Today, we’re releasing torchchat, a library showcasing how to seamlessly and performantly run Llama 3, 3.1, and other large language models across laptop, desktop, and mobile.
In our previous blog posts, we showed how to use native PyTorch 2 to run LLMs with great performance using CUDA. Torchchat expands on this with more target environments, models and execution modes. Additionally it provides important functions such as export, quantization and eval in a way that’s easy to understand providing an E2E story for those who want to build a local inference solution.
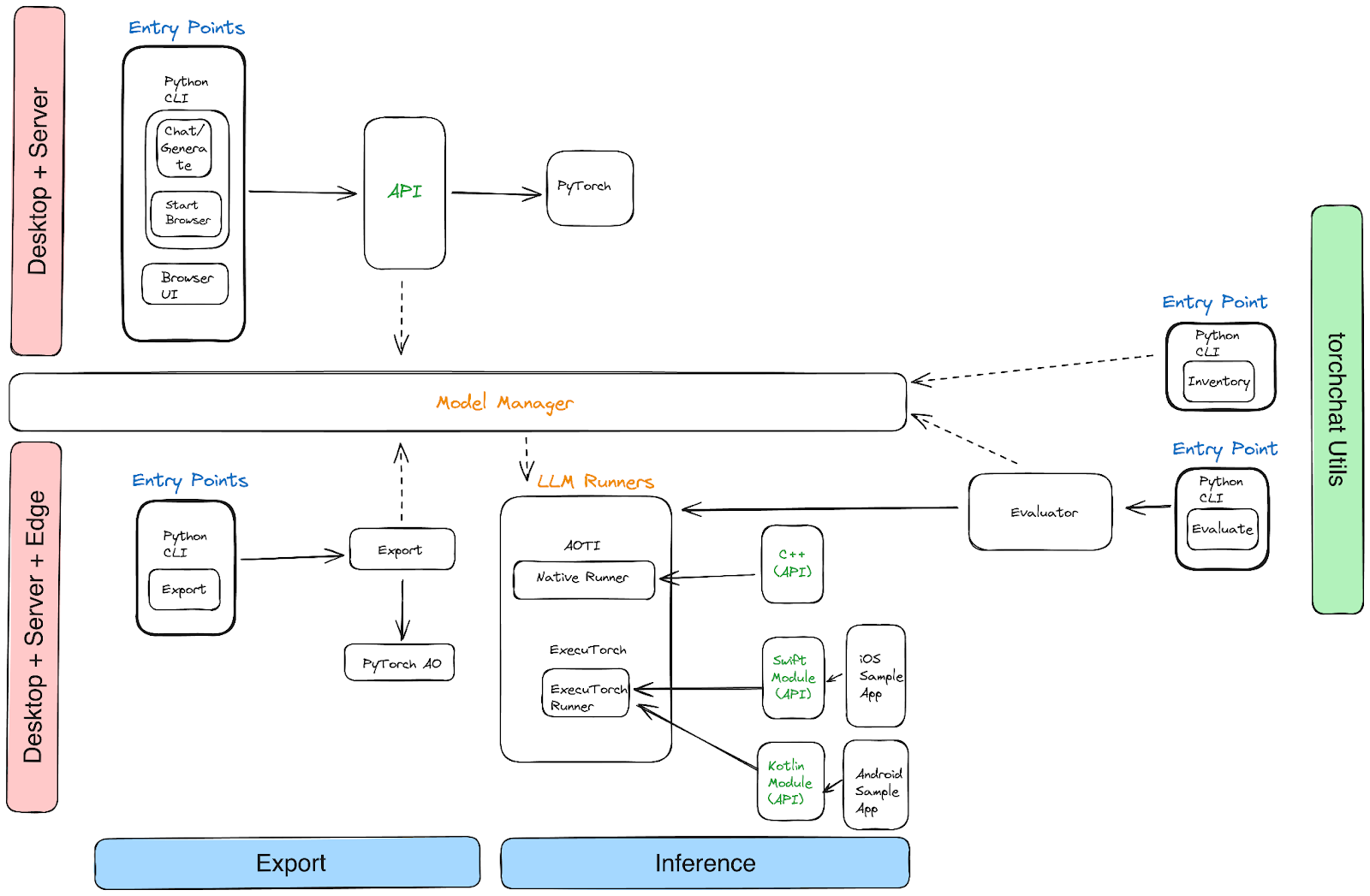
You will find the project organized into three areas:
- Python: Torchchat provides a REST API that is called via a Python CLI or can be accessed via the browser
- C++: Torchchat produces a desktop-friendly binary using PyTorch’s AOTInductor backend
- Mobile devices: Torchchat uses ExecuTorch to export a .pte binary file for on-device inference
Performance
The following table tracks the performance of torchchat for Llama 3 for a variety of configurations.
Numbers for Llama 3.1 are coming soon.
Llama 3 8B Instruct on Apple MacBook Pro M1 Max 64GB Laptop
| Mode | DType | Llama 3 8B Tokens/Sec |
| Arm Compile | float16 | 5.84 |
| int8 | 1.63 | |
| int4 | 3.99 | |
| Arm AOTI | float16 | 4.05 |
| int8 | 1.05 | |
| int4 | 3.28 | |
| MPS Eager | float16 | 12.63 |
| int8 | 16.9 | |
| int4 | 17.15 |
Llama 3 8B Instruct on Linux x86 and CUDA
Intel(R) Xeon(R) Platinum 8339HC CPU @ 1.80GHz with 180GB Ram + A100 (80GB)
| Mode | DType | Llama 3 8B Tokens/Sec |
| x86 Compile | bfloat16 | 2.76 |
| int8 | 3.15 | |
| int4 | 5.33 | |
| CUDA Compile | bfloat16 | 83.23 |
| int8 | 118.17 | |
| int4 | 135.16 |
Llama3 8B Instruct on Mobile
Torchchat achieves > 8T/s on the Samsung Galaxy S23 and iPhone using 4-bit GPTQ via ExecuTorch.
Conclusion
We encourage you to clone the torchchat repo and give it a spin, explore its capabilities, and share your feedback as we continue to empower the PyTorch community to run LLMs locally and on constrained devices. Together, let’s unlock the full potential of generative AI and LLMs on any device. Please submit issues as you see them, since we are still iterating quickly. We’re also inviting community contributions across a broad range of areas, from additional models, target hardware support, new quantization schemes, or performance improvements. Happy experimenting!