Finetuning Llama2 with QLoRA
In this tutorial, we’ll learn about QLoRA, an enhancement on top of LoRA that maintains frozen model parameters in 4-bit quantized precision, thereby reducing memory usage. We’ll walk through how QLoRA can be utilized within torchtune to finetune a Llama2-7b model in <10 GB of memory. It is highly recommended to first develop an understanding of LoRA finetuning in torchtune.
How QLoRA saves memory over LoRA finetuning
An overview of QLoRA in torchtune
How to run a QLoRA finetune in torchtune
Be familiar with torchtune
Make sure to install torchtune
Make sure you have downloaded the Llama2-7B model weights
Be familiar with LoRA in torchtune
What is QLoRA?
QLoRA builds on top of LoRA to enable further memory savings. In LoRA, model parameters can be thought of as existing in two partitions: adapters, which are low-rank matrices added to different layers of a neural network, and base model parameters, which are parameters that are part of the original model. In vanilla LoRA-style training, both these parameters are held in the same precision (typically fp32 or bf16), and therefore activations and intermediate gradients computed are in fp32/bf16.
QLoRA further quantizes the base model parameters into a bespoke 4-bit NormalFloat (NF4) data type, resulting in 4-8x less parameter memory usage while largely retaining model accuracy. As a result, the vast majority of parameters only take up 4 bits (as opposed to 16 or 32 bits by bf16/fp32 dtypes). This quantization is done through the method highlighted in the original QLoRA paper. Adapter parameters are still held in the original precision, and activations, gradients, and optimizer states still exist in the higher precision to preserve accuracy.
The QLoRA authors introduce two key abstractions to decrease memory usage and avoid accuracy degradation: the bespoke 4-bit NormatFloat type, and a double quantization method that quantizes the quantization parameters themselves to save even more memory. torchtune uses the NF4Tensor abstraction from the torchao library to build QLoRA components as specified in the paper. torchao is a PyTorch-native library that allows you to quantize and prune your models.
Using QLoRA to save memory
In this section, we’ll overview how to apply QLoRA to a LoRALinear layer in torchtune. For a deep dive into details on QLoRA in torchtune and underlying abstractions,
please see the QLoRA in torchtune deepdive section of this tutorial.
A core idea of QLoRA is the distinction between compute and storage datatypes (dtypes). Specifically, QLoRA stores base model parameters in 4-bit precision (i.e. the storage dtype), and runs computation in an original higher precision (the compute dtype), generally either fp32 or bf16. As a first step, QLoRA needs to quantize these base model parameters to 4-bit precision and store them.
To quantize a LoRALinear layer in the QLoRA style, simply pass in the quantize_base flag as True into LoRALinear. This flag
will result in base model weights being quantized and backed by the NF4Tensor dtype. Forward passes will also be automatically handled to work with the NF4Tensor dtype,
specifically, the NF4 base weight will be de-quantized to the compute precision, activation will be computed, and only the 4-bit parameter will be stored for gradient computation
in the backward pass, avoiding extra memory usage that would be incurred by storing the higher precision compute dtype.
Here’s an example of creating a quantized LoRALinear layer in comparison to an unquantized LoRALinear layer. As we can see, the quantized layer consumes
~8x less memory than the unquantized counterpart.
import torch
from torchtune.modules.peft import LoRALinear
torch.set_default_device("cuda")
qlora_linear = LoRALinear(512, 512, rank=8, alpha=0.1, quantize_base=True)
print(torch.cuda.memory_allocated()) # 177,152 bytes
del qlora_linear
torch.cuda.empty_cache()
lora_linear = LoRALinear(512, 512, rank=8, alpha=0.1, quantize_base=False)
print(torch.cuda.memory_allocated()) # 1,081,344 bytes
Using QLoRA in torchtune
We’ll now cover how you can initialize a QLoRA-enabled Llama2-7b model as well as some details around checkpointing with QLoRA.
With torchtune, you can use a simple builder similar to the LoRA builder (lora_llama_2_7b) to apply QLoRA to Llama2 models. Here’s a simple example of
initializing a Llama2-7b model with QLoRA enabled:
from torchtune.models.llama2 import qlora_llama2_7b
qlora_model = qlora_llama2_7b(lora_attn_modules=["q_proj", "v_proj"])
Under the hood, this will apply LoRA to the q_proj and v_proj matrices in all attention layers, and further quantize the base parameters
in these matrices to the NF4 dtype. Note that quantization of base model parameters is only applied to layers that are configured to have
LoRA adapters added. For example, in this case, k_proj and output_proj in the attention layers don’t have LoRA applied to them, so their
base model parameters are not quantized. We can see this by printing the base model parameter dtypes for a particular attention layer:
attn = qlora_model.layers[0].attn
print(type(attn.q_proj.weight)) # <class 'torchao.dtypes.nf4tensor.NF4Tensor'>
print(type(attn.k_proj.weight)) # <class 'torch.nn.parameter.Parameter'>
Next, there are a couple of details essential to checkpointing (i.e. state_dict) of QLoRA-enabled models.
To integrate well with torchtune’s checkpointing, we need to convert NF4Tensors back to their
original precision (generally fp32/bf16). This allows QLoRA-trained checkpoints to interoperate well with the rest of the ecosystem, within
torchtune and beyond (e.g. post-training quantization, evaluation, inference). This conversion process also allows LoRA adapter weights to be merged back into the base model as done
in a typical LoRA training flow.
To achieve this, when using torchtune’s qlora_llama2_7b builder, we automatically register a hook, reparametrize_as_dtype_state_dict_post_hook,
that runs after calling .state_dict() on the top level model. This hook converts NF4Tensors back to their original precision, while also offloading these
converted tensors to the CPU. This offloading is to avoid peaking memory; if we did not, we would have to maintain an entire bf16/fp32 copy of the state_dict
on GPU.
Putting it all together: QLoRA finetune
Putting it all together, we can now finetune a model using torchtune’s LoRA recipe, with a QLoRA configuration.
Make sure that you have first downloaded the Llama2 weights and tokenizer by following these instructions. You can then run the following command to perform a QLoRA finetune of Llama2-7B on a single GPU.
tune run lora_finetune_single_device --config llama2/7B_qlora_single_device
Note
Make sure to correctly point to the location of your Llama2 weights and tokenizer. This can be done
either by adding checkpointer.checkpoint_files=[my_model_checkpoint_path] tokenizer_checkpoint=my_tokenizer_checkpoint_path
or by directly modifying the 7B_qlora_single_device.yaml file. See our All About Configs
for more details on how you can easily clone and modify torchtune configs.
By default, this run should log peak memory stats at model initialization time and every 100 iterations during training. Let’s understand the memory savings enabled by QLoRA on top of LoRA training. LoRA training can be run as follows:
tune run lora_finetune_single_device --config llama2/7B_lora_single_device
You should see the memory usage printed out during model initialization and training. An example log for LoRA model initialization is as follows:
Memory Stats after model init::
GPU peak memory allocation: 13.96 GB
GPU peak memory reserved: 13.98 GB
GPU peak memory active: 13.96 GB
The following table compares the QLoRA’s memory reserved during model initialization and training against vanilla LoRA’s. We can see that QLoRA reduces peak memory by about 35% during model initialization, and about 40% during model training:
Finetuning method |
Peak memory reserved, model init |
Peak memory reserved, training |
|---|---|---|
LoRA |
13.98 GB |
15.57 GB |
QLoRA |
9.13 GB |
9.29 GB |
From the logs, one can see that the out-of-the-box training performance is quite slow, slower than 1 iteration per second:
1|149|Loss: 0.9157477021217346: 1%| | 149/25880 [02:08<6:14:19, 1.15it/s
To speed things up, we can leverage torch.compile to compile our model and run the compiled result. To work with
QLoRA training, a nightly build of PyTorch must be used. To update PyTorch to the latest nightly,
please see the installation instructions. Once updated,
you can specify the compile flag as True via a config override:
tune run lora_finetune_single_device --config llama2/7B_qlora_single_device compile=True
From the logs, we can see about a 200% speed up (after a few hundred iterations once the training has stabilized):
1|228|Loss: 0.8158286809921265: 1%| | 228/25880 [11:59<1:48:16, 3.95it/s
A comparison of the smoothed loss curves between QLoRA and LoRA can be seen below.
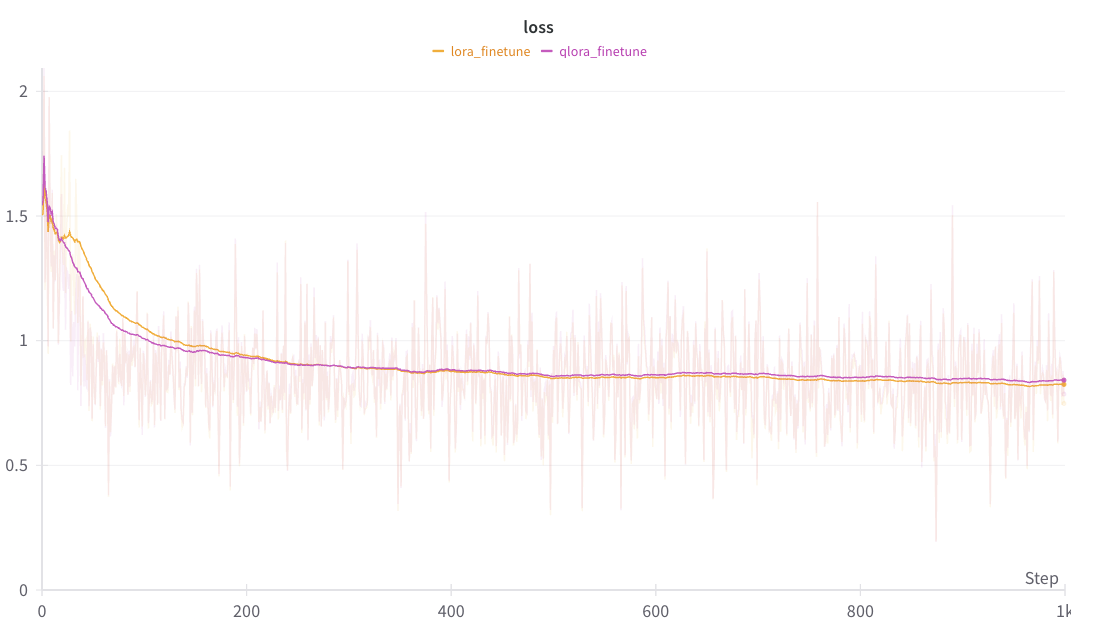
Note
The above figure was generated with W&B. You can use torchtune’s WandBLogger
to generate similar loss curves, but you will need to install W&B and setup an account separately.
As an exercise, you can also try running some evaluation tasks or manually inspecting generations
output by your saved checkpoints (which can be found in output_dir).
In the final section, we’ll go over a deep dive on how a QLoRA component can be built from a LoRA component.
Deep-dive: Building QLoRA from LoRA
This deep-dive section resumes from the Using QLoRA to save memory portion of this tutorial and dives into how quantization is done with NF4Tensor and handled appropriately in the forward pass.
First, we’ll begin with a vanilla minimal LoRA layer, taken from the LoRA tutorial and augmented to support quantization:
from torch import nn, Tensor
import torch.nn.functional as F
from torchao.dtypes.nf4tensor import linear_nf4, to_nf4
class LoRALinear(nn.Module):
def __init__(
self,
in_dim: int,
out_dim: int,
rank: int,
alpha: float,
dropout: float,
quantize_base: bool
):
# These are the weights from the original pretrained model
self.linear = nn.Linear(in_dim, out_dim, bias=False)
self.linear_weight = self.linear.weight
# Use torchao's to_nf4 API to quantize the base weight if needed.
if quantize_base:
self.linear_weight = to_nf4(self.linear_weight)
# These are the new LoRA params. In general rank << in_dim, out_dim
self.lora_a = nn.Linear(in_dim, rank, bias=False)
self.lora_b = nn.Linear(rank, out_dim, bias=False)
# Rank and alpha are commonly-tuned hyperparameters
self.rank = rank
self.alpha = alpha
# Most implementations also include some dropout
self.dropout = nn.Dropout(p=dropout)
# The original params are frozen, and only LoRA params are trainable.
self.linear.weight.requires_grad = False
self.lora_a.weight.requires_grad = True
self.lora_b.weight.requires_grad = True
def forward(self, x: Tensor) -> Tensor:
# frozen_out would be the output of the original model
if quantize_base:
# Call into torchao's linear_nf4 to run linear forward pass w/quantized weight.
frozen_out = linear_nf4(x, self.weight)
else:
frozen_out = F.linear(x, self.weight)
# lora_a projects inputs down to the much smaller self.rank,
# then lora_b projects back up to the output dimension
lora_out = self.lora_b(self.lora_a(self.dropout(x)))
# Finally, scale by the alpha parameter (normalized by rank)
# and add to the original model's outputs
return frozen_out + (self.alpha / self.rank) * lora_out
As mentioned above, torchtune takes a dependency on torchao for some of the core components required for QLoRA. This includes the
NF4Tensor, as well as helpful utilities including to_nf4 and linear_nf4.
The key changes on top of the LoRA layer are the usage of the to_nf4 and linear_nf4 APIs.
to_nf4 accepts an unquantized (bf16 or fp32) tensor and produces an NF4 representation of the weight. See the implementation of to_nf4 for more details.
linear_nf4 handles the forward pass and autograd when running with quantized base model weights. It computes the forward pass as a regular
F.linear with the incoming activation and unquantized weight. The quantized weight is saved for backward, as opposed to the unquantized version of the weight, to avoid extra
memory usage due to storing higher precision variables to compute gradients in the backward pass. See linear_nf4 for more details.
