


Note
Go to the end to download the full example code.
Get started with your own first training loop
Author: Vincent Moens
Note
To run this tutorial in a notebook, add an installation cell at the beginning containing:
!pip install tensordict !pip install torchrl
Time to wrap up everything we’ve learned so far in this Getting Started series!
In this tutorial, we will be writing the most basic training loop there is using only components we have presented in the previous lessons.
We’ll be using DQN with a CartPole environment as a prototypical example.
We will be voluntarily keeping the verbosity to its minimum, only linking each section to the related tutorial.
Building the environment
We’ll be using a gym environment with a StepCounter
transform. If you need a refresher, check our these features are presented in
the environment tutorial.
import torch
torch.manual_seed(0)
import time
from torchrl.envs import GymEnv, StepCounter, TransformedEnv
env = TransformedEnv(GymEnv("CartPole-v1"), StepCounter())
env.set_seed(0)
from tensordict.nn import TensorDictModule as Mod, TensorDictSequential as Seq
Designing a policy
The next step is to build our policy. We’ll be making a regular, deterministic version of the actor to be used within the loss module and during evaluation. Next, we will augment it with an exploration module for inference.
from torchrl.modules import EGreedyModule, MLP, QValueModule
value_mlp = MLP(out_features=env.action_spec.shape[-1], num_cells=[64, 64])
value_net = Mod(value_mlp, in_keys=["observation"], out_keys=["action_value"])
policy = Seq(value_net, QValueModule(spec=env.action_spec))
exploration_module = EGreedyModule(
env.action_spec, annealing_num_steps=100_000, eps_init=0.5
)
policy_explore = Seq(policy, exploration_module)
Data Collector and replay buffer
Here comes the data part: we need a data collector to easily get batches of data and a replay buffer to store that data for training.
from torchrl.collectors import SyncDataCollector
from torchrl.data import LazyTensorStorage, ReplayBuffer
init_rand_steps = 5000
frames_per_batch = 100
optim_steps = 10
collector = SyncDataCollector(
env,
policy_explore,
frames_per_batch=frames_per_batch,
total_frames=-1,
init_random_frames=init_rand_steps,
)
rb = ReplayBuffer(storage=LazyTensorStorage(100_000))
from torch.optim import Adam
Loss module and optimizer
We build our loss as indicated in the dedicated tutorial, with its optimizer and target parameter updater:
from torchrl.objectives import DQNLoss, SoftUpdate
loss = DQNLoss(value_network=policy, action_space=env.action_spec, delay_value=True)
optim = Adam(loss.parameters(), lr=0.02)
updater = SoftUpdate(loss, eps=0.99)
Logger
We’ll be using a CSV logger to log our results, and save rendered videos.
from torchrl._utils import logger as torchrl_logger
from torchrl.record import CSVLogger, VideoRecorder
path = "./training_loop"
logger = CSVLogger(exp_name="dqn", log_dir=path, video_format="mp4")
video_recorder = VideoRecorder(logger, tag="video")
record_env = TransformedEnv(
GymEnv("CartPole-v1", from_pixels=True, pixels_only=False), video_recorder
)
Training loop
Instead of fixing a specific number of iterations to run, we will keep on training the network until it reaches a certain performance (arbitrarily defined as 200 steps in the environment – with CartPole, success is defined as having longer trajectories).
total_count = 0
total_episodes = 0
t0 = time.time()
for i, data in enumerate(collector):
# Write data in replay buffer
rb.extend(data)
max_length = rb[:]["next", "step_count"].max()
if len(rb) > init_rand_steps:
# Optim loop (we do several optim steps
# per batch collected for efficiency)
for _ in range(optim_steps):
sample = rb.sample(128)
loss_vals = loss(sample)
loss_vals["loss"].backward()
optim.step()
optim.zero_grad()
# Update exploration factor
exploration_module.step(data.numel())
# Update target params
updater.step()
if i % 10:
torchrl_logger.info(f"Max num steps: {max_length}, rb length {len(rb)}")
total_count += data.numel()
total_episodes += data["next", "done"].sum()
if max_length > 200:
break
t1 = time.time()
torchrl_logger.info(
f"solved after {total_count} steps, {total_episodes} episodes and in {t1-t0}s."
)
Rendering
Finally, we run the environment for as many steps as we can and save the video locally (notice that we are not exploring).
record_env.rollout(max_steps=1000, policy=policy)
video_recorder.dump()
This is what your rendered CartPole video will look like after a full training loop:
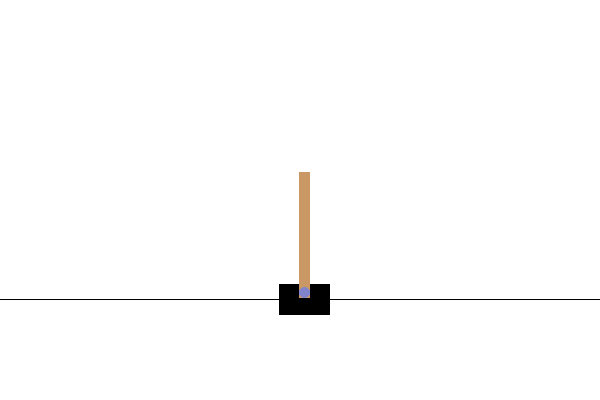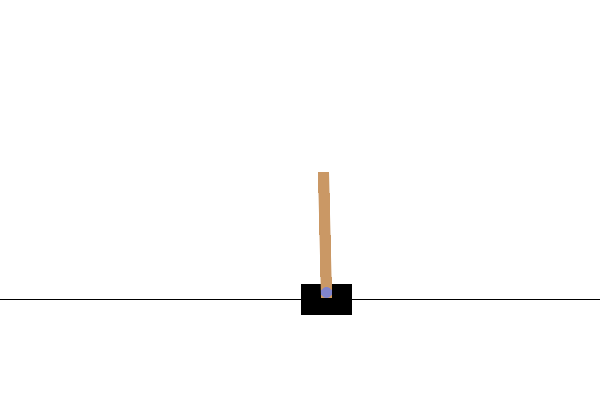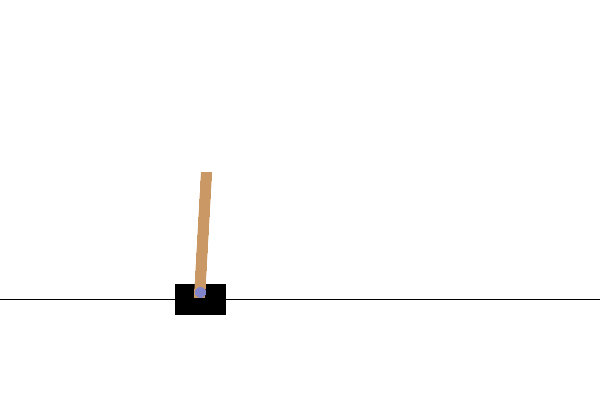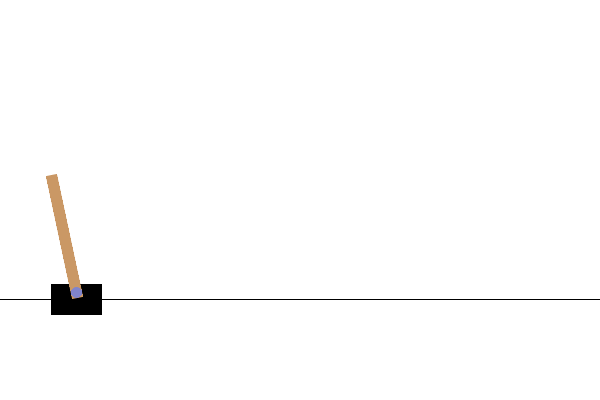
This concludes our series of “Getting started with TorchRL” tutorials! Feel free to share feedback about it on GitHub.
