How to do DistributedDataParallel(DDP)
This document shows how to use torch.nn.parallel.DistributedDataParallel in xla, and further describes its difference against the native xla data parallel approach. You can find a minimum runnable example here.
Background / Motivation
Customers have long requested the ability to use PyTorch’s DistributedDataParallel API with xla. And here we enable it as an experimental feature.
How to use DistributedDataParallel
For those who switched from the PyTorch eager mode to XLA, here are all the changes you need to do to convert your eager DDP model into XLA model. We assume that you already know how to use XLA on a single device.
Import xla specific distributed packages:
import torch_xla
import torch_xla.runtime as xr
import torch_xla.distributed.xla_backend
Init xla process group similar to other process groups such as nccl and gloo.
dist.init_process_group("xla", rank=rank, world_size=world_size)
Use xla specific APIs to get rank and world_size if you need to.
new_rank = xr.global_ordinal()
world_size = xr.world_size()
Pass
gradient_as_bucket_view=Trueto the DDP wrapper.
ddp_model = DDP(model, gradient_as_bucket_view=True)
Finally launch your model with xla specific launcher.
torch_xla.launch(demo_fn)
Here we have put everything together (the example is actually taken from the DDP tutorial). The way you code it is pretty similar to the eager experience. Just with xla specific touches on a single device plus the above five changes to your script.
import os
import sys
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
# additional imports for xla
import torch_xla
import torch_xla.core.xla_model as xm
import torch_xla.runtime as xr
import torch_xla.distributed.xla_backend
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the xla process group
dist.init_process_group("xla", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 1000000)
self.relu = nn.ReLU()
self.net2 = nn.Linear(1000000, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
def demo_basic(rank):
# xla specific APIs to get rank, world_size.
new_rank = xr.global_ordinal()
assert new_rank == rank
world_size = xr.world_size()
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to XLA device
device = xm.xla_device()
model = ToyModel().to(device)
# currently, graident_as_bucket_view is needed to make DDP work for xla
ddp_model = DDP(model, gradient_as_bucket_view=True)
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10).to(device))
labels = torch.randn(20, 5).to(device)
loss_fn(outputs, labels).backward()
optimizer.step()
# xla specific API to execute the graph
xm.mark_step()
cleanup()
def run_demo(demo_fn):
# xla specific launcher
torch_xla.launch(demo_fn)
if __name__ == "__main__":
run_demo(demo_basic)
Benchmarking
Resnet50 with fake data
The following results are collected with the command: python
test/test_train_mp_imagenet.py --fake_data --model=resnet50 --num_epochs=1 on a
TPU VM V3-8 environment with ToT PyTorch and PyTorch/XLA. And the statistical
metrics are produced by using the script in this pull
request. The unit for the rate is
images per second.
| Type | Mean | Median | 90th % | Std Dev | CV |
| xm.optimizer_step | 418.54 | 419.22 | 430.40 | 9.76 | 0.02 |
| DDP | 395.97 | 395.54 | 407.13 | 7.60 | 0.02 |
The performance difference between our native approach for distributed data parallel and DistributedDataParallel wrapper is: 1 - 395.97 / 418.54 = 5.39%. This result seems reasonable given the DDP wrapper introduces extra overheads on tracing the DDP runtime.
MNIST with fake data
The following results are collected with the command: python
test/test_train_mp_mnist.py --fake_data on a TPU VM V3-8 environment with ToT
PyTorch and PyTorch/XLA. And the statistical metrics are produced by using the
script in this pull request. The
unit for the rate is images per second.
| Type | Mean | Median | 90th % | Std Dev | CV |
| xm.optimizer_step | 17864.19 | 20108.96 | 24351.74 | 5866.83 | 0.33 |
| DDP | 10701.39 | 11770.00 | 14313.78 | 3102.92 | 0.29 |
The performance difference between our native approach for distributed data parallel and DistributedDataParallel wrapper is: 1 - 14313.78 / 24351.74 = 41.22%. Here we compare 90th % instead since the dataset is small and first a few rounds are heavily impacted by data loading. This slowdown is huge but makes sense given the model is small. The additional DDP runtime tracing overhead is hard to amortize.
MNIST with real data
The following results are collected with the command: python
test/test_train_mp_mnist.py --logdir mnist/ on a TPU VM V3-8 environment with
ToT PyTorch and PyTorch/XLA.
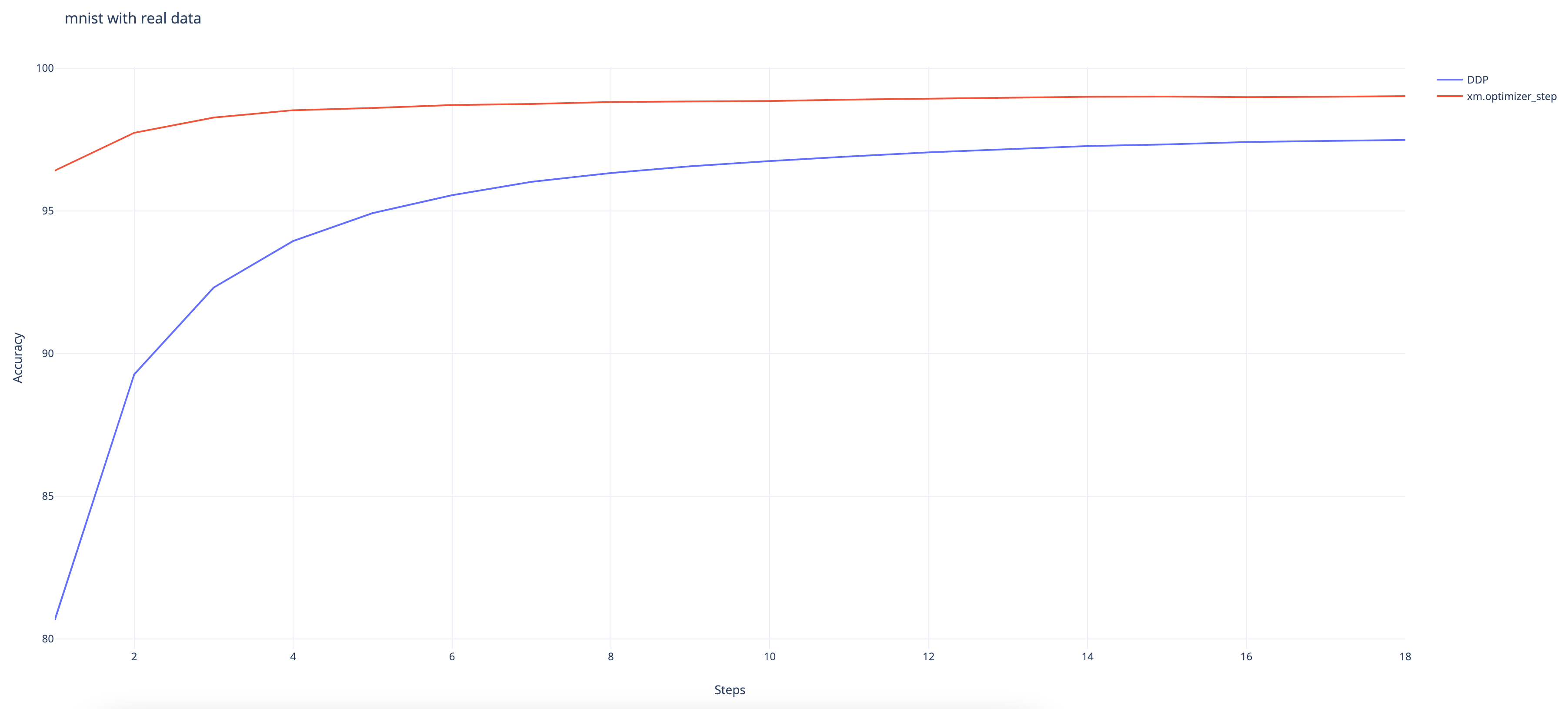
And we can observe that the DDP wrapper converges slower than the native XLA approach even though it still achieves a high accuracy rate at 97.48% at the end. (The native approach achieves 99%.)
Disclaimer
This feature is still experimental and under active development. Use it in cautions and feel free to file any bugs to the xla github repo. For those who are interested in the native xla data parallel approach, here is the tutorial.
Here are some of the known issues that are under investigation:
gradient_as_bucket_view=Trueneeds to be enforced.There are some issues while being used with
torch.utils.data.DataLoader.test_train_mp_mnist.pywith real data crashes before exiting.
Fully Sharded Data Parallel (FSDP) in PyTorch XLA
Fully Sharded Data Parallel (FSDP) in PyTorch XLA is a utility for sharding Module parameters across data-parallel workers.
Example usage:
import torch
import torch_xla.core.xla_model as xm
import torch_xla.runtime as xr
from torch_xla.distributed.fsdp import XlaFullyShardedDataParallel as FSDP
model = FSDP(my_module)
optim = torch.optim.Adam(model.parameters(), lr=0.0001)
output = model(x, y)
loss = output.sum()
loss.backward()
optim.step()
It is also possible to shard individual layers separately and have an outer wrapper handle any leftover parameters.
Notes:
The
XlaFullyShardedDataParallelclass supports both the ZeRO-2 optimizer (sharding gradients and optimizer states) and the ZeRO-3 optimizer (sharding parameters, gradients, and optimizer states) in https://arxiv.org/abs/1910.02054.The ZeRO-3 optimizer should be implemented via nested FSDP with
reshard_after_forward=True. Seetest/test_train_mp_mnist_fsdp_with_ckpt.pyandtest/test_train_mp_imagenet_fsdp.pyfor an example.For large models that cannot fit into a single TPU memory or the host CPU memory, one should interleave submodule construction with inner FSDP wrapping. See ``FSDPViTModel` <https://github.com/ronghanghu/vit_10b_fsdp_example/blob/master/run_vit_training.py>`_ for an example.
a simple wrapper
checkpoint_moduleis provided (based ontorch_xla.utils.checkpoint.checkpointfrom https://github.com/pytorch/xla/pull/3524) to perform gradient checkpointing over a givennn.Moduleinstance. Seetest/test_train_mp_mnist_fsdp_with_ckpt.pyandtest/test_train_mp_imagenet_fsdp.pyfor an example.Auto-wrapping submodules: instead of manually nested FSDP wrapping, one can also specify an
auto_wrap_policyargument to automatically wrap the submodules with inner FSDP.size_based_auto_wrap_policyintorch_xla.distributed.fsdp.wrapis an example ofauto_wrap_policycallable, this policy wraps layers with the number of parameters larger than 100M.transformer_auto_wrap_policyintorch_xla.distributed.fsdp.wrapis an example ofauto_wrap_policycallable for transformer-like model architectures.
For example, to automatically wrap all torch.nn.Conv2d submodules with inner FSDP, one can use:
from torch_xla.distributed.fsdp.wrap import transformer_auto_wrap_policy
auto_wrap_policy = partial(transformer_auto_wrap_policy, transformer_layer_cls={torch.nn.Conv2d})
Additionally, one can also specify an auto_wrapper_callable argument to use a custom callable wrapper for the submodules (the default wrapper is just the XlaFullyShardedDataParallel class itself). For example, one can use the following to apply gradient checkpointing (i.e. activation checkpointing/rematerialization) to each auto-wrapped submodule.
from torch_xla.distributed.fsdp import checkpoint_module
auto_wrapper_callable = lambda m, *args, **kwargs: XlaFullyShardedDataParallel(
checkpoint_module(m), *args, **kwargs)
When stepping the optimizer, directly call
optimizer.stepand do not callxm.optimizer_step. The latter reduces the gradient across ranks, which is not needed for FSDP (where the parameters are already sharded).When saving model and optimizer checkpoints during training, each training process needs to save its own checkpoint of the (sharded) model and optimizer state dicts (use
master_only=Falseand set different paths for each rank inxm.save). When resuming, it needs to load the checkpoint for the corresponding rank.Please also save
model.get_shard_metadata()along withmodel.state_dict()as follows and useconsolidate_sharded_model_checkpointsto stitch the sharded model checkpoints together into a full model state dict. Seetest/test_train_mp_mnist_fsdp_with_ckpt.pyfor an example. .. code-block:: python3- ckpt = {
‘model’: model.state_dict(), ‘shard_metadata’: model.get_shard_metadata(), ‘optimizer’: optimizer.state_dict(),
} ckpt_path = f’/tmp/rank-{xr.global_ordinal()}-of-{xr.world_size()}.pth’ xm.save(ckpt, ckpt_path, master_only=False)
The checkpoint consolidation script can also be launched from the command line as follows. .. code-block:: bash
# consolidate the saved checkpoints via command line tool python3 -m torch_xla.distributed.fsdp.consolidate_sharded_ckpts –ckpt_prefix /path/to/your_sharded_checkpoint_files –ckpt_suffix “_rank--of-.pth”
The implementation of this class is largely inspired by and mostly follows the structure of fairscale.nn.FullyShardedDataParallel in https://fairscale.readthedocs.io/en/stable/api/nn/fsdp.html. One of the biggest differences from fairscale.nn.FullyShardedDataParallel is that in XLA we don’t have explicit parameter storage, so here we resort to a different approach to free full parameters for ZeRO-3.
Example training scripts on MNIST and ImageNet
Minimum example : ``examples/fsdp/train_resnet_fsdp_auto_wrap.py` <https://github.com/pytorch/xla/blob/master/examples/fsdp/train_resnet_fsdp_auto_wrap.py>`_
MNIST: ``test/test_train_mp_mnist_fsdp_with_ckpt.py` <https://github.com/pytorch/xla/blob/master/test/test_train_mp_mnist_fsdp_with_ckpt.py>`_ (it also tests checkpoint consolidation)
ImageNet: ``test/test_train_mp_imagenet_fsdp.py` <https://github.com/pytorch/xla/blob/master/test/test_train_mp_imagenet_fsdp.py>`_
Installation
FSDP is available on PyTorch/XLA 1.12 release and newer nightly. Please refer to https://github.com/pytorch/xla#-available-images-and-wheels for installation guide.
Clone PyTorch/XLA repo
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch/
git clone --recursive https://github.com/pytorch/xla.git
cd ~/
Train MNIST on v3-8 TPU
It gets around 98.9 accuracy for 2 epochs:
python3 ~/pytorch/xla/test/test_train_mp_mnist_fsdp_with_ckpt.py \
--batch_size 16 --drop_last --num_epochs 2 \
--use_nested_fsdp --use_gradient_checkpointing
This script automatically tests checkpoint consolidation at the end. You can also manually consolidate the sharded checkpoints via
# consolidate the saved checkpoints via command line tool
python3 -m torch_xla.distributed.fsdp.consolidate_sharded_ckpts \
--ckpt_prefix /tmp/mnist-fsdp/final_ckpt \
--ckpt_suffix "_rank-*-of-*.pth"
Train ImageNet with ResNet-50 on v3-8 TPU
It gets around 75.9 accuracy for 100 epochs; download ImageNet-1k to /datasets/imagenet-1k:
python3 ~/pytorch/xla/test/test_train_mp_imagenet_fsdp.py \
--datadir /datasets/imagenet-1k --drop_last \
--model resnet50 --test_set_batch_size 64 --eval_interval 10 \
--lr 0.4 --batch_size 128 --num_warmup_epochs 5 --lr_scheduler_divide_every_n_epochs 30 --lr_scheduler_divisor 10 --num_epochs 100 \
--use_nested_fsdp
You can also add --use_gradient_checkpointing (which needs to be used along with --use_nested_fsdp or --auto_wrap_policy) to apply gradient checkpointing on the residual blocks.
Example training scripts on TPU pod (with 10 billion parameters)
To train large models that cannot fit into a single TPU, one should apply auto-wrap or manually wrap the submodules with inner FSDP when building the entire model to implement the ZeRO-3 algorithm.
Please see https://github.com/ronghanghu/vit_10b_fsdp_example for an example of sharded training of a Vision Transformer (ViT) model using this XLA FSDP PR.
