Overview
This blog walks through two crucial DeepSpeed updates: (1) a PyTorch-identical backward API that enables efficient training of multimodal, multi-component models (including non-scalar backward calls), and (2) low-precision model training that significantly reduces peak memory, especially.
For multimodal workloads, like combining a vision encoder with an LLM, training loops can become complex and multi-component. The first update introduces a PyTorch-identical backward API that makes writing such loops straightforward, enabling sophisticated parallelism schemes with simple, clean code, while DeepSpeed transparently manages various performance optimizations. As one example, the flexibility of the API enabled disaggregated hybrid parallelism, achieving a 30% speedup for multimodal AI model training while making model development with DeepSpeed feel closer to “vanilla PyTorch”.
Meanwhile, for LLM fine-tuning, a new option to keep all model states (parameters, gradients, and optimizer states) in lower-precision, such as BF16 or FP16, drastically reduces the memory footprint, allowing researchers to train larger models on more constrained hardware. Low-precision training is highly beneficial across a wide range of applications, including supervised fine-tuning (SFT), reinforcement learning (RL), and multimodal training. Our experiment showed 40% peak memory reduction while keeping numerical stability (benchmarking script). The numerical stability is achieved through integration with torch.autocast, which ensures the quality of the model is maintained.
The remainder of this blog will elaborate on how these updates directly facilitate the development of cutting-edge training workloads.
1. PyTorch-identical backward API
DeepSpeed now supports PyTorch’s native backward() syntax while preserving all its optimizations. Traditionally, DeepSpeed’s training loop relied on the engine’s backward API:
loss = model_engine(batch)
model_engine.backward(loss)
model_engine.step()The engine’s backward API was sufficient for traditional pretraining and fine-tuning pipelines. However, recent complex training pipelines require more flexibility. There were two major limitations:
- It only accepted a scalar loss.
- You had to call
model_engine.backward(loss), rather than using the usual PyTorchloss.backward()style.
Due to these constraints, users could not simply implement patterns that vanilla PyTorch allows. Here are some examples:
# 1. Combine multiple models and losses
output1 = model1(batch1)
output2 = model2(batch2)
loss = criterion(output1, output2)
loss.backward()
# 2. Define a loss function separately from the main model
output = model(batch)
loss = loss_fn(output)
loss.backward()
# 3. Call backward through non-scalar tensors with custom gradients
output = model(batch)
output.backward(grad)DeepSpeed Engine was able to handle these use cases using internal APIs; however, that required significant code changes and could easily introduce bugs. With the addition of PyTorch-identical backward API, we can now use the same code as native PyTorch while keeping DeepSpeed’s powerful optimizations, including ZeRO and offloading.
One example use case for the PyTorch-identical backward API is disaggregated hybrid parallelism for multimodal models using Ray. In this training pipeline, two Ray Actor groups handle the vision encoder and the LLM separately. On a backward pass, the LLM passes a gradient to the vision encoder, and the vision encoder calls the backward function with that gradient. However, because the gradient is a non-scalar tensor, such a use case wasn’t officially supported by DeepSpeed APIs. The disaggregated hybrid parallelism demonstrates that the flexibility of the backward API combined with DeepSpeed’s optimization and DeepSpeed-Ulysses (highly efficient sequence parallelism), achieves 30% speedup in training.
Below is the pseudo-code for the two models running on different actors. Since they run in different processes, we pass gradients via Ray actor communication. As seen here, the gradient of the vision embedding is a non-scalar tensor. Although this code is identical to the PyTorch API, it will activate various DeepSpeed optimizations based on your configuration.
# Runs on LLM actors
def text_backward_step(self):
# ...
self.loss.backward()
return self.vision_embeddings.grad.detach().clone()
# Runs on Vision actors
def vision_backward_step(self, vision_embedding_grad):
self.vision_output.backward(gradient=vision_embedding_grad)Check out the repository for the complete training pipeline.
2. Memory-efficient low-precision model states
You can now keep all model states (parameters, gradients, and optimizer states) in BF16 or FP16, significantly reducing memory consumption.
Traditionally, DeepSpeed’s mixed precision keeps FP32 master parameters, gradients, and optimizer states, which is technically safer but memory-intensive. While DeepSpeed has supported torch.autocast via configuration (see the API documentation), the lack of an option to bypass creating FP32 states limited the trainability of large models on constrained hardware. In practice, many training workloads converge stably without FP32 states.
With the low-precision model states option, you can easily skip creating FP32 states and combine the low-precision option with torch.autocast support (see the document and example for configuration details). This combination drastically improves memory efficiency without sacrificing convergence.
{
...
"zero_optimization": {
"stage": 3,
...
},
"bf16": {
"enabled": true,
"bf16_master_weights_and_grads": true,
"bf16_optimizer_states": true
},
"torch_autocast": {
"enabled": true,
"dtype": "bfloat16"
}
}Our example script demonstrates the significant memory savings:
| Configuration | Allocated Memory | Peak Memory | Avg Step Time |
| Baseline (fp32 master) | 25.74 GB | 31.38 GB | 0.6016s |
| BF16 low-precision (master + opt states) | 16.17 GB | 18.93 GB | 0.6427s |
The experiment (7B model, ZeRO3, 4GPUs) demonstrated 40% reduction in peak memory. To verify that BF16 low-precision training maintains numerical stability, we trained for 1000 steps on the Wikitext-103 dataset:
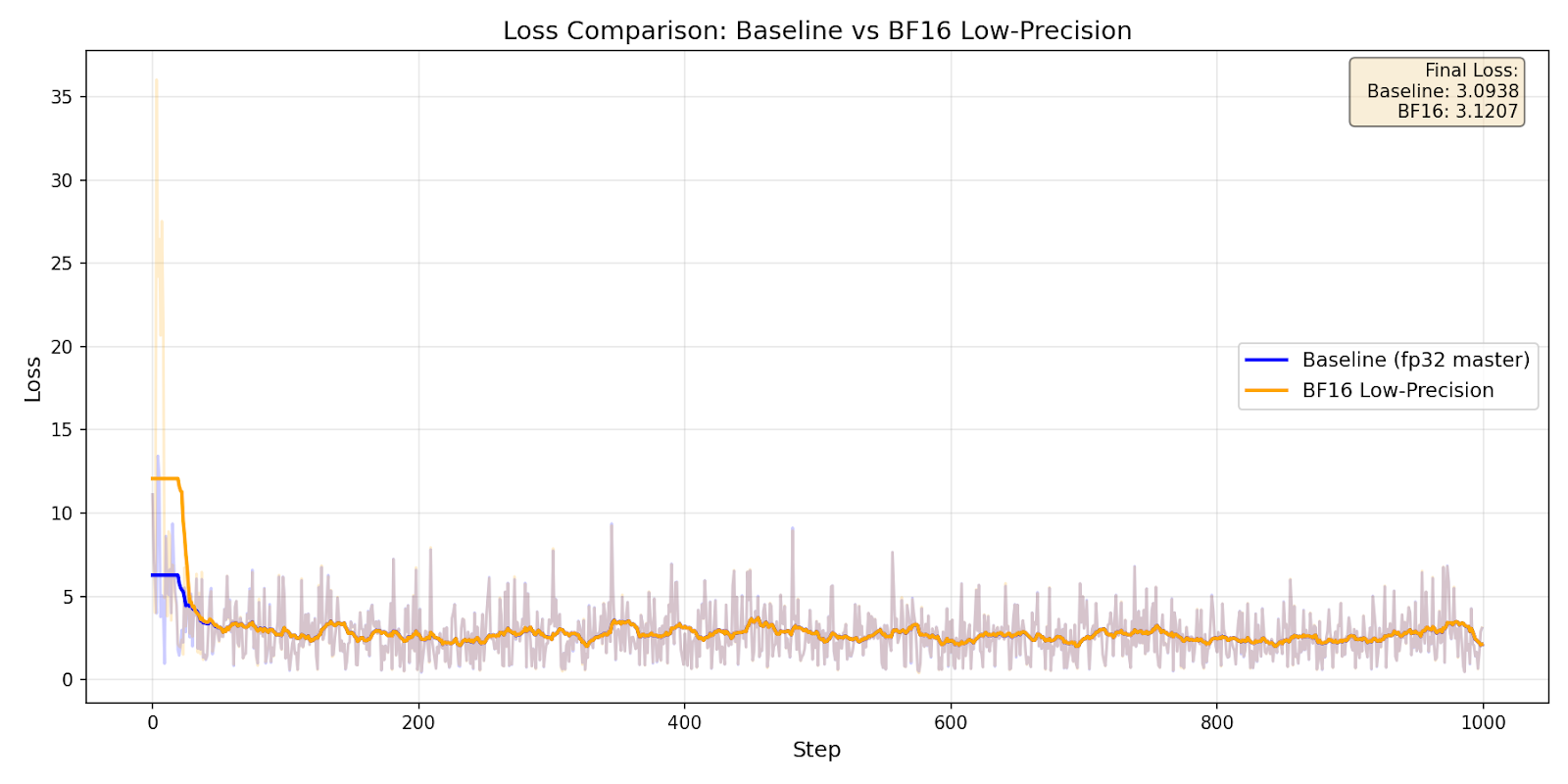 Loss curve comparison
Loss curve comparison
| Configuration | Final Loss | Mean Loss |
| Baseline (fp32 master) | 3.09 | 2.78 |
| BF16 Low-Precision | 3.12 | 2.90 |
Related Tests
We continuously test these new APIs in our CI, and you can see various use-case patterns in the tests.
- PyTorch-compatible backward API
- Low-precision master params/grads/optimizer states
- Combination with torch.autocast
Closing Thoughts
This DeepSpeed update delivers key advancements:
- Enabling Complex Multimodal Workloads: The new PyTorch-identical backward API enables sophisticated multi-component training loops, such as those required for multimodal models, with simple, clean code. As one example, the PyTorch-identical backward API has enabled a 30% speedup for disaggregated hybrid parallelism.
- Scaling to Larger Models: Low-precision model states combined with
torch.autocastreduce peak memory by up to 40% without sacrificing convergence, allowing you to train larger models with the same hardware.
We are excited to see how you use the new APIs and features described in this blog post in your own training setups, and we welcome feedback and issues on GitHub as you try them out.