Support for Intel GPUs is now available in PyTorch® 2.5, providing improved functionality and performance for Intel GPUs which including Intel® Arc™ discrete graphics, Intel® Core™ Ultra processors with built-in Intel® Arc™ graphics and Intel® Data Center GPU Max Series. This integration brings Intel GPUs and the SYCL* software stack into the official PyTorch stack, ensuring a consistent user experience and enabling more extensive AI application scenarios, particularly in the AI PC domain.
Developers and customers building for and using Intel GPUs will have a better user experience by directly obtaining continuous software support from native PyTorch, unified software distribution, and consistent product release time.
Furthermore, Intel GPU support provides more choices to users. Now PyTorch provides a consistent GPU programming paradigm on both front ends and back ends. Developers can now run and deploy workloads on Intel GPUs with minimal coding efforts.
Overview of Intel GPU support
Intel GPU support in PyTorch provides eager mode and graph mode support in the PyTorch built-in front end. Eager mode now has an implementation of commonly used Aten operators with the SYCL programming language. Graph mode (torch.compile) now has an enabled Intel GPU back end to implement the optimization for Intel GPUs and to integrate Triton.
Essential components of Intel GPU support were added to PyTorch, including runtime, Aten operators, oneDNN, TorchInductor, Triton and Intel GPU tool chains integration. Meanwhile, quantization and distributed are being actively developed in preparation for the PyTorch 2.6 release.
Features
In addition to providing key features for Intel® Client GPUs and Intel® Data Center GPU Max Series for inference and training, PyTorch keeps the same user experience as other hardware the PyTorch supports. If you migrate code from CUDA*, you can run the existing application code on an Intel GPU with minimal code changes for the device name (from cuda to xpu). For example:
# CUDA Code
tensor = torch.tensor([1.0, 2.0]).to(“cuda”)
# Code for Intel GPU
tensor = torch.tensor([1.0, 2.0]).to(“xpu”)
PyTorch 2.5 features with an Intel GPU include:
- Inference and training workflows.
- Enhance both torch.compile and eager mode functionalities (more Ops), together with performance improvement, and fully run three Dynamo Hugging Face*, TIMM* and TorchBench* benchmarks for eager and compile modes.
- Data types such as FP32, BF16, FP16, and automatic mixed precision (AMP).
- Runs on Intel® Client GPUs and Intel® Data Center GPU Max Series.
- Supports Linux (Ubuntu, SUSE Linux and Red Hat Linux) and Windows 10/11.
Get Started
Get a tour of the environment setup, PIP wheels installation, and examples on Intel® Client GPUs and Intel® Data Center GPU Max Series from Getting Started Guide. Support for Intel GPUs can be experienced through PyTorch PIP wheels installation by nightly and preview binary releases.
- Try Intel® Client GPUs through Intel® Arc™ Graphics family (Codename DG2), Intel® Core™ Ultra processor family with Intel® Graphics (Codename Meteor Lake), and Intel® Core™ Ultra mobile processor family with Intel® Graphics (Codename Lunar Lake).
- Try Intel Data Center GPU Max Series through Intel® Tiber™ AI Cloud.
- To learn how to create a free Standard account, see Get Started. Then do the following:
- Sign in to the cloud console.
- From the Training section, open the PyTorch on Intel® GPUs notebook and click “Launch Jupyter Notebook.”
- Ensure that the PyTorch 2.5 kernel is selected for the notebook.
- To learn how to create a free Standard account, see Get Started. Then do the following:
Performance
The performance of Intel GPU on PyTorch was continuously optimized to achieve decent result on three Dynamo Hugging Face, TIMM and TorchBench benchmarks for eager and compile modes.
The latest performance data measured on top of PyTorch Dynamo Benchmarking Suite using Intel® Data Center GPU Max Series 1100 single card showcase the FP16/BF16 significant speedup ratio over FP32 on eager mode in Figure 1, and Torch.compile mode speedup ratio over eager mode in Figure 2. Both inference and training reached the similar significant improvements.
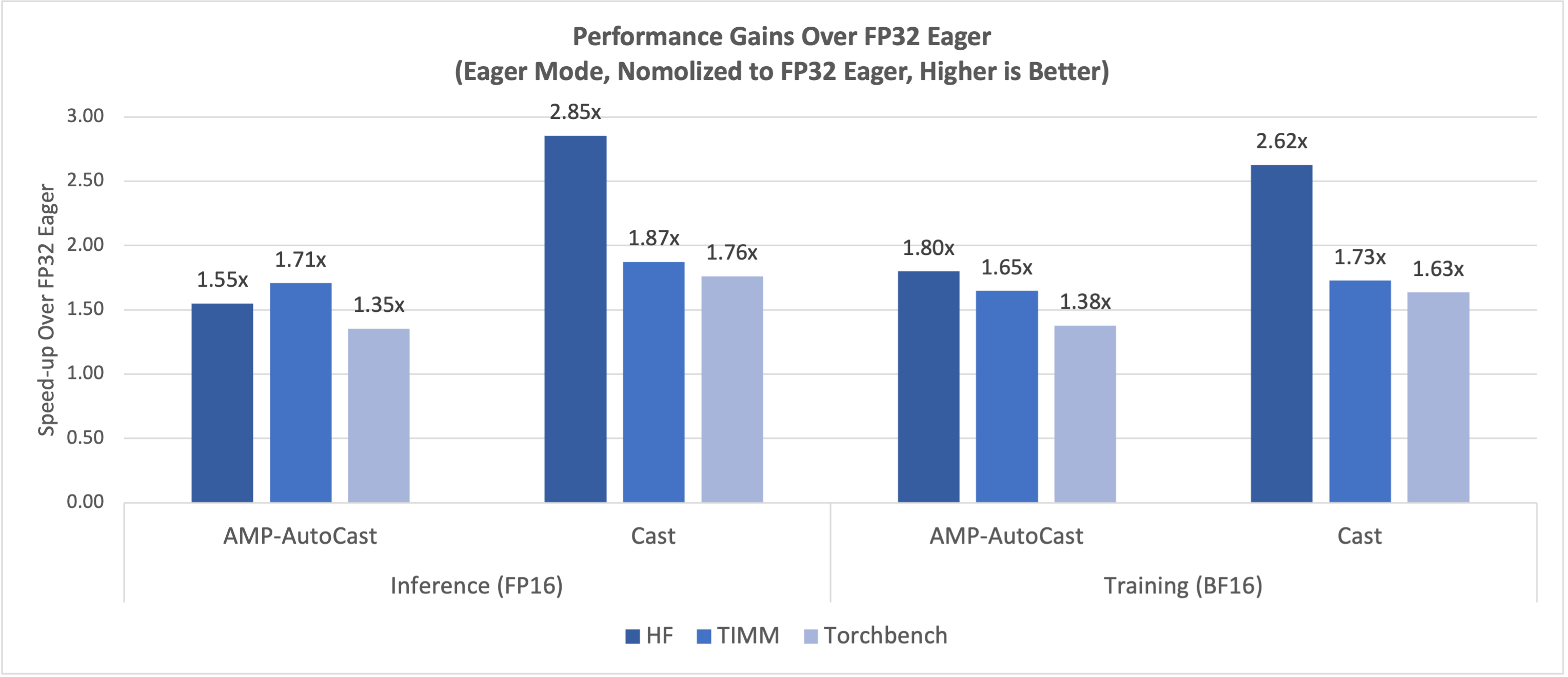
Figure 2: FP16/BF16 Performance Gains Over FP32 Eager
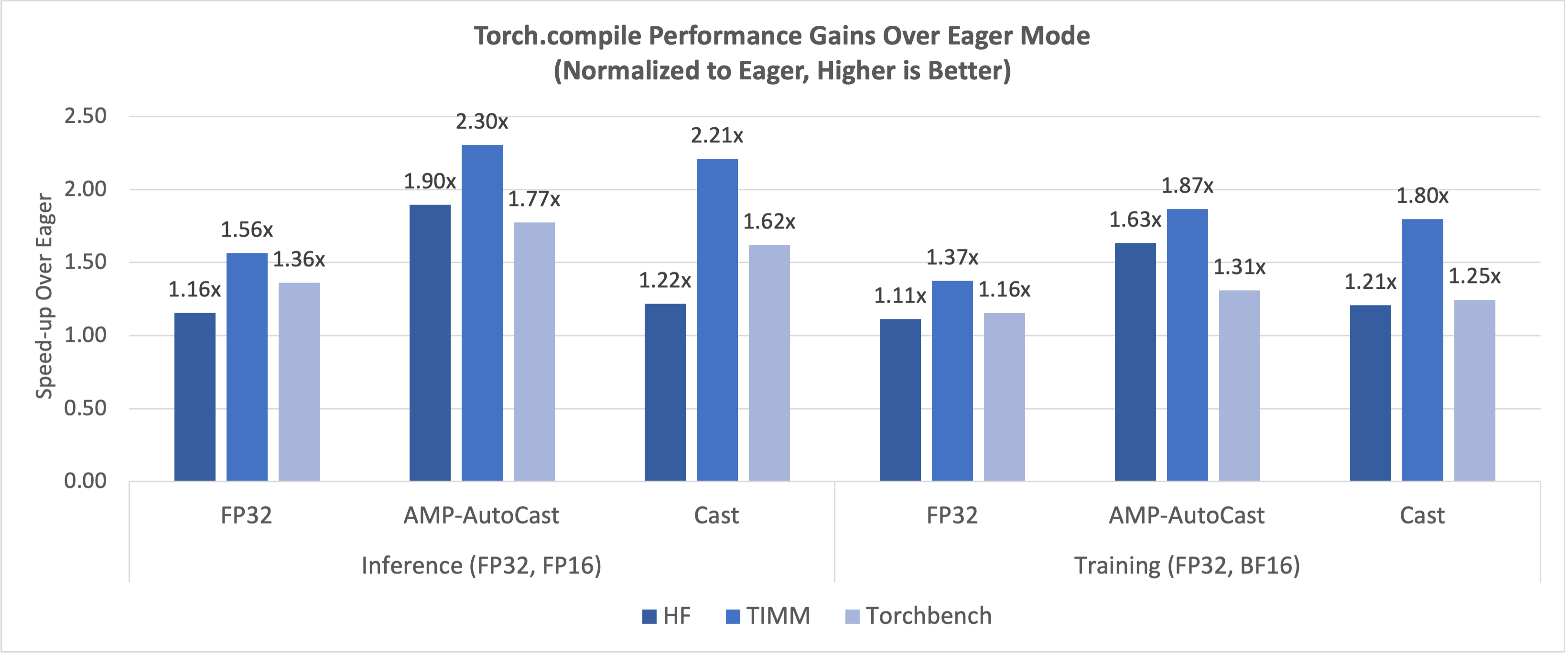
Figure 3: Torch.compile Performance Gains Over Eager Mode
Summary
Intel GPU on PyTorch 2.5 brings Intel® Client GPUs (Intel® Core™ Ultra processors with built-in Intel® Arc™ graphics and Intel® Arc™ Graphics for dGPU parts) and Intel® Data Center GPU Max Series into the PyTorch ecosystem for AI workload acceleration. Especially, Client GPUs is added to the GPU-supported list for AI PC use scenarios on Windows and Linux environment.
We warmly welcome the community to evaluate and provide feedback on these enhancements to Intel GPU support on PyTorch.
Resources
Acknowledgments
We want thank PyTorch open source community for their technical discussions and insights: Andrey Talman, Alban Desmaison, Nikita Shulga, Eli Uriegas, Jason Ansel, and Bin Bao.
We also thank collaborators from PyTorch for their professional support and guidance.
Performance Configuration
The configurations in the table are collected with svr-info. Test by Intel on September 12, 2024.
Table 1
| Component | Details |
|---|---|
| Name | Intel® Max Series GPU 1100 in Intel® Tiber™ Developer Cloud |
| Time | Thu Sep 12 08:21:27 UTC 2024 |
| System | Supermicro SYS-521GE-TNRT |
| Baseboard | Supermicro X13DEG-OA |
| Chassis | Supermicro Other |
| CPU Model | Intel(R) Xeon(R) Platinum 8468V |
| Microarchitecture | SPR_XCC |
| Sockets | 2 |
| Cores per Socket | 48 |
| Hyperthreading | Enabled |
| CPUs | 192 |
| Intel Turbo Boost | Enabled |
| Base Frequency | 2.4GHz |
| All-core Maximum Frequency | 2.4GHz |
| Maximum Frequency | 2.9GHz |
| NUMA Nodes | 2 |
| Prefetchers | L2 HW: Enabled, L2 Adj.: Enabled, DCU HW: Enabled, DCU IP: Enabled, AMP: Disabled, Homeless: Disabled, LLC: Disabled |
| PPINs | 5e3f862ef7ba9d50, 6c85812edfcc84b1 |
| Accelerators | DLB 2, DSA 2, IAA 2, QAT (on CPU) 2, QAT (on chipset) 0 |
| Installed Memory | 1024GB (16x64GB DDR5 4800 MT/s [4800 MT/s]) |
| Hugepagesize | 2048 kB |
| Transparent Huge Pages | madvise |
| Automatic NUMA Balancing | Enabled |
| NIC | 2 x Ethernet Controller X710 for 10GBASE-T, 4 x MT2892 Family [ConnectX-6 Dx] |
| Disk | 1 x 894.3G Micron_7450_MTFDKBG960TFR |
| BIOS | 1.4a |
| Microcode | 0x2b0004b1 |
| OS | Ubuntu 22.04.2 LTS |
| Kernel | 5.15.0-73-generic |
| TDP | 330W |
| Power & Perf Policy | Normal (6) |
| Frequency Governor | performance |
| Frequency Driver | acpi-cpufreq |
| Max C-State | 9 |
Table 2
| Component | Details |
|---|---|
| Single Card | Intel® Max Series GPU 1100 series on 4th Gen Intel® Xeon® processors of Intel Tiber Developer Cloud |
| Workload & version | Timm ac34701, TorchBench 03cde49, Torchvision d23a6e1, Torchaudio b3f6f51, Transformers 243e186 |
| Software Stack | intel-for-pytorch-gpu-dev 0.5.3, intel-pti-dev 0.9.0, Intel xpu backend for Triton cc981fe |
| Framework | Pytorch 4a3dabd67f8ce63f2fc45f278421cca3cc532cfe |
| GPU driver | agama-ci-devel-803.61 |
| GFX FW Version | PVC2_1.23374 |
Notices & Disclaimers
Performance varies by use, configuration and other factors. Learn more on the Performance Index site. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation.
Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
AI disclaimer:
AI features may require software purchase, subscription or enablement by a software or platform provider, or may have specific configuration or compatibility requirements. Details at www.intel.com/AIPC. Results may vary.