In this blog, we demonstrate the scalability of FSDP with a pre-training exemplar, a 7B model trained for 2T tokens, and share various techniques we used to achieve a rapid training speed of 3,700 tokens/sec/GPU, or 40B tokens/day on 128 A100 GPUs. This translates to a model FLOPS utilization (MFU) and hardware FLOPS utilization (HFU) of 57%. Additionally, we have observed near linear scaling of FSDP to 512 GPUs, implying that training a 7B model on 512 GPUs to 2T tokens using this method would take just under two weeks.
IBM researchers trained a Meta Llama 2 7B architecture to 2T tokens, which we will refer to as LlamaT(est). This model demonstrates comparable model quality as Llama 2 on various academic benchmarks. All of the training code, along with our methodology to achieve this throughput, can be found in this blog. We also share the configuration knobs that work well for the Llama 2 models – 7B, 13B, 34B, and 70B for A100s and H100s.
In this process, we also propose a _new _selective activation checkpointing mechanism that applies to FSDP which gives us a 10% boost beyond out-of-the box FSDP. We have open sourced the training code base and an associated scalable data loader as the methodology to achieve this throughput.
One key benefit of a PyTorch native pathway for training is the ability to seamlessly train on multiple hardware backends. For example, the recent end-to-end stack for training that was released by AllenAI through OLMo also leverages PyTorch FSDP for training on AMD and NVIDIA GPUs. There are three main components that we leverage from FSDP to achieve our throughput:
- SDPA Flash attention, that enables fused attention kernels and efficient attention computation
- Overlap in computation and communication allows for better utilization of the GPU
- Selective activation checkpointing enables us to tradeoff between GPU memory and compute
IBM has been working closely with Team PyTorch at Meta on PyTorch FSDP for nearly two years: introducing the rate limiter for achieving better throughput on Ethernet interconnects, distributed checkpointing to improve the checkpoint times by an order of magnitude, and implementing the early version of checkpointing for the hybrid sharding mode of FSDP. Late last year, we used FSDP to train a model end-to-end.
Training Details
The 7B model is trained on 128 A100 GPUs with 400Gbps network connectivity and GPU direct RDMA. We use SDPA FlashAttention v2 for attention computation, and for this model we turned off activation checkpointing that limits the batch size, but provides the highest throughput – batch size is 1 million tokens per batch for 128 GPUs and improves throughput by about 10% when compared to activation checkpointing. With these parameters, we have an almost full overlap in computation and communication. We use the AdamW optimizer in 32-bit with beta1 of 0.9 and beta2 of 0.95, weight decay of 0.1, and a learning rate ending at 3e-5 with a warmup to max learning rate of 3e-4 and a cosine schedule to reduce to 3e-5 over 2T tokens. The training was performed using mixed precision bf16 on an internal dataset. The training stack is using IBM’s Foundation Model Stack for model architecture and PyTorch nightlies post-2.2 release for FSDP and SDPA. We tried a few different nightlies during the time period of Nov 2023 through Feb 2024 and we observed an improvement in the throughput.
Selective activation checkpointing
We jointly implemented a simple and effective mechanism of selective activation checkpointing (AC). In FSDP, the common practice is to checkpoint each transformer block. A simple extension is to checkpoint every _n _blocks and reduce the amount of recomputation, while increasing the memory needed. This is quite effective for the 13B model size, increasing the throughput by 10%. For the 7B model size, we did not need activation checkpointing at all. Future versions of FSDP will provide selective activation checkpointing at an operator level, enabling an optimal compute-memory tradeoff. The code for the above is implemented here.
Throughput and MFU, HFU computation
While we only trained the 7B model to 2T tokens, we performed numerous experiments on the other model sizes to provide the best configuration options. This is summarized in the table below for two types of infrastructure — an A100 cluster with 128 GPUs and 400Gbps inter-node interconnect, and an H100 cluster with 96 GPUs and 800Gbps inter-node interconnect.
| Model size | Batch size | Activation checkpoint | Throughput tokens/sec/GPU (A100 80GB and 400Gbps interconnect) | MFU % (A100 80GB) | HFU % (A100 80GB) | Throughput tokens/sec/GPU (H100 80GB and 800Gbps interconnect) | MFU % (H100 80GB) | HFU % (H100 80GB) |
| 7B | 2 | No | 3700 | 0.57 | 0.57 | 7500 | 0.37 | 0.37 |
| 13B | 2 | Selective | 1800 | 0.51 | 0.59 | 3800 | 0.35 | 0.40 |
| 34B | 2 | Yes | 700 | 0.47 | 0.64 | 1550 | 0.32 | 0.44 |
| 70B | 2 | Yes | 370 | 0.50 | 0.67 | 800 | 0.34 | 0.45 |
Table 1: Model and Hardware FLOPS utilization of various model sizes on A100 and H100 GPUs
HFU numbers are computed using the PyTorch FLOP counter and the theoretical bf16 performance of A100 and H100 GPUs, whereas MFU numbers are computed using the methodology outlined in NanoGPT and the PaLM paper. We also note that the batch sizes we use for the larger models are intentionally kept at 2 per GPU to mimic choices made in training models of 4k sequence length and achieve this up to 512 GPUs without exceeding the 4M tokens popular batch size. Beyond that, we would need tensor parallelism or sequence parallelism.
We note in the table above that for A100s, that activation recomputation causes the MFU to reduce, while HFU increases! With the introduction of better activation checkpointing schemes, we expect MFU to increase and catch up with HFU. However, we observe that for H100s, both MFU and HFU are relatively low. We analyze the PyTorch profile traces on H100 and observe that there is a 10% gap due to network “peeking” out. In addition, we hypothesize that the HBM bandwidth of H100s is the cause for the reduced HFU/MFU on H100s and not being able to obtain the 3x improvement (H100s are theoretically 3x faster than A100s – 312 vs 989TFLOPS, but only have <2x the HBM bandwidth than A100s – 2.0 vs 3.35TBps). We plan to try out other configuration options like Tensor Parallel to improve the knobs for the 70B model on H100s.
Model details
The loss curve for training is shown in the below figure.
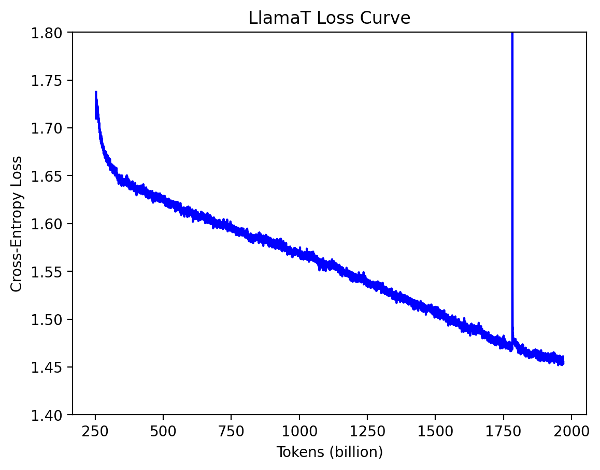
Figure 1: LlamaT training loss curve
The 2T checkpoint is converted to Hugging Face format by a script that is provided in the repository and we then use lm-evaluation-harness to compute key academic benchmarks and compare that by running it on Llama2-7B. These results are captured in the below table.
| Evaluation metric | Llama2-7B (baseline) | LlamaT-7B |
| MMLU (zero shot) | 0.41 | 0.43 |
| MMLU (5-shot weighted avg) | 0.47 | 0.50 |
| Arc challenge | 0.46 | 0.44 |
| Arc easy | 0.74 | 0.71 |
| Boolq | 0.78 | 0.76 |
| Copa | 0.87 | 0.83 |
| Hellaswag | 0.76 | 0.74 |
| Openbookqa | 0.44 | 0.42 |
| Piqa | 0.79 | 0.79 |
| Sciq | 0.91 | 0.91 |
| Winogrande | 0.69 | 0.67 |
| Truthfulqa | 0.39 | 0.39 |
| GSM8k (8-shot) | 0.13 | 0.11 |
Table 1: LM eval harness scores
We observe that the model performs competitively with Llama2 (bolder is better).
Training chronicles
Training was stable with no crashes, though we did observe a few hiccups:
0-200B tokens: We observed a slowdown in the iteration time (time taken to execute one training step). We stopped the job to ensure that the data loader was not causing any slowdowns and the checkpointing was performant and accurate. We did not find any issues. By this time, HSDP checkpointing code was available in PyTorch, and we took this opportunity to make the switch to PyTorch checkpointing code.
200B tokens-1.9T: We did not do any manual intervention in the job in late December. When we came back early January, disk space had exceeded and checkpoints were failing to be written, although the training job continued. The last known checkpoint was 1.5T.
1.5T-1.7T: We evaluated the 1.5T checkpoint with lm-evaluation-harness and discovered that model has been trained with an extra special token between two documents due to the Hugging Face tokenizer introducing a separator token and our dataloader also appending its own document separator. We modified the dataloader to eliminate the extra special token, and continued training with the modified dataloader from 1.7T token onwards.
1.7T-2T: The loss initially spiked due to the change in the special tokens which was quickly recovered in a few billion tokens. The training finished without any other manual intervention!
Key takeaways and even more speed
We demonstrated how one can use FSDP to train a model to 2T tokens with an excellent performance of 3700 tokens/sec/GPU and that generates a good quality model. As part of this exercise, we open sourced all our code for training and the knobs to achieve this throughput. These knobs can be leveraged by not only large-scale runs, but also smaller scale tuning runs. You can find the code here.
FSDP APIs implement the ZeRO algorithms in a PyTorch native manner and allow for tuning and training of large models. In the past, we have seen FSDP proof points (Stanford Alpaca, Hugging Face, Llama 2 recipes) on tuning a variety of LLMs (such as Meta Llama 2 7B to 70B Llama) using simple training loops and achieving good throughputs and training times.
Finally, we note that there are several levers for speeding up training:
- Node optimizations that can speedup specific operations (e.g., attention computation using Flash Attention V2)
- Graph optimizations (e.g., fusing kernels, torch.compile)
- Overlap in compute-communications
- Activation recomputation
We have leveraged 1, 3, and a variation of 4 in this blog and are working closely with Team PyTorch at Meta to get torch.compile (2) as well as a more advanced version of 4 with per-operator selective activation recomputation. We plan to share a simple formatting code and example data to ingest into our data loader to enable others to use the code base for training of models.
Acknowledgements
There are several teams that have been involved in reaching this proof point and we would like to thank the teams across Meta and IBM. Specifically, we extend our gratitude to the PyTorch distributed team, Facebook Research and Applied AI teams that built the FSDP APIs and made enhancements based on our feedback. We also wish to thank the data team at IBM Research that curated the data corpus used in this exercise and the infrastructure team at IBM Research (especially, Claudia Misale, Shweta Salaria, and Seetharami Seelam) that optimized NCCL and network configurations. By building and leveraging all of these components, we have successfully demonstrated the LlamaT proof point.
The selective activation checkpointing was conceptualized at IBM by Linsong Chu, Davis Wertheimer, Mudhakar Srivatsa, and Raghu Ganti and implemented by Less Wright at Meta.
Special thanks to Stas Bekman and Minjia Zhang, who provided extensive feedback and helped improve the blog. Their insights have been invaluable in highlighting key aspects of optimizing the training and exploring further enhancements.
Appendix
Communication computation overlap
Another key aspect of training in a multi-node setting is the ability to overlap communication and computation. In FSDP, there are multiple opportunities for overlapping – during the FSDP unit gathering phase at forward pass as well as the backward pass computation. Overlapping the gather during forward pass while the computation of the previous unit and overlapping backward computation with the next unit gathering and gradient scattering help improve GPU utilization by nearly 2x. We illustrate this on the 400Gbps network interconnect with A100 80GB GPUs. In the case of HSDP, there is no inter-node traffic during the pre-fetch stage for forward pass and the overlap is only for the backward gradient computation phase. Of course, HSDP is feasible only when the model can be sharded within a single node, limiting the size of models to around 30B parameters.
The below figure shows three steps in FSDP with the communication between nodes at the bottom and the compute stream at the top of the second half of the image. For the 7B model with no activation recomputation, we observe the overlap to be complete. In practice, the overlap percentage possible is 90% since the first block during forward pass and the last block during backward pass are not able to overlap.

A zoomed in view of the above three-step process is shown below for a single step. We can clearly see the granularity of the computation and communication and how they overlap in an interleaved manner.
