
TL;DR: DeepSeek-V4 support was live in SGLang on Day-0, but the Day-0 stack was only the starting point. Since launch, we have coordinated a set of kernel, runtime, and hardening improvements: MHC fusion and token-bucket prewarm, KV Compression V2, W4A4 MegaMoE, stronger SWA budgeting and eviction behavior, better disaggregated decode admission, breakable CUDA graph support in the DeepSeek-V4 prefill path, and bug fixes in both SGLang and Dynamo that removed instability from the serving frontier.
In this blog, we look at the performance results. On the public SemiAnalysis InferenceX GB300 disaggregated lane (DeepSeek-V4 Pro, FP4, ISL=8192, OSL=1024, dynamo-sglang), the June 2026 MTP curve delivers ~11,200 tok/s/GPU at roughly 50 tok/s/user, versus ~2,200 tok/s/GPU for the Day-0 (April 2026) no-MTP curve — a 5x increase at the same user-visible interactivity.
Performance Results
Below are the performance results from the public SemiAnalysis InferenceX dashboard. Each figure fixes the model, GPU family, precision, workload, serving framework, and serving mode, and compares SGLang against itself over time.
NVIDIA GB300 Disaggregated 8K/1K
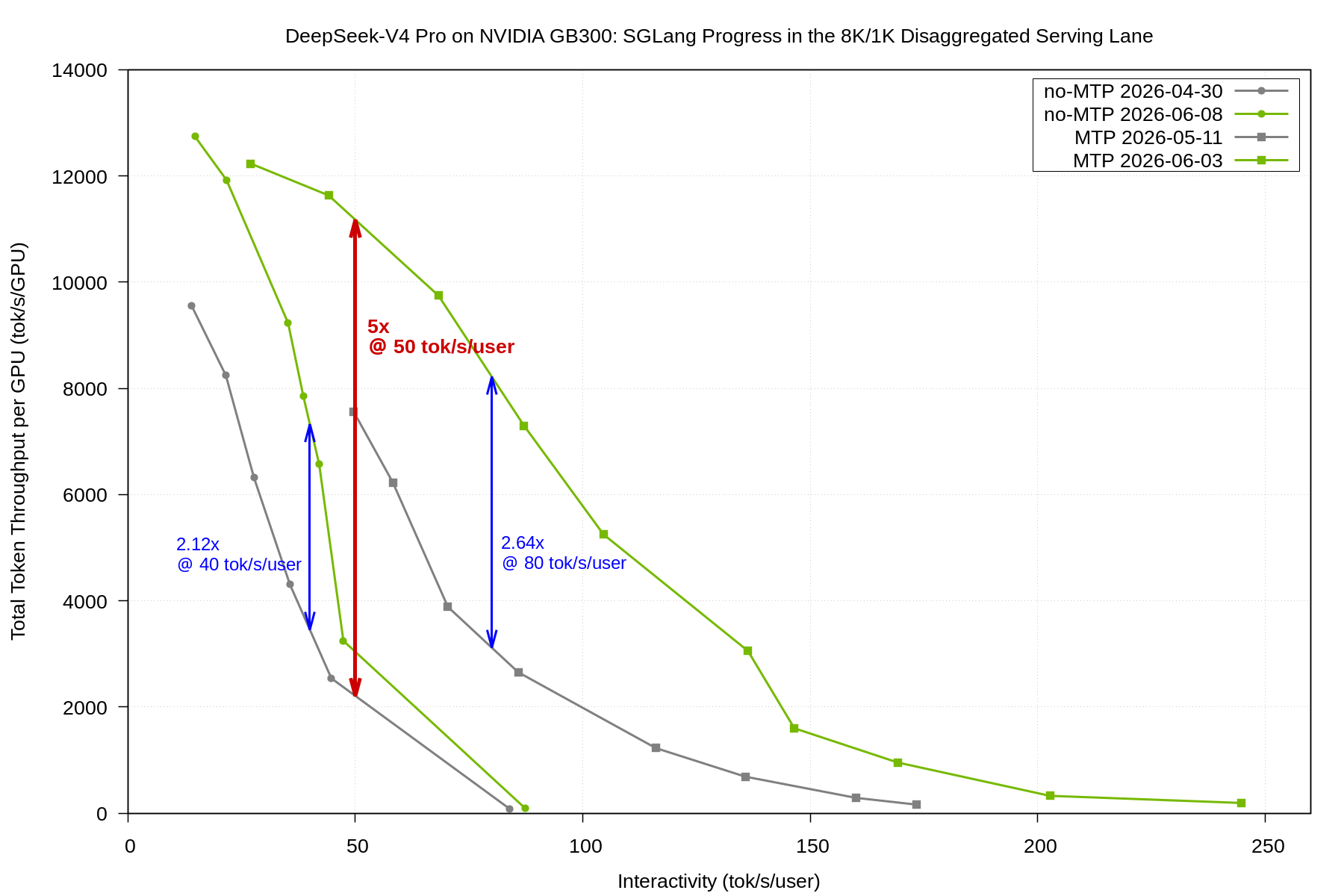
The NVIDIA GB300 disaggregated lane shows substantial performance improvement.
Two things stand out. First, this is not a single-point win: both the no-MTP and MTP curves lifted across the entire interactivity range. Second — and more important for real deployments — the curves now hold throughput much deeper into the high-interactivity region. The Day-0 curve fell off steeply past ~40 tok/s/user; the June curves sustain 2.1x more throughput at 40 tok/s/user (no-MTP) and 2.6x more at 80 tok/s/user (MTP), the interactivity range most deployments target.
The no-MTP and MTP frontiers sit on top of the same DeepSeek-V4 serving stack. When we reduced prefill-side kernel overhead, made DeepSeek-V4 runtime compilation behavior more predictable, improved decode-side SWA accounting, aligned the FP4 MoE path with the deployed recipes, and fixed correctness issues that were distorting the speculative path, both curves moved.
NVIDIA Blackwell Ultra Aggregated 8K/1K
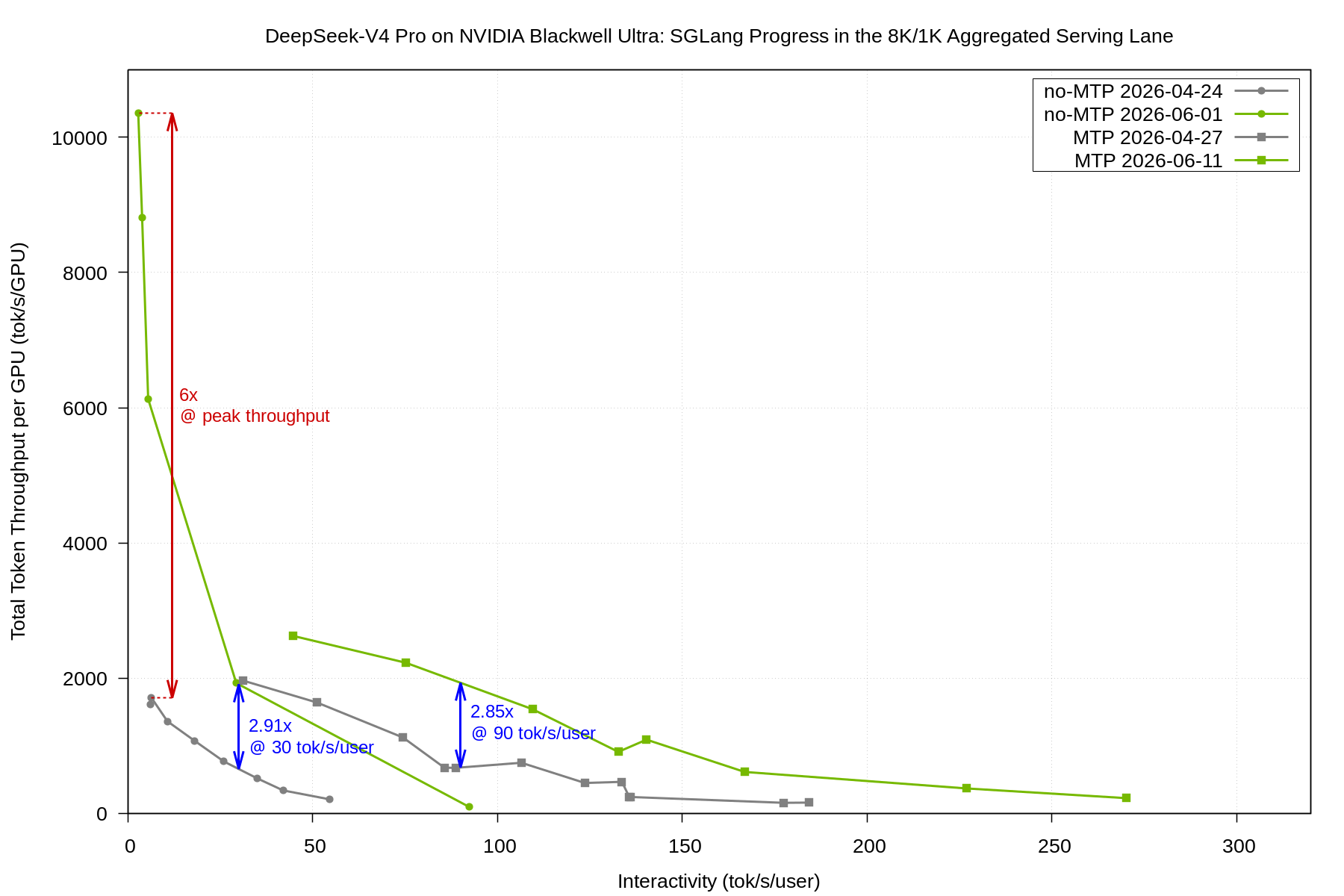
The NVIDIA Blackwell Ultra aggregated lane also showcases significant performance improvements thanks to the same optimizations. Throughput improved by 2.91x at 30 tok/s/user (no-MTP) and by 2.85x at 90 tok/s/user (MTP).
In addition, the no-MTP peak throughput improved by more than 6x compared with the Day-0 curve. This is because the earlier no-MTP curve started from a lower-throughput fallback recipe with TP-only execution, no DP attention, no speculative decoding, and a narrower search space. By the later public submissions, the Blackwell Ultra aggregated lane had moved to a much stronger recipe family with better recipe-per-concurrency dispatch, higher sustainable batch sizes on the decode worker, and a more mature FP4/MoE path.
What Already Existed on Day-0
Day-0 support was already substantial. By the launch window, SGLang already had a functional DeepSeek-V4 serving path, deployment guidance through the DeepSeek-V4 recipe family, and verified launch configurations across multiple platforms. The launch stack already exercised the main ingredients that make DeepSeek-V4 hard and interesting to serve: FP4 inference, MoE execution with both DeepGEMM MegaMoE kernels for high-throughput and the FlashInfer TRT-LLM MoE backend for low-latency, FlashMLA-related attention/kernel infrastructure, DP/EP/TP recipe variants, disaggregated deployment, speculative decoding support, and full CUDA graph support on the decode side.
That foundation mattered. Instead of starting from “can the model run at all?”, we were starting from a working system that could already serve DeepSeek-V4 on real hardware, including the first NVIDIA Blackwell Ultra aggregate submissions and the first NVIDIA GB300 disaggregated submissions right after the Day-0 launch. The follow-up work was about turning that Day-0 stack into a faster, more stable, more production-shaped serving path.
What Changed After Day-0
Kernel-Related Optimizations
The most visible kernel-side work was in the MHC pipeline. In #24775, SGLang rewired the DeepSeek-V4 MHC path around a deeper fused implementation: the large mhc_pre path moved onto a stronger DeepGEMM-backed flow, RMSNorm work was fused into the MHC path instead of being left as a separate stage boundary, and SGLang added a dedicated fused hc_head kernel. That change reduces the amount of intermediate tensor traffic and scheduler-visible plumbing in one of the most expensive parts of the DeepSeek-V4 prefill path. Continuing the same theme, #25976 adds a fused mhc_fused_post_pre kernel, which shrinks the number of expensive boundaries in the MHC path instead of treating MHC as a pile of independent point operations.
KV Compression V2 was the other major kernel-facing jump. #24890 added the V2 DeepSeek-V4 compression kernels, including new c4, c128, and online c128 compression kernels, updated compressor plumbing, and new fused norm/rope V2 pieces. This matters because DeepSeek-V4 needs not only fast matmuls, but also compression and indexer kernels that remain efficient as concurrency increases.
The FP4 MoE path also improved materially. Before #25052, the DeepGEMM MegaMoE path for DeepSeek-V4 was using the W4A8 kernel, which means the expert weights were quantized to MXFP4 but the activation path still quantized to MXFP8. After #25052, SGLang adds an option to enable the W4A4 MegaMoE path, so the activation path is also quantized to MXFP4 instead of MXFP8 with negligible accuracy loss. That improves MoE efficiency most clearly in the higher-throughput operating range.
Taken together, this is the kernel story after Day-0: fewer unfused boundaries, better DeepSeek-V4-specific compression kernels, better FP4 MoE kernels, and less non-matmul overhead hiding inside the prefill and compression path.
Runtime-Related Optimizations
The runtime work was just as important. On DeepSeek-V4, the serving frontier is often set by whether the runtime can budget, allocate, graph-capture, and recycle the right state under real request mixes. That is why the runtime-level optimizations and disaggregation work moved the curves so much.
#24036 fixes disaggregated decode SWA preallocation sizing by separating full-length accounting from the SWA tail that actually has to remain resident in the sliding-window pool. #24857 pushes that farther with more accurate full-token and SWA-token budgeting, better reservation logic across waiting, running, and transfer states, and more realistic preallocation behavior for the SWA tail. In practical terms, these changes let the decode worker run at a much higher effective batch size, or a much larger number of concurrent requests, before hitting the memory limit. That is directly valuable for throughput because a decode worker that can sustain a larger batch can keep the GPU much busier.
We also refined our runtime recipes to better match different serving scenarios. For the Blackwell Ultra aggregated lane, we moved away from a one-size-fits-all approach to a per-concurrency dispatch strategy, enabling each concurrency level to use a tailored recipe. For the NVIDIA GB300 disaggregated lane, we introduced a set of tuned recipes that delivered substantial performance gains. These improvements came from carefully tuning key parameters such as the prefill-to-decode ratio, parallel execution plans (for example, wide-EP configurations), KV cache memory allocation for full and sliding window attention, token and request size limits, and tokenizer configuration.
The CUDA graph story also improved. The DeepSeek-V4 runtime path contains enough irregular behavior to make graph capture challenging, and the runtime had to retreat into eager islands too often. The breakable-CUDA-graph work for DeepSeek-V4 DP attention in #25195, together with the follow-up speculative-path enablement in #25795, pushed more of the prefill path back under graph-friendly execution. That improves prefill worker performance by making it less host-bound and by letting the GPU stay better utilized during the prefill phase. Decode already had full CUDA graph support on Day-0, so the main additional value here is on the prefill side, which has more irregular paths that break graph capture more often.
There are also a few optimizations that are not covered by the SemiAnalysis InferenceX benchmarking scenarios but still matter for real deployments. PD deployment with common parallelisms such as TP, DP, and EP already existed on Day-0. #24704 extends that path by adding pipeline parallelism support for DeepSeek-V4 PD deployments. The DeepEP path was also tightened further with changes like DeepEP Waterfill support in #25391.
Bug Fixes and Hardening
Some of the most valuable performance improvements in this period were bug-shaped. They did not make the benchmark story by adding a new algorithm. They made it by removing correctness and stability problems that kept the runtime from holding the better curve.
On the speculative and disaggregated side, #23919 fixes the PD-MTP metadata buffer hidden-size bug, and #25805 fixes a double-free in SWA memory handling under disaggregated decode with MTP speculation. Those are the sort of issues that can make a speculative serving path look fine in one narrow recipe and then collapse when you push it across a real concurrency sweep.
Runtime compilation behavior also needed hardening. #25810 adds a representative MHC token-count bucket prewarm so the first real requests do not keep paying lazy compile costs for the token-count buckets that DeepSeek-V4 actually visits. That is a performance change, but it is also a reliability change: a serving system that already knows its hot shapes should not spend the critical path rediscovering them at runtime.
There were also correctness fixes. #25733 fixes a DeepSeek-V4-Pro NaN on NVIDIA Blackwell by converting the fp8_einsum input scale to ue8m0. That change is primarily a correctness fix, but it also had a practical serving-side effect on the speculative path: once the Blackwell FP8-einsum scaling stopped corrupting the DeepSeek-V4 MTP path, acceptance length recovered as well. In one observed run, this one-line fix increased the acceptance rate from 0.57 to 0.70. This is a good example of a bug fix that does not present itself as a “performance PR” yet still helps move the MTP frontier in practice.
Dynamo also needed one important fix to work well with SGLang. ai-dynamo/dynamo#9080 aligns bootstrap-room generation with the chosen prefill DP rank, which reduces workload imbalance across DP ranks. That is outside the main SGLang repository, but it is still part of the public serving path for the GB300 disaggregated lane and therefore part of the performance story we see in the live frontier.
So the bug-fix bucket is part of the performance story, not separate from it. When the DeepSeek-V4 runtime stops mis-sizing metadata, stops double-freeing SWA state, stops paying lazy MHC compile costs for known shapes, stops tripping numerical hazards on NVIDIA Blackwell, and stops skewing work across DP ranks, the serving frontier becomes both faster and more trustworthy.
How to Reproduce
Below are the public reference points for the scripts and recipes used by the SemiAnalysis InferenceX runs that generated the results in this post.
The NVIDIA GB300 disaggregated runs utilize srt-slurm to launch the Dynamo frontend and SGLang prefill/decode servers in Slurm-managed clusters. The configs used for the GB300 disaggregated performance sweep can be found at https://github.com/SemiAnalysisAI/InferenceX/tree/801d1261235f4892d4831de9de70c34f5bea7d98/benchmarks/multi_node/srt-slurm-recipes/sglang/deepseek-v4/8k1k
The srt-slurm reproduction flow looks like this:
git clone https://github.com/NVIDIA/srt-slurm
cd srt-slurm
pip install -e .
srtctl apply -f benchmarks/multi_node/srt-slurm-recipes/sglang/deepseek-v4/8k1k/disagg-gb300-10p1d-dep4-dep32-18-c2500.yamlThe NVIDIA Blackwell Ultra aggregated scripts can be found below:
- NVIDIA Blackwell Ultra aggregated no-MTP script: https://github.com/SemiAnalysisAI/InferenceX/blob/801d1261235f4892d4831de9de70c34f5bea7d98/benchmarks/single_node/fixed_seq_len/dsv4_fp4_b300_sglang.sh
- NVIDIA Blackwell Ultra aggregated MTP script: https://github.com/SemiAnalysisAI/InferenceX/blob/801d1261235f4892d4831de9de70c34f5bea7d98/benchmarks/single_node/fixed_seq_len/dsv4_fp4_b300_sglang_mtp.sh
For the exact NVIDIA GB300 and NVIDIA Blackwell Ultra curves shown in this post, refer to the SemiAnalysis InferenceX website to get the original performance data and the latest curves.
Roadmap
The next steps are less about proving DeepSeek-V4 viability and more about continuing to tighten the production path:
- Optimize kernel performance for the DeepSeek-V4 model, including DeepEP v2, the ragged indexer kernel, and more fusion on small kernels.
- Expand DeepSeek-V4 support on SM120/SM121 hardware as well as NVFP4 checkpoints.
- Continue improving cache- and routing-sensitive DeepSeek-V4 serving paths.
- Optimize DeepSeek-V4 performance on agentic benchmarks.
These pending optimizations are being tracked in this roadmap issue: #23602.
Acknowledgements
Thanks to the SGLang and NVIDIA contributors who drove the DeepSeek-V4 kernel, runtime, and serving-path work; the SemiAnalysis InferenceX team for keeping the benchmark workflows and changelogs public; and the broader DeepSeek-V4 serving effort around GB300 and Blackwell Ultra deployment.
SGLang Team and Community Contributors: Yuhao Yang, Cheng Wan, Baizhou Zhang, Pranjal Shankhdhar, Tom Chen, Ziyi Xu, Qiaolin Yu, Ke Bao, Liangsheng Yin, Yuwei An, Chunan Zeng, Shangming Cai, Yanbo Yang, Lianmin Zheng, Banghua Zhu, Ying Sheng
NVIDIA Team: Yangmin Li, Weiliang Liu, Ishan Dhanani, Hao Lu, Ian Wang, Trevor Morris, Elvis Chen, Shu-Hao Yeh, Julien Lin, Akhil Goel, Nicolas Castet, Kedar Potdar, Ankur Singh, Harshika Shrivastava, Kaixi Matteo Chen, Xuting Zhou, Po-Han Huang, Triston Cao, and many more