


Note
Click here to download the full example code
Forced Alignment with Wav2Vec2
Author: Moto Hira
This tutorial shows how to align transcript to speech with
torchaudio, using CTC segmentation algorithm described in
CTC-Segmentation of Large Corpora for German End-to-end Speech
Recognition.
Note
This tutorial was originally written to illustrate a usecase for Wav2Vec2 pretrained model.
TorchAudio now has a set of APIs designed for forced alignment.
The CTC forced alignment API tutorial illustrates the
usage of torchaudio.functional.forced_align(), which is
the core API.
If you are looking to align your corpus, we recommend to use
torchaudio.pipelines.Wav2Vec2FABundle, which combines
forced_align() and other support
functions with pre-trained model specifically trained for
forced-alignment. Please refer to the
Forced alignment for multilingual data which
illustrates its usage.
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2.3.0
2.3.0
cuda
Overview
The process of alignment looks like the following.
Estimate the frame-wise label probability from audio waveform
Generate the trellis matrix which represents the probability of labels aligned at time step.
Find the most likely path from the trellis matrix.
In this example, we use torchaudio’s Wav2Vec2 model for
acoustic feature extraction.
Preparation
First we import the necessary packages, and fetch data that we work on.
from dataclasses import dataclass
import IPython
import matplotlib.pyplot as plt
torch.random.manual_seed(0)
SPEECH_FILE = torchaudio.utils.download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav")
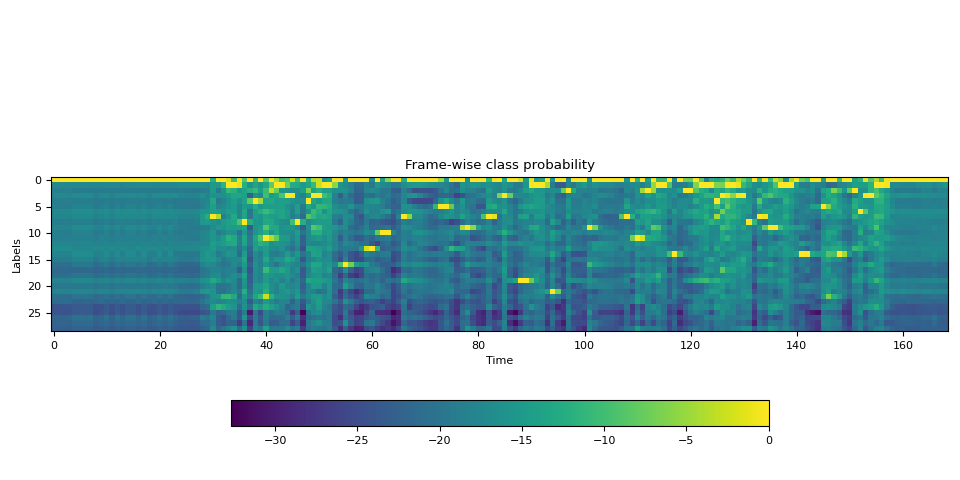
Generate frame-wise label probability
The first step is to generate the label class porbability of each audio
frame. We can use a Wav2Vec2 model that is trained for ASR. Here we use
torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H().
torchaudio provides easy access to pretrained models with associated
labels.
Note
In the subsequent sections, we will compute the probability in
log-domain to avoid numerical instability. For this purpose, we
normalize the emission with torch.log_softmax().
bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H
model = bundle.get_model().to(device)
labels = bundle.get_labels()
with torch.inference_mode():
waveform, _ = torchaudio.load(SPEECH_FILE)
emissions, _ = model(waveform.to(device))
emissions = torch.log_softmax(emissions, dim=-1)
emission = emissions[0].cpu().detach()
print(labels)
('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')
Visualization
def plot():
fig, ax = plt.subplots()
img = ax.imshow(emission.T)
ax.set_title("Frame-wise class probability")
ax.set_xlabel("Time")
ax.set_ylabel("Labels")
fig.colorbar(img, ax=ax, shrink=0.6, location="bottom")
fig.tight_layout()
plot()
Generate alignment probability (trellis)
From the emission matrix, next we generate the trellis which represents the probability of transcript labels occur at each time frame.
Trellis is 2D matrix with time axis and label axis. The label axis represents the transcript that we are aligning. In the following, we use to denote the index in time axis and to denote the index in label axis. represents the label at label index .
To generate, the probability of time step , we look at the trellis from time step and emission at time step . There are two path to reach to time step with label . The first one is the case where the label was at and there was no label change from to . The other case is where the label was at and it transitioned to the next label at .
The follwoing diagram illustrates this transition.
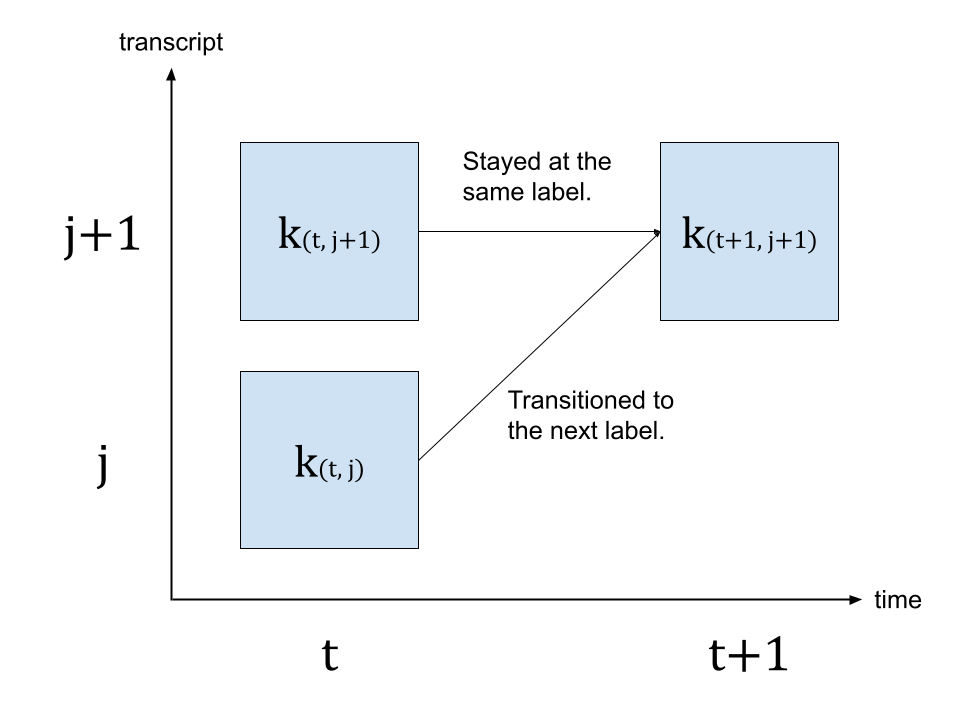
Since we are looking for the most likely transitions, we take the more likely path for the value of , that is
where represents is trellis matrix, and represents the probability of label at time step . represents the blank token from CTC formulation. (For the detail of CTC algorithm, please refer to the Sequence Modeling with CTC [distill.pub])
# We enclose the transcript with space tokens, which represent SOS and EOS.
transcript = "|I|HAD|THAT|CURIOSITY|BESIDE|ME|AT|THIS|MOMENT|"
dictionary = {c: i for i, c in enumerate(labels)}
tokens = [dictionary[c] for c in transcript]
print(list(zip(transcript, tokens)))
def get_trellis(emission, tokens, blank_id=0):
num_frame = emission.size(0)
num_tokens = len(tokens)
trellis = torch.zeros((num_frame, num_tokens))
trellis[1:, 0] = torch.cumsum(emission[1:, blank_id], 0)
trellis[0, 1:] = -float("inf")
trellis[-num_tokens + 1 :, 0] = float("inf")
for t in range(num_frame - 1):
trellis[t + 1, 1:] = torch.maximum(
# Score for staying at the same token
trellis[t, 1:] + emission[t, blank_id],
# Score for changing to the next token
trellis[t, :-1] + emission[t, tokens[1:]],
)
return trellis
trellis = get_trellis(emission, tokens)
[('|', 1), ('I', 7), ('|', 1), ('H', 8), ('A', 4), ('D', 11), ('|', 1), ('T', 3), ('H', 8), ('A', 4), ('T', 3), ('|', 1), ('C', 16), ('U', 13), ('R', 10), ('I', 7), ('O', 5), ('S', 9), ('I', 7), ('T', 3), ('Y', 19), ('|', 1), ('B', 21), ('E', 2), ('S', 9), ('I', 7), ('D', 11), ('E', 2), ('|', 1), ('M', 14), ('E', 2), ('|', 1), ('A', 4), ('T', 3), ('|', 1), ('T', 3), ('H', 8), ('I', 7), ('S', 9), ('|', 1), ('M', 14), ('O', 5), ('M', 14), ('E', 2), ('N', 6), ('T', 3), ('|', 1)]
Visualization
def plot():
fig, ax = plt.subplots()
img = ax.imshow(trellis.T, origin="lower")
ax.annotate("- Inf", (trellis.size(1) / 5, trellis.size(1) / 1.5))
ax.annotate("+ Inf", (trellis.size(0) - trellis.size(1) / 5, trellis.size(1) / 3))
fig.colorbar(img, ax=ax, shrink=0.6, location="bottom")
fig.tight_layout()
plot()
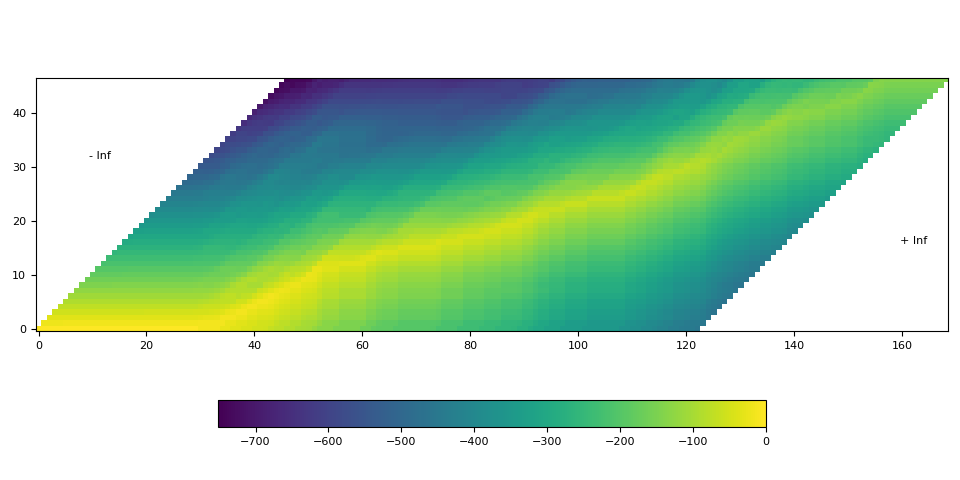
In the above visualization, we can see that there is a trace of high probability crossing the matrix diagonally.
Find the most likely path (backtracking)
Once the trellis is generated, we will traverse it following the elements with high probability.
We will start from the last label index with the time step of highest probability, then, we traverse back in time, picking stay () or transition (), based on the post-transition probability or .
Transition is done once the label reaches the beginning.
The trellis matrix is used for path-finding, but for the final probability of each segment, we take the frame-wise probability from emission matrix.
@dataclass
class Point:
token_index: int
time_index: int
score: float
def backtrack(trellis, emission, tokens, blank_id=0):
t, j = trellis.size(0) - 1, trellis.size(1) - 1
path = [Point(j, t, emission[t, blank_id].exp().item())]
while j > 0:
# Should not happen but just in case
assert t > 0
# 1. Figure out if the current position was stay or change
# Frame-wise score of stay vs change
p_stay = emission[t - 1, blank_id]
p_change = emission[t - 1, tokens[j]]
# Context-aware score for stay vs change
stayed = trellis[t - 1, j] + p_stay
changed = trellis[t - 1, j - 1] + p_change
# Update position
t -= 1
if changed > stayed:
j -= 1
# Store the path with frame-wise probability.
prob = (p_change if changed > stayed else p_stay).exp().item()
path.append(Point(j, t, prob))
# Now j == 0, which means, it reached the SoS.
# Fill up the rest for the sake of visualization
while t > 0:
prob = emission[t - 1, blank_id].exp().item()
path.append(Point(j, t - 1, prob))
t -= 1
return path[::-1]
path = backtrack(trellis, emission, tokens)
for p in path:
print(p)
Point(token_index=0, time_index=0, score=0.9999996423721313)
Point(token_index=0, time_index=1, score=0.9999996423721313)
Point(token_index=0, time_index=2, score=0.9999996423721313)
Point(token_index=0, time_index=3, score=0.9999996423721313)
Point(token_index=0, time_index=4, score=0.9999996423721313)
Point(token_index=0, time_index=5, score=0.9999996423721313)
Point(token_index=0, time_index=6, score=0.9999996423721313)
Point(token_index=0, time_index=7, score=0.9999996423721313)
Point(token_index=0, time_index=8, score=0.9999998807907104)
Point(token_index=0, time_index=9, score=0.9999996423721313)
Point(token_index=0, time_index=10, score=0.9999996423721313)
Point(token_index=0, time_index=11, score=0.9999998807907104)
Point(token_index=0, time_index=12, score=0.9999996423721313)
Point(token_index=0, time_index=13, score=0.9999996423721313)
Point(token_index=0, time_index=14, score=0.9999996423721313)
Point(token_index=0, time_index=15, score=0.9999996423721313)
Point(token_index=0, time_index=16, score=0.9999996423721313)
Point(token_index=0, time_index=17, score=0.9999996423721313)
Point(token_index=0, time_index=18, score=0.9999998807907104)
Point(token_index=0, time_index=19, score=0.9999996423721313)
Point(token_index=0, time_index=20, score=0.9999996423721313)
Point(token_index=0, time_index=21, score=0.9999996423721313)
Point(token_index=0, time_index=22, score=0.9999996423721313)
Point(token_index=0, time_index=23, score=0.9999997615814209)
Point(token_index=0, time_index=24, score=0.9999998807907104)
Point(token_index=0, time_index=25, score=0.9999998807907104)
Point(token_index=0, time_index=26, score=0.9999998807907104)
Point(token_index=0, time_index=27, score=0.9999998807907104)
Point(token_index=0, time_index=28, score=0.9999985694885254)
Point(token_index=0, time_index=29, score=0.9999943971633911)
Point(token_index=0, time_index=30, score=0.9999842643737793)
Point(token_index=1, time_index=31, score=0.9846165180206299)
Point(token_index=1, time_index=32, score=0.9999706745147705)
Point(token_index=1, time_index=33, score=0.15376661717891693)
Point(token_index=1, time_index=34, score=0.9999172687530518)
Point(token_index=2, time_index=35, score=0.6086705327033997)
Point(token_index=2, time_index=36, score=0.9997723698616028)
Point(token_index=3, time_index=37, score=0.9997134804725647)
Point(token_index=3, time_index=38, score=0.9999358654022217)
Point(token_index=4, time_index=39, score=0.9861685633659363)
Point(token_index=4, time_index=40, score=0.9242331385612488)
Point(token_index=5, time_index=41, score=0.926007866859436)
Point(token_index=5, time_index=42, score=0.01556419488042593)
Point(token_index=5, time_index=43, score=0.9998375177383423)
Point(token_index=6, time_index=44, score=0.9988489151000977)
Point(token_index=7, time_index=45, score=0.1021796241402626)
Point(token_index=7, time_index=46, score=0.9999427795410156)
Point(token_index=8, time_index=47, score=0.9999943971633911)
Point(token_index=8, time_index=48, score=0.9979604482650757)
Point(token_index=9, time_index=49, score=0.0360121876001358)
Point(token_index=9, time_index=50, score=0.06167365238070488)
Point(token_index=9, time_index=51, score=4.336783240432851e-05)
Point(token_index=10, time_index=52, score=0.9999799728393555)
Point(token_index=11, time_index=53, score=0.9967040419578552)
Point(token_index=11, time_index=54, score=0.9999257326126099)
Point(token_index=11, time_index=55, score=0.9999982118606567)
Point(token_index=12, time_index=56, score=0.9990678429603577)
Point(token_index=12, time_index=57, score=0.9999996423721313)
Point(token_index=12, time_index=58, score=0.9999996423721313)
Point(token_index=12, time_index=59, score=0.8453492522239685)
Point(token_index=12, time_index=60, score=0.9999996423721313)
Point(token_index=13, time_index=61, score=0.9996009469032288)
Point(token_index=13, time_index=62, score=0.999998927116394)
Point(token_index=14, time_index=63, score=0.00353023293428123)
Point(token_index=14, time_index=64, score=1.0)
Point(token_index=14, time_index=65, score=1.0)
Point(token_index=14, time_index=66, score=0.9999915361404419)
Point(token_index=15, time_index=67, score=0.9971516132354736)
Point(token_index=15, time_index=68, score=0.9999990463256836)
Point(token_index=15, time_index=69, score=0.9999992847442627)
Point(token_index=15, time_index=70, score=0.9999997615814209)
Point(token_index=15, time_index=71, score=0.9999998807907104)
Point(token_index=15, time_index=72, score=0.9999880790710449)
Point(token_index=15, time_index=73, score=0.011415631510317326)
Point(token_index=15, time_index=74, score=0.9999977350234985)
Point(token_index=16, time_index=75, score=0.9996123909950256)
Point(token_index=16, time_index=76, score=0.999998927116394)
Point(token_index=16, time_index=77, score=0.9729099869728088)
Point(token_index=16, time_index=78, score=0.999998927116394)
Point(token_index=17, time_index=79, score=0.9949352145195007)
Point(token_index=17, time_index=80, score=0.999998927116394)
Point(token_index=17, time_index=81, score=0.9999123811721802)
Point(token_index=17, time_index=82, score=0.9999774694442749)
Point(token_index=18, time_index=83, score=0.6568986177444458)
Point(token_index=18, time_index=84, score=0.9984309077262878)
Point(token_index=18, time_index=85, score=0.9999876022338867)
Point(token_index=19, time_index=86, score=0.9993754029273987)
Point(token_index=19, time_index=87, score=0.9999988079071045)
Point(token_index=19, time_index=88, score=0.10457336902618408)
Point(token_index=19, time_index=89, score=0.9999969005584717)
Point(token_index=20, time_index=90, score=0.39713507890701294)
Point(token_index=20, time_index=91, score=0.9999932050704956)
Point(token_index=21, time_index=92, score=1.69728946275427e-06)
Point(token_index=21, time_index=93, score=0.9861241579055786)
Point(token_index=21, time_index=94, score=0.9999960660934448)
Point(token_index=22, time_index=95, score=0.9992733597755432)
Point(token_index=22, time_index=96, score=0.9993415474891663)
Point(token_index=22, time_index=97, score=0.9999983310699463)
Point(token_index=23, time_index=98, score=0.9999971389770508)
Point(token_index=23, time_index=99, score=0.9999998807907104)
Point(token_index=23, time_index=100, score=0.9999995231628418)
Point(token_index=23, time_index=101, score=0.9999732971191406)
Point(token_index=24, time_index=102, score=0.9983206391334534)
Point(token_index=24, time_index=103, score=0.9999991655349731)
Point(token_index=24, time_index=104, score=0.9999996423721313)
Point(token_index=24, time_index=105, score=0.9999998807907104)
Point(token_index=24, time_index=106, score=1.0)
Point(token_index=24, time_index=107, score=0.9998623132705688)
Point(token_index=24, time_index=108, score=0.9999980926513672)
Point(token_index=25, time_index=109, score=0.9988552331924438)
Point(token_index=25, time_index=110, score=0.9999798536300659)
Point(token_index=26, time_index=111, score=0.8575102090835571)
Point(token_index=26, time_index=112, score=0.9999847412109375)
Point(token_index=27, time_index=113, score=0.9870213866233826)
Point(token_index=27, time_index=114, score=1.8971080862684175e-05)
Point(token_index=27, time_index=115, score=0.9999794960021973)
Point(token_index=28, time_index=116, score=0.9998254179954529)
Point(token_index=28, time_index=117, score=0.9999990463256836)
Point(token_index=29, time_index=118, score=0.9999732971191406)
Point(token_index=29, time_index=119, score=0.0009179709595628083)
Point(token_index=29, time_index=120, score=0.9993636012077332)
Point(token_index=30, time_index=121, score=0.9975398778915405)
Point(token_index=30, time_index=122, score=0.0003043622418772429)
Point(token_index=30, time_index=123, score=0.9999344348907471)
Point(token_index=31, time_index=124, score=6.090586339269066e-06)
Point(token_index=31, time_index=125, score=0.9833256006240845)
Point(token_index=32, time_index=126, score=0.9974588751792908)
Point(token_index=33, time_index=127, score=0.0008251128601841629)
Point(token_index=33, time_index=128, score=0.9965149164199829)
Point(token_index=34, time_index=129, score=0.017433946952223778)
Point(token_index=34, time_index=130, score=0.9989169836044312)
Point(token_index=35, time_index=131, score=0.9999697208404541)
Point(token_index=36, time_index=132, score=0.9999842643737793)
Point(token_index=36, time_index=133, score=0.9997639060020447)
Point(token_index=37, time_index=134, score=0.5118544101715088)
Point(token_index=37, time_index=135, score=0.9998302459716797)
Point(token_index=38, time_index=136, score=0.0852130874991417)
Point(token_index=38, time_index=137, score=0.004070050548762083)
Point(token_index=38, time_index=138, score=0.9999815225601196)
Point(token_index=39, time_index=139, score=0.012034581042826176)
Point(token_index=39, time_index=140, score=0.9999980926513672)
Point(token_index=39, time_index=141, score=0.0005822110688313842)
Point(token_index=39, time_index=142, score=0.9999072551727295)
Point(token_index=40, time_index=143, score=0.9999960660934448)
Point(token_index=40, time_index=144, score=0.9999980926513672)
Point(token_index=40, time_index=145, score=0.9999916553497314)
Point(token_index=41, time_index=146, score=0.9971168041229248)
Point(token_index=41, time_index=147, score=0.9981781244277954)
Point(token_index=41, time_index=148, score=0.9999310970306396)
Point(token_index=42, time_index=149, score=0.9879370331764221)
Point(token_index=42, time_index=150, score=0.9997633099555969)
Point(token_index=42, time_index=151, score=0.9999535083770752)
Point(token_index=43, time_index=152, score=0.9999715089797974)
Point(token_index=44, time_index=153, score=0.31822556257247925)
Point(token_index=44, time_index=154, score=0.999782145023346)
Point(token_index=45, time_index=155, score=0.01603216677904129)
Point(token_index=45, time_index=156, score=0.999901294708252)
Point(token_index=46, time_index=157, score=0.46628203988075256)
Point(token_index=46, time_index=158, score=0.9999994039535522)
Point(token_index=46, time_index=159, score=0.9999996423721313)
Point(token_index=46, time_index=160, score=0.9999995231628418)
Point(token_index=46, time_index=161, score=0.9999996423721313)
Point(token_index=46, time_index=162, score=0.9999996423721313)
Point(token_index=46, time_index=163, score=0.9999996423721313)
Point(token_index=46, time_index=164, score=0.9999995231628418)
Point(token_index=46, time_index=165, score=0.9999995231628418)
Point(token_index=46, time_index=166, score=0.9999996423721313)
Point(token_index=46, time_index=167, score=0.9999996423721313)
Point(token_index=46, time_index=168, score=0.9999995231628418)
Visualization
def plot_trellis_with_path(trellis, path):
# To plot trellis with path, we take advantage of 'nan' value
trellis_with_path = trellis.clone()
for _, p in enumerate(path):
trellis_with_path[p.time_index, p.token_index] = float("nan")
plt.imshow(trellis_with_path.T, origin="lower")
plt.title("The path found by backtracking")
plt.tight_layout()
plot_trellis_with_path(trellis, path)
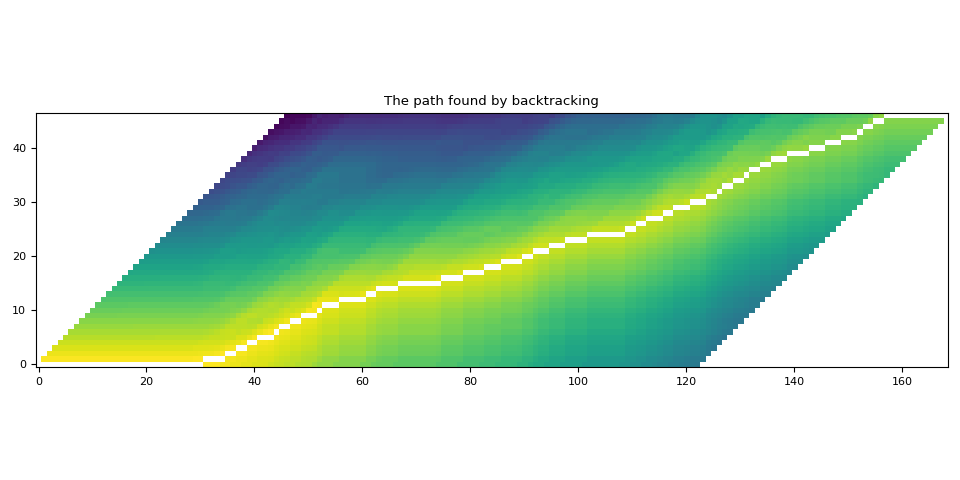
Looking good.
Segment the path
Now this path contains repetations for the same labels, so let’s merge them to make it close to the original transcript.
When merging the multiple path points, we simply take the average probability for the merged segments.
# Merge the labels
@dataclass
class Segment:
label: str
start: int
end: int
score: float
def __repr__(self):
return f"{self.label}\t({self.score:4.2f}): [{self.start:5d}, {self.end:5d})"
@property
def length(self):
return self.end - self.start
def merge_repeats(path):
i1, i2 = 0, 0
segments = []
while i1 < len(path):
while i2 < len(path) and path[i1].token_index == path[i2].token_index:
i2 += 1
score = sum(path[k].score for k in range(i1, i2)) / (i2 - i1)
segments.append(
Segment(
transcript[path[i1].token_index],
path[i1].time_index,
path[i2 - 1].time_index + 1,
score,
)
)
i1 = i2
return segments
segments = merge_repeats(path)
for seg in segments:
print(seg)
| (1.00): [ 0, 31)
I (0.78): [ 31, 35)
| (0.80): [ 35, 37)
H (1.00): [ 37, 39)
A (0.96): [ 39, 41)
D (0.65): [ 41, 44)
| (1.00): [ 44, 45)
T (0.55): [ 45, 47)
H (1.00): [ 47, 49)
A (0.03): [ 49, 52)
T (1.00): [ 52, 53)
| (1.00): [ 53, 56)
C (0.97): [ 56, 61)
U (1.00): [ 61, 63)
R (0.75): [ 63, 67)
I (0.88): [ 67, 75)
O (0.99): [ 75, 79)
S (1.00): [ 79, 83)
I (0.89): [ 83, 86)
T (0.78): [ 86, 90)
Y (0.70): [ 90, 92)
| (0.66): [ 92, 95)
B (1.00): [ 95, 98)
E (1.00): [ 98, 102)
S (1.00): [ 102, 109)
I (1.00): [ 109, 111)
D (0.93): [ 111, 113)
E (0.66): [ 113, 116)
| (1.00): [ 116, 118)
M (0.67): [ 118, 121)
E (0.67): [ 121, 124)
| (0.49): [ 124, 126)
A (1.00): [ 126, 127)
T (0.50): [ 127, 129)
| (0.51): [ 129, 131)
T (1.00): [ 131, 132)
H (1.00): [ 132, 134)
I (0.76): [ 134, 136)
S (0.36): [ 136, 139)
| (0.50): [ 139, 143)
M (1.00): [ 143, 146)
O (1.00): [ 146, 149)
M (1.00): [ 149, 152)
E (1.00): [ 152, 153)
N (0.66): [ 153, 155)
T (0.51): [ 155, 157)
| (0.96): [ 157, 169)
Visualization
def plot_trellis_with_segments(trellis, segments, transcript):
# To plot trellis with path, we take advantage of 'nan' value
trellis_with_path = trellis.clone()
for i, seg in enumerate(segments):
if seg.label != "|":
trellis_with_path[seg.start : seg.end, i] = float("nan")
fig, [ax1, ax2] = plt.subplots(2, 1, sharex=True)
ax1.set_title("Path, label and probability for each label")
ax1.imshow(trellis_with_path.T, origin="lower", aspect="auto")
for i, seg in enumerate(segments):
if seg.label != "|":
ax1.annotate(seg.label, (seg.start, i - 0.7), size="small")
ax1.annotate(f"{seg.score:.2f}", (seg.start, i + 3), size="small")
ax2.set_title("Label probability with and without repetation")
xs, hs, ws = [], [], []
for seg in segments:
if seg.label != "|":
xs.append((seg.end + seg.start) / 2 + 0.4)
hs.append(seg.score)
ws.append(seg.end - seg.start)
ax2.annotate(seg.label, (seg.start + 0.8, -0.07))
ax2.bar(xs, hs, width=ws, color="gray", alpha=0.5, edgecolor="black")
xs, hs = [], []
for p in path:
label = transcript[p.token_index]
if label != "|":
xs.append(p.time_index + 1)
hs.append(p.score)
ax2.bar(xs, hs, width=0.5, alpha=0.5)
ax2.axhline(0, color="black")
ax2.grid(True, axis="y")
ax2.set_ylim(-0.1, 1.1)
fig.tight_layout()
plot_trellis_with_segments(trellis, segments, transcript)
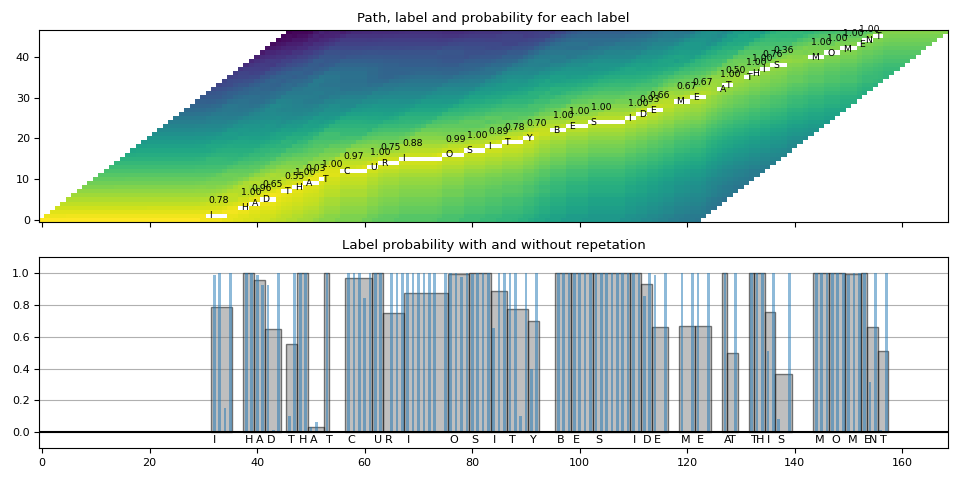
Looks good.
Merge the segments into words
Now let’s merge the words. The Wav2Vec2 model uses '|'
as the word boundary, so we merge the segments before each occurance of
'|'.
Then, finally, we segment the original audio into segmented audio and listen to them to see if the segmentation is correct.
# Merge words
def merge_words(segments, separator="|"):
words = []
i1, i2 = 0, 0
while i1 < len(segments):
if i2 >= len(segments) or segments[i2].label == separator:
if i1 != i2:
segs = segments[i1:i2]
word = "".join([seg.label for seg in segs])
score = sum(seg.score * seg.length for seg in segs) / sum(seg.length for seg in segs)
words.append(Segment(word, segments[i1].start, segments[i2 - 1].end, score))
i1 = i2 + 1
i2 = i1
else:
i2 += 1
return words
word_segments = merge_words(segments)
for word in word_segments:
print(word)
I (0.78): [ 31, 35)
HAD (0.84): [ 37, 44)
THAT (0.52): [ 45, 53)
CURIOSITY (0.89): [ 56, 92)
BESIDE (0.94): [ 95, 116)
ME (0.67): [ 118, 124)
AT (0.66): [ 126, 129)
THIS (0.70): [ 131, 139)
MOMENT (0.88): [ 143, 157)
Visualization
def plot_alignments(trellis, segments, word_segments, waveform, sample_rate=bundle.sample_rate):
trellis_with_path = trellis.clone()
for i, seg in enumerate(segments):
if seg.label != "|":
trellis_with_path[seg.start : seg.end, i] = float("nan")
fig, [ax1, ax2] = plt.subplots(2, 1)
ax1.imshow(trellis_with_path.T, origin="lower", aspect="auto")
ax1.set_facecolor("lightgray")
ax1.set_xticks([])
ax1.set_yticks([])
for word in word_segments:
ax1.axvspan(word.start - 0.5, word.end - 0.5, edgecolor="white", facecolor="none")
for i, seg in enumerate(segments):
if seg.label != "|":
ax1.annotate(seg.label, (seg.start, i - 0.7), size="small")
ax1.annotate(f"{seg.score:.2f}", (seg.start, i + 3), size="small")
# The original waveform
ratio = waveform.size(0) / sample_rate / trellis.size(0)
ax2.specgram(waveform, Fs=sample_rate)
for word in word_segments:
x0 = ratio * word.start
x1 = ratio * word.end
ax2.axvspan(x0, x1, facecolor="none", edgecolor="white", hatch="/")
ax2.annotate(f"{word.score:.2f}", (x0, sample_rate * 0.51), annotation_clip=False)
for seg in segments:
if seg.label != "|":
ax2.annotate(seg.label, (seg.start * ratio, sample_rate * 0.55), annotation_clip=False)
ax2.set_xlabel("time [second]")
ax2.set_yticks([])
fig.tight_layout()
plot_alignments(
trellis,
segments,
word_segments,
waveform[0],
)
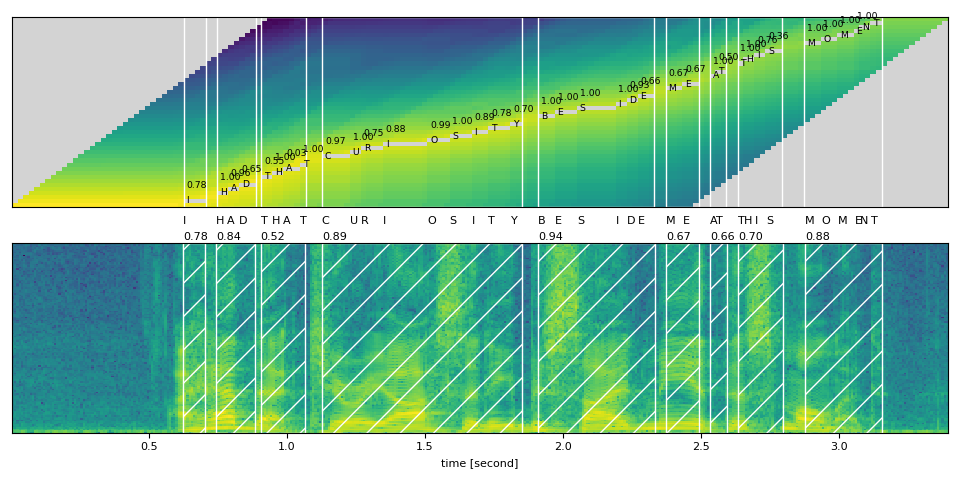
Audio Samples
def display_segment(i):
ratio = waveform.size(1) / trellis.size(0)
word = word_segments[i]
x0 = int(ratio * word.start)
x1 = int(ratio * word.end)
print(f"{word.label} ({word.score:.2f}): {x0 / bundle.sample_rate:.3f} - {x1 / bundle.sample_rate:.3f} sec")
segment = waveform[:, x0:x1]
return IPython.display.Audio(segment.numpy(), rate=bundle.sample_rate)
# Generate the audio for each segment
print(transcript)
IPython.display.Audio(SPEECH_FILE)
|I|HAD|THAT|CURIOSITY|BESIDE|ME|AT|THIS|MOMENT|
display_segment(0)
I (0.78): 0.624 - 0.704 sec
display_segment(1)
HAD (0.84): 0.744 - 0.885 sec
display_segment(2)
THAT (0.52): 0.905 - 1.066 sec
display_segment(3)
CURIOSITY (0.89): 1.127 - 1.851 sec
display_segment(4)
BESIDE (0.94): 1.911 - 2.334 sec
display_segment(5)
ME (0.67): 2.374 - 2.495 sec
display_segment(6)
AT (0.66): 2.535 - 2.595 sec
display_segment(7)
THIS (0.70): 2.635 - 2.796 sec
display_segment(8)
MOMENT (0.88): 2.877 - 3.159 sec
Conclusion
In this tutorial, we looked how to use torchaudio’s Wav2Vec2 model to perform CTC segmentation for forced alignment.
Total running time of the script: ( 0 minutes 1.741 seconds)
