Featured projects

TL;DR
Helion kernels were integrated into vLLM for FP8 inference using Qwen3 models and evaluated across NVIDIA H100 and B200 GPUs. The experiments show that Helion provides a productive PyTorch-native workflow for developing fused GPU kernels while delivering performance improvements for many quantization, normalization, and fusion-heavy inference kernels. End-to-end benchmarks demonstrated throughput gains across multiple serving scenarios, with additional optimization work underway for GEMM performance on Blackwell GPUs.
Brief Background on vLLM and Helion
vLLM is a high-performance inference and serving framework for large language models (LLMs). It is widely used for production LLM serving due to its strong throughput performance, efficient KV-cache management, continuous batching architecture, and support for advanced inference features such as speculative decoding, quantization, and distributed serving. Internally, vLLM relies heavily on custom GPU kernels, TorchInductor fusion, and optimized GEMM backends such as CUTLASS and DeepGEMM to achieve high inference efficiency across different hardware platforms.
Helion is a PyTorch-native hardware agnostic kernel DSL designed for writing high-performance kernels using a tile-programming model. Unlike lower-level CUDA programming, Helion provides a more natural PyTorch-syntax-centric development experience while still exposing low-level control over memory layout, tiling strategy, and kernel scheduling. You can think of it as PyTorch with tiles. If you know PyTorch or Triton, you already know most of Helion. Other than smooth authoring experience, another strength of Helion is its powerful ahead-of-time (AOT) autotuning infrastructure, which can explore a large kernel configuration space and automatically select optimized implementations for specific workloads and hardware targets.
vLLM Model Inference with Helion Kernels
We began by focusing on tensor-parallel-free inference using the Qwen3 model family with FP8 activation quantization enabled.
Our goal was to evaluate whether Helion kernels can improve inference performance compared to the existing vLLM implementations.
For this experiment, we replaced nearly all forward-pass kernels involved in quantized inference with Helion implementations and benchmarked them at both kernel level and end-to-end serving level.
vLLM Forward Pass Fusion Pattern
For Qwen3 models, the unfused forward pass in vLLM executes the following sequence of kernels:
- input_norm
- fp8_quant
- scaled_mm (qkv_proj)
- split_qkv
- q_norm
- k_norm
- rope
- attention
- fp8_quant
- scaled_mm (out_proj)
- post_attention_norm
- fp8_quant
- scaled_mm (gate_up)
- silu_and_mul
- fp8_quant
- scaled_mm (down_proj)
Dynamic Per-Token Activation Quantization
After torch.compile and TorchInductor fusion passes are applied, the execution pattern becomes:
- rms_norm + fp8_quant
- scaled_mm (qkv_proj)
- split_qkv + q_norm + v_norm
- rope
- attention
- fp8_quant
- scaled_mm (out_proj)
- rms_norm + fp8_quant
- scaled_mm (gate_up)
- silu_and_mul + fp8_quant
- scaled_mm (down_proj)
Note that both scaled_mm and attention are registered as PyTorch Custom Operators. Since these operators are opaque to TorchInductor, they form hard boundaries that prevent further compiler-side fusion.
Dynamic Per-Group Activation Quantization
When dynamic per-group activation quantization is enabled and DeepGEMM is selected for scaled_mm_blockwise, the execution pattern changes to:
- rms_norm
- fp8_quant (ue8m0)
- scaled_mm (qkv_proj, DeepGEMM)
- split_qkv + q_norm + v_norm
- rope
- attention
- fp8_quant (ue8m0)
- scaled_mm (out_proj, DeepGEMM)
- rms_norm
- fp8_quant (ue8m0)
- scaled_mm (gate_up, DeepGEMM)
- silu_and_mul
- fp8_quant (ue8m0)
- scaled_mm (down_proj, DeepGEMM)
DeepGEMM uses UE8M0 activation quantization internally. In the current vLLM implementation, fuse_act_quant and fuse_norm_quant passes are not supported for UE8M0 quantization, which prevents these additional fusions from occurring.
If DeepGEMM is unavailable and CUTLASS-based kernels are used instead, the execution pattern becomes similar to the dynamic per-token quantization case.
Helion Kernels Implementation
For this work, we implemented the following Helion kernels:
- dynamic_per_token_scaled_fp8_quant
- rms_norm_dynamic_per_token_quant
- silu_and_mul_dynamic_per_token_quant
- fused_qk_norm_rope
- per_token_group_fp8_quant
- rms_norm_per_block_quant
- silu_and_mul_per_block_quant
- scaled_mm
- scaled_mm_blockwise
The scaled_mm and scaled_mm_blockwise kernels follow the existing Triton implementations in vLLM (triton_scaled_mm, w8a8_triton_block_scaled_mm). silu_and_mul_dynamic_per_token_quant is a new fused kernel that combines silu_and_mul and dynamic_per_token_quant into a single kernel launch. The remaining kernels are Helion reimplementations of the existing torch.ops._C CUDA kernels used by vLLM.
vLLM Helion Kernel Integration
We integrated these kernels using the vLLM Helion kernel integration framework which provided:
- Autotuning infrastructure
- Config management
- Kernel registration
- Runtime dispatching
To enable the Helion kernels, we manually updated vLLM fusion passes to replace the corresponding kernels with corresponding Helion fused kernels. After fusion, the forward-pass execution patterns became the following:
For per-token activation quantization:
- rms_norm_dynamic_per_token_quant (helion)
- scaled_mm (helion)
- fused_qk_norm_rope (helion)
- attention (default)
- dynamic_per_token_scaled_fp8_quant (helion)
- scaled_mm (helion)
- rms_norm_dynamic_per_token_quant (helion)
- scaled_mm (helion)
- silu_and_mul_dynamic_per_token_quant (helion)
- scaled_mm (helion)
For per-group activation quantization:
- rms_norm_per_block_quant (helion)
- scaled_mm_blockwise (helion)
- fused_qk_norm_rope (helion)
- attention (default)
- per_token_group_fp8_quant (helion)
- scaled_mm_blockwise (helion)
- rms_norm_per_block_quant (helion)
- scaled_mm_blockwise (helion)
- silu_and_mul_per_block_quant (helion)
- scaled_mm_blockwise (helion)
Autotuning
We used the Helion’s default LFBOTreeSearch algorithm with the following configuration:
initial_population=FROM_RANDOM, copies=5, max_generations=20, similarity_penalty=1.0
To maximize performance, we autotuned kernels using shapes that exactly match the compile-time static dimensions of each model, such as hidden size and intermediate size. This is the advantage of vLLM-Helion integration – it allows Helion to autotune/store/dispatch configs for many different shapes, the same advantage would apply to real world production use cases too.
For the dynamic dimension (num_tokens), we autotuned across power-of-two values ranging from 1 to 8192.
For example, we autotuned scaled_mm kernel for input tensors [M, K] x [K, N], where
- M ranges from 1 to 8192
- (K, N) pairs correspond to the projection layers of each Qwen3 model.
| Model | qkv_proj | out_proj | gate_up | down_proj |
| Qwen3-1.7B | [2048, 4096] | [2048, 2048] | [2048, 12288] | [6144, 2048] |
| Qwen3-8B | [4096, 6144] | [4096, 4096] | [4096, 24576] | [12288, 4096] |
| Qwen3-32B | [5120, 10240] | [5120, 5120] | [5120, 51200] | [25600, 5120] |
Tab. 1: Projection layer [K, N] dimensions for each Qwen3 model.
We independently autotuned all kernels for each hardware platform under test.
Runtime Dispatching
At runtime, the Helion integration framework dispatched requests to the autotuned config most appropriate for the input shape.
For example, scaled_mm dispatching is performed based on shapes of two input matrices (M, K, N), where M is rounded up to the next power of two according to runtime num_tokens of each batch of requests. Similar strategy is applied to other kernels as well.
Performance Evaluation – Kernel Level
Kernel level benchmarking aims to evaluate the local speedups produced by each individual Helion kernel against their baselines. Specifically, we used CUTLASS as the baseline for scaled_mm and scaled_mm_blockwise. While other ops are compared against torch.compile ‘ed vLLM implementation and existing torch.ops._C kernels. This is because:
- per-token quantization in vLLM uses
torch.compileby default, - per-group quantization uses
torch.ops._CCUDA implementations by default due to this performance issue.
For the torch.compile baseline, we matched the vLLM compilation setup:
torch.compile(
native_torch_impl,
fullgraph=True,
dynamic=False,
backend="inductor",
options={
'enable_auto_functionalized_v2': False,
'size_asserts': False,
'alignment_asserts': False,
'scalar_asserts': False,
'combo_kernels': True,
'benchmark_combo_kernel': True
}
)
Notably, enabling 'combo_kernels': True is important because it allows TorchInductor to fuse multiple independent kernels into a single launch
For kernel-level benchmarking, we enabled CudaGraph mode via triton.testing.do_bench_cudagraph with proper warmup and repetitive testing to get rid of noises like dispatch overhead or cold cache and variations in timing.
| Kernel \ Speedup against baseline (Hardware) | Speedup against torch.compile
(H100) |
Speedup against
torch.ops._C (H100) |
Speedup against
CUTLASS (H100) |
Speedup against
torch.compile (B200) |
Speedup against
torch.ops._C (B200) |
Speedup against CUTLASS
(B200) |
| dynamic_per_token_scaled_fp8_quant | 1.237x | 1.405x | N/A | 1.311x | 1.495x | N/A |
| rms_norm_dynamic_per_token_quant | 1.180x | 1.802x | N/A | 1.240x | 1.969x | N/A |
| silu_and_mul_dynamic_per_token_quant | 1.256x | N/A | N/A | 1.420x | N/A | N/A |
| fused_qk_norm_rope | 1.383x | 1.204x | N/A | 1.133x | 1.155x | N/A |
| per_token_group_fp8_quant | 1.423x | 1.408x | N/A | 1.150x | 1.446x | N/A |
| rms_norm_per_block_quant | 1.674x | 2.055x | N/A | 1.424x | 2.128x | N/A |
| silu_and_mul_per_block_quant | 1.731x | 2.269x | N/A | 1.483x | 2.325x | N/A |
| scaled_mm | N/A | N/A | 1.080x | N/A | N/A | 0.739x |
| scaled_mm_blockwise | N/A | N/A | 0.957x | N/A | N/A | 0.782x |
Tab. 2: A summary of the geometric-mean speedups achieved by Helion kernels.
For non-GEMM kernels, Helion consistently demonstrates strong performance and outperforms both TorchInductor-generated kernels and the existing vLLM CUDA implementations.
For GEMM workloads (scaled_mm and scaled_mm_blockwise), results were more mixed:
- On H100, scaled_mm outperformed CUTLASS.
- On B200, both GEMM kernels currently lagged behind CUTLASS
The primary limiting factor for B200 is the performance of Triton-generated GEMM kernels on Blackwell GPUs rather than the Helion programming model itself. Helion currently relies on Triton code generation for these kernels, and the observed performance gap largely reflects the current state of Triton GEMM performance on Blackwell hardware. Ongoing work on Helion’s CuteDSL backend is expected to further improve GEMM performance on Blackwell.
Performance Evaluation – End-to-End Model Level
End-to-end model level benchmarking, on the other hand, highlights the user-visible impact of Helion kernels. We picked 3 different variants of Qwen3 models for this purpose:
- Qwen3-1.7B
- Qwen3-8B
- Qwen3-32B
CudaGraph is enabled for all model-level benchmarking traffic patterns, which varies num_tokens values ranging from 1 to 8192 at power-of-two intervals for all three Qwen3 models.
To construct the traffic pattern, we used the built-in vLLM serving benchmark with the random input data.
To minimize noise from prefix caching effects, we:
- disabled prompt shuffling,
- restarted the vLLM server before each benchmark run.
Here is an example command:
vllm serve --model $MODEL --max-num-seqs $BATCH_SIZE --tensor-parallel-size 1 --compilation-config '{"max_cudagraph_capture_size": 8192, "custom_ops": ["+quant_fp8"], "pass_config": {"fuse_norm_quant": true, "fuse_act_quant": true, "enable_qk_norm_rope_fusion": true}}'
vllm bench serve \
--backend vllm \
--model $MODEL \
--endpoint /v1/completions \
--dataset-name random \
--num-prompts $NUM_PROMPTS \
--max-concurrency $BATCH_SIZE \
--input-len 512 \
--output-len 600 \
----num-warmups $NUM_WARMUPS \
--disable-shuffle
max_cudagraph_capture_size was set to 8192 to match the default max_num_batched_tokens, ensuring all execution paths were CUDA-graph captured.
All workloads are evaluated on two NVidia GPU platforms:
- NVIDIA H100
- NVIDIA B200
To gain more insight into where performance improvements come from, we grouped the Helion kernels into three categories and benchmarked them independently as well as in combinations.
- fp8_quant: fp8 quantization kernels and fused quant kernels
- qk_norm_rope:
fused_qk_norm_ropekernel - scaled_mm:
scaled_mmorscaled_mm_blockwisekernel.
Dynamic per-token activation quantization
We used the following checkpoints:
- RedHatAI/Qwen3-1.7B-FP8-dynamic
- RedHatAI/Qwen3-8B-FP8-dynamic
- RedHatAI/Qwen3-32B-FP8-dynamic
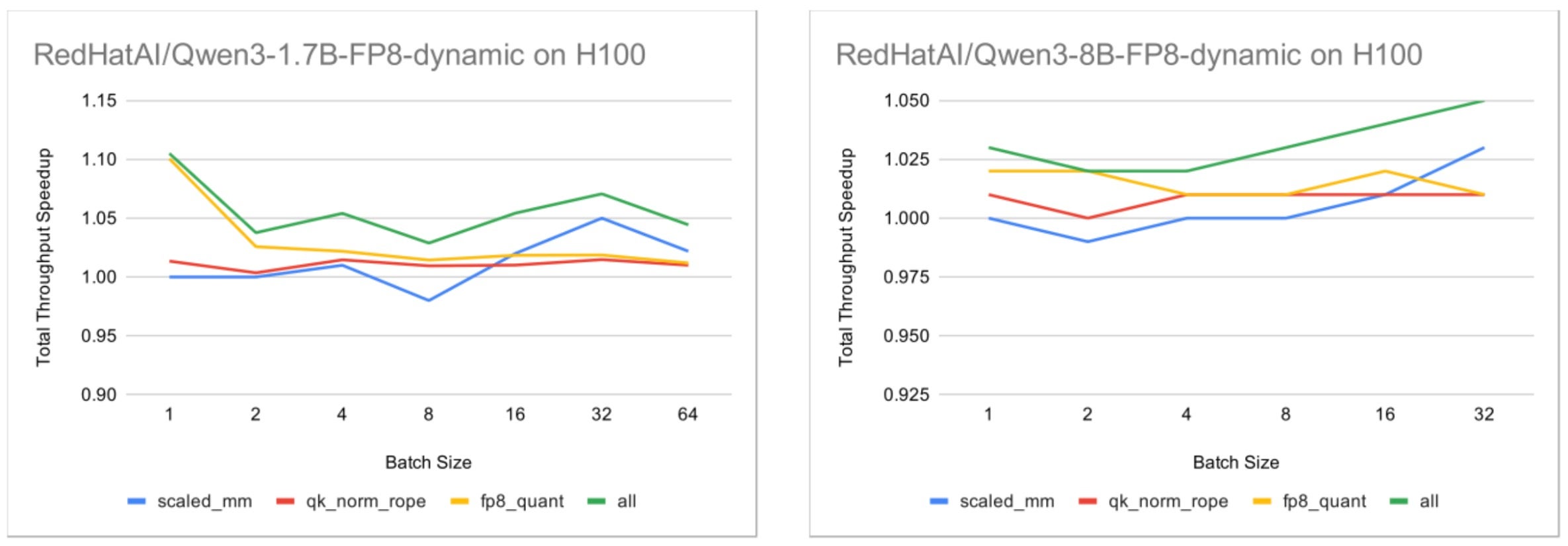
Fig. 1: Total throughput speedup on H100 with per-token activation quantization enabled, using the default vLLM setup as the baseline.
For the 1.7B model, the results show approximately 1.05x end-to-end throughput improvement on H100 when all Helion kernel groups are enabled. For the 8B model, the improvement is most pronounced around batch size 32, which aligns with the kernel-level observations where Helion scaled_mm achieves its strongest performance around num_tokens = 32.
We also evaluated speculative decoding scenarios where the effective decode-phase num_tokens naturally falls into this performance sweet spot.
Using:
- RedHatAI/Qwen3-8B-speculator.eagle3
- RedHatAI/Qwen3-32B-speculator.eagle3
we observed up to approximately 1.09x end-to-end throughput improvement when all Helion kernels were enabled.
| Batch Size | Model | # Speculative Tokens (per-pos acc rate) | Helion TTFT
(mean, ms) |
Default TTFT
(mean, ms) |
TTFT Speedup | Helion TPOT
(mean, ms) |
Default TPOT (mean, ms) | TPOT Speedup | Helion Total Throughput
(tok/s) |
Default Total Throughput
(tok/s) |
Total Throughput Speedup |
| 16 | Qwen3-8B | 1 (47%) | 34.75 | 39.93 | 1.15x | 4.63 | 5.01 | 1.08x | 6,314.86 | 5817.23 | 1.09x |
| 16 | Qwen3-8B | 3 (35%, 25%, 15%) | 38.46 | 51.18 | 1.33x | 4.40 | 4.63 | 1.05x | 6,616.60 | 6261.1 | 1.06x |
| 8 | Qwen3-32B | 2 (24%, 10%) | 81.92 | 100.93 | 1.23x | 13.29 | 14.37 | 1.08x | 1,101.61 | 1018.32 | 1.08x |
| 8 | Qwen3-32B | 3 (24%, 10%, 4%) | 83.01 | 104.73 | 1.26x | 13.33 | 14.21 | 1.07x | 1,100.04 | 1030.51 | 1.07x |
Tab. 3: End-to-end benchmark results on H100 with per-token activation quantization and speculative decoding enabled. Acceptance rates for speculative tokens are reported in parentheses.
On NVIDIA B200, we enabled only the fp8_quant kernel group during end-to-end evaluation. The remaining kernel groups either:
- underperformed relative to the baseline (Triton limitation for Blackwell GEMMs)
- or showed inconsistent gains across traffic patterns.
Even with only the quantization-related kernels enabled, we still observed meaningful throughput improvements across all tested Qwen3 model sizes.
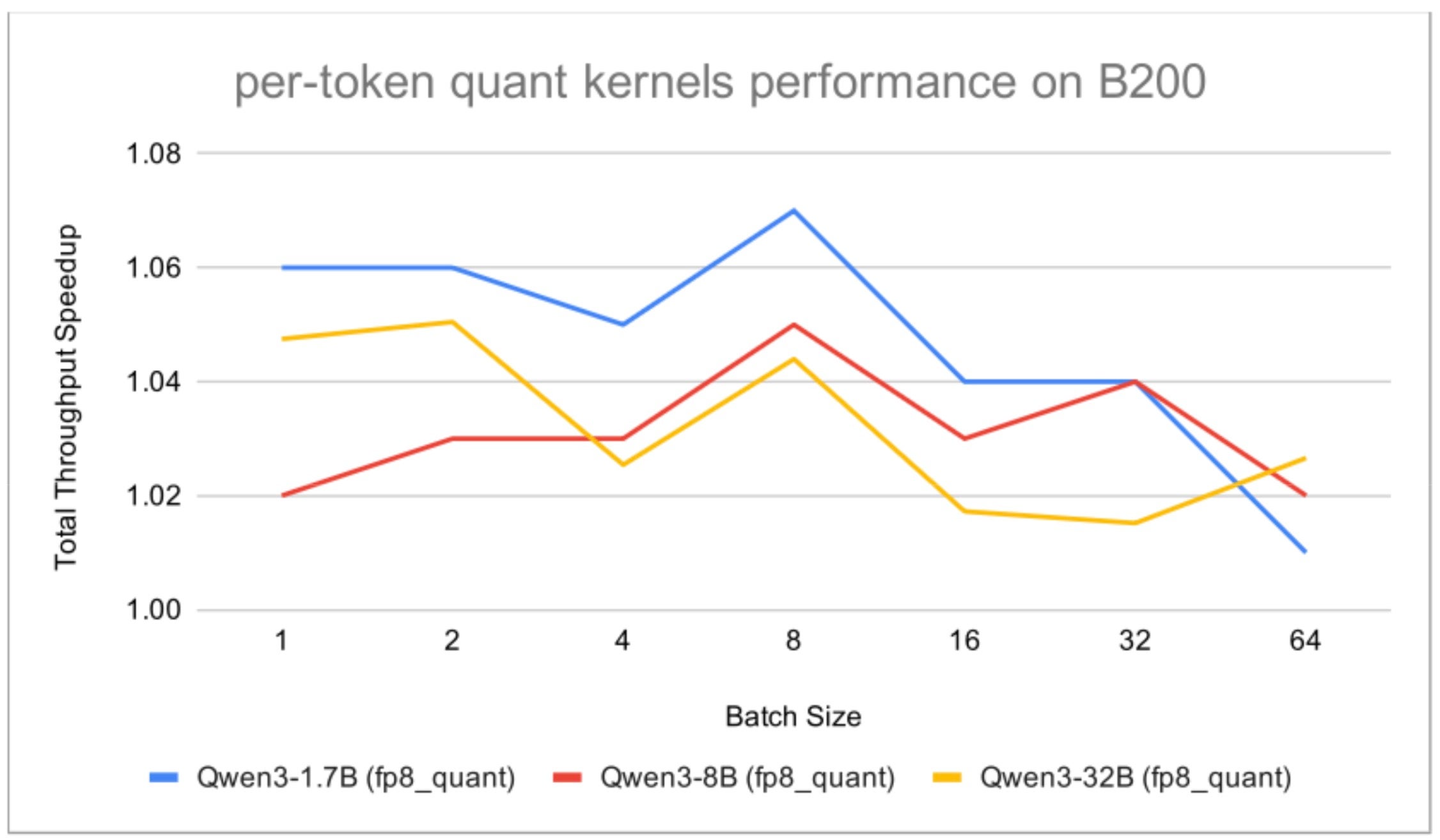
Fig. 2: Total throughput speedup on B200 with per-token activation quantization enabled, using the default vLLM setup as the baseline.
Dynamic per-group activation quantization
For per-group activation quantization, we used the following checkpoints:
- Qwen/Qwen3-1.7B-FP8
- Qwen/Qwen3-8B-FP8
- Qwen/Qwen3-32B-FP8
For per-group activation quantization, DeepGEMM is the default backend for blockwise FP8 GEMM on both H100 and B200. However, our current per-group Helion quantization kernels are not yet compatible with the UE8M0 quantization format required by DeepGEMM. Therefore, for this experiment, we forced vLLM to use CUTLASS as the linear backend.
This means the baseline in this section is not the default vLLM configuration. However, the comparison is still meaningful because we are able to use consistent CUTLASS kernels for the linear layer for all runs. As a result, the measured differences come from the non-GEMM kernels being evaluated, such as FP8 quantization and fused quantization kernels, rather than from changes in the linear backend.
The following figures show enabling only the small Helion kernels still produced approximately 1.05x end-to-end throughput improvement across all workloads.
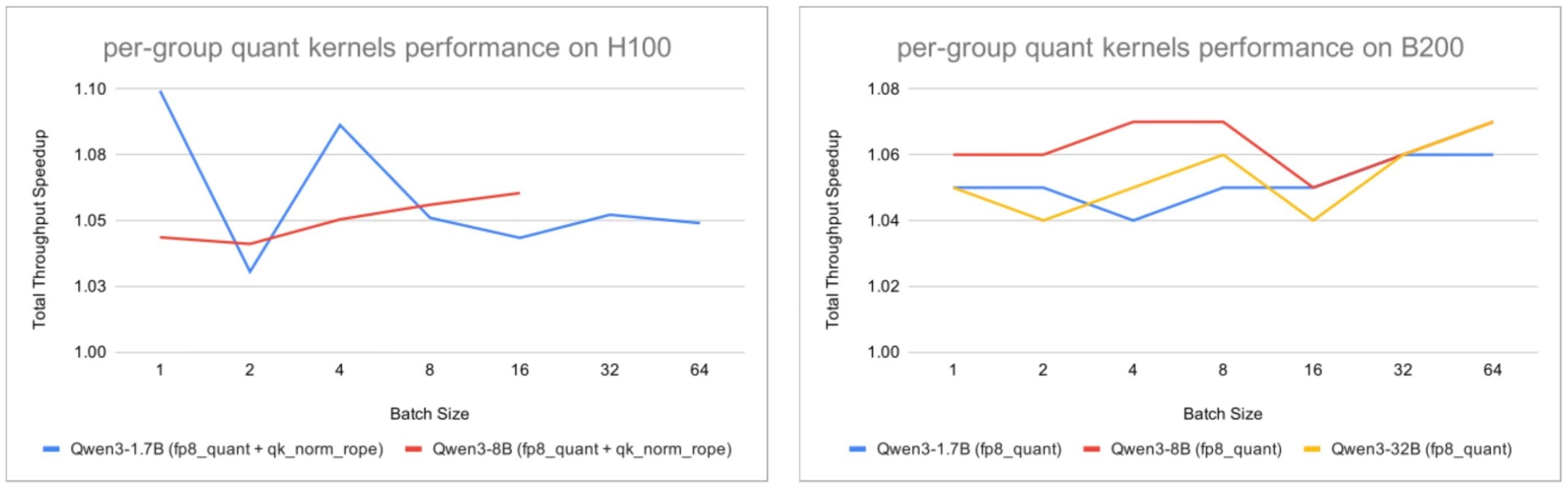
Fig. 3: Total throughput speedup on H100 and B200 with per-group activation quantization enabled, using the default vLLM setup with the linear layer backend replaced by CUTLASS as the baseline.
Resources
For reproducibility and further exploration, all Helion kernel implementations discussed in this post are linked in the corresponding GitHub issue. The same issue also includes the vLLM branches used in our experiments for reproducing the reported end-to-end benchmark results.
Caveats
During our experiments, the majority of engineering time was spent on kernel autotuning. For large kernels such as scaled_mm, running a full-effort autotuning sweep across all three model sizes, covering a total of 168 distinct input shapes, can take an entire day, as Helion automatically generates and benchmarks thousands of candidate kernel implementations for each shape. Initial research suggests that exhaustive per-shape autotuning and dispatching may not always be necessary, and that reducing the number of specialization buckets may achieve a better tradeoff between autotuning cost and runtime performance with minimal performance degradation. The Helion team is actively exploring additional techniques to further reduce tuning time, including search-space reduction strategies and LLM-guided autotuning approaches.
Another caveat is that Helion runtime dispatching itself introduces tens of microseconds of CPU overhead per kernel launch. For small kernels, this overhead can dominate the end-to-end latency. As a result, CUDA graph capture and replay are essential for achieving optimal performance with Helion kernels. The Helion team is actively reducing the dispatch latency without CudaGraph mode.
Conclusion
Helion provides a natural, PyTorch-syntax-centric approach for writing kernels in a tile-programming style. It significantly simplifies kernel development and reduces implementation effort. In our experiments, most kernels could be implemented and validated within a single day, demonstrating that Helion is a practical DSL for rapidly developing new kernels and exploring kernel fusion opportunities.
Combined with its powerful AOT autotuning capability, Helion demonstrated strong potential for achieving high performance. Our experiments show that Helion kernels deliver strong performance for many kernels and consistently outperform the default vLLM implementations in most cases. For GEMM kernels, there is still room for improvement to match or exceed CUTLASS performance, particularly on Blackwell GPUs, the teams are actively working to improve it by improving Triton code gen and introducing alternative backends like CuteDSL.
Acknowledgments
This work was supported by many contributors across the OCTO and vLLM teams at Red Hat, as well as the Helion team at Meta. In particular, we would like to thank our colleagues: Luka Govedič, Richard Zou and Will Feng for their feedback and support throughout this work.