Featured projects


TL;DR
Helion, PyTorch’s domain-specific language (DSL) for performance portable machine learning kernels, heavily relies on autotuning for performance. Currently Helion searches utilize the Likelihood-Free Bayesian Optimization (LFBO) to find the most performant configs. LFBO is a strong baseline which works well, but it still grinds through hundreds of compile-and-benchmark cycles per kernel. To this end, we introduce an LLM-guided autotuner that matches LFBO-level kernel performance (geomean 1.009X) while benchmarking ~10X fewer configurations in ~6.7X less wall-clock time. For the handful of kernels where the LLM trails by >5%, a hybrid strategy (LLM seeding followed by LFBO refinement) closes the gap while remaining ~3X cheaper than the full LFBO search. Finally, the result is largely LLM model-independent — Opus-4.8, gpt-5.5, and Sonnet-4.6 perform within a couple percent of each other — showing that LLM-guided autotuning is a practical approach to dramatically faster kernel tuning at production quality.
Introduction
Autotuning is the backbone of Helion – PyTorch’s DSL for authoring performant and portable ML kernels. Every Helion kernel is tuned across a vast, high-dimensional configuration space (tile sizes, block sizes, num_warps, num_stages, see documentation for more) to reach peak performance on the target hardware. Reducing the tuning time is also critical for developer velocity and production deployment, which impacts Helion adoption.
The autotuner searches the combinatorial space to find configurations, benchmarks each configuration, and keeps the best. Making that search faster and smarter is an active area of work. Helion’s current default autotuner uses LFBO (Likelihood-Free Bayesian Optimization), where a lightweight Random Forest classifier is trained during the search on the fly on the benchmarked data, learning to predict which configurations are promising candidates. It uses the prediction to focus on the parameters that matter the most to take targeted jumps through the space. LFBO search is now the default, as it showed substantial improvements in both kernel performance and tuning time on NVIDIA and AMD GPUs. See our PyTorch blog “Accelerating Autotuning in Helion with Bayesian Optimization” for more details.
LFBO is a strong baseline which works well, but it still grinds through hundreds of compile-and-benchmark cycles per kernel. What if, instead of starting the search blindly, you could ask an LLM to reason about the kernel and propose configurations? That’s the LLM-guided autotuner – for each round of autotuning, an LLM is shown the kernel, the workload, and the best-so-far configs to propose new configs to try. In this blog, we describe how the LLM-guided autotuner works and show benchmarking results comparing the LLM-guided search to LFBO search on 33 (11 kernels x 3 shapes) cases on B200. Results show that the new LLM-based approach reaches LFBO-level kernel performance while compiling/benchmarking 10X less configs, leading to 6.7X less wall-clock time. We also introduce a hybrid search to combine the best of both worlds, which uses an LLM to quickly get to a performant configuration, followed by LFBO for fine-grained search.
How the LLM-Guided Autotuner Works
Operating through multiple cycles of prompts and feedback, the new LLM-based autotuner executes a population-based search. In the initial phase, Helion provides the kernel and the associated details to the LLM to ask for a set of candidate configurations. Once LLM responds, Helion compiles and benchmarks the configs, retaining the top-performing configurations. Subsequent refinement rounds then occur, where the LLM is given the most successful configs, their performance metrics, and an analysis of successful patterns to guide specific mutations. If no significant performance gains are detected, the process terminates early. An example process is shown for an rms_norm kernel running on a B200 GPU.
The Initial Prompt
The initial prompt sets the role of the LLM, provides the knobs, and gives the output contract:
You are an expert GPU kernel autotuner for Helion/Triton kernels.
Use the provided Configuration Space and Default Configuration as the source of truth for allowed field names, scalar-vs-list, required list lengths, valid ranges and defaults.
Output contract:
-Return minified JSON on a single line: {"configs":[...]}. No markdown/fences/comments.
-Only specify fields you want to change; unspecified = default.
-For list-valued fields, emit a JSON array of the exact required length shown in the space.
-If unsure about a field's structure, length, or allowed values, omit it instead of guessing.
Helion also provides the kernel, the target hardware, and the configuration space. The rms_norm kernel prompt has:
- Kernel source: The actual @helion.kernel source code
- Input Tensors: e.g.: arg[0]: shape=[4096, 1024], dtype=torch.float16, …
- GPU Hardware: e.g.: NVIDIA B200, 148 SMs, 178.4 GB, 2048 threads/SM
- Configuration Space: Every tunable field with type/range
- Default Configuration: The baseline config.
The Helion compiler also analyzes the kernel to add heuristics to the prompt. For rms_norm:
## Compiler Analysis
Helion's compiler statically analyzed this kernel's structure and derived the following structural priors. Treat them as strong starting points.
**Compiler-derived seed config(s):**
```json
{"block_sizes":[1],"load_eviction_policies":["last","last","last","last","last"],"reduction_loops":[null]}
What the Model Returns
A minified JSON with 15 configs. Opus-4.8’s first reply for rms_norm:
{"configs":[
{"block_sizes":[1],"load_eviction_policies":["last","last","last","last","last"]},
{"block_sizes":[1]},
{"block_sizes":[4],"load_eviction_policies":["last", "..."],"num_warps":8},
{"block_sizes":[8],"load_eviction_policies":["last", "..."],"num_warps":8,"num_stages":2},
{"block_sizes":[16],"load_eviction_policies":["last", "..."],"num_warps":8,"num_stages":4},
{"block_sizes":[1],"load_eviction_policies":["last", "..."],"pid_type":"persistent_blocked"}
….
]}
Helion’s harness parses this, drops malformed and duplicate configs to compile and benchmark them.
Refinement Rounds
After benchmarking, each subsequent round sends a refinement prompt built from the search state:
- Search state: Round number, population size, best perf so far.
- Anchor configs: Top configs to mutate around.
- Results: Measured performance for the benchmarked configs.
- Top/failed config patterns: Which field values correlate with fast vs. failed/slow configs.
- Next Step: Recommendations based on failure-rate of configs
So the model anchors on the best and avoids the patterns that failed. The feedback loop stops early if relative improvement from each round drops below ~0.5%.
LLM-Seeded LFBO: The Best of Both Worlds
We also explore a hybrid strategy (LLM-Seeded LFBO Search) to address LLM’s tendency to leave micro-architectural knobs unexplored. This approach merges the complementary advantages of both LLM and LFBO: the LLM provides a strong starting point, while LFBO excels at local search.
The Hybrid Workflow
- Stage 1 – LLM Seeding: The process begins with a single round of LLM-Guided Search, as described “The Initial Prompt” above. Helion benchmarks to validate and retain the top configs.
- Handoff: The most successful LLM-generated configs serve as the starting point for the next phase to train LFBO’s surrogate model. This allows LFBO to begin with immediate knowledge of promising regions rather than starting from a blank slate.
- Stage 2 – LFBO Refinement: LFBO Search is executed with its initial population seeded. LFBO performs its iterative loop: updating the Random-Forest classifier, predicting top candidates, and mutating critical parameters based on feature importance. This cycle continues until performance gains stall or reaches the maximum number (20) of iterations.
The system returns the optimal configuration found across both stages. By leveraging a high-quality starting point and an informed surrogate, the hybrid search converges significantly faster than a cold LFBO search. This efficiency allows the search budget to be focused on fine-tuning the specific micro-architectural knobs that the LLM may not find.
Benchmarking Results
The Methodology
We compare LFBO (LFBOTreeSearch with full effort) to LLM-Guided Search using Opus 4.8 across 11 kernels — matmul (square + split-K), grouped-GEMM, attention, fp8-attention, softmax, rms_norm, rope, swiglu, mamba2, and gated-delta-net — on small, medium, and large shapes on NVIDIA B200.
Result 1: The Efficiency Win
This is where the LLM shines, matching LFBO’s quality with significantly smaller search cost.
- Geomean configs benchmarked: 9.8X fewer configs (~55 vs ~546 per kernel) for LLM-guided autotuner. This is a machine-independent metric that demonstrates the efficacy of the new approach.
- Geomean wall-clock time: 6.7X less end-to-end tuning time (39 s vs 261 s), measured on a 384-thread host. The end-to-end tuning time consists of config generation (for the LLM, including its API round-trips), Triton/ptxas compilation of every candidate, and GPU benchmarking of every candidate.
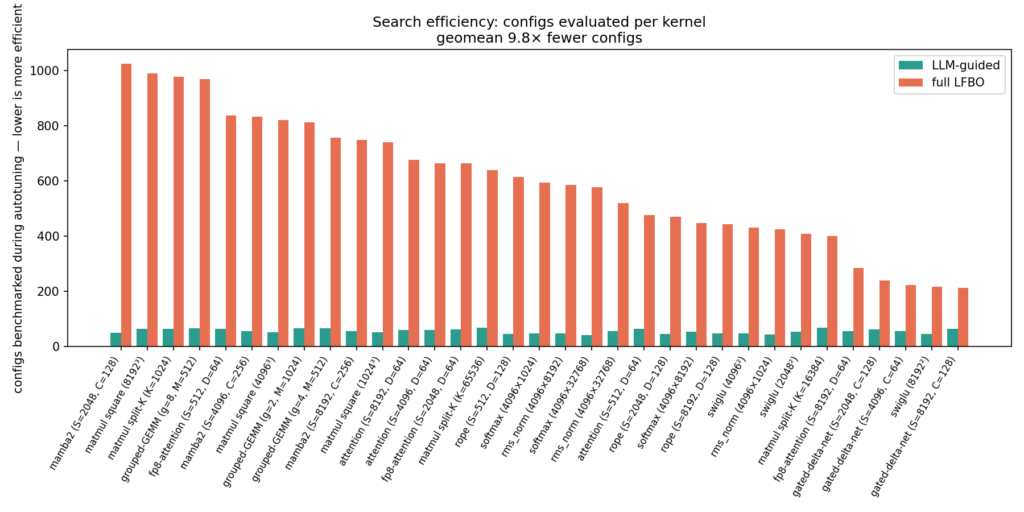
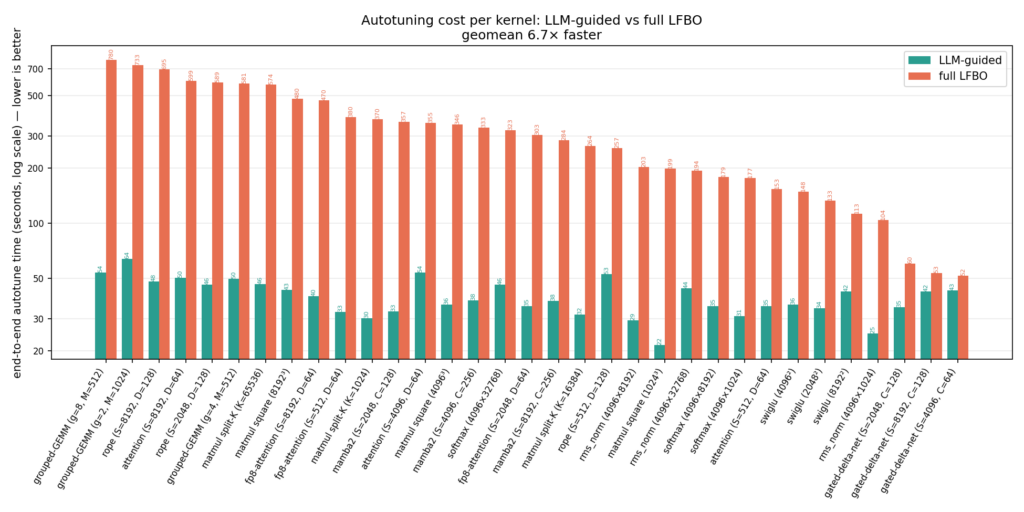
End-to-end tuning time is dominated by compiling candidate configs, where Helion precompiles them in parallel across CPU cores. As this host has 100s of threads, compilation is heavily parallelized. On a machine with fewer cores, the LLM’s ~10X fewer configs would translate into a proportionally larger wall-clock time reduction. The machine-independent metrics are the number of configs benchmarked and how fast the best configs converge to their optimal results (shown below).
Result 2: LLM Converges in the First ~7% of LFBO Budget
Plotting best-config-so-far against search effort makes the difference vivid. The LLM drops to its plateau in a few dozen configs.
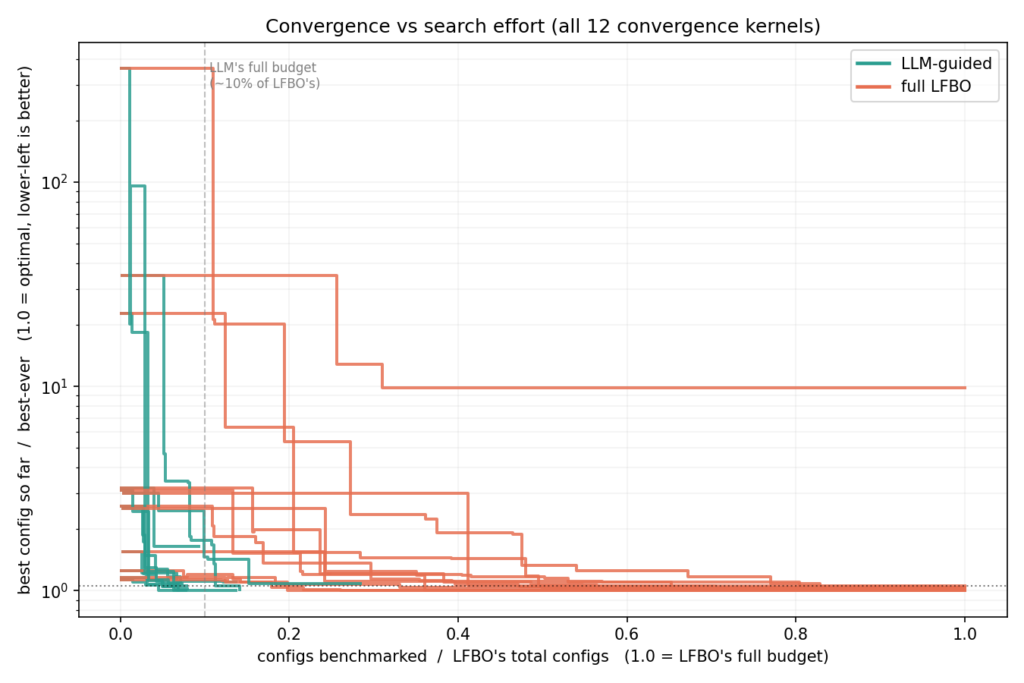
Across all 12 convergence kernels, the LLM drops to its plateau inside roughly the first ~7% of LFBO’s budget. On grouped GEMM (g=4, m=512), that’s 18X fewer configs than LFBO at the same kernel performance.
Result 3: LLM Delivers LFBO-level Performance
On kernel performance, the LLM is roughly on-par with LFBO, with the geomean performance of LLM kernel/LFBO kernel latency being 1.009X.
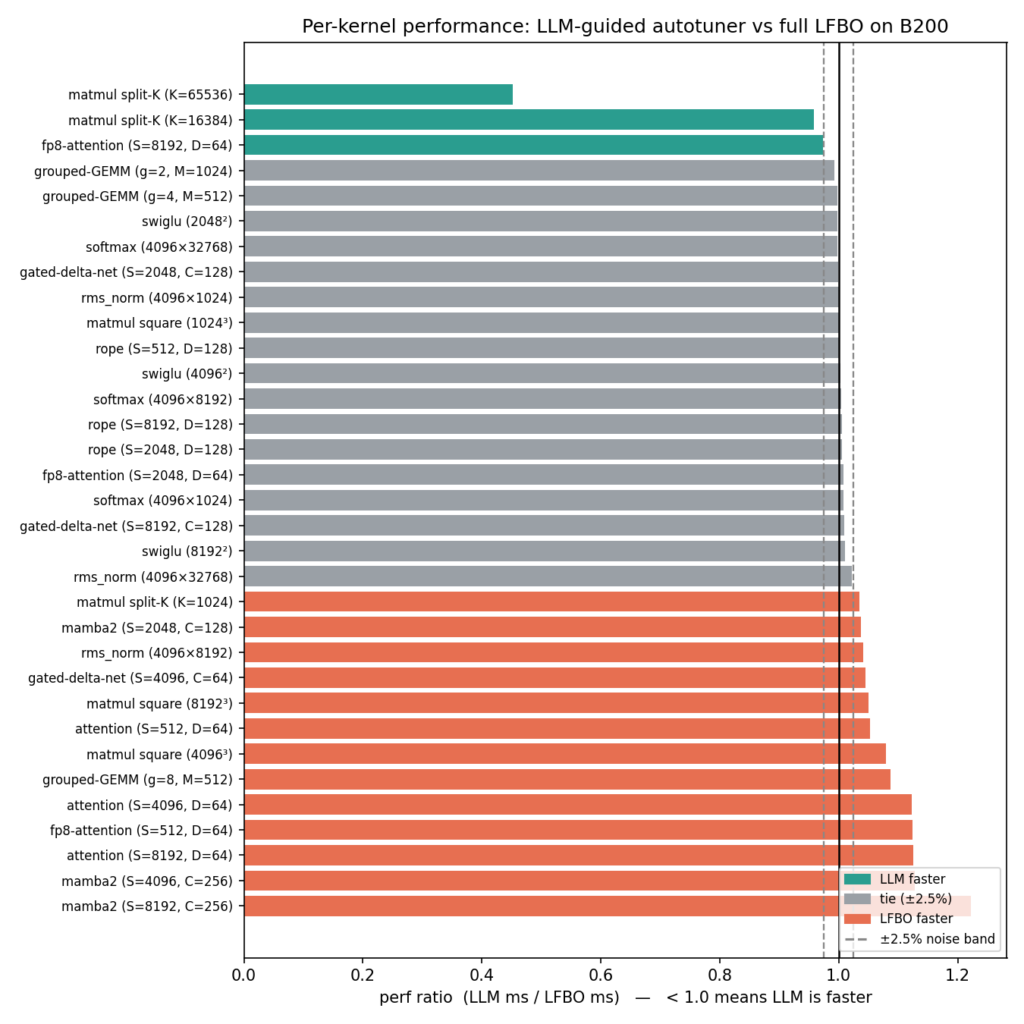
Hence LLM gives you a good config fast, while LFBO can outperform at the cost of more config exploration and tuning time. There are 8 cases where LLM loses to LFBO by more than 5% in kernel performance.
Can the Hybrid Search Close the Gap?
If LLM’s weakness is leaving fine tuning the knobs, we can use our hybrid search strategy with LLM-Seeded LFBO TreeSearch.
We ran the hybrid search on the 8 cases where the LLM trails LFBO by more than 5%.
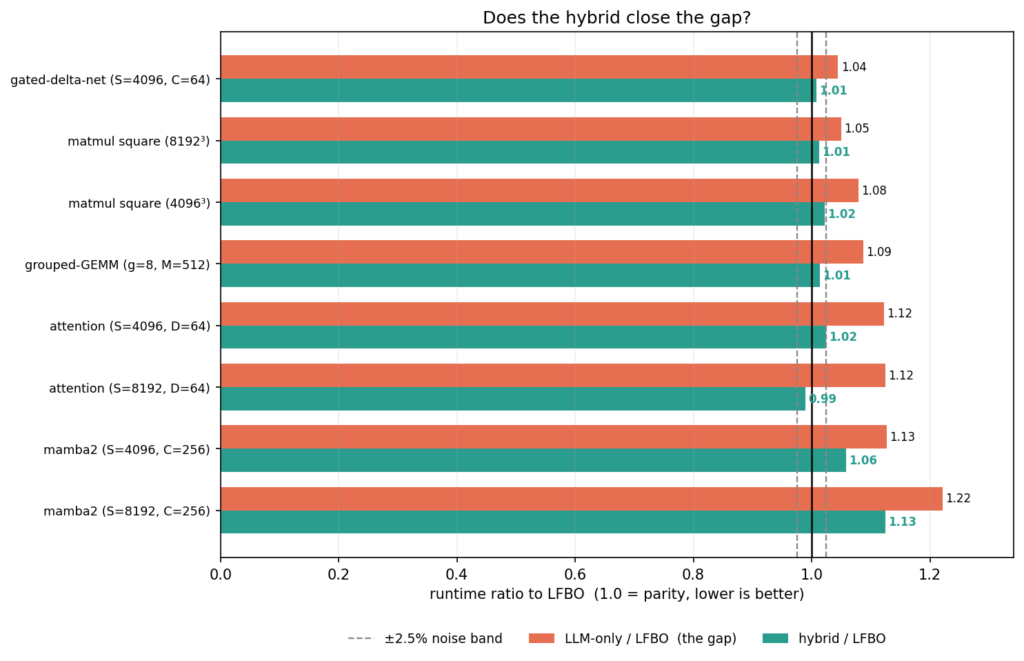
The hybrid strategy improves kernel performance in all cases and closes the gap to LFBO in 6/8 cases. The mamba2 family still does worse than LFBO and we are investigating improving the LLM heuristics to close this gap.
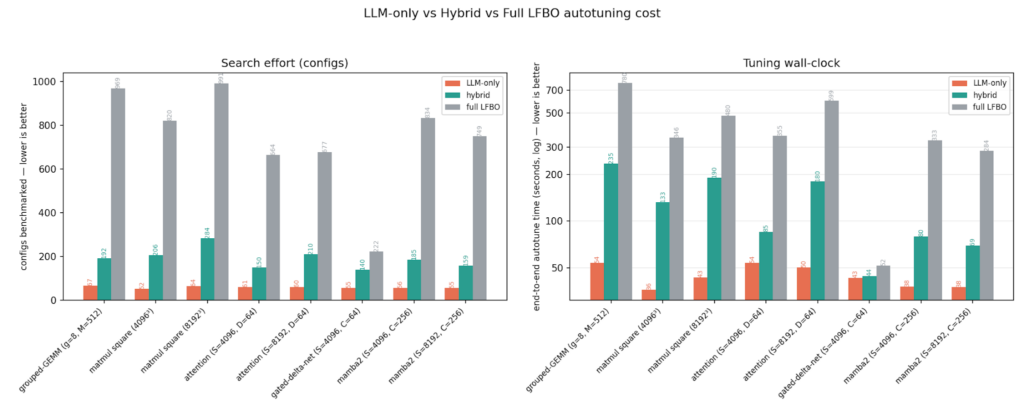
In terms of autotuning time, hybrid search is significantly more efficient than LFBO. Across the 8 kernels, it explores 4X fewer configs LFBO, leading to 3X faster end-to-end autotuning time. The geomean results comparing LLM-only, hybrid, and LFBO are shown below.
| LLM-only | Hybrid | Full LFBO | |
| Autotuning Time | 44 s | 111 s | 328 s |
| Explored Configs | 59 | 186 | 686 |
We also present the individual kernel results below comparing the number of explored configs as well as their tuning times:
Does the Model Matter?
Everything above used one model: Claude Opus-4.8. One may ask whether the model doing the work is load-bearing, or whether any capable LLM gets you the same place. To this end, we benchmark the LLM-only search (LLM-Guided Search) across the full 33-kernel instances with two more models, OpenAI gpt-5.5 and Claude Sonnet-4.6, to compare to the Opus 4.8 baseline.
| model | geomean perf vs Opus-4.8 | Geomean configs explored |
| Opus-4.8 | 1.00 (baseline) | 55 |
| gpt-5.5 | 0.98 | 61 |
| Sonnet-4-6 | 1.03 | 51 |
In geomean, all 3 models performed very similarly and interestingly, Sonnet-4.6 did it with the fewest number of configs.
Conclusions
The question we set out to answer was, “Can an LLM autotune Helion kernels as well as the LFBO search, but far more cheaply? Across a 33-kernel suite, benchmarked on B200, the answer is yes.
The efficiency gain is substantial: The LLM-guided autotuner converges to LFBO-quality results in 7% of LFBO’s budget, explores ~10X fewer configurations, with ~6.7X reduction in wall-clock time, offering a massive boost in developer velocity.
LLM reaches LFBO-level performance: The LLM-guided autotuner ties the LFBO search on most kernels and even wins on some. There are cases that LFBO wins at the cost of higher autotuning time.
Hybrid strategy bridges the gap: The hybrid approach (LLM seeding followed by LFBO refinement) can recover remaining performance while remaining ~3X cheaper than a LFBO search.
The Practical Recipe: For a streamlined workflow, we suggest trying the LLM-only search to rapidly identify a high-performance kernel. To maximize performance, users can apply the hybrid search to refine and capture the final performance gains. Moving forward, we plan to enhance the heuristics to further boost the effectiveness of both the LLM-guided and hybrid autotuners.