Silero Speech-To-Text Models
# this assumes that you have a proper version of PyTorch already installed
pip install -q torchaudio omegaconf soundfile
import torch
import zipfile
import torchaudio
from glob import glob
device = torch.device('cpu') # gpu also works, but our models are fast enough for CPU
model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_stt',
language='en', # also available 'de', 'es'
device=device)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils # see function signature for details
# download a single file, any format compatible with TorchAudio (soundfile backend)
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav',
dst ='speech_orig.wav', progress=True)
test_files = glob('speech_orig.wav')
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]),
device=device)
output = model(input)
for example in output:
print(decoder(example.cpu()))
Model Description
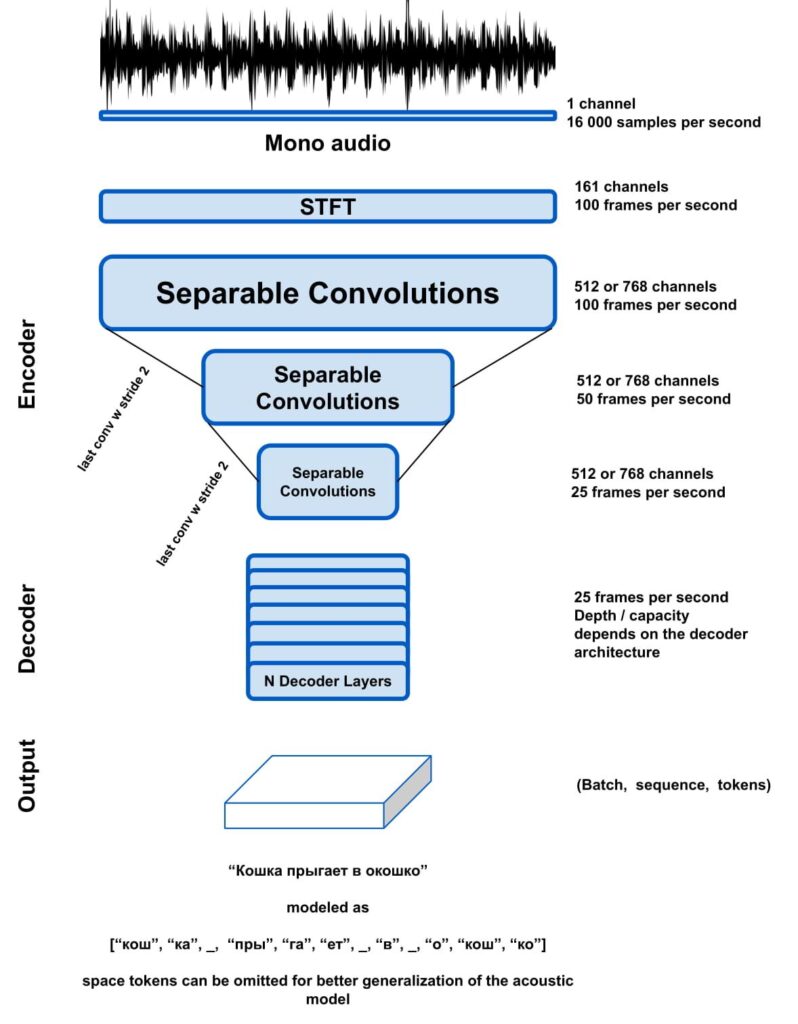
Silero Speech-To-Text models provide enterprise grade STT in a compact form-factor for several commonly spoken languages. Unlike conventional ASR models our models are robust to a variety of dialects, codecs, domains, noises, lower sampling rates (for simplicity audio should be resampled to 16 kHz). The models consume a normalized audio in the form of samples (i.e. without any pre-processing except for normalization to -1 … 1) and output frames with token probabilities. We provide a decoder utility for simplicity (we could include it into our model itself, but scripted modules had problems with storing model artifacts i.e. labels during certain export scenarios).
We hope that our efforts with Open-STT and Silero Models will bring the ImageNet moment in speech closer.
Supported Languages and Formats
As of this page update, the following languages are supported:
- English
- German
- Spanish
To see the always up-to-date language list, please visit our repo and see the yml file for all available checkpoints.
Additional Examples and Benchmarks
For additional examples and other model formats please visit this link. For quality and performance benchmarks please see the wiki. These resources will be updated from time to time.