Introduction
Normalization methods (LayerNorm/RMSNorm) are foundational in deep learning and are used to normalize values of inputs to result in a smoother training process for deep learning models. We evaluate and improve torch.compile performance for LayerNorm/RMSNorm on NVIDIA H100 and B200 to reach near SOTA performance on a kernel-by-kernel basis, in addition with further speedups through automatic fusion capabilities.
Forwards
LayerNorm
LayerNorm was first introduced in this paper: https://arxiv.org/abs/1607.06450. It normalizes the inputs by taking the mean and variance, along with scaling by learnable parameters, gamma (weight) and Beta (bias).
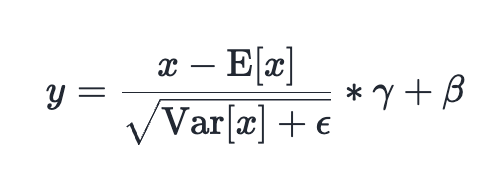
RMSNorm
RMSNorm (root mean square norm) was introduced as a follow up of LayerNorm in this paper: https://arxiv.org/abs/1910.07467. Instead of centering on the mean, the RMS is used to normalize, which is a sum of the squares of x values. We still use gamma (weight) as a learnable parameter for scaling, although there is no longer a bias term.

The forward pass for both LayerNorm and RMSNorm are relatively similar, typically with a reduction across the contiguous dimension and some extra pointwise ops, with RMSNorm typically being a bit more efficient as there are fewer flops and no bias. For the purposes of this study, we present benchmark results among LayerNorm and RMSNorm interchangeably given the similarity of the kernels.
Quack
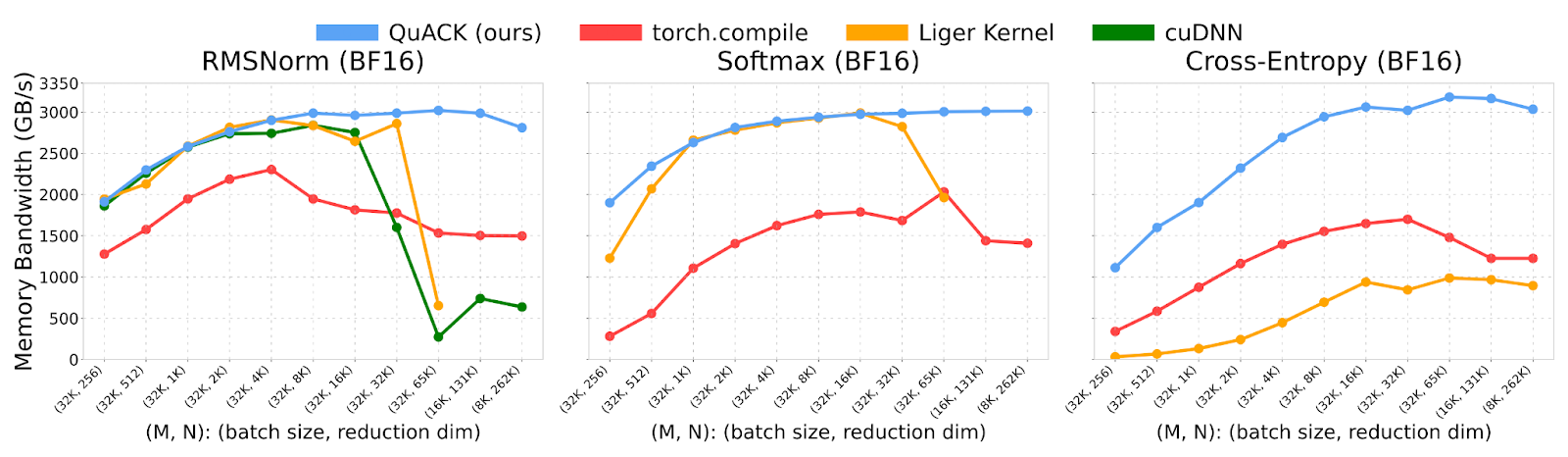
Quack is a library of hyper optimized CuteDSL kernels from Tri Dao: https://github.com/Dao-AILab/quack. Their current README shows on H100 how Quack outperforms torch.compile for these reduction kernels. We use Quack as the SOTA baseline of which we evaluate the performance of torch.compile on. Quack’s README showcases previous results from torch.compile performance below, of which it can be observed that torch.compile ~50% of Quack performance typically.
torch.compile
Below we illustrate the general logic of a torch.compile generated kernel for LayerNorm forwards, with the same approach for RMSNorm). We assume that the input reduction dimension (rnumel) is contiguous, which we refer to in Inductor as an Inner reduction.
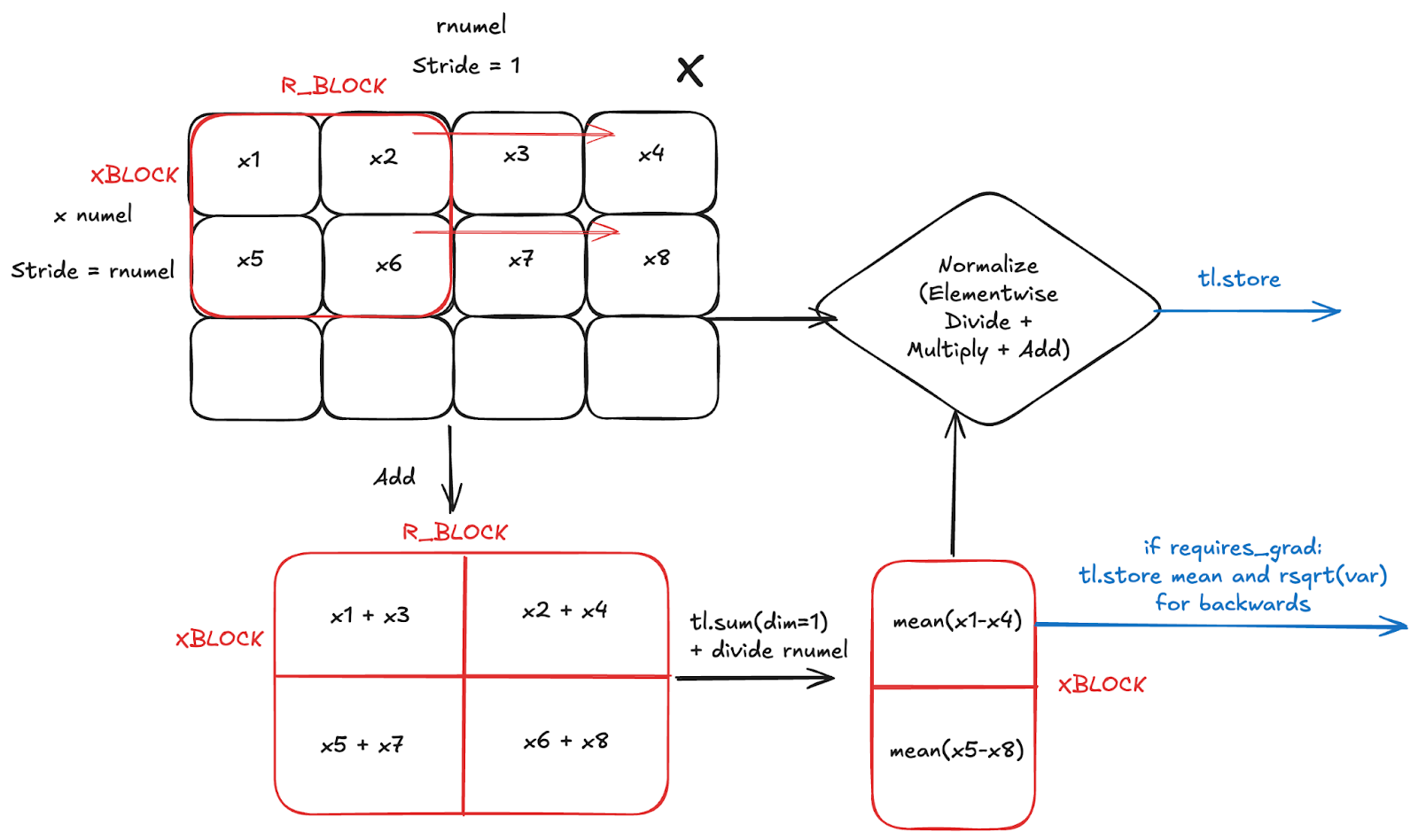
While the kernel might look a bit confusing, what’s actually happening is very simple:
- Maintain partial sums of size R_BLOCK for each row in X the input
- Use partial sums to calculate mean and variance
- Apply elementwise to X based on layernorm formula
- Store output of elementwise
- Store mean and variance if elementwise_affine=True and requires_grad=True for backwards
As a side note, if R is smaller than some heuristic (1024), then Inductor generates a persistent reduction, where we no longer need to loop over the r dimension. Instead, we go directly to taking the mean.
In comparing the torch.compile vs Quack versions of RMSNorm forwards, we can reproduce the poor performance of torch.compile compared to Quack on H100 and B200. However, after autotuning and using that to motivate Inductor defaults, we arrive at SOTA performance on H100 and B200. In general, the following was done to achieve this result:
- Inserting torch._dynamo.reset() during benchmarking – makes sure that torch.compile does not use automatic dynamic shapes, as previously a torch.compile call per shape was performed, making the compiler assume dynamic shapes
- Poor Autotune Configuration Decisions – By default was making suboptimal decisions for the autotune configs on H100 and B200, leading to poor performance, though this is mitigated with mode=’max-autotune’. Several improvements were made to the default heuristics:
- Scale up inner reduction RBLOCK
- Scale XBLOCK in persistent reductions for smaller reductions, numel <= 2048
- Decrease num_warps based on certain reduction dimensions. Num_warps would often be too large for peak vectorization. Peak vectorization is essential for maximizing bytes in flight -> saturating peak memory bandwidth for memory bound workloads, of which Blackwell is more sensitive to given the higher memory bandwidth.
Benchmark Results
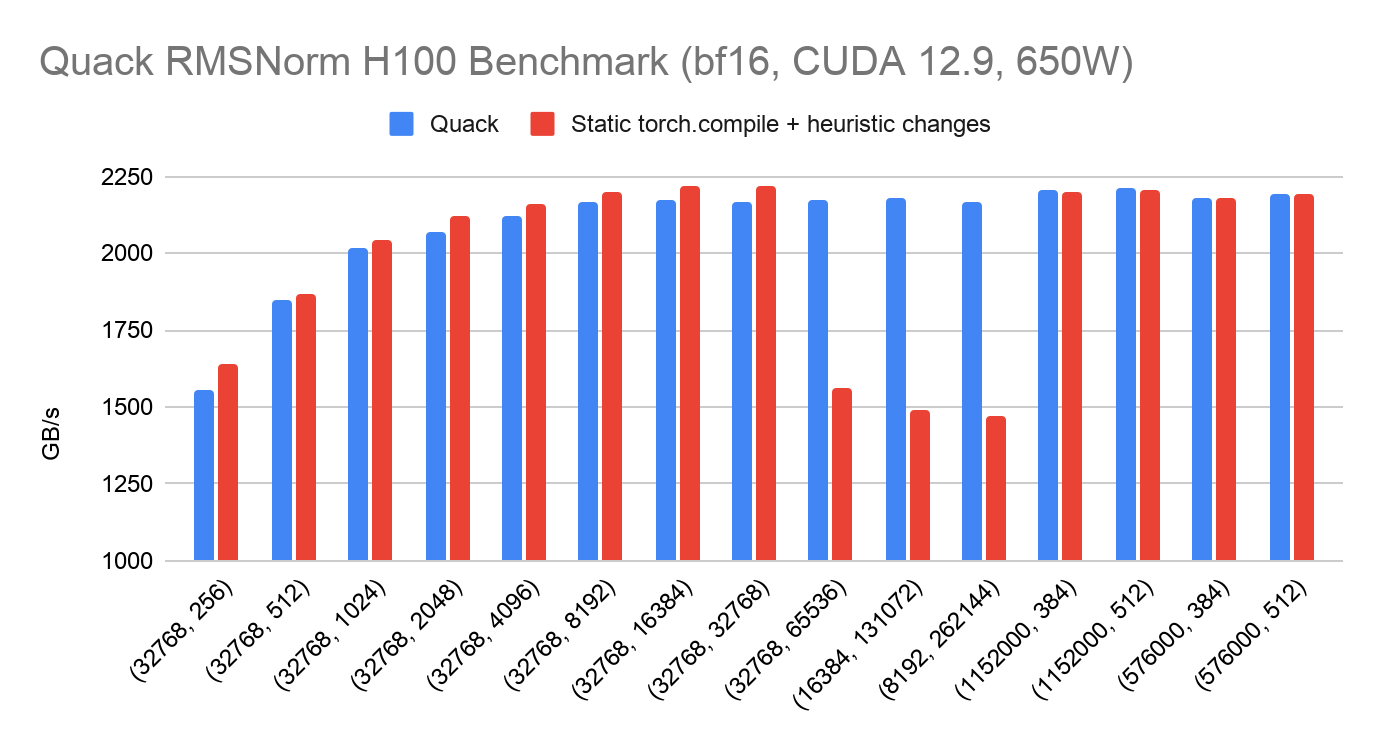
Below we present benchmark results of torch.compile 2.11 vs Quack (March 24th 2026 trunk) on the Quack benchmark shapes alongside some common shapes in the wild, with large M, small N. We demonstrate that torch.compile is generally on parity with Quack. There are two classes of regressions that do occur:
- Small regressions on N=384, as Triton is unable to cleanly represent non power-of-2 block size
- Large regressions on very large N for H100, due to the inability to represent distributed shared memory in Triton
Backwards
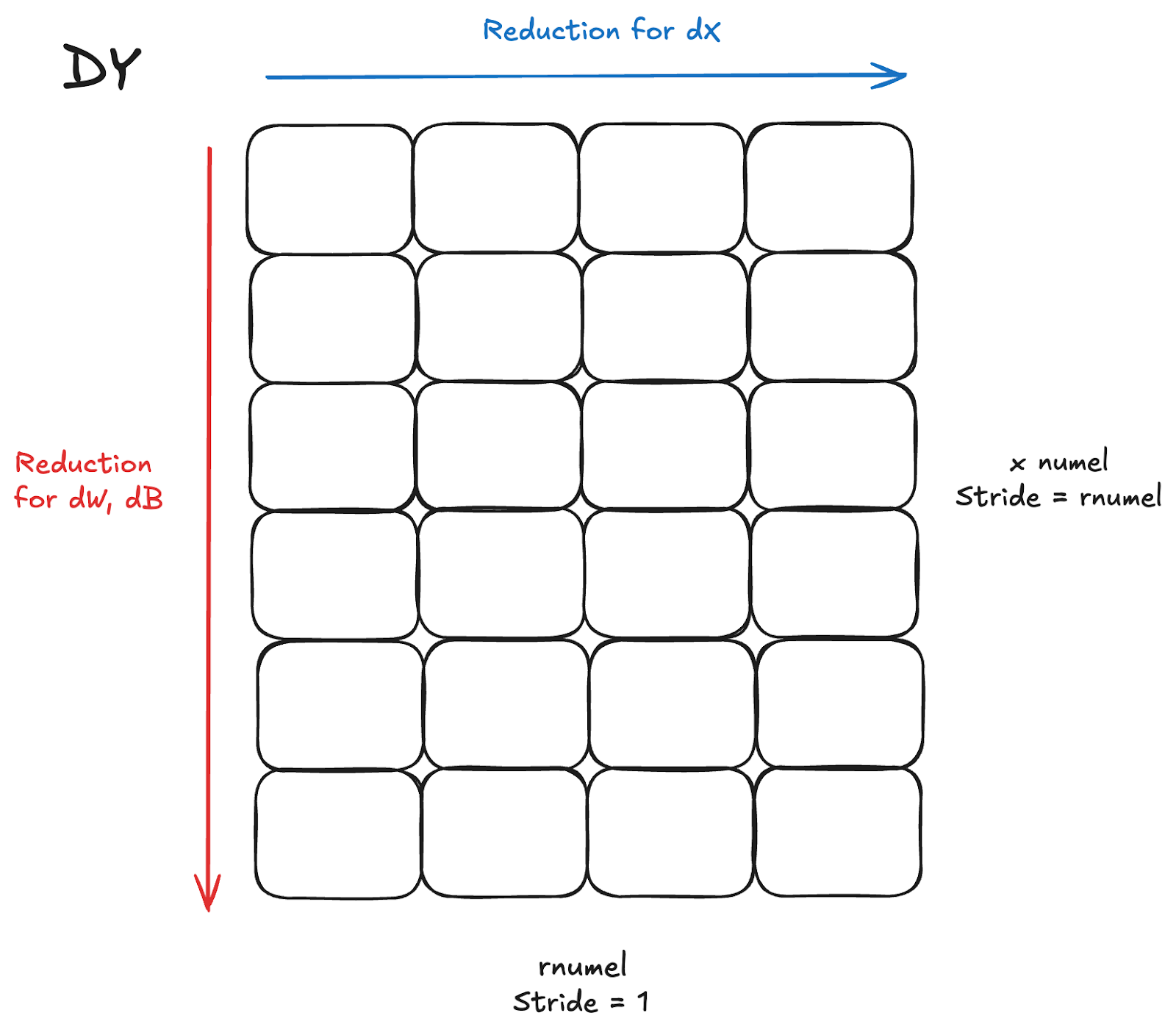
The backwards pass for LayerNorm/RMSNorm is a bit more involved than the forward pass. We have to calculate at least 2 gradients, dX for the input, dW for the weights, and optionally dB for the bias in LayerNorm. To simplify and avoid the associated complex math formulas, for performance considerations, these gradient calculations require reductions across both dimensions of dY, the incoming gradient to the backwards pass (the gradient of the previous output in the forwards).
The naive option here, and what is sometimes unavoidable with a very large reduction dimension, is to perform the reductions in separate kernels, one for dX, and one for dW, dB. However, that leads to reading the same inputs (dY) in 2 separate kernels, doubling the bytes being read. Given the memory bound nature of normalization kernels, leads to significant additional latency.
Fused Reductions
For reasonable shapes where numel is generally not too large and a single row can fit adequately in a thread block, generally <= 16384, it is possible to have a more performant fused kernel that doesn’t blow up shared memory/registers. Essentially, the kernel would perform the reduction for dW, dB as normal but for each row also reduce the columns for dX at the same time. Existing literature exists for this type of fusion, such as in Liger, a fused semi-persistent normalization backwards from Meta, and Quack’s fused kernel in CuteDSL.
In Inductor, we represent reductions with distinct types, such as:
- INNER reduction: reductions that reduce thru the stride=1 dimension
- OUTER reduction: reductions that reduce thru the remaining dimension
Based on these definitions, the fused kernel is an INNER and OUTER reduction on the same input tensor, with the INNER reduction as dX (contiguous) and the OUTER reduction as (dW, dB).
Split Reduction
Typically for many shapes in the wild, xnumel or the batch dimension is large, much larger than rnumel. In this case, it is generally preferred to process partial sums of the reduction across X and a final torch.sum of the partial sums to allow for better parallelism. The Triton tutorial layernorm illustrates the split reduction, though they utilize locks with atomics with a single thread-block being responsible for individual rows, which is poor for performance on a larger batch dimension (X) and leads to numerical inconsistencies:
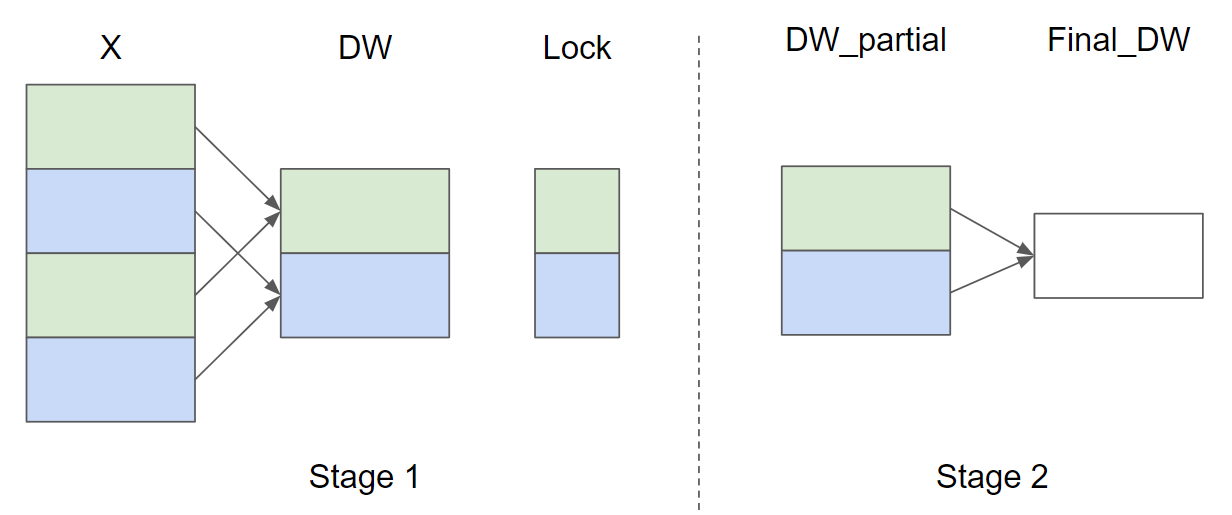
Inductor has similar capabilities currently with split reduction, which allocates a workspace tensor for the partial sums, like above, but does not use atomics, instead ensuring that a single CTA processes multiple rows and writes to one unique spot in the workspace tensor.
Inductor Generated Fused Norm Backwards
Combining the fused and split reduction paradigms described above, we enable TorchInductor to automatically generate fused state-of-the-art normalization backward kernels. Furthermore, allowing the compiler to generate such kernels allows for more autotuning and automatic fusion capabilities with surrounding operations. Since the main challenge here is to fuse reductions with the same input but different reduction order, we call this optimization MixOrderReduction.
For a given [M, N] shape input, the generated kernel performs:
- Split-reduction by splitting the M dimension with SPLIT_SIZE chunks
- for each chunk, we have one row in the workspace tensor saving the partial reduced results for the OUTER reduction (e.g. partial sum of each column or dW, dB)
- for each chunk, we want to load each row in the chunk by a loop
- do the INNER reduction as usual (e.g. sum the entire row or dX)
- Combine the loaded row with the row in the workspace tensor as the updated partial reduced result
We have an extra reduction to reduce the partial reduced results in the workspace tensor to get the final result for the OUTER reduction. The extra kernel works on much smaller input tensors so it’s not a huge performance hit to have it in a separate kernel.
In the Inductor codegen logic itself, we perform the following steps after recognizing the mix order reduction pattern:
- for the OUTER reduction kernel, we replace the reduction and store_reduction nodes with a new type of partial_accumulate node. This node tracks the value being reduced, what kind of reduction we do etc. This transformation converts the OUTER reduction kernel into a pointwise kernel (PW1)
- Reorder loops for the transformed pointwise kernel (PW1) leveraging the previous loop reordering work and we get (PW2)
- Now PW2 and the INNER reduction have the same loop order and we can fuse them
Autotuning for Split-Size
SPLIT_SIZE is very critical to the perf of mix-order reduction kernels. The default perf of the Liger RMSNorm backwards kernel on shape (1152000, 384) with dtype=bfloat16 achieves 0.417 TB/s on H100. When reducing the SPLIT_SIZE by 32x, we get 1.912 TB/s.
We demonstrate results across the shapes we benchmark and different split sizes on H100 for torch.bfloat16 dtype.
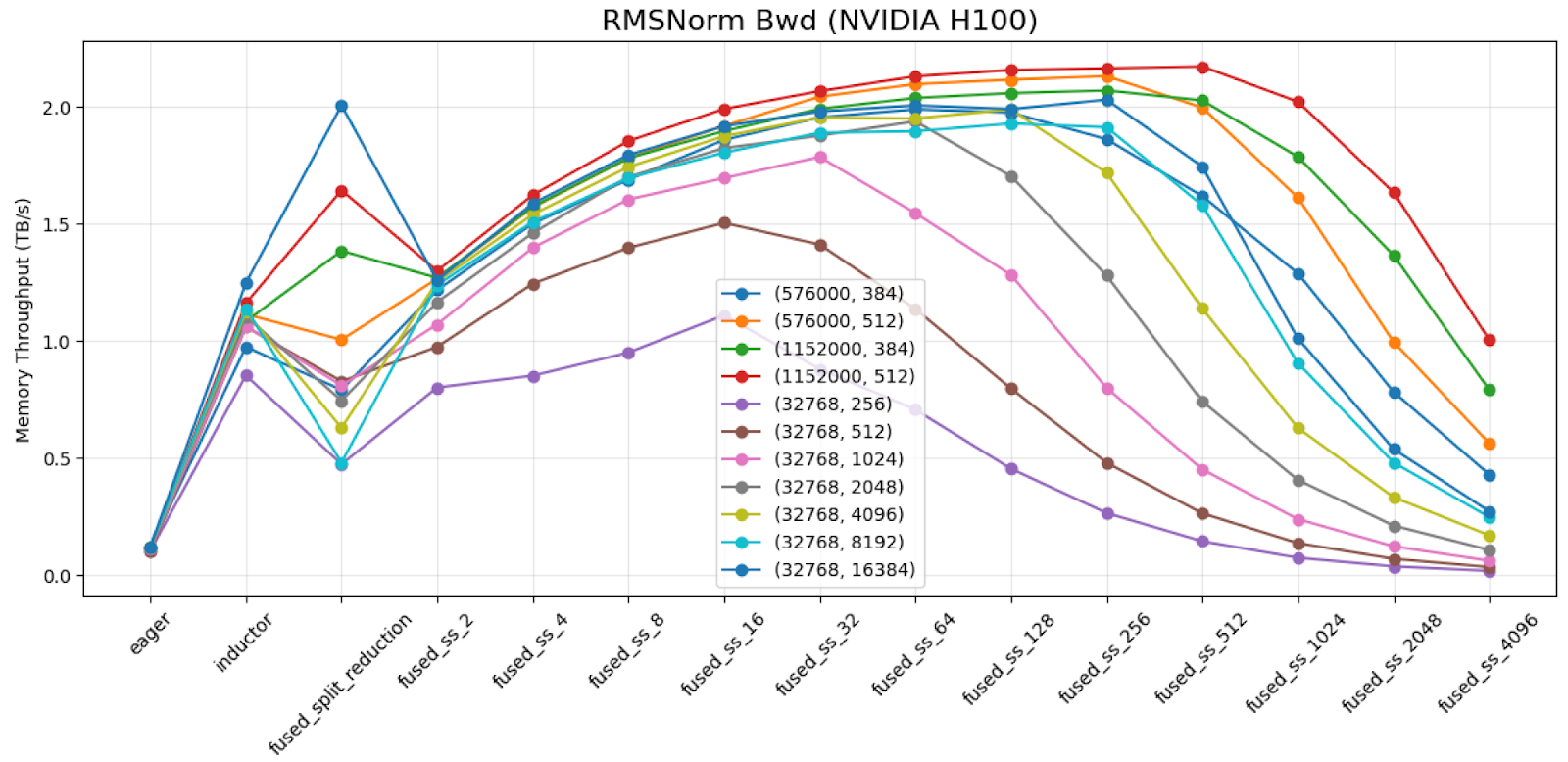
As shown above, we can conclude that:
- An improper split-size choice can cause > 2x perf degradation
- The curve is more or less a parabola shape. An autotuning strategy to keep expanding to 2x or 1/2 split size until we found a maximum should be a very effective strategy for this problem.
Inductor’s existing split-reduction feature may split the outer reduction for better perf. The split size picked by split-reduction (shown as ‘fused_split_reduction’ column in the chart) may be bad due to using an unrelated heuristics. We make MixOrderReduction ignore the split size picked for split-reduction and use its own heuristics or autotuning mechanism to pick a better split-size.
Software Pipelining
Another discovery while trying to achieve peak bandwidth on the backwards kernel is the addition of software pipelining, aka prefetching loads. Typically, only compute intensive workloads like GEMM and Attention performed pipelining as more memory bound workloads did not need it, with no num_stages autotuning in Inductor for pointwise/reduction kernels or the Liger examples. However, we observed that in the Quack kernels there was some notion of prefetching. We added num_stages as an autotuning parameter for Inductor kernels generally, and saw significant speedups for some shapes, especially for large M, small N, up to 20% when applied to MixOrderReduction:
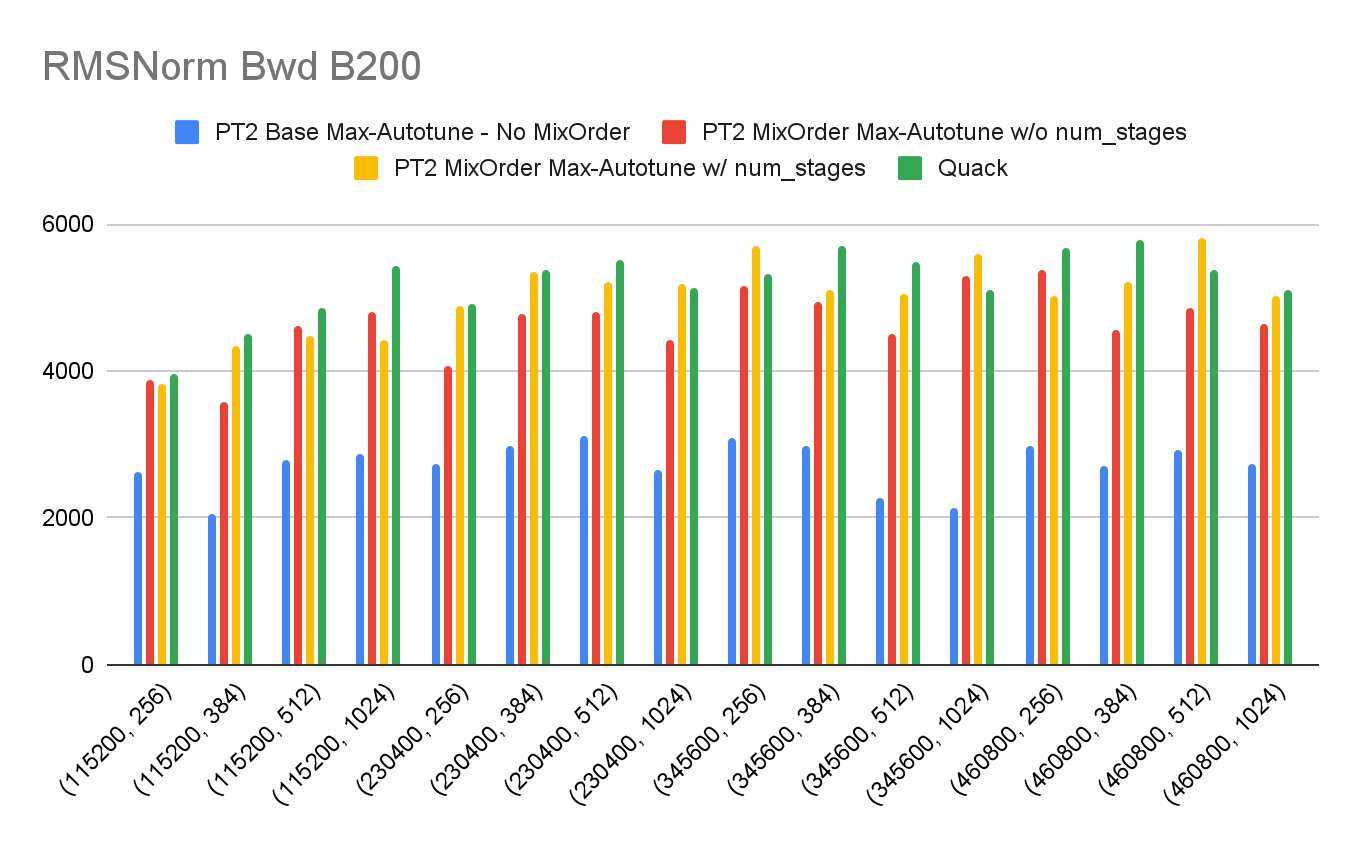
Benchmark Results
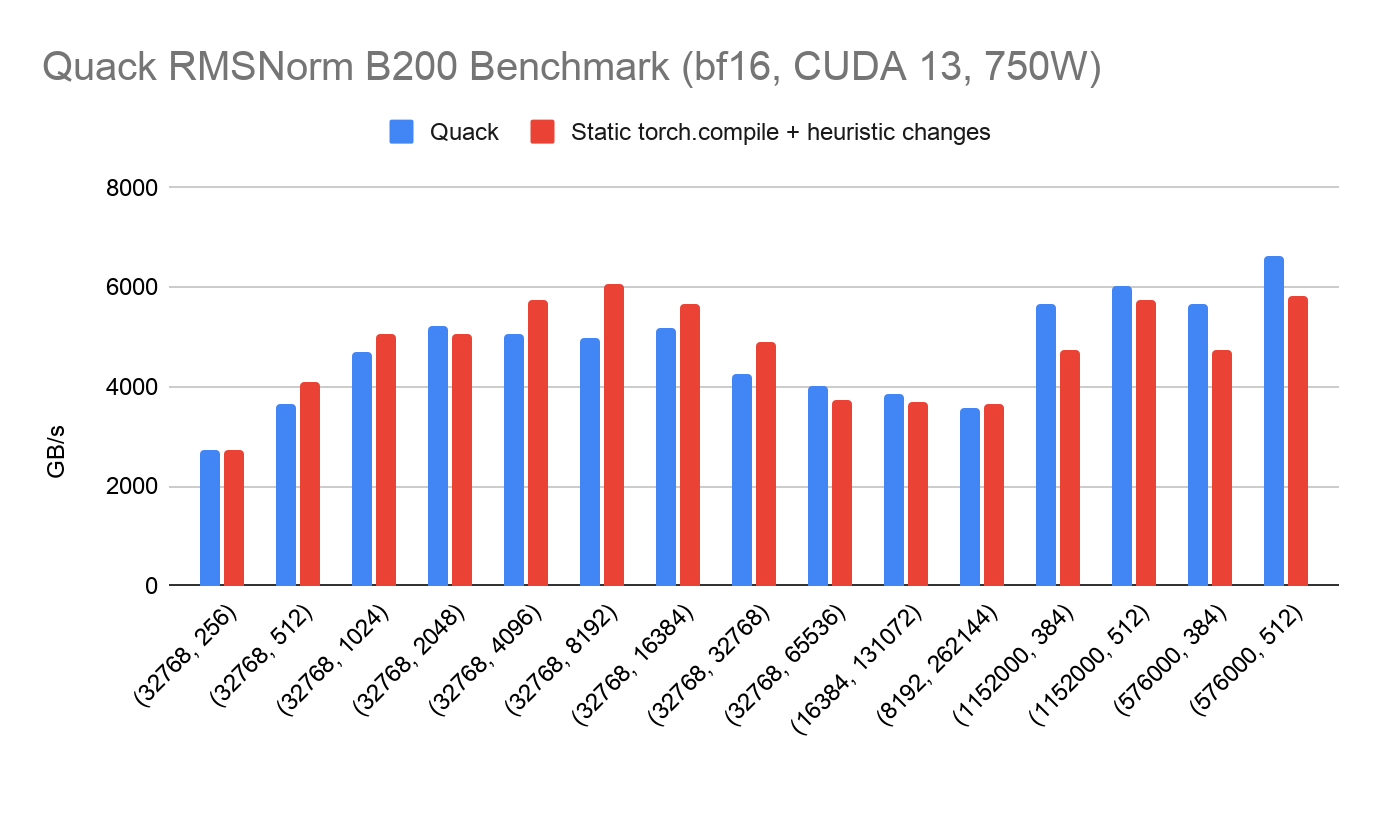
Below we present benchmark results for MixOrderReduction compared to PyTorch eager and previous compile, alongside OSS baselines such as Quack and liger. Both of these benchmarks were run on a 750W B200 machine on CUDA 12.9 in late 2025.
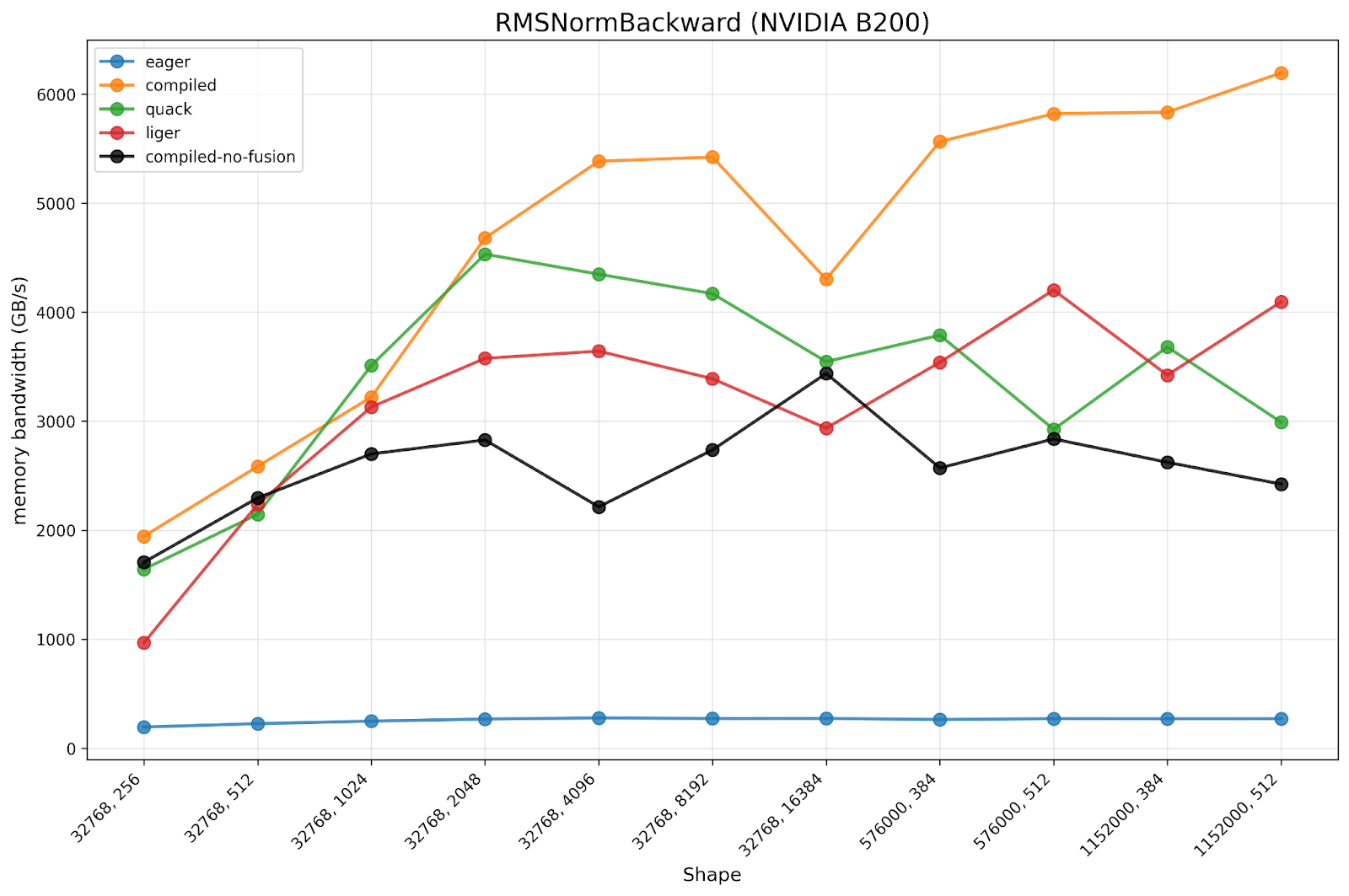
We observe that:
- The torch.compile w/ MixOrderReduction is 17.07x faster than eager, while torch.compile w/o MixOrderReduction is only 9.93x faster than eager.
- We observe the torch.compile w/ MixOrderReduction is 1.45x faster than Liger and 1.34x faster than Quack
We also present benchmarking results for LayerNorm, expecting similar results to RMSNorm due to the similarity in the kernels.
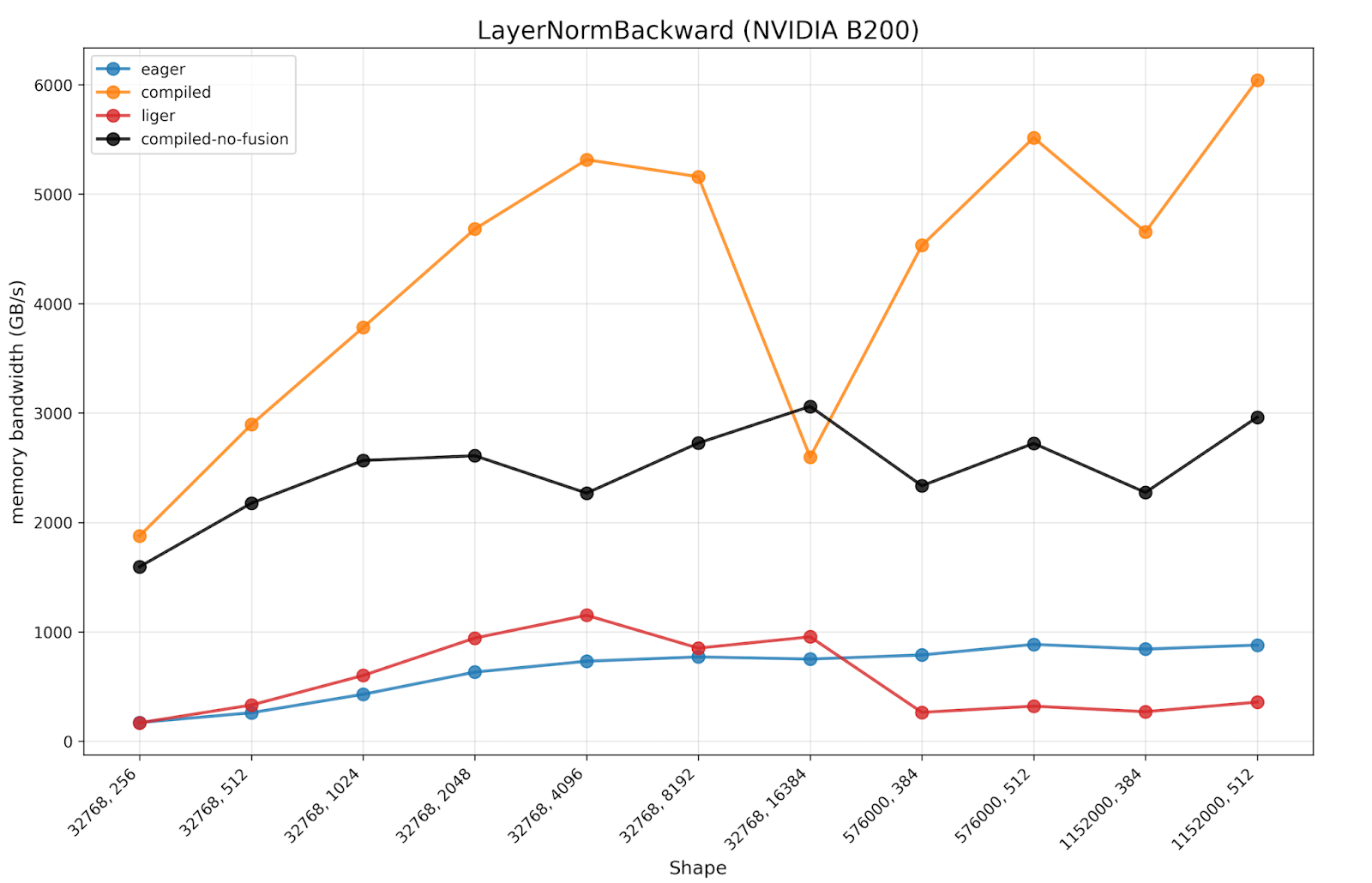
We observe the same trend in the results as RMSNorm, where torch.compile w/o MixOrderReduction has a significant speedup compared to PyTorch eager. However, torch.compile w/ the new MixOrderReduction paradigm has almost a 2x speedup compared to the previous torch.compile baseline, much closer to peak memory bandwidth.
Conclusion
We improved torch.compile to generate near SOTA forward and backward normalization kernels on H100 and B200 through torch.compile on standard shapes compared to Quack. On top of these optimized kernels, torch.compile provides automatic fusion capabilities of surrounding ops, other pointwise/reductions, allowing for better e2e performance than hand authored kernels.