main("file://foo/bar")
making it compatible with input stored in various storages.
With FileSystem there were existing libraries defining the file system abstraction.
In the torchx.runtime, you’ll find libraries or pointers to other libraries
that provide abstractions for various functionalities that you may need to author
a infra-agnostic application. Ideally features in torchx.runtime are upstreamed
in a timely fashion to libraries such as lightning that are intended to be used to
author your application. But finding a proper permanent home for these abstractions
may take time or even require an entirely new OSS project to be created.
Until this happens the features can mature and be accessible to users
through the torchx.runtime module.
Next Steps
Check out the Quickstart Guide to learn how to create and run components.
