


Note
Go to the end to download the full example code.
Recurrent DQN: Training recurrent policies
Author: Vincent Moens
How to incorporating an RNN in an actor in TorchRL
How to use that memory-based policy with a replay buffer and a loss module
PyTorch v2.0.0
gym[mujoco]
tqdm
Overview
Memory-based policies are crucial not only when the observations are partially observable but also when the time dimension must be taken into account to make informed decisions.
Recurrent neural network have long been a popular tool for memory-based policies. The idea is to keep a recurrent state in memory between two consecutive steps, and use this as an input to the policy along with the current observation.
This tutorial shows how to incorporate an RNN in a policy using TorchRL.
Key learnings:
Incorporating an RNN in an actor in TorchRL;
Using that memory-based policy with a replay buffer and a loss module.
The core idea of using RNNs in TorchRL is to use TensorDict as a data carrier for the hidden states from one step to another. We’ll build a policy that reads the previous recurrent state from the current TensorDict, and writes the current recurrent states in the TensorDict of the next state:
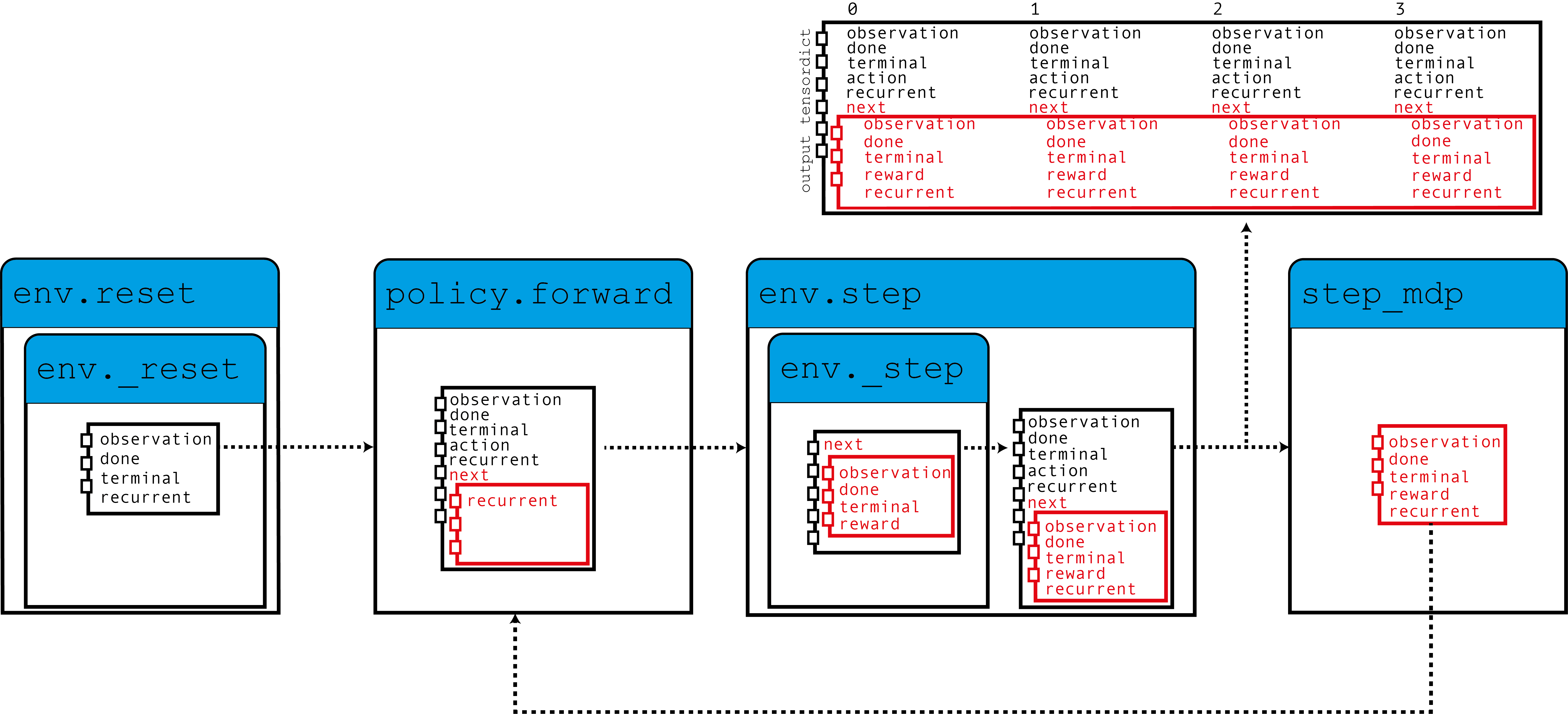
As this figure shows, our environment populates the TensorDict with zeroed recurrent
states which are read by the policy together with the observation to produce an
action, and recurrent states that will be used for the next step.
When the step_mdp() function is called, the recurrent states
from the next state are brought to the current TensorDict. Let’s see how this
is implemented in practice.
If you are running this in Google Colab, make sure you install the following dependencies:
!pip3 install torchrl
!pip3 install gym[mujoco]
!pip3 install tqdm
Setup
import torch
import tqdm
from tensordict.nn import (
TensorDictModule as Mod,
TensorDictSequential,
TensorDictSequential as Seq,
)
from torch import nn
from torchrl.collectors import SyncDataCollector
from torchrl.data import LazyMemmapStorage, TensorDictReplayBuffer
from torchrl.envs import (
Compose,
ExplorationType,
GrayScale,
InitTracker,
ObservationNorm,
Resize,
RewardScaling,
set_exploration_type,
StepCounter,
ToTensorImage,
TransformedEnv,
)
from torchrl.envs.libs.gym import GymEnv
from torchrl.modules import ConvNet, EGreedyModule, LSTMModule, MLP, QValueModule
from torchrl.objectives import DQNLoss, SoftUpdate
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
Environment
As usual, the first step is to build our environment: it helps us define the problem and build the policy network accordingly. For this tutorial, we’ll be running a single pixel-based instance of the CartPole gym environment with some custom transforms: turning to grayscale, resizing to 84x84, scaling down the rewards and normalizing the observations.
Note
The StepCounter transform is accessory. Since the CartPole
task goal is to make trajectories as long as possible, counting the steps
can help us track the performance of our policy.
Two transforms are important for the purpose of this tutorial:
InitTrackerwill stamp the calls toreset()by adding a"is_init"boolean mask in the TensorDict that will track which steps require a reset of the RNN hidden states.The
TensorDictPrimertransform is a bit more technical. It is not required to use RNN policies. However, it instructs the environment (and subsequently the collector) that some extra keys are to be expected. Once added, a call to env.reset() will populate the entries indicated in the primer with zeroed tensors. Knowing that these tensors are expected by the policy, the collector will pass them on during collection. Eventually, we’ll be storing our hidden states in the replay buffer, which will help us bootstrap the computation of the RNN operations in the loss module (which would otherwise be initiated with 0s). In summary: not including this transform will not impact hugely the training of our policy, but it will make the recurrent keys disappear from the collected data and the replay buffer, which will in turn lead to a slightly less optimal training. Fortunately, theLSTMModulewe propose is equipped with a helper method to build just that transform for us, so we can wait until we build it!
env = TransformedEnv(
GymEnv("CartPole-v1", from_pixels=True, device=device),
Compose(
ToTensorImage(),
GrayScale(),
Resize(84, 84),
StepCounter(),
InitTracker(),
RewardScaling(loc=0.0, scale=0.1),
ObservationNorm(standard_normal=True, in_keys=["pixels"]),
),
)
As always, we need to initialize manually our normalization constants:
env.transform[-1].init_stats(1000, reduce_dim=[0, 1, 2], cat_dim=0, keep_dims=[0])
td = env.reset()
Policy
Our policy will have 3 components: a ConvNet
backbone, an LSTMModule memory layer and a shallow
MLP block that will map the LSTM output onto the
action values.
Convolutional network
We build a convolutional network flanked with a torch.nn.AdaptiveAvgPool2d
that will squash the output in a vector of size 64. The ConvNet
can assist us with this:
feature = Mod(
ConvNet(
num_cells=[32, 32, 64],
squeeze_output=True,
aggregator_class=nn.AdaptiveAvgPool2d,
aggregator_kwargs={"output_size": (1, 1)},
device=device,
),
in_keys=["pixels"],
out_keys=["embed"],
)
we execute the first module on a batch of data to gather the size of the output vector:
n_cells = feature(env.reset())["embed"].shape[-1]
LSTM Module
TorchRL provides a specialized LSTMModule class
to incorporate LSTMs in your code-base. It is a TensorDictModuleBase
subclass: as such, it has a set of in_keys and out_keys that indicate
what values should be expected to be read and written/updated during the
execution of the module. The class comes with customizable predefined
values for these attributes to facilitate its construction.
Note
Usage limitations: The class supports almost all LSTM features such as
dropout or multi-layered LSTMs.
However, to respect TorchRL’s conventions, this LSTM must have the batch_first
attribute set to True which is not the default in PyTorch. However,
our LSTMModule changes this default
behavior, so we’re good with a native call.
Also, the LSTM cannot have a bidirectional attribute set to True as
this wouldn’t be usable in online settings. In this case, the default value
is the correct one.
lstm = LSTMModule(
input_size=n_cells,
hidden_size=128,
device=device,
in_key="embed",
out_key="embed",
)
Let us look at the LSTM Module class, specifically its in and out_keys:
print("in_keys", lstm.in_keys)
print("out_keys", lstm.out_keys)
in_keys ['embed', 'recurrent_state_h', 'recurrent_state_c', 'is_init']
out_keys ['embed', ('next', 'recurrent_state_h'), ('next', 'recurrent_state_c')]
We can see that these values contain the key we indicated as the in_key (and out_key)
as well as recurrent key names. The out_keys are preceded by a “next” prefix
that indicates that they will need to be written in the “next” TensorDict.
We use this convention (which can be overridden by passing the in_keys/out_keys
arguments) to make sure that a call to step_mdp() will
move the recurrent state to the root TensorDict, making it available to the
RNN during the following call (see figure in the intro).
As mentioned earlier, we have one more optional transform to add to our
environment to make sure that the recurrent states are passed to the buffer.
The make_tensordict_primer() method does
exactly that:
env.append_transform(lstm.make_tensordict_primer())
TransformedEnv(
env=GymEnv(env=CartPole-v1, batch_size=torch.Size([]), device=cpu),
transform=Compose(
ToTensorImage(keys=['pixels']),
GrayScale(keys=['pixels']),
Resize(w=84, h=84, interpolation=InterpolationMode.BILINEAR, keys=['pixels']),
StepCounter(keys=[]),
InitTracker(keys=[]),
RewardScaling(loc=0.0000, scale=0.1000, keys=['reward']),
ObservationNorm(keys=['pixels']),
TensorDictPrimer(primers=CompositeSpec(
recurrent_state_h: UnboundedContinuousTensorSpec(
shape=torch.Size([1, 128]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous),
recurrent_state_c: UnboundedContinuousTensorSpec(
shape=torch.Size([1, 128]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous), device=cpu, shape=torch.Size([])), default_value={'recurrent_state_h': 0.0, 'recurrent_state_c': 0.0}, random=None)))
and that’s it! We can print the environment to check that everything looks good now that we have added the primer:
print(env)
TransformedEnv(
env=GymEnv(env=CartPole-v1, batch_size=torch.Size([]), device=cpu),
transform=Compose(
ToTensorImage(keys=['pixels']),
GrayScale(keys=['pixels']),
Resize(w=84, h=84, interpolation=InterpolationMode.BILINEAR, keys=['pixels']),
StepCounter(keys=[]),
InitTracker(keys=[]),
RewardScaling(loc=0.0000, scale=0.1000, keys=['reward']),
ObservationNorm(keys=['pixels']),
TensorDictPrimer(primers=CompositeSpec(
recurrent_state_h: UnboundedContinuousTensorSpec(
shape=torch.Size([1, 128]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous),
recurrent_state_c: UnboundedContinuousTensorSpec(
shape=torch.Size([1, 128]),
space=None,
device=cpu,
dtype=torch.float32,
domain=continuous), device=cpu, shape=torch.Size([])), default_value={'recurrent_state_h': 0.0, 'recurrent_state_c': 0.0}, random=None)))
MLP
We use a single-layer MLP to represent the action values we’ll be using for our policy.
and fill the bias with zeros:
mlp[-1].bias.data.fill_(0.0)
mlp = Mod(mlp, in_keys=["embed"], out_keys=["action_value"])
Using the Q-Values to select an action
The last part of our policy is the Q-Value Module.
The Q-Value module QValueModule
will read the "action_values" key that is produced by our MLP and
from it, gather the action that has the maximum value.
The only thing we need to do is to specify the action space, which can be done
either by passing a string or an action-spec. This allows us to use
Categorical (sometimes called “sparse”) encoding or the one-hot version of it.
qval = QValueModule(action_space=None, spec=env.action_spec)
Note
TorchRL also provides a wrapper class torchrl.modules.QValueActor that
wraps a module in a Sequential together with a QValueModule
like we are doing explicitly here. There is little advantage to do this
and the process is less transparent, but the end results will be similar to
what we do here.
We can now put things together in a TensorDictSequential
stoch_policy = Seq(feature, lstm, mlp, qval)
DQN being a deterministic algorithm, exploration is a crucial part of it.
We’ll be using an step()
(see training loop below).
exploration_module = EGreedyModule(
annealing_num_steps=1_000_000, spec=env.action_spec, eps_init=0.2
)
stoch_policy = TensorDictSequential(
stoch_policy,
exploration_module,
)
Using the model for the loss
The model as we’ve built it is well equipped to be used in sequential settings.
However, the class torch.nn.LSTM can use a cuDNN-optimized backend
to run the RNN sequence faster on GPU device. We would not want to miss
such an opportunity to speed up our training loop!
To use it, we just need to tell the LSTM module to run on “recurrent-mode”
when used by the loss.
As we’ll usually want to have two copies of the LSTM module, we do this by
calling a set_recurrent_mode() method that
will return a new instance of the LSTM (with shared weights) that will
assume that the input data is sequential in nature.
policy = Seq(feature, lstm.set_recurrent_mode(True), mlp, qval)
Because we still have a couple of uninitialized parameters we should initialize them before creating an optimizer and such.
policy(env.reset())
TensorDict(
fields={
action: Tensor(shape=torch.Size([2]), device=cpu, dtype=torch.int64, is_shared=False),
action_value: Tensor(shape=torch.Size([2]), device=cpu, dtype=torch.float32, is_shared=False),
chosen_action_value: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.float32, is_shared=False),
done: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
embed: Tensor(shape=torch.Size([128]), device=cpu, dtype=torch.float32, is_shared=False),
is_init: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
recurrent_state_c: Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_h: Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False),
pixels: Tensor(shape=torch.Size([1, 84, 84]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_c: Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_h: Tensor(shape=torch.Size([1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([]),
device=cpu,
is_shared=False)
DQN Loss
Out DQN loss requires us to pass the policy and, again, the action-space.
While this may seem redundant, it is important as we want to make sure that
the DQNLoss and the QValueModule
classes are compatible, but aren’t strongly dependent on each other.
To use the Double-DQN, we ask for a delay_value argument that will
create a non-differentiable copy of the network parameters to be used
as a target network.
loss_fn = DQNLoss(policy, action_space=env.action_spec, delay_value=True)
Since we are using a double DQN, we need to update the target parameters.
We’ll use a SoftUpdate instance to carry out
this work.
updater = SoftUpdate(loss_fn, eps=0.95)
optim = torch.optim.Adam(policy.parameters(), lr=3e-4)
Collector and replay buffer
We build the simplest data collector there is. We’ll try to train our algorithm
with a million frames, extending the buffer with 50 frames at a time. The buffer
will be designed to store 20 thousands trajectories of 50 steps each.
At each optimization step (16 per data collection), we’ll collect 4 items
from our buffer, for a total of 200 transitions.
We’ll use a LazyMemmapStorage storage to keep the data
on disk.
Note
For the sake of efficiency, we’re only running a few thousands iterations here. In a real setting, the total number of frames should be set to 1M.
collector = SyncDataCollector(env, stoch_policy, frames_per_batch=50, total_frames=200)
rb = TensorDictReplayBuffer(
storage=LazyMemmapStorage(20_000), batch_size=4, prefetch=10
)
Training loop
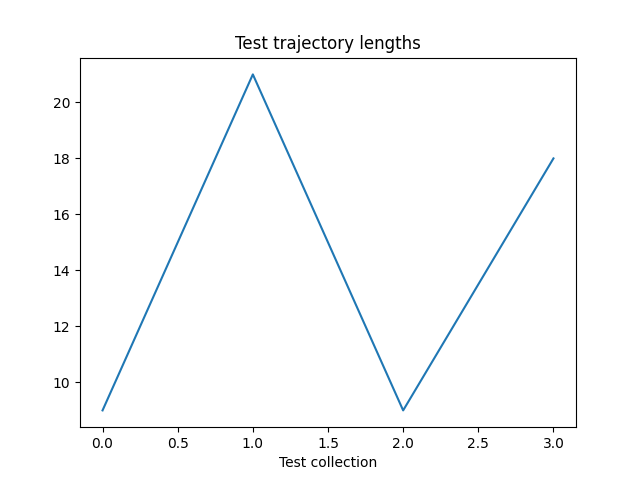
To keep track of the progress, we will run the policy in the environment once every 50 data collection, and plot the results after training.
utd = 16
pbar = tqdm.tqdm(total=collector.total_frames)
longest = 0
traj_lens = []
for i, data in enumerate(collector):
if i == 0:
print(
"Let us print the first batch of data.\nPay attention to the key names "
"which will reflect what can be found in this data structure, in particular: "
"the output of the QValueModule (action_values, action and chosen_action_value),"
"the 'is_init' key that will tell us if a step is initial or not, and the "
"recurrent_state keys.\n",
data,
)
pbar.update(data.numel())
# it is important to pass data that is not flattened
rb.extend(data.unsqueeze(0).to_tensordict().cpu())
for _ in range(utd):
s = rb.sample().to(device, non_blocking=True)
loss_vals = loss_fn(s)
loss_vals["loss"].backward()
optim.step()
optim.zero_grad()
longest = max(longest, data["step_count"].max().item())
pbar.set_description(
f"steps: {longest}, loss_val: {loss_vals['loss'].item(): 4.4f}, action_spread: {data['action'].sum(0)}"
)
exploration_module.step(data.numel())
updater.step()
with set_exploration_type(ExplorationType.MODE), torch.no_grad():
rollout = env.rollout(10000, stoch_policy)
traj_lens.append(rollout.get(("next", "step_count")).max().item())
0%| | 0/200 [00:00<?, ?it/s]Let us print the first batch of data.
Pay attention to the key names which will reflect what can be found in this data structure, in particular: the output of the QValueModule (action_values, action and chosen_action_value),the 'is_init' key that will tell us if a step is initial or not, and the recurrent_state keys.
TensorDict(
fields={
action: Tensor(shape=torch.Size([50, 2]), device=cpu, dtype=torch.int64, is_shared=False),
action_value: Tensor(shape=torch.Size([50, 2]), device=cpu, dtype=torch.float32, is_shared=False),
chosen_action_value: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.float32, is_shared=False),
collector: TensorDict(
fields={
traj_ids: Tensor(shape=torch.Size([50]), device=cpu, dtype=torch.int64, is_shared=False)},
batch_size=torch.Size([50]),
device=None,
is_shared=False),
done: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
embed: Tensor(shape=torch.Size([50, 128]), device=cpu, dtype=torch.float32, is_shared=False),
is_init: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
next: TensorDict(
fields={
done: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
is_init: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
pixels: Tensor(shape=torch.Size([50, 1, 84, 84]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_c: Tensor(shape=torch.Size([50, 1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_h: Tensor(shape=torch.Size([50, 1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
reward: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([50]),
device=None,
is_shared=False),
pixels: Tensor(shape=torch.Size([50, 1, 84, 84]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_c: Tensor(shape=torch.Size([50, 1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
recurrent_state_h: Tensor(shape=torch.Size([50, 1, 128]), device=cpu, dtype=torch.float32, is_shared=False),
step_count: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.int64, is_shared=False),
terminated: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False),
truncated: Tensor(shape=torch.Size([50, 1]), device=cpu, dtype=torch.bool, is_shared=False)},
batch_size=torch.Size([50]),
device=None,
is_shared=False)
25%|██▌ | 50/200 [00:00<00:01, 135.42it/s]
steps: 11, loss_val: 0.0006, action_spread: tensor([47, 3]): 25%|██▌ | 50/200 [00:19<00:01, 135.42it/s]
steps: 11, loss_val: 0.0006, action_spread: tensor([47, 3]): 25%|██▌ | 50/200 [00:19<00:01, 135.42it/s]
steps: 11, loss_val: 0.0006, action_spread: tensor([47, 3]): 50%|█████ | 100/200 [00:20<00:23, 4.27it/s]
steps: 12, loss_val: 0.0004, action_spread: tensor([43, 7]): 50%|█████ | 100/200 [00:38<00:23, 4.27it/s]
steps: 12, loss_val: 0.0004, action_spread: tensor([43, 7]): 75%|███████▌ | 150/200 [00:39<00:15, 3.28it/s]
steps: 26, loss_val: 0.0004, action_spread: tensor([13, 37]): 75%|███████▌ | 150/200 [00:58<00:15, 3.28it/s]
steps: 26, loss_val: 0.0004, action_spread: tensor([13, 37]): 100%|██████████| 200/200 [00:59<00:00, 2.95it/s]
steps: 27, loss_val: 0.0004, action_spread: tensor([43, 7]): 100%|██████████| 200/200 [01:18<00:00, 2.95it/s]
Let’s plot our results:
if traj_lens:
from matplotlib import pyplot as plt
plt.plot(traj_lens)
plt.xlabel("Test collection")
plt.title("Test trajectory lengths")
Conclusion
We have seen how an RNN can be incorporated in a policy in TorchRL. You should now be able:
Create an LSTM module that acts as a
TensorDictModuleIndicate to the LSTM module that a reset is needed via an
InitTrackertransformIncorporate this module in a policy and in a loss module
Make sure that the collector is made aware of the recurrent state entries such that they can be stored in the replay buffer along with the rest of the data
Further Reading
The TorchRL documentation can be found here.
Total running time of the script: (2 minutes 15.835 seconds)
Estimated memory usage: 1897 MB
