How It Started: Hitting the GIL Wall at Scale
We’ve been running production model serving for many years. When we first started building Shepherd Model Gateway, the goal was modest: figure out if cache-aware load balancing could improve routing across inference replicas.
It could. And as we went deeper, we found a much bigger problem.
In both SGLang and vLLM, tokenization and detokenization had become bottlenecks. Not in theory — in production, under real traffic. The root cause was architectural: although both engines use Rust or C++ tokenizer libraries underneath, the calls go through Python. That means the GIL. That means a single-threaded ceiling on CPU-bound work that sits directly in the serving path.
At a small scale, this doesn’t matter. At large-scale prefill-decode disaggregated serving, and at large-scale expert parallelism across GPU clusters, it matters enormously. These configurations make GPUs extremely fast — fast enough that the CPU side of the pipeline becomes the constraint. Every microsecond of GIL-bound tokenization is a microsecond where GPUs worth hundreds of thousands of dollars sit idle, waiting for input.
That’s where the journey really started. Not with a gateway vision — with a production problem. Could we disaggregate the entire CPU workload from the GPU path and run it in Rust? Not Python-calling-Rust. Pure Rust. No GIL. No single-threaded ceiling. No Python process boundaries.
The answer was yes, and the project that proved it became Shepherd Model Gateway.

SMG Architecture: Clients → Gateway → Router → Workers
SMG’s architecture is built on one principle: GPUs should do tensor math. Everything else belongs in a dedicated serving layer.
We looked at the model-serving stack and identified every CPU-bound workload entangled with GPU inference: tokenization, detokenization, reasoning output parsing, function call extraction, MCP tool orchestration, multimodal preprocessing, chat history management, structured output validation, stop sequence detection. Each one is a CPU task that, when co-located with the GPU process behind the Python GIL, creates back-pressure on the most expensive hardware in the rack.
SMG moves all of these into a Rust gateway layer that communicates with inference engines over gRPC. The protocol is minimal and GPU-focused: send preprocessed tokens in, stream generated tokens out. Everything else is the gateway’s responsibility.
This isn’t the approach most projects in the distributed inference space have taken. Excellent work is happening with projects like NVIDIA Dynamo and llm-d, which focus on optimizing the inference engine layer and the orchestration around it. We see that work as complementary. But SMG’s bet is different: rather than making the engine smarter, make the gateway smarter. Offload everything that doesn’t require a GPU onto a purpose-built Rust layer that scales independently, evolves independently, and runs with zero GIL contention.
The gRPC Re-Architecture: Making It Real
 The gRPC Pipeline: Gateway-side processing before engine handoff
The gRPC Pipeline: Gateway-side processing before engine handoff
The single largest technical investment in SMG’s history was rebuilding the entire serving pipeline around a native Rust gRPC data plane. This was the architectural proof of the disaggregation thesis.
Tokenization and detokenization move into the gateway. SMG runs tokenizers natively in Rust with a two-level cache — L0 exact-match for repeated prompts, L1 prefix-aware at special-token boundaries. The inference engine receives pre-tokenized input and never touches a tokenizer. No Python. No GIL.
Reasoning and tool call parsing runs in the gateway’s streaming pipeline. As tokens arrive over gRPC, SMG’s parsers — including Cohere Command, DeepSeek, Llama, Nemotron, Kimi-K2, GLM-4, and Qwen Coder — extract reasoning blocks, function calls, and structured output in real-time. No post-processing step on the engine side.
Multimodal processing was the most ambitious piece. We rewrote major components of Hugging Face’s transformers image processor from Python to Rust — reimplementing vision preprocessing pipelines, tensor operations, and model-specific transformations in a completely different language and runtime. The result: SMG communicates preprocessed tensors directly to engines via gRPC with zero Python overhead. Support for Llama 4 Vision, Qwen VL, and all major vision-language models, with backend-specific optimizations for SGLang, vLLM, and TensorRT-LLM. This is, to our knowledge, an industry first.
MCP tool orchestration runs entirely in the gateway with auth-aware connection pooling, concurrent batch execution, approval workflows, automatic reconnection, and HTTP header forwarding. The inference engine has no knowledge of MCP. We also built a complete built-in tool routing infrastructure — turning any MCP server into native capabilities (FileSearch, WebSearch, CodeInterpreter) for any model. Deploy Llama or Qwen with the same built-in tools as GPT-4.
Chat history management with pluggable storage (PostgreSQL, OracleDB, Redis and in-memory), schema versioning via Flyway, customizable table/column names, and storage hooks for pre/post persistence callbacks. All in the gateway, keeping the engine stateless.
WASM middleware provides programmable extensibility without forking the codebase. Custom authentication, compliance logging, PII redaction, cost tracking, compression — all via WebAssembly plugins with sandboxed isolation. Another industry first.
The gRPC protocol itself — published as smg-grpc-proto on PyPI — defines the narrow contract between gateway and engine. This design means you can upgrade your gateway (new parsers, new protocols, new tools) without touching your inference engine, and upgrade your engine (new GPU kernels, new quantization) without touching your gateway. They evolve independently because the interface is clean.
What SMG Delivers Today
SMG was created by Simo Lin and Chang Su, members of the LightSeek Foundation. In roughly six months, we shipped thirteen releases. Rather than walk through each one, here is what the project delivers today — and the evidence behind each capability.
Multi-Model Inference Gateway
A single SMG process fronts your entire fleet — multiple models, multiple engines, one entry point. Route requests across SGLang, vLLM, TensorRT-LLM, and MLX backends simultaneously. Add OpenAI, Anthropic, Google Gemini, AWS Bedrock, and Azure OpenAI as external providers. One gateway, every engine, every vendor.
Five Native Agentic APIs
SMG natively supports Chat Completions (OpenAI), Responses API (OpenAI), Messages API (Anthropic), Interactions API (Gemini), and Realtime API (WebSocket/WebRTC). These are not translation layers — each is a first-class implementation. The Messages API preserves thinking blocks end-to-end with ThinkingConfig, thinking_delta streaming events, and interleaved reasoning + text + tool use content blocks. The Responses API brings OpenAI’s conversation management to Llama, DeepSeek, Qwen, and every open-source model — SMG remains the only open-source gateway supporting it. Run agentic workflows designed for Claude on Llama 4, Qwen 3, DeepSeek, or Kimi with full protocol fidelity.
Native Rust gRPC Data Plane
 Two-Level Tokenizer Cache: L0 exact-match, L1 prefix-aware
Two-Level Tokenizer Cache: L0 exact-match, L1 prefix-aware
The architectural core: a native Rust gRPC pipeline between gateway and engine. The contract is minimal — preprocessed tokens in, generated tokens out. Everything else is the gateway’s responsibility. Tokenization runs in Rust with a two-level cache (L0 exact-match, L1 prefix-aware). Reasoning and tool call parsing runs in the streaming pipeline as tokens arrive — supporting fifteen model families including DeepSeek-R1, Qwen3, GLM-4, Kimi, Llama-4, Cohere Command, and more. No Python. No GIL. The gRPC protocol is published as smg-grpc-proto on PyPI, and both vLLM (PR #36169) and NVIDIA TensorRT-LLM (five merged PRs) have adopted it upstream.
Intelligent Routing

Cache-Aware Routing Flow
Eight load-balancing policies: cache-aware, round robin, random, power-of-two, consistent hashing, prefix hash, manual (sticky sessions), and bucket-based. Cache-aware routing was rewritten from the ground up — 10–12x faster (216,000 insertions/sec), 99% memory reduction (180 KB → 1.4 KB per node, 10,000 cached prefixes: 1.8 GB → 14 MB). Event-driven KV cache routing streams real-time cache state from all backends via SubscribeKvEvents RPC, with auto-learned block sizes. Production results on 8 Llama replicas: TTFT average down 23%, TTFT p99 down 28%. Prefill-decode disaggregation routes prefill and decode phases to separate worker pools with independent policies — 20–30% TTFT improvement in PD setups.
Multimodal Processing in Rust
We rewrote major components of Hugging Face’s image processors from Python to Rust — vision preprocessing pipelines, tensor operations, and model-specific transformations in a completely different language and runtime. Eight vision model families supported: Kimi K2.5, Llama-4 Vision, LLaVA, Phi-3/Phi-4 Vision, Pixtral, Qwen-VL, Qwen2-VL, and Qwen3-VL. Preprocessed tensors flow directly to engines via gRPC with zero Python overhead. To our knowledge, an industry first.
MCP Tool Orchestration & Built-in Tools

MCP Architecture: Tool orchestration in the gateway
MCP runs entirely in the gateway with auth-aware connection pooling, concurrent batch execution, approval workflows, automatic reconnection, and four transports (STDIO, HTTP, SSE, Streamable). Universal MCP Built-in Tools turn any MCP server into native capabilities — FileSearch, WebSearch, CodeInterpreter — for any model. Deploy Llama or Qwen with the same built-in tools as GPT-4. Per-tenant isolation, policy-based trust levels, and execution metrics come standard.
WASM Middleware

WASM Plugin Pipeline
Programmable extensibility via WebAssembly plugins with sandboxed isolation — another industry first. Custom authentication, compliance logging, PII redaction, cost tracking, compression — all without forking the codebase. Built on Wasmtime with Component Model and async support. Storage hooks intercept chat history operations for custom pre/post processing.
Enterprise Security & Observability

TLS/mTLS Architecture
JWT/OIDC authentication with JWKS discovery, role-based access control, API key auth, and multi-tenant rate limiting. TLS and mTLS for both client-facing and inter-node communication. A six-layer metrics system with 40+ Prometheus metrics covering HTTP, router, worker, inference, discovery, MCP, database, and mesh layers. Full OpenTelemetry distributed tracing. Structured JSON logging with request correlation.
Reliability & High Availability
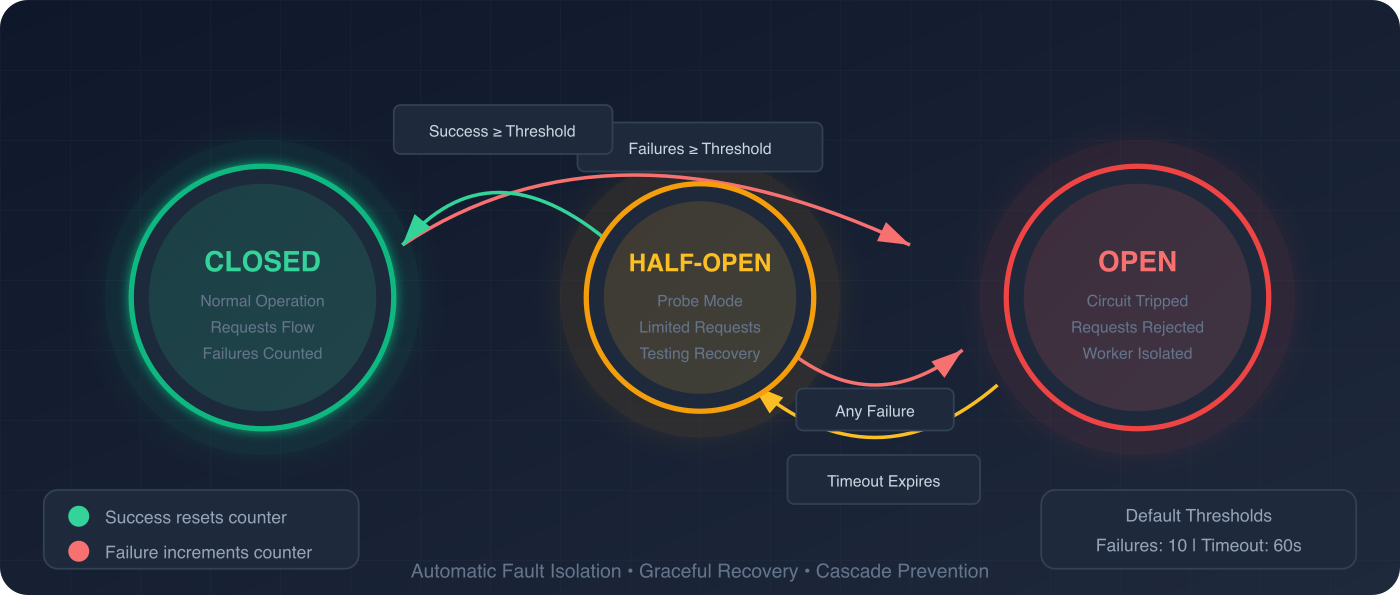
Circuit Breaker State Machine
Per-worker circuit breakers (closed/open/half-open), automatic retries with exponential backoff and jitter, periodic health checks, concurrent request rate limiting, request timeouts, and configurable graceful shutdown. SWIM-protocol gossip mesh with CRDT-based state sync for multi-node deployments. Distributed rate limiting via consistent hashing across cluster nodes. Partition-tolerant by design.
Data Persistence & Service Discovery

Service Discovery: Kubernetes, DNS, Manual
Chat history management with pluggable storage — PostgreSQL, OracleDB, Redis, or in-memory — with schema versioning and customizable table/column names. Kubernetes label-based pod discovery, DNS discovery, or manual worker URLs. Model ID sourced from pod namespace, labels, or annotations. Bootstrap port annotation for automatic prefill port discovery in PD setups.
Universal Platform Support
Linux, Windows, macOS, x86, ARM — from a single Python wheel (pip install smg). Python 3.8–3.14. Production-ready client SDKs in Python, Rust, Java, and Go. Engine-specific Docker images. Full modularization into standalone crates: smg-auth, smg-mesh, smg-mcp, smg-wasm, smg-grpc-client, smg-kv-index, llm-tokenizer, llm-multimodal, openai-protocol, and more.
Proving the Thesis: gRPC Gateway Benchmarks
The disaggregation thesis predicts that moving CPU workloads off the GPU path should show measurable benefits — especially under production conditions. We tested this systematically.
Methodology
All benchmarks run on NVIDIA H100 GPUs using NVIDIA GenAI-Perf (genai-perf) via the SMG nightly benchmark suite on GitHub Actions. 8 models (GPT-OSS-20B, Llama-3.1-8B, Llama-3.3-70B, Llama-3.3-70B-FP8, Llama-4-Maverick, Llama-4-Scout, Qwen2.5-7B, Qwen3-30B-MoE), 2 runtimes (SGLang, vLLM), 5 traffic scenarios, 9 concurrency levels (1–256). Total: 1,082 matched gRPC vs HTTP comparison points.
The Scaling Story: Advantage Grows with Concurrency
At concurrency 1, gRPC and HTTP perform within noise. At concurrency 256, gRPC delivers ~8% more throughput. The gateway’s binary serialization and HTTP/2 multiplexing compound under load — exactly when it matters.
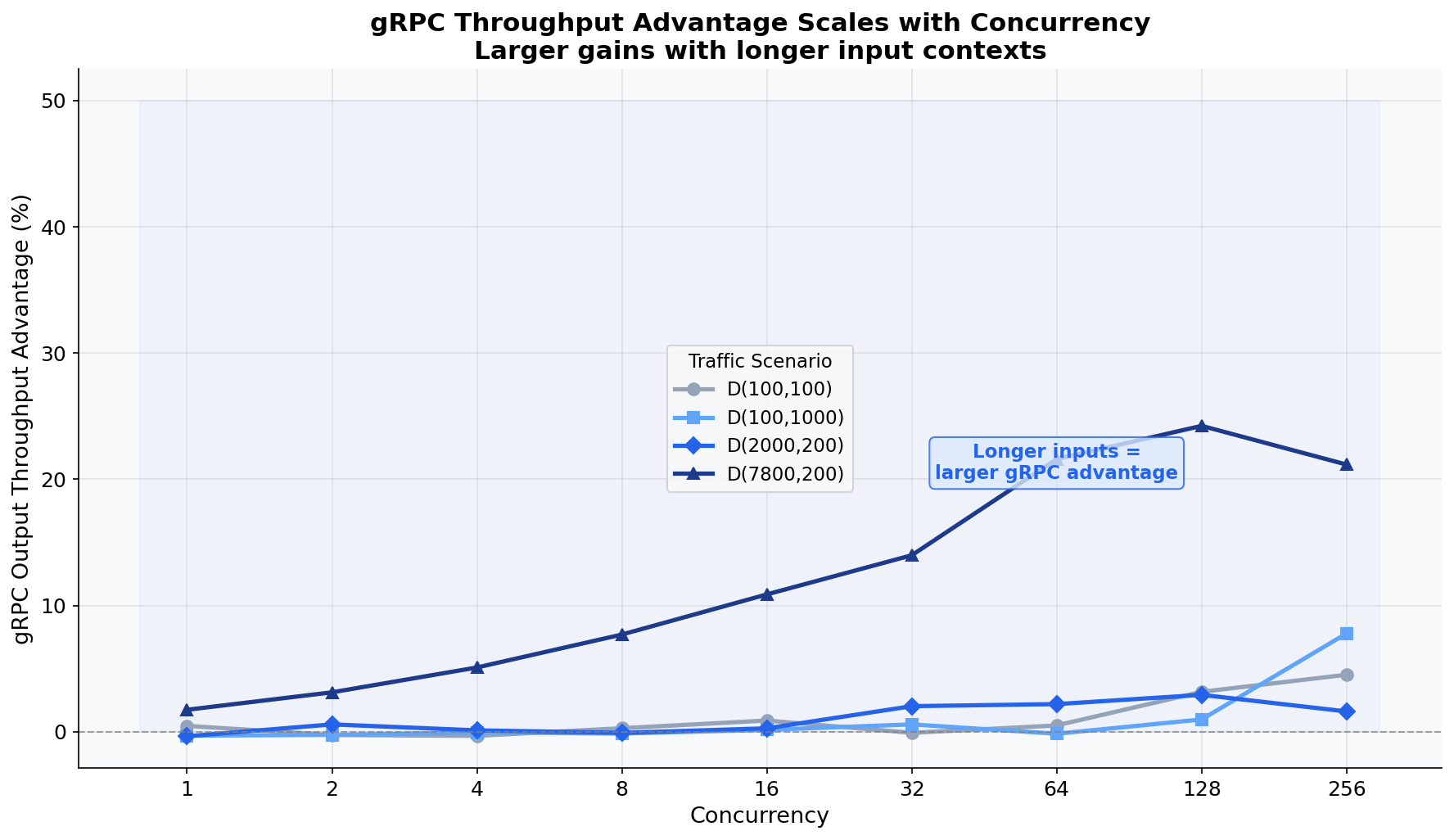
Long Contexts: Where gRPC Transforms Performance
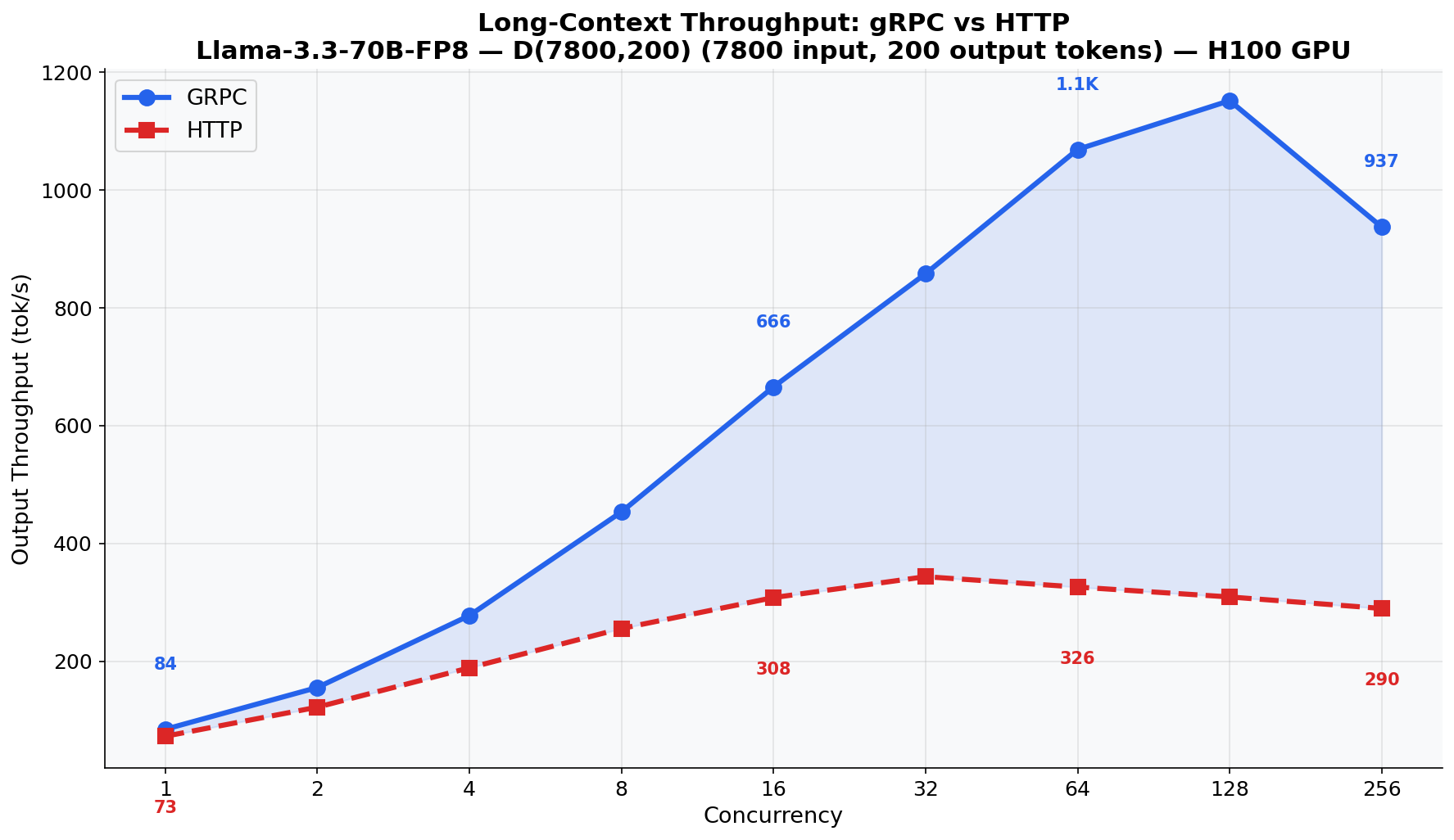
HTTP/JSON serialization cost grows linearly with prompt length. gRPC/protobuf uses compact binary encoding that doesn’t pay this tax. At 7800 input tokens, the serialization cost is substantial. The D(7800,200) scenario shows +12.2% throughput advantage across all models.
The most dramatic result: Llama-3.3-70B-FP8 with 7800-token inputs. This model, running FP8 quantization on H100, is fast enough that HTTP serialization becomes the dominant bottleneck. gRPC delivers up to 3.5x higher output throughput: 1,150 tok/s vs 327 tok/s.
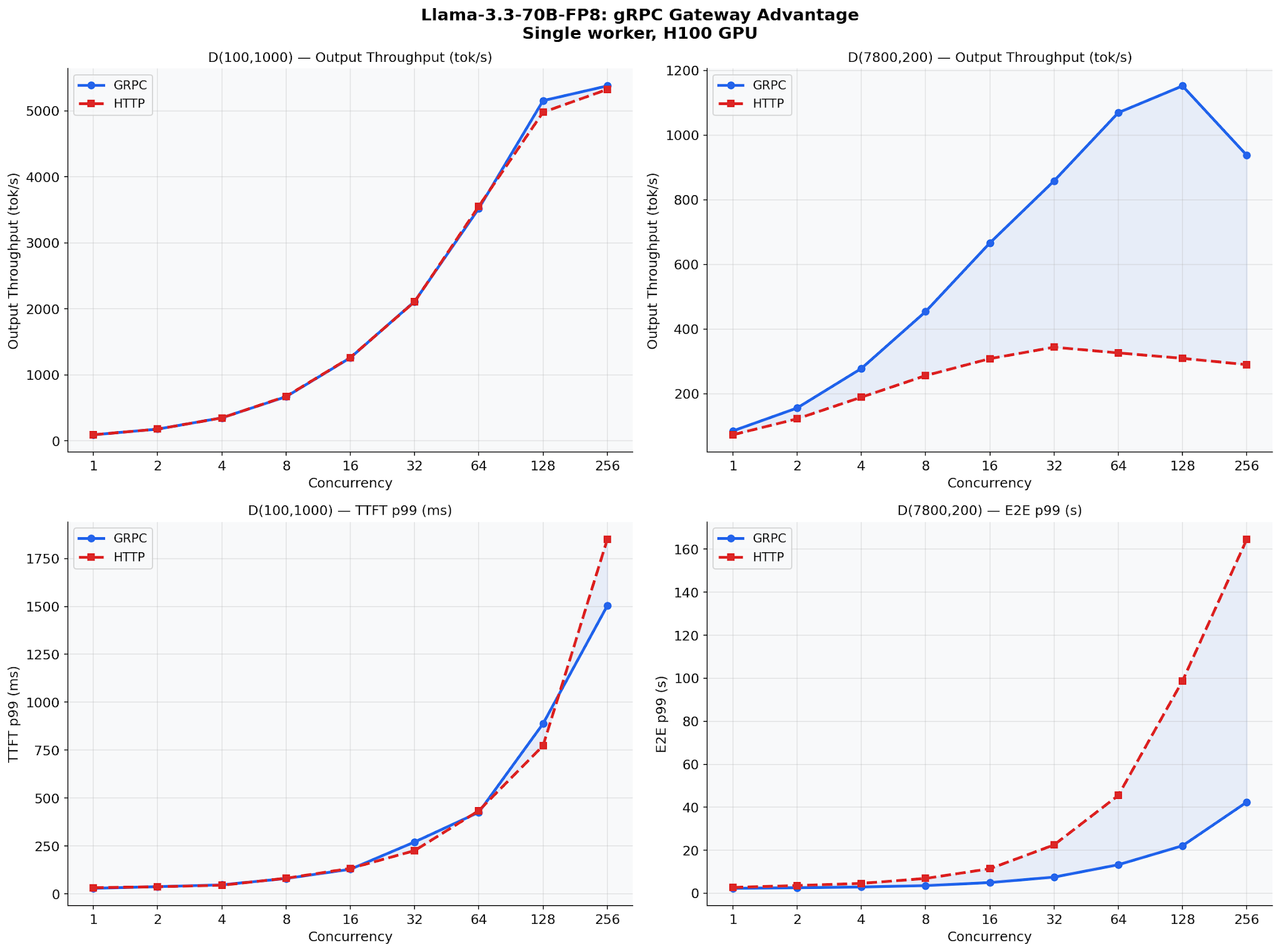
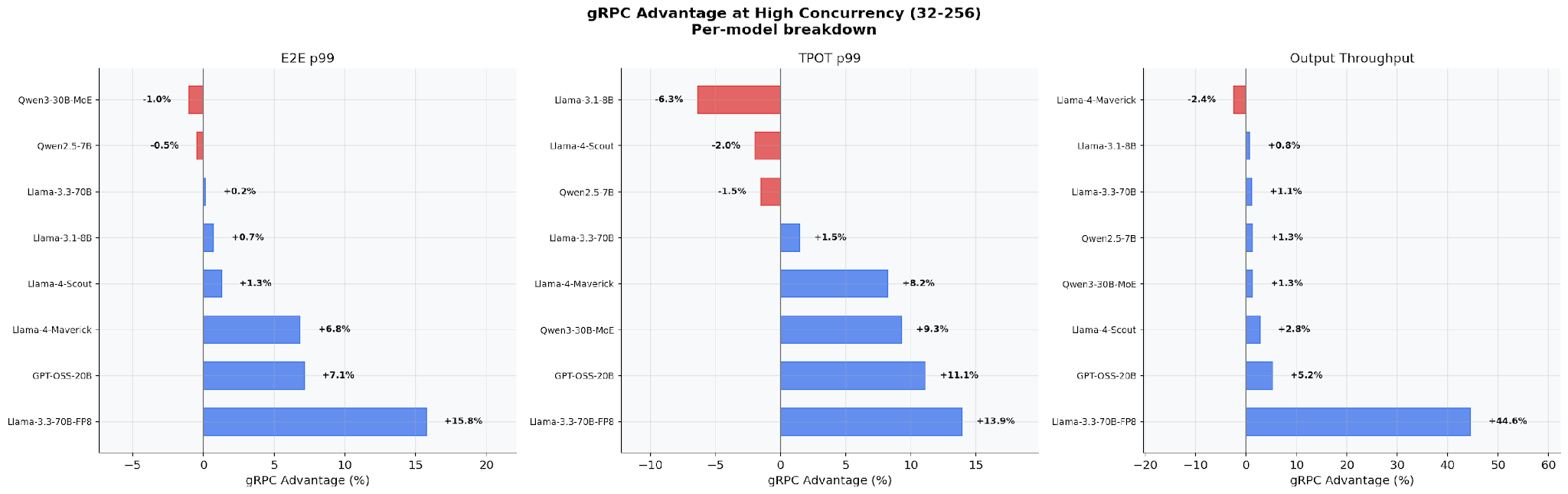
Per-Model Breakdown at High Concurrency
At production concurrency levels (32–256), the gRPC advantage varies by model architecture. Llama-3.3-70B-FP8 sees the largest gains (+15.8% E2E p99, +44.6% output throughput). Smaller dense models (Llama-3.1-8B, Qwen2.5-7B) show modest improvements. The pattern is clear: faster GPUs → larger gRPC advantage, because CPU overhead becomes a bigger fraction of total latency.
The Landscape
We’re not the only team working on LLM infrastructure.
NVIDIA Dynamo brings deep hardware integration and optimized inference orchestration. llm-d tackles distributed inference scheduling with a Kubernetes-native approach. Both are doing important work at the engine and cluster layer.
SMG operates at a different boundary: the serving and protocol layer. We own everything between the client and the GPU — tokenization, agentic protocol translation, tool orchestration, cache-aware routing, multimodal preprocessing, reliability. One layer, zero external dependencies, pure Rust.
The key insight: these approaches compose. You can run SMG in front of vLLM managed by llm-d, or in front of TensorRT-LLM with Dynamo handling GPU orchestration. The boundaries are clean because the responsibilities are different.
Production Adoption
SMG powers production deployments at:
- Google Cloud Platform — multi-tenant AI infrastructure
- Oracle Cloud Infrastructure — enterprise GenAI services
- Alibaba Cloud — cloud-native AI workloads
- TogetherAI — distributed inference infrastructure
From startups to hyperscalers.
What’s Next
- Batch API scheduling — two-tier architecture with Job Scheduler and Capacity Governor for offline workloads.
- Semantic routing — lightweight classification-based dispatch to different backends based on content, not static rules.
- Mixture of Vendors (MoV) — route the same model across multiple providers for A/B testing, cost optimization, and quality comparison.
- MCP Semantic Search — efficient tool discovery across servers with hundreds of registered tools.
- Custom metrics load balancing — CEL expressions over arbitrary metrics with sub-millisecond routing overhead.
GitHub: github.com/lightseekorg/smg
Install: pip install smg –upgrade
Docs: lightseekorg.github.io/smg
Acknowledgement
SMG’s development has been shaped by close collaboration with engineering teams and open-source communities across the industry. We’re grateful for the contributions, feedback, and partnership of:
- Oracle Generative AI Service — Jun Qian, Jingqiao Zhang, Wei Gao, Keyang Ru, Xinyue Zhang, Yifeng Liu, Ziwen Zhao, Daisy Zhou, Khoa Tran.
- TogetherAI — Yineng Zhang, Wei Gong, Chandra Mourya, Connor Li.
- Thinking Machines Lab — Eric Zhang, Rajat Goel, Jeff Hanson.
We also thank the SGLang, vLLM, and TensorRT-LLM communities for upstream collaboration and protocol adoption, and the teams at radixArk and Inferact for their partnership and feedback.
Their production deployments, code contributions, and technical insights have shaped what SMG is today.