Overview
Introducing PyTorch 2.0, our first steps toward the next generation 2-series release of PyTorch. Over the last few years we have innovated and iterated from PyTorch 1.0 to the most recent 1.13 and moved to the newly formed PyTorch Foundation, part of the Linux Foundation.
PyTorch’s biggest strength beyond our amazing community is that we continue as a first-class Python integration, imperative style, simplicity of the API and options. PyTorch 2.0 offers the same eager-mode development and user experience, while fundamentally changing and supercharging how PyTorch operates at compiler level under the hood. We are able to provide faster performance and support for Dynamic Shapes and Distributed.
Below you will find all the information you need to better understand what PyTorch 2.0 is, where it’s going and more importantly how to get started today (e.g., tutorial, requirements, models, common FAQs). There is still a lot to learn and develop but we are looking forward to community feedback and contributions to make the 2-series better and thank you all who have made the 1-series so successful.
PyTorch 2.x: faster, more pythonic and as dynamic as ever
Today, we announce torch.compile, a feature that pushes PyTorch performance to new heights and starts the move for parts of PyTorch from C++ back into Python. We believe that this is a substantial new direction for PyTorch – hence we call it 2.0. torch.compile is a fully additive (and optional) feature and hence 2.0 is 100% backward compatible by definition.
Underpinning torch.compile are new technologies – TorchDynamo, AOTAutograd, PrimTorch and TorchInductor.
-
TorchDynamo captures PyTorch programs safely using Python Frame Evaluation Hooks and is a significant innovation that was a result of 5 years of our R&D into safe graph capture
-
AOTAutograd overloads PyTorch’s autograd engine as a tracing autodiff for generating ahead-of-time backward traces.
- PrimTorch canonicalizes ~2000+ PyTorch operators down to a closed set of ~250 primitive operators that developers can target to build a complete PyTorch backend. This substantially lowers the barrier of writing a PyTorch feature or backend.
- TorchInductor is a deep learning compiler that generates fast code for multiple accelerators and backends. For NVIDIA and AMD GPUs, it uses OpenAI Triton as a key building block.
TorchDynamo, AOTAutograd, PrimTorch and TorchInductor are written in Python and support dynamic shapes (i.e. the ability to send in Tensors of different sizes without inducing a recompilation), making them flexible, easily hackable and lowering the barrier of entry for developers and vendors.
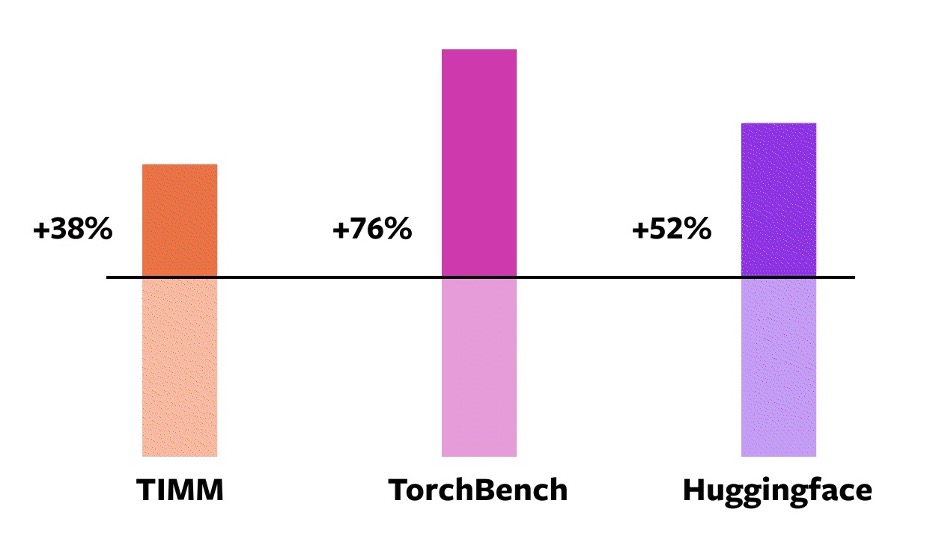
To validate these technologies, we used a diverse set of 163 open-source models across various machine learning domains. We built this benchmark carefully to include tasks such as Image Classification, Object Detection, Image Generation, various NLP tasks such as Language Modeling, Q&A, Sequence Classification, Recommender Systems and Reinforcement Learning. We separate the benchmarks into three categories:
- 46 models from HuggingFace Transformers
- 61 models from TIMM: a collection of state-of-the-art PyTorch image models by Ross Wightman
- 56 models from TorchBench: a curated set of popular code-bases from across github
We don’t modify these open-source models except to add a torch.compile call wrapping them.
We then measure speedups and validate accuracy across these models. Since speedups can be dependent on data-type, we measure speedups on both float32 and Automatic Mixed Precision (AMP). We report an uneven weighted average speedup of 0.75 * AMP + 0.25 * float32 since we find AMP is more common in practice.
Across these 163 open-source models torch.compile works 93% of time, and the model runs 43% faster in training on an NVIDIA A100 GPU. At Float32 precision, it runs 21% faster on average and at AMP Precision it runs 51% faster on average.
Caveats: On a desktop-class GPU such as a NVIDIA 3090, we’ve measured that speedups are lower than on server-class GPUs such as A100. As of today, our default backend TorchInductor supports CPUs and NVIDIA Volta and Ampere GPUs. It does not (yet) support other GPUs, xPUs or older NVIDIA GPUs.
Try it: torch.compile is in the early stages of development. Starting today, you can try out torch.compile in the nightly binaries. We expect to ship the first stable 2.0 release in early March 2023.
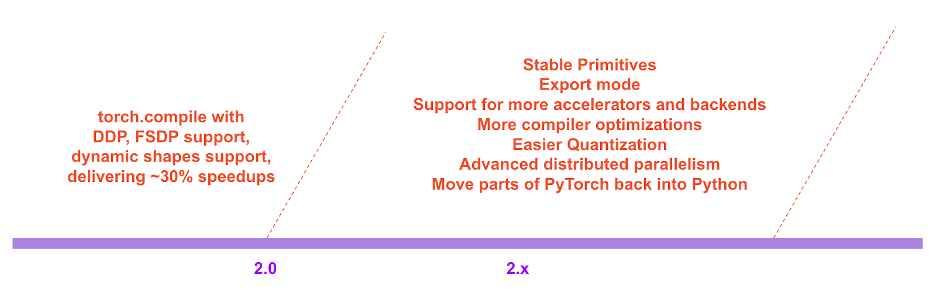
In the roadmap of PyTorch 2.x we hope to push the compiled mode further and further in terms of performance and scalability. Some of this work is in-flight, as we talked about at the Conference today. Some of this work has not started yet. Some of this work is what we hope to see, but don’t have the bandwidth to do ourselves. If you are interested in contributing, come chat with us at the Ask the Engineers: 2.0 Live Q&A Series starting this month (details at the end of this post) and/or via Github / Forums.
Testimonials
Here is what some of PyTorch’s users have to say about our new direction:
Sylvain Gugger the primary maintainer of HuggingFace transformers:
“With just one line of code to add, PyTorch 2.0 gives a speedup between 1.5x and 2.x in training Transformers models. This is the most exciting thing since mixed precision training was introduced!”
Ross Wightman the primary maintainer of TIMM (one of the largest vision model hubs within the PyTorch ecosystem):
“It just works out of the box with majority of TIMM models for inference and train workloads with no code changes”
Luca Antiga the CTO of Lightning AI and one of the primary maintainers of PyTorch Lightning
“PyTorch 2.0 embodies the future of deep learning frameworks. The possibility to capture a PyTorch program with effectively no user intervention and get massive on-device speedups and program manipulation out of the box unlocks a whole new dimension for AI developers.”
Motivation
Our philosophy on PyTorch has always been to keep flexibility and hackability our top priority, and performance as a close second. We strived for:
- High-Performance eager execution
- Pythonic internals
- Good abstractions for Distributed, Autodiff, Data loading, Accelerators, etc.
Since we launched PyTorch in 2017, hardware accelerators (such as GPUs) have become ~15x faster in compute and about ~2x faster in the speed of memory access. So, to keep eager execution at high-performance, we’ve had to move substantial parts of PyTorch internals into C++. Moving internals into C++ makes them less hackable and increases the barrier of entry for code contributions.
From day one, we knew the performance limits of eager execution. In July 2017, we started our first research project into developing a Compiler for PyTorch. The compiler needed to make a PyTorch program fast, but not at the cost of the PyTorch experience. Our key criteria was to preserve certain kinds of flexibility – support for dynamic shapes and dynamic programs which researchers use in various stages of exploration.
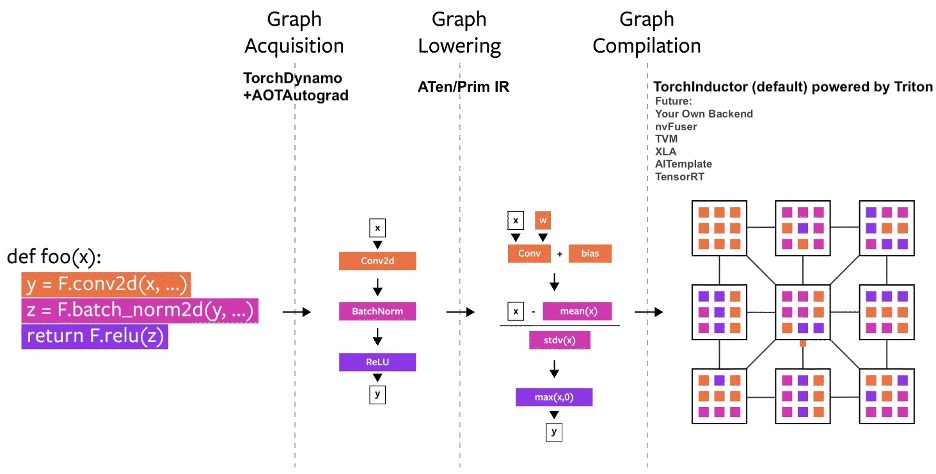
Technology Overview
Over the years, we’ve built several compiler projects within PyTorch. Let us break down the compiler into three parts:
- graph acquisition
- graph lowering
- graph compilation
Graph acquisition was the harder challenge when building a PyTorch compiler.
In the past 5 years, we built torch.jit.trace, TorchScript, FX tracing, Lazy Tensors. But none of them felt like they gave us everything we wanted. Some were flexible but not fast, some were fast but not flexible and some were neither fast nor flexible. Some had bad user-experience (like being silently wrong). While TorchScript was promising, it needed substantial changes to your code and the code that your code depended on. This need for substantial change in code made it a non-starter for a lot of PyTorch users.
TorchDynamo: Acquiring Graphs reliably and fast
Earlier this year, we started working on TorchDynamo, an approach that uses a CPython feature introduced in PEP-0523 called the Frame Evaluation API. We took a data-driven approach to validate its effectiveness on Graph Capture. We used 7,000+ Github projects written in PyTorch as our validation set. While TorchScript and others struggled to even acquire the graph 50% of the time, often with a big overhead, TorchDynamo acquired the graph 99% of the time, correctly, safely and with negligible overhead – without needing any changes to the original code. This is when we knew that we finally broke through the barrier that we were struggling with for many years in terms of flexibility and speed.
TorchInductor: fast codegen using a define-by-run IR
For a new compiler backend for PyTorch 2.0, we took inspiration from how our users were writing high performance custom kernels: increasingly using the Triton language. We also wanted a compiler backend that used similar abstractions to PyTorch eager, and was general purpose enough to support the wide breadth of features in PyTorch. TorchInductor uses a pythonic define-by-run loop level IR to automatically map PyTorch models into generated Triton code on GPUs and C++/OpenMP on CPUs. TorchInductor’s core loop level IR contains only ~50 operators, and it is implemented in Python, making it easily hackable and extensible.
AOTAutograd: reusing Autograd for ahead-of-time graphs
For PyTorch 2.0, we knew that we wanted to accelerate training. Thus, it was critical that we not only captured user-level code, but also that we captured backpropagation. Moreover, we knew that we wanted to reuse the existing battle-tested PyTorch autograd system. AOTAutograd leverages PyTorch’s torch_dispatch extensibility mechanism to trace through our Autograd engine, allowing us to capture the backwards pass “ahead-of-time”. This allows us to accelerate both our forwards and backwards pass using TorchInductor.
PrimTorch: Stable Primitive operators
Writing a backend for PyTorch is challenging. PyTorch has 1200+ operators, and 2000+ if you consider various overloads for each operator.
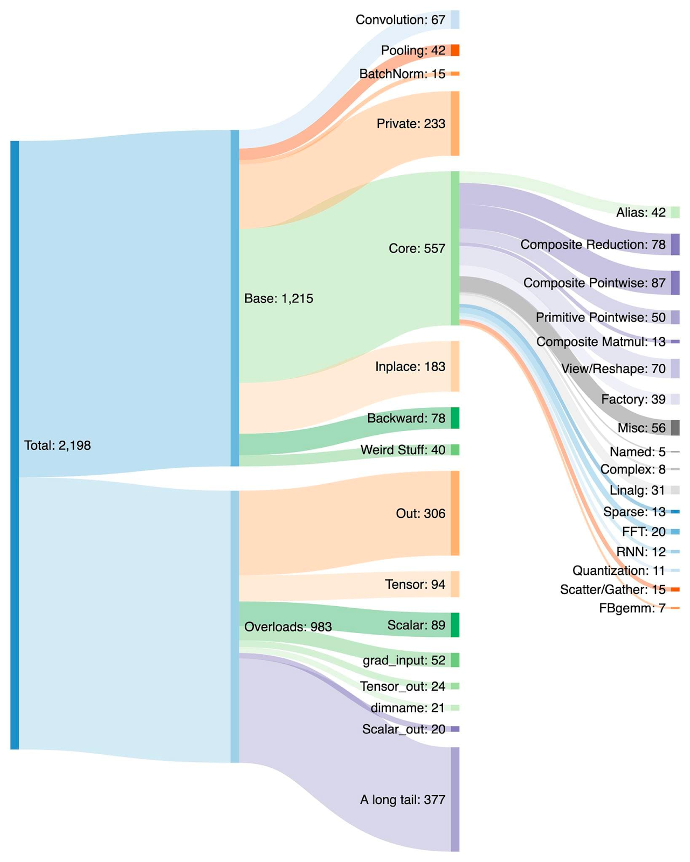
Hence, writing a backend or a cross-cutting feature becomes a draining endeavor. Within the PrimTorch project, we are working on defining smaller and stable operator sets. PyTorch programs can consistently be lowered to these operator sets. We aim to define two operator sets:
- Prim ops with about ~250 operators, which are fairly low-level. These are suited for compilers because they are low-level enough that you need to fuse them back together to get good performance.
- ATen ops with about ~750 canonical operators and suited for exporting as-is. These are suited for backends that already integrate at the ATen level or backends that won’t have compilation to recover performance from a lower-level operator set like Prim ops.
We discuss more about this topic below in the Developer/Vendor Experience section
User Experience
We introduce a simple function torch.compile that wraps your model and returns a compiled model.
compiled_model = torch.compile(model)
This compiled_model holds a reference to your model and compiles the forward function to a more optimized version. When compiling the model, we give a few knobs to adjust it:
def torch.compile(model: Callable,
*,
mode: Optional[str] = "default",
dynamic: bool = False,
fullgraph:bool = False,
backend: Union[str, Callable] = "inductor",
# advanced backend options go here as kwargs
**kwargs
) -> torch._dynamo.NNOptimizedModule
-
mode specifies what the compiler should be optimizing while compiling.
- The default mode is a preset that tries to compile efficiently without taking too long to compile or using extra memory.
- Other modes such as
reduce-overheadreduce the framework overhead by a lot more, but cost a small amount of extra memory.max-autotunecompiles for a long time, trying to give you the fastest code it can generate.
- dynamic specifies whether to enable the code path for Dynamic Shapes. Certain compiler optimizations cannot be applied to dynamic shaped programs. Making it explicit whether you want a compiled program with dynamic shapes or with static shapes will help the compiler give you better optimized code.
- fullgraph is similar to Numba’s
nopython. It compiles the entire program into a single graph or gives an error explaining why it could not do so. Most users don’t need to use this mode. If you are very performance conscious, then you try to use it. - backend specifies which compiler backend to use. By default, TorchInductor is used, but there are a few others available.

The compile experience intends to deliver most benefits and the most flexibility in the default mode. Here is a mental model of what you get in each mode.
Now, let us look at a full example of compiling a real model and running it (with random data)
import torch
import torchvision.models as models
model = models.resnet18().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
compiled_model = torch.compile(model)
x = torch.randn(16, 3, 224, 224).cuda()
optimizer.zero_grad()
out = compiled_model(x)
out.sum().backward()
optimizer.step()
The first time you run the compiled_model(x), it compiles the model. Hence, it takes longer to run. Subsequent runs are fast.
Modes
The compiler has a few presets that tune the compiled model in different ways. You might be running a small model that is slow because of framework overhead. Or, you might be running a large model that barely fits into memory. Depending on your need, you might want to use a different mode.
# API NOT FINAL
# default: optimizes for large models, low compile-time
# and no extra memory usage
torch.compile(model)
# reduce-overhead: optimizes to reduce the framework overhead
# and uses some extra memory. Helps speed up small models
torch.compile(model, mode="reduce-overhead")
# max-autotune: optimizes to produce the fastest model,
# but takes a very long time to compile
torch.compile(model, mode="max-autotune")
Reading and updating Attributes
Accessing model attributes work as they would in eager mode.
You can access or modify attributes of your model (such as model.conv1.weight) as you generally would. This is completely safe and sound in terms of code correction. TorchDynamo inserts guards into the code to check if its assumptions hold true. If attributes change in certain ways, then TorchDynamo knows to recompile automatically as needed.
# optimized_model works similar to model, feel free to access its attributes and modify them
optimized_model.conv1.weight.fill_(0.01)
# this change is reflected in model
Hooks
Module and Tensor hooks don’t fully work at the moment, but they will eventually work as we finish development.
Serialization
You can serialize the state-dict of the optimized_model OR the model. They point to the same parameters and state and hence are equivalent.
torch.save(optimized_model.state_dict(), "foo.pt")
# both these lines of code do the same thing
torch.save(model.state_dict(), "foo.pt")
You cannot serialize optimized_model currently. If you wish to save the object directly, save model instead.
torch.save(optimized_model, "foo.pt") # Error
torch.save(model, "foo.pt") # Works
Inference and Export
For model inference, after generating a compiled model using torch.compile, run some warm-up steps before actual model serving. This helps mitigate latency spikes during initial serving.
In addition, we will be introducing a mode called torch.export that carefully exports the entire model and the guard infrastructure for environments that need guaranteed and predictable latency. torch.export would need changes to your program, especially if you have data dependent control-flow.
# API Not Final
exported_model = torch._dynamo.export(model, input)
torch.save(exported_model, "foo.pt")
This is in early stages of development. Catch the talk on Export Path at the PyTorch Conference for more details. You can also engage on this topic at our “Ask the Engineers: 2.0 Live Q&A Series” starting this month (more details at the end of this post).
Debugging Issues
A compiled mode is opaque and hard to debug. You will have questions such as:
- Why is my program crashing in compiled mode?
- Is compiled mode as accurate as eager mode?
- Why am I not seeing speedups?
If compiled mode produces an error or a crash or diverging results from eager mode (beyond machine precision limits), it is very unlikely that it is your code’s fault. However, understanding what piece of code is the reason for the bug is useful.
To aid in debugging and reproducibility, we have created several tools and logging capabilities out of which one stands out: The Minifier.
The minifier automatically reduces the issue you are seeing to a small snippet of code. This small snippet of code reproduces the original issue and you can file a github issue with the minified code. This will help the PyTorch team fix the issue easily and quickly.
If you are not seeing the speedups that you expect, then we have the torch._dynamo.explain tool that explains which parts of your code induced what we call “graph breaks”. Graph breaks generally hinder the compiler from speeding up the code, and reducing the number of graph breaks likely will speed up your code (up to some limit of diminishing returns).
You can read about these and more in our troubleshooting guide.
Dynamic Shapes
When looking at what was necessary to support the generality of PyTorch code, one key requirement was supporting dynamic shapes, and allowing models to take in tensors of different sizes without inducing recompilation every time the shape changes.
As of today, support for Dynamic Shapes is limited and a rapid work in progress. It will be fully featured by stable release. It is gated behind a dynamic=True argument, and we have more progress on a feature branch (symbolic-shapes), on which we have successfully run BERT_pytorch in training with full symbolic shapes with TorchInductor. For inference with dynamic shapes, we have more coverage. For example, let’s look at a common setting where dynamic shapes are helpful - text generation with language models.
We can see that even when the shape changes dynamically from 4 all the way to 256, Compiled mode is able to consistently outperform eager by up to 40%. Without support for dynamic shapes, a common workaround is to pad to the nearest power of two. However, as we can see from the charts below, it incurs a significant amount of performance overhead, and also results in significantly longer compilation time. Moreover, padding is sometimes non-trivial to do correctly.
By supporting dynamic shapes in PyTorch 2.0’s Compiled mode, we can get the best of performance and ease of use.
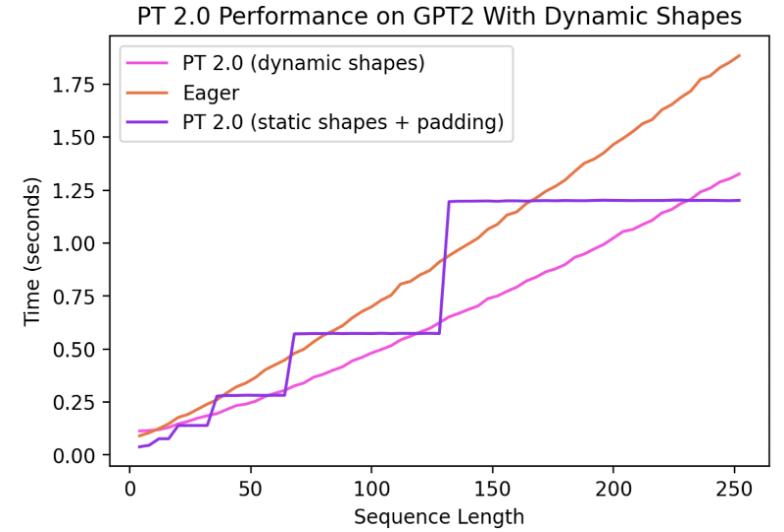
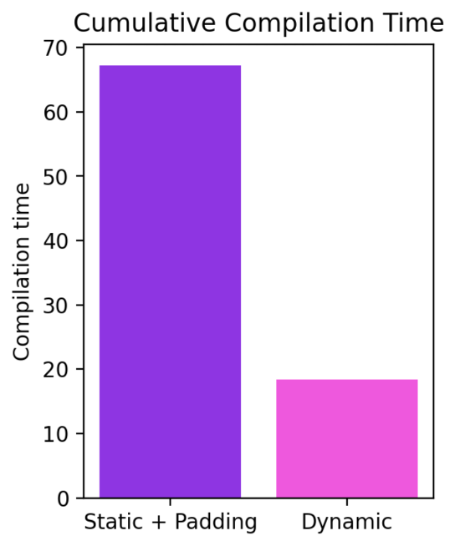
The current work is evolving very rapidly and we may temporarily let some models regress as we land fundamental improvements to infrastructure. The latest updates for our progress on dynamic shapes can be found here.
Distributed
In summary, torch.distributed’s two main distributed wrappers work well in compiled mode.
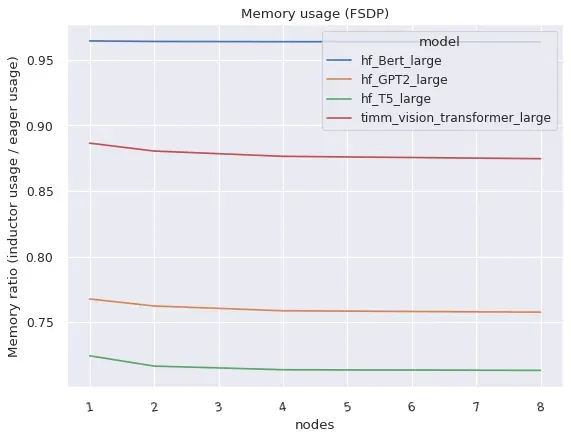
Both DistributedDataParallel (DDP) and FullyShardedDataParallel (FSDP) work in compiled mode and provide improved performance and memory utilization relative to eager mode, with some caveats and limitations.
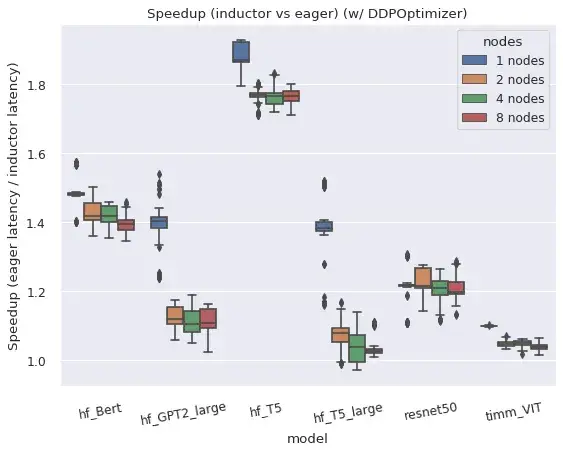
Right: FSDP in Compiled mode takes substantially lesser memory than in eager mode
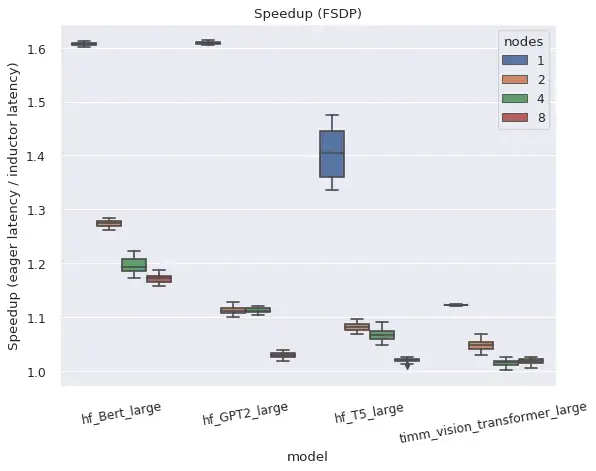
DistributedDataParallel (DDP)
DDP relies on overlapping AllReduce communications with backwards computation, and grouping smaller per-layer AllReduce operations into ‘buckets’ for greater efficiency. AOTAutograd functions compiled by TorchDynamo prevent communication overlap, when combined naively with DDP, but performance is recovered by compiling separate subgraphs for each ‘bucket’ and allowing communication ops to happen outside and in-between the subgraphs. DDP support in compiled mode also currently requires static_graph=False. See this post for more details on the approach and results for DDP + TorchDynamo.
FullyShardedDataParallel (FSDP)
FSDP itself is a “beta” PyTorch feature and has a higher level of system complexity than DDP due to the ability to tune which submodules are wrapped and because there are generally more configuration options. FSDP works with TorchDynamo and TorchInductor for a variety of popular models, if configured with the use_original_params=True flag. Some compatibility issues with particular models or configurations are expected at this time, but will be actively improved, and particular models can be prioritized if github issues are filed.
Users specify an auto_wrap_policy argument to indicate which submodules of their model to wrap together in an FSDP instance used for state sharding, or manually wrap submodules in FSDP instances. For example, many transformer models work well when each ‘transformer block’ is wrapped in a separate FSDP instance and thus only the full state of one transformer block needs to be materialized at one time. Dynamo will insert graph breaks at the boundary of each FSDP instance, to allow communication ops in forward (and backward) to happen outside the graphs and in parallel to computation.
If FSDP is used without wrapping submodules in separate instances, it falls back to operating similarly to DDP, but without bucketing. Hence all gradients are reduced in one operation, and there can be no compute/communication overlap even in Eager. This configuration has only been tested with TorchDynamo for functionality but not for performance.
Developer/Vendor Experience
With PyTorch 2.0, we want to simplify the backend (compiler) integration experience. To do this, we have focused on reducing the number of operators and simplifying the semantics of the operator set necessary to bring up a PyTorch backend.
In graphical form, the PT2 stack looks like:
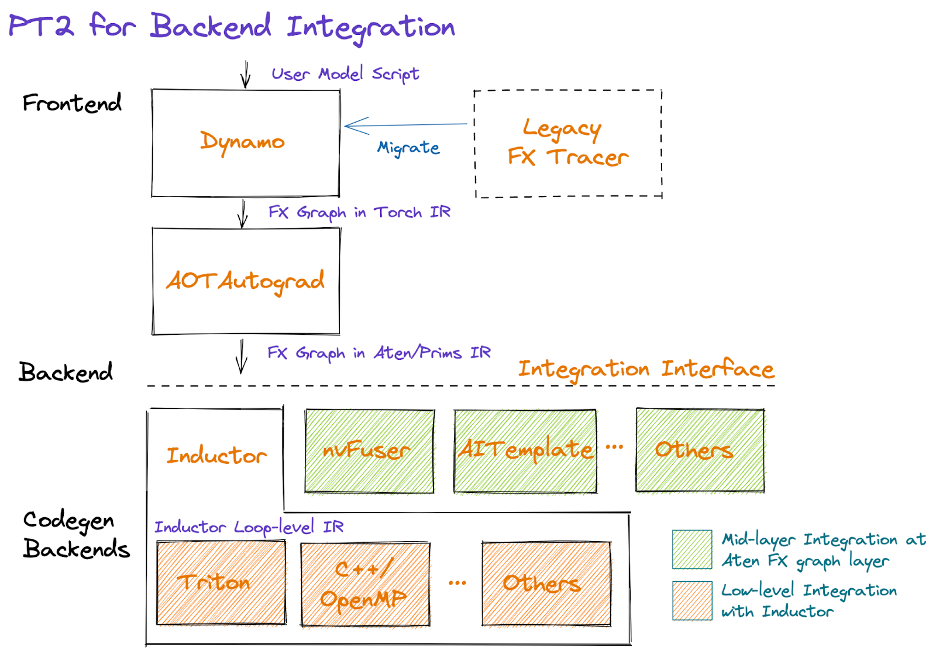
Starting in the middle of the diagram, AOTAutograd dynamically captures autograd logic in an ahead-of-time fashion, producing a graph of forward and backwards operators in FX graph format.
We provide a set of hardened decompositions (i.e. operator implementations written in terms of other operators) that can be leveraged to reduce the number of operators a backend is required to implement. We also simplify the semantics of PyTorch operators by selectively rewriting complicated PyTorch logic including mutations and views via a process called functionalization, as well as guaranteeing operator metadata information such as shape propagation formulas. This work is actively in progress; our goal is to provide a primitive and stable set of ~250 operators with simplified semantics, called PrimTorch, that vendors can leverage (i.e. opt-in to) in order to simplify their integrations.
After reducing and simplifying the operator set, backends may choose to integrate at the Dynamo (i.e. the middle layer, immediately after AOTAutograd) or Inductor (the lower layer). We describe some considerations in making this choice below, as well as future work around mixtures of backends.
Dynamo Backend
Vendors with existing compiler stacks may find it easiest to integrate as a TorchDynamo backend, receiving an FX Graph in terms of ATen/Prims IR. Note that for both training and inference, the integration point would be immediately after AOTAutograd, since we currently apply decompositions as part of AOTAutograd, and merely skip the backward-specific steps if targeting inference.
Inductor backend
Vendors can also integrate their backend directly into Inductor. Inductor takes in a graph produced by AOTAutograd that consists of ATen/Prim operations, and further lowers them down to a loop level IR. Today, Inductor provides lowerings to its loop-level IR for pointwise, reduction, scatter/gather and window operations. In addition, Inductor creates fusion groups, does indexing simplification, dimension collapsing, and tunes loop iteration order in order to support efficient code generation. Vendors can then integrate by providing the mapping from the loop level IR to hardware-specific code. Currently, Inductor has two backends: (1) C++ that generates multithreaded CPU code, (2) Triton that generates performant GPU code. These Inductor backends can be used as an inspiration for the alternate backends.
Mixture of Backends Interface (coming soon)
We have built utilities for partitioning an FX graph into subgraphs that contain operators supported by a backend and executing the remainder eagerly. These utilities can be extended to support a “mixture of backends,” configuring which portions of the graphs to run for which backend. However, there is not yet a stable interface or contract for backends to expose their operator support, preferences for patterns of operators, etc. This remains as ongoing work, and we welcome feedback from early adopters.
Final Thoughts
We are super excited about the direction that we’ve taken for PyTorch 2.0 and beyond. The road to the final 2.0 release is going to be rough, but come join us on this journey early-on. If you are interested in deep-diving further or contributing to the compiler, please continue reading below which includes more information on how to get started (e.g., tutorials, benchmarks, models, FAQs) and Ask the Engineers: 2.0 Live Q&A Series starting this month. Additional resources include:
Accelerating Hugging Face and TIMM models with PyTorch 2.0
Author: Mark Saroufim
torch.compile() makes it easy to experiment with different compiler backends to make PyTorch code faster with a single line decorator torch.compile(). It works either directly over an nn.Module as a drop-in replacement for torch.jit.script() but without requiring you to make any source code changes. We expect this one line code change to provide you with between 30%-2x training time speedups on the vast majority of models that you’re already running.
opt_module = torch.compile(module)
torch.compile supports arbitrary PyTorch code, control flow, mutation and comes with experimental support for dynamic shapes. We’re so excited about this development that we call it PyTorch 2.0.
What makes this announcement different for us is we’ve already benchmarked some of the most popular open source PyTorch models and gotten substantial speedups ranging from 30% to 2x https://github.com/pytorch/torchdynamo/issues/681.
There are no tricks here, we’ve pip installed popular libraries like https://github.com/huggingface/transformers, https://github.com/huggingface/accelerate and https://github.com/rwightman/pytorch-image-models and then ran torch.compile() on them and that’s it.
It’s rare to get both performance and convenience, but this is why the core team finds PyTorch 2.0 so exciting.
Requirements
For GPU (newer generation GPUs will see drastically better performance)
pip3 install numpy --pre torch --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117
For CPU
pip3 install --pre torch --index-url https://download.pytorch.org/whl/nightly/cpu
Optional: Verify Installation
git clone https://github.com/pytorch/pytorch
cd tools/dynamo
python verify_dynamo.py
Optional: Docker installation
We also provide all the required dependencies in the PyTorch nightly binaries which you can download with
docker pull ghcr.io/pytorch/pytorch-nightly
And for ad hoc experiments just make sure that your container has access to all your GPUs
docker run --gpus all -it ghcr.io/pytorch/pytorch-nightly:latest /bin/bash
Getting Started
Please read Mark Saroufim’s full blog post where he walks you through a tutorial and real models for you to try PyTorch 2.0 today.
Our goal with PyTorch was to build a breadth-first compiler that would speed up the vast majority of actual models people run in open source. The Hugging Face Hub ended up being an extremely valuable benchmarking tool for us, ensuring that any optimization we work on actually helps accelerate models people want to run.
The blog tutorial will show you exactly how to replicate those speedups so you can be as excited as to PyTorch 2.0 as we are. So please try out PyTorch 2.0, enjoy the free perf and if you’re not seeing it then please open an issue and we will make sure your model is supported https://github.com/pytorch/torchdynamo/issues
After all, we can’t claim we’re created a breadth-first unless YOUR models actually run faster.
FAQs
-
What is PT 2.0?
2.0 is the latest PyTorch version. PyTorch 2.0 offers the same eager-mode development experience, while adding a compiled mode via torch.compile. This compiled mode has the potential to speedup your models during training and inference. -
Why 2.0 instead of 1.14?
PyTorch 2.0 is what 1.14 would have been. We were releasing substantial new features that we believe change how you meaningfully use PyTorch, so we are calling it 2.0 instead. -
How do I install 2.0? Any additional requirements?
Install the latest nightlies:
CUDA 11.8
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu118CUDA 11.7
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu117CPU
pip3 install numpy --pre torch torchvision torchaudio --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cpu -
Is 2.0 code backwards-compatible with 1.X?
Yes, using 2.0 will not require you to modify your PyTorch workflows. A single line of codemodel = torch.compile(model)can optimize your model to use the 2.0 stack, and smoothly run with the rest of your PyTorch code. This is completely opt-in, and you are not required to use the new compiler. -
Is 2.0 enabled by default?
2.0 is the name of the release. torch.compile is the feature released in 2.0, and you need to explicitly use torch.compile. - How do I migrate my PT1.X code to PT2.0?
Your code should be working as-is without the need for any migrations. If you want to use the new Compiled mode feature introduced in 2.0, then you can start by optimizing your model with one line:model = torch.compile(model).
While the speedups are primarily observed during training, you can also use it for inference if your model runs faster than eager mode.import torch def train(model, dataloader): model = torch.compile(model) for batch in dataloader: run_epoch(model, batch) def infer(model, input): model = torch.compile(model) return model(\*\*input) -
Why should I use PT2.0 instead of PT 1.X?
See answer to Question (2). - What is my code doing differently when running PyTorch 2.0?
Out of the box, PyTorch 2.0 is the same as PyTorch 1.x, your models run in eager-mode i.e. every line of Python is executed one after the other.
In 2.0, if you wrap your model inmodel = torch.compile(model), your model goes through 3 steps before execution:- Graph acquisition: first the model is rewritten as blocks of subgraphs. Subgraphs which can be compiled by TorchDynamo are “flattened” and the other subgraphs (which might contain control-flow code or other unsupported Python constructs) will fall back to Eager-Mode.
- Graph lowering: all the PyTorch operations are decomposed into their constituent kernels specific to the chosen backend.
- Graph compilation, where the kernels call their corresponding low-level device-specific operations.
- What new components does PT2.0 add to PT?
- TorchDynamo generates FX Graphs from Python bytecode. It maintains the eager-mode capabilities using guards to ensure the generated graphs are valid (read more)
- AOTAutograd to generate the backward graph corresponding to the forward graph captured by TorchDynamo (read more).
- PrimTorch to decompose complicated PyTorch operations into simpler and more elementary ops (read more).
- [Backend] Backends integrate with TorchDynamo to compile the graph into IR that can run on accelerators. For example, TorchInductor compiles the graph to either Triton for GPU execution or OpenMP for CPU execution (read more).
-
What compiler backends does 2.0 currently support?
The default and the most complete backend is TorchInductor, but TorchDynamo has a growing list of backends that can be found by callingtorchdynamo.list_backends(). -
How does distributed training work with 2.0?
DDP and FSDP in Compiled mode can run up to 15% faster than Eager-Mode in FP32 and up to 80% faster in AMP precision. PT2.0 does some extra optimization to ensure DDP’s communication-computation overlap works well with Dynamo’s partial graph creation. Ensure you run DDP with static_graph=False. More details here. -
How can I learn more about PT2.0 developments?
The PyTorch Developers forum is the best place to learn about 2.0 components directly from the developers who build them. -
Help my code is running slower with 2.0’s Compiled Mode!
The most likely reason for performance hits is too many graph breaks. For instance, something innocuous as a print statement in your model’s forward triggers a graph break. We have ways to diagnose these - read more here. - My previously-running code is crashing with 2.0’s Compiled Mode! How do I debug it?
Here are some techniques to triage where your code might be failing, and printing helpful logs: https://pytorch.org/docs/stable/torch.compiler_faq.html#why-is-my-code-crashing.
Ask the Engineers: 2.0 Live Q&A Series
We will be hosting a series of live Q&A sessions for the community to have deeper questions and dialogue with the experts. Please check back to see the full calendar of topics throughout the year. If you are unable to attend: 1) They will be recorded for future viewing and 2) You can attend our Dev Infra Office Hours every Friday at 10 AM PST @ https://github.com/pytorch/pytorch/wiki/Dev-Infra-Office-Hours.
Please click here to see dates, times, descriptions and links.
Disclaimer: Please do not share your personal information, last name, company when joining the live sessions and submitting questions.
| TOPIC | HOST |
| The new developer experience of using 2.0 (install, setup, clone an example, run with 2.0) | Suraj Subramanian LinkedIn | Twitter |
| PT2 Profiling and Debugging | Bert Maher LinkedIn | Twitter |
| A deep dive on TorchInductor and PT 2.0 Backend Integration | Natalia Gimelshein, Bin Bao and Sherlock Huang Natalia Gimelshein Sherlock Huang |
| Extend PyTorch without C++ and functorch: JAX-like composable function transforms for PyTorch | Anjali Chourdia and Samantha Andow Anjali Chourdia LinkedIn | Twitter Samantha Andow LinkedIn | Twitter |
| A deep dive on TorchDynamo | Michael Voznesensky |
| Rethinking data loading with TorchData:Datapipes and Dataloader2 | Kevin Tse |
| Composable training (+ torcheval, torchsnapshot) | Ananth Subramaniam |
| How and why contribute code and tutorials to PyTorch | Zain Rizvi, Svetlana Karslioglu and Carl Parker Zain Rizvi LinkedIn | Twitter Svetlana Karslioglu LinkedIn | Twitter |
| Dynamic Shapes and Calculating Maximum Batch Size | Edward Yang and Elias Ellison Edward Yang |
| PyTorch 2.0 Export: Sound Whole Graph Capture for PyTorch | Michael Suo and Yanan Cao Yanan Cao |
| 2-D Parallelism using DistributedTensor and PyTorch DistributedTensor | Wanchao Liang and Alisson Gusatti Azzolini Wanchao Liang LinkedIn | Twitter Alisson Gusatti Azzolini |
| TorchRec and FSDP in Production | Dennis van der Staay, Andrew Gu and Rohan Varma Dennis van der Staay Rohan Varma LinkedIn | Twitter |
| The Future of PyTorch On-Device | Raziel Alvarez Guevara LinkedIn | Twitter |
| TorchMultiModal Intro Blog Scaling Blog |
Kartikay Khandelwal LinkedIn | Twitter |
| BetterTransformers (+ integration with Hugging Face), Model Serving and Optimizations Blog 1 Github |
Hamid Shojanazeri and Mark Saroufim Mark Saroufim LinkedIn | Twitter |
| PT2 and Distributed | Will Constable |
