


Note
Go to the end to download the full example code.
TorchRL objectives: Coding a DDPG loss
Author: Vincent Moens
Overview
TorchRL separates the training of RL sota-implementations in various pieces that will be assembled in your training script: the environment, the data collection and storage, the model and finally the loss function.
TorchRL losses (or “objectives”) are stateful objects that contain the trainable parameters (policy and value models). This tutorial will guide you through the steps to code a loss from the ground up using TorchRL.
To this aim, we will be focusing on DDPG, which is a relatively straightforward algorithm to code. Deep Deterministic Policy Gradient (DDPG) is a simple continuous control algorithm. It consists in learning a parametric value function for an action-observation pair, and then learning a policy that outputs actions that maximize this value function given a certain observation.
What you will learn:
how to write a loss module and customize its value estimator;
how to build an environment in TorchRL, including transforms (for example, data normalization) and parallel execution;
how to design a policy and value network;
how to collect data from your environment efficiently and store them in a replay buffer;
how to store trajectories (and not transitions) in your replay buffer);
how to evaluate your model.
Prerequisites
This tutorial assumes that you have completed the
PPO tutorial which gives
an overview of the TorchRL components and dependencies, such as
tensordict.TensorDict and tensordict.nn.TensorDictModules,
although it should be
sufficiently transparent to be understood without a deep understanding of
these classes.
Note
We do not aim at giving a SOTA implementation of the algorithm, but rather to provide a high-level illustration of TorchRL’s loss implementations and the library features that are to be used in the context of this algorithm.
Imports and setup
%%bash pip3 install torchrl mujoco glfw
import torch
import tqdm
We will execute the policy on CUDA if available
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
collector_device = torch.device("cpu") # Change the device to ``cuda`` to use CUDA
TorchRL LossModule
TorchRL provides a series of losses to use in your training scripts. The aim is to have losses that are easily reusable/swappable and that have a simple signature.
The main characteristics of TorchRL losses are:
They are stateful objects: they contain a copy of the trainable parameters such that
loss_module.parameters()gives whatever is needed to train the algorithm.They follow the
TensorDictconvention: thetorch.nn.Module.forward()method will receive a TensorDict as input that contains all the necessary information to return a loss value.>>> data = replay_buffer.sample() >>> loss_dict = loss_module(data)
They output a
tensordict.TensorDictinstance with the loss values written under a"loss_<smth>"wheresmthis a string describing the loss. Additional keys in theTensorDictmay be useful metrics to log during training time.Note
The reason we return independent losses is to let the user use a different optimizer for different sets of parameters for instance. Summing the losses can be simply done via
>>> loss_val = sum(loss for key, loss in loss_dict.items() if key.startswith("loss_"))
The __init__ method
The parent class of all losses is LossModule.
As many other components of the library, its forward() method expects
as input a tensordict.TensorDict instance sampled from an experience
replay buffer, or any similar data structure. Using this format makes it
possible to re-use the module across
modalities, or in complex settings where the model needs to read multiple
entries for instance. In other words, it allows us to code a loss module that
is oblivious to the data type that is being given to is and that focuses on
running the elementary steps of the loss function and only those.
To keep the tutorial as didactic as we can, we’ll be displaying each method of the class independently and we’ll be populating the class at a later stage.
Let us start with the __init__()
method. DDPG aims at solving a control task with a simple strategy:
training a policy to output actions that maximize the value predicted by
a value network. Hence, our loss module needs to receive two networks in its
constructor: an actor and a value networks. We expect both of these to be
TensorDict-compatible objects, such as
tensordict.nn.TensorDictModule.
Our loss function will need to compute a target value and fit the value
network to this, and generate an action and fit the policy such that its
value estimate is maximized.
The crucial step of the LossModule.__init__() method is the call to
convert_to_functional(). This method will extract
the parameters from the module and convert it to a functional module.
Strictly speaking, this is not necessary and one may perfectly code all
the losses without it. However, we encourage its usage for the following
reason.
The reason TorchRL does this is that RL sota-implementations often execute the same
model with different sets of parameters, called “trainable” and “target”
parameters.
The “trainable” parameters are those that the optimizer needs to fit. The
“target” parameters are usually a copy of the former’s with some time lag
(absolute or diluted through a moving average).
These target parameters are used to compute the value associated with the
next observation. One the advantages of using a set of target parameters
for the value model that do not match exactly the current configuration is
that they provide a pessimistic bound on the value function being computed.
Pay attention to the create_target_params keyword argument below: this
argument tells the convert_to_functional()
method to create a set of target parameters in the loss module to be used
for target value computation. If this is set to False (see the actor network
for instance) the target_actor_network_params attribute will still be
accessible but this will just return a detached version of the
actor parameters.
Later, we will see how the target parameters should be updated in TorchRL.
from tensordict.nn import TensorDictModule
def _init(
self,
actor_network: TensorDictModule,
value_network: TensorDictModule,
) -> None:
super(type(self), self).__init__()
self.convert_to_functional(
actor_network,
"actor_network",
create_target_params=True,
)
self.convert_to_functional(
value_network,
"value_network",
create_target_params=True,
compare_against=list(actor_network.parameters()),
)
self.actor_in_keys = actor_network.in_keys
# Since the value we'll be using is based on the actor and value network,
# we put them together in a single actor-critic container.
actor_critic = ActorCriticWrapper(actor_network, value_network)
self.actor_critic = actor_critic
self.loss_function = "l2"
The value estimator loss method
In many RL algorithm, the value network (or Q-value network) is trained based
on an empirical value estimate. This can be bootstrapped (TD(0), low
variance, high bias), meaning
that the target value is obtained using the next reward and nothing else, or
a Monte-Carlo estimate can be obtained (TD(1)) in which case the whole
sequence of upcoming rewards will be used (high variance, low bias). An
intermediate estimator (TD(ValueEstimators Enum class, which contains
pointers to all the value estimators implemented. Let us define the default
value function here. We will take the simplest version (TD(0)), and show later
on how this can be changed.
from torchrl.objectives.utils import ValueEstimators
default_value_estimator = ValueEstimators.TD0
We also need to give some instructions to DDPG on how to build the value estimator, depending on the user query. Depending on the estimator provided, we will build the corresponding module to be used at train time:
from torchrl.objectives.utils import default_value_kwargs
from torchrl.objectives.value import TD0Estimator, TD1Estimator, TDLambdaEstimator
def make_value_estimator(self, value_type: ValueEstimators, **hyperparams):
hp = dict(default_value_kwargs(value_type))
if hasattr(self, "gamma"):
hp["gamma"] = self.gamma
hp.update(hyperparams)
value_key = "state_action_value"
if value_type == ValueEstimators.TD1:
self._value_estimator = TD1Estimator(value_network=self.actor_critic, **hp)
elif value_type == ValueEstimators.TD0:
self._value_estimator = TD0Estimator(value_network=self.actor_critic, **hp)
elif value_type == ValueEstimators.GAE:
raise NotImplementedError(
f"Value type {value_type} it not implemented for loss {type(self)}."
)
elif value_type == ValueEstimators.TDLambda:
self._value_estimator = TDLambdaEstimator(value_network=self.actor_critic, **hp)
else:
raise NotImplementedError(f"Unknown value type {value_type}")
self._value_estimator.set_keys(value=value_key)
The make_value_estimator method can but does not need to be called: ifgg
not, the LossModule will query this method with
its default estimator.
The actor loss method
The central piece of an RL algorithm is the training loss for the actor. In the case of DDPG, this function is quite simple: we just need to compute the value associated with an action computed using the policy and optimize the actor weights to maximize this value.
When computing this value, we must make sure to take the value parameters out
of the graph, otherwise the actor and value loss will be mixed up.
For this, the hold_out_params() function
can be used.
def _loss_actor(
self,
tensordict,
) -> torch.Tensor:
td_copy = tensordict.select(*self.actor_in_keys)
# Get an action from the actor network: since we made it functional, we need to pass the params
with self.actor_network_params.to_module(self.actor_network):
td_copy = self.actor_network(td_copy)
# get the value associated with that action
with self.value_network_params.detach().to_module(self.value_network):
td_copy = self.value_network(td_copy)
return -td_copy.get("state_action_value")
The value loss method
We now need to optimize our value network parameters. To do this, we will rely on the value estimator of our class:
from torchrl.objectives.utils import distance_loss
def _loss_value(
self,
tensordict,
):
td_copy = tensordict.clone()
# V(s, a)
with self.value_network_params.to_module(self.value_network):
self.value_network(td_copy)
pred_val = td_copy.get("state_action_value").squeeze(-1)
# we manually reconstruct the parameters of the actor-critic, where the first
# set of parameters belongs to the actor and the second to the value function.
target_params = TensorDict(
{
"module": {
"0": self.target_actor_network_params,
"1": self.target_value_network_params,
}
},
batch_size=self.target_actor_network_params.batch_size,
device=self.target_actor_network_params.device,
)
with target_params.to_module(self.actor_critic):
target_value = self.value_estimator.value_estimate(tensordict).squeeze(-1)
# Computes the value loss: L2, L1 or smooth L1 depending on `self.loss_function`
loss_value = distance_loss(pred_val, target_value, loss_function=self.loss_function)
td_error = (pred_val - target_value).pow(2)
return loss_value, td_error, pred_val, target_value
Putting things together in a forward call
The only missing piece is the forward method, which will glue together the
value and actor loss, collect the cost values and write them in a TensorDict
delivered to the user.
from tensordict import TensorDict, TensorDictBase
def _forward(self, input_tensordict: TensorDictBase) -> TensorDict:
loss_value, td_error, pred_val, target_value = self.loss_value(
input_tensordict,
)
td_error = td_error.detach()
td_error = td_error.unsqueeze(input_tensordict.ndimension())
if input_tensordict.device is not None:
td_error = td_error.to(input_tensordict.device)
input_tensordict.set(
"td_error",
td_error,
inplace=True,
)
loss_actor = self.loss_actor(input_tensordict)
return TensorDict(
source={
"loss_actor": loss_actor.mean(),
"loss_value": loss_value.mean(),
"pred_value": pred_val.mean().detach(),
"target_value": target_value.mean().detach(),
"pred_value_max": pred_val.max().detach(),
"target_value_max": target_value.max().detach(),
},
batch_size=[],
)
from torchrl.objectives import LossModule
class DDPGLoss(LossModule):
default_value_estimator = default_value_estimator
make_value_estimator = make_value_estimator
__init__ = _init
forward = _forward
loss_value = _loss_value
loss_actor = _loss_actor
Now that we have our loss, we can use it to train a policy to solve a control task.
Environment
In most sota-implementations, the first thing that needs to be taken care of is the construction of the environment as it conditions the remainder of the training script.
For this example, we will be using the "cheetah" task. The goal is to make
a half-cheetah run as fast as possible.
In TorchRL, one can create such a task by relying on dm_control or gym:
env = GymEnv("HalfCheetah-v4")
or
env = DMControlEnv("cheetah", "run")
By default, these environment disable rendering. Training from states is
usually easier than training from images. To keep things simple, we focus
on learning from states only. To pass the pixels to the tensordicts that
are collected by env.step(), simply pass the from_pixels=True
argument to the constructor:
env = GymEnv("HalfCheetah-v4", from_pixels=True, pixels_only=True)
We write a make_env() helper function that will create an environment
with either one of the two backends considered above (dm-control or gym).
from torchrl.envs.libs.dm_control import DMControlEnv
from torchrl.envs.libs.gym import GymEnv
env_library = None
env_name = None
def make_env(from_pixels=False):
"""Create a base ``env``."""
global env_library
global env_name
if backend == "dm_control":
env_name = "cheetah"
env_task = "run"
env_args = (env_name, env_task)
env_library = DMControlEnv
elif backend == "gym":
env_name = "HalfCheetah-v4"
env_args = (env_name,)
env_library = GymEnv
else:
raise NotImplementedError
env_kwargs = {
"device": device,
"from_pixels": from_pixels,
"pixels_only": from_pixels,
"frame_skip": 2,
}
env = env_library(*env_args, **env_kwargs)
return env
Transforms
Now that we have a base environment, we may want to modify its representation
to make it more policy-friendly. In TorchRL, transforms are appended to the
base environment in a specialized torchr.envs.TransformedEnv class.
It is common in DDPG to rescale the reward using some heuristic value. We will multiply the reward by 5 in this example.
If we are using
dm_control, it is also important to build an interface between the simulator which works with double precision numbers, and our script which presumably uses single precision ones. This transformation goes both ways: when callingenv.step(), our actions will need to be represented in double precision, and the output will need to be transformed to single precision. TheDoubleToFloattransform does exactly this: thein_keyslist refers to the keys that will need to be transformed from double to float, while thein_keys_invrefers to those that need to be transformed to double before being passed to the environment.We concatenate the state keys together using the
CatTensorstransform.Finally, we also leave the possibility of normalizing the states: we will take care of computing the normalizing constants later on.
from torchrl.envs import (
CatTensors,
DoubleToFloat,
EnvCreator,
InitTracker,
ObservationNorm,
ParallelEnv,
RewardScaling,
StepCounter,
TransformedEnv,
)
def make_transformed_env(
env,
):
"""Apply transforms to the ``env`` (such as reward scaling and state normalization)."""
env = TransformedEnv(env)
# we append transforms one by one, although we might as well create the
# transformed environment using the `env = TransformedEnv(base_env, transforms)`
# syntax.
env.append_transform(RewardScaling(loc=0.0, scale=reward_scaling))
# We concatenate all states into a single "observation_vector"
# even if there is a single tensor, it'll be renamed in "observation_vector".
# This facilitates the downstream operations as we know the name of the
# output tensor.
# In some environments (not half-cheetah), there may be more than one
# observation vector: in this case this code snippet will concatenate them
# all.
selected_keys = list(env.observation_spec.keys())
out_key = "observation_vector"
env.append_transform(CatTensors(in_keys=selected_keys, out_key=out_key))
# we normalize the states, but for now let's just instantiate a stateless
# version of the transform
env.append_transform(ObservationNorm(in_keys=[out_key], standard_normal=True))
env.append_transform(DoubleToFloat())
env.append_transform(StepCounter(max_frames_per_traj))
# We need a marker for the start of trajectories for our Ornstein-Uhlenbeck (OU)
# exploration:
env.append_transform(InitTracker())
return env
Parallel execution
The following helper function allows us to run environments in parallel. Running environments in parallel can significantly speed up the collection throughput. When using transformed environment, we need to choose whether we want to execute the transform individually for each environment, or centralize the data and transform it in batch. Both approaches are easy to code:
env = ParallelEnv(
lambda: TransformedEnv(GymEnv("HalfCheetah-v4"), transforms),
num_workers=4
)
env = TransformedEnv(
ParallelEnv(lambda: GymEnv("HalfCheetah-v4"), num_workers=4),
transforms
)
To leverage the vectorization capabilities of PyTorch, we adopt the first method:
def parallel_env_constructor(
env_per_collector,
transform_state_dict,
):
if env_per_collector == 1:
def make_t_env():
env = make_transformed_env(make_env())
env.transform[2].init_stats(3)
env.transform[2].loc.copy_(transform_state_dict["loc"])
env.transform[2].scale.copy_(transform_state_dict["scale"])
return env
env_creator = EnvCreator(make_t_env)
return env_creator
parallel_env = ParallelEnv(
num_workers=env_per_collector,
create_env_fn=EnvCreator(lambda: make_env()),
create_env_kwargs=None,
pin_memory=False,
)
env = make_transformed_env(parallel_env)
# we call `init_stats` for a limited number of steps, just to instantiate
# the lazy buffers.
env.transform[2].init_stats(3, cat_dim=1, reduce_dim=[0, 1])
env.transform[2].load_state_dict(transform_state_dict)
return env
# The backend can be ``gym`` or ``dm_control``
backend = "gym"
Note
frame_skip batches multiple step together with a single action
If > 1, the other frame counts (for example, frames_per_batch, total_frames)
need to be adjusted to have a consistent total number of frames collected
across experiments. This is important as raising the frame-skip but keeping the
total number of frames unchanged may seem like cheating: all things compared,
a dataset of 10M elements collected with a frame-skip of 2 and another with
a frame-skip of 1 actually have a ratio of interactions with the environment
of 2:1! In a nutshell, one should be cautious about the frame-count of a
training script when dealing with frame skipping as this may lead to
biased comparisons between training strategies.
Scaling the reward helps us control the signal magnitude for a more efficient learning.
reward_scaling = 5.0
We also define when a trajectory will be truncated. A thousand steps (500 if frame-skip = 2) is a good number to use for the cheetah task:
max_frames_per_traj = 500
Normalization of the observations
To compute the normalizing statistics, we run an arbitrary number of random
steps in the environment and compute the mean and standard deviation of the
collected observations. The ObservationNorm.init_stats() method can
be used for this purpose. To get the summary statistics, we create a dummy
environment and run it for a given number of steps, collect data over a given
number of steps and compute its summary statistics.
def get_env_stats():
"""Gets the stats of an environment."""
proof_env = make_transformed_env(make_env())
t = proof_env.transform[2]
t.init_stats(init_env_steps)
transform_state_dict = t.state_dict()
proof_env.close()
return transform_state_dict
Normalization stats
Number of random steps used as for stats computation using ObservationNorm
init_env_steps = 5000
transform_state_dict = get_env_stats()
Number of environments in each data collector
env_per_collector = 4
We pass the stats computed earlier to normalize the output of our environment:
parallel_env = parallel_env_constructor(
env_per_collector=env_per_collector,
transform_state_dict=transform_state_dict,
)
from torchrl.data import CompositeSpec
Building the model
We now turn to the setup of the model. As we have seen, DDPG requires a value network, trained to estimate the value of a state-action pair, and a parametric actor that learns how to select actions that maximize this value.
Recall that building a TorchRL module requires two steps:
writing the
torch.nn.Modulethat will be used as network,wrapping the network in a
tensordict.nn.TensorDictModulewhere the data flow is handled by specifying the input and output keys.
In more complex scenarios, tensordict.nn.TensorDictSequential can
also be used.
The Q-Value network is wrapped in a ValueOperator
that automatically sets the out_keys to "state_action_value for q-value
networks and state_value for other value networks.
TorchRL provides a built-in version of the DDPG networks as presented in the
original paper. These can be found under DdpgMlpActor
and DdpgMlpQNet.
Since we use lazy modules, it is necessary to materialize the lazy modules before being able to move the policy from device to device and achieve other operations. Hence, it is good practice to run the modules with a small sample of data. For this purpose, we generate fake data from the environment specs.
from torchrl.modules import (
ActorCriticWrapper,
DdpgMlpActor,
DdpgMlpQNet,
OrnsteinUhlenbeckProcessWrapper,
ProbabilisticActor,
TanhDelta,
ValueOperator,
)
def make_ddpg_actor(
transform_state_dict,
device="cpu",
):
proof_environment = make_transformed_env(make_env())
proof_environment.transform[2].init_stats(3)
proof_environment.transform[2].load_state_dict(transform_state_dict)
out_features = proof_environment.action_spec.shape[-1]
actor_net = DdpgMlpActor(
action_dim=out_features,
)
in_keys = ["observation_vector"]
out_keys = ["param"]
actor = TensorDictModule(
actor_net,
in_keys=in_keys,
out_keys=out_keys,
)
actor = ProbabilisticActor(
actor,
distribution_class=TanhDelta,
in_keys=["param"],
spec=CompositeSpec(action=proof_environment.action_spec),
).to(device)
q_net = DdpgMlpQNet()
in_keys = in_keys + ["action"]
qnet = ValueOperator(
in_keys=in_keys,
module=q_net,
).to(device)
# initialize lazy modules
qnet(actor(proof_environment.reset().to(device)))
return actor, qnet
actor, qnet = make_ddpg_actor(
transform_state_dict=transform_state_dict,
device=device,
)
Exploration
The policy is wrapped in a OrnsteinUhlenbeckProcessWrapper
exploration module, as suggested in the original paper.
Let’s define the number of frames before OU noise reaches its minimum value
annealing_frames = 1_000_000
actor_model_explore = OrnsteinUhlenbeckProcessWrapper(
actor,
annealing_num_steps=annealing_frames,
).to(device)
if device == torch.device("cpu"):
actor_model_explore.share_memory()
Data collector
TorchRL provides specialized classes to help you collect data by executing the policy in the environment. These “data collectors” iteratively compute the action to be executed at a given time, then execute a step in the environment and reset it when required. Data collectors are designed to help developers have a tight control on the number of frames per batch of data, on the (a)sync nature of this collection and on the resources allocated to the data collection (for example GPU, number of workers, and so on).
Here we will use
SyncDataCollector, a simple, single-process
data collector. TorchRL offers other collectors, such as
MultiaSyncDataCollector, which executed the
rollouts in an asynchronous manner (for example, data will be collected while
the policy is being optimized, thereby decoupling the training and
data collection).
The parameters to specify are:
an environment factory or an environment,
the policy,
the total number of frames before the collector is considered empty,
the maximum number of frames per trajectory (useful for non-terminating environments, like
dm_controlones).Note
The
max_frames_per_trajpassed to the collector will have the effect of registering a newStepCountertransform with the environment used for inference. We can achieve the same result manually, as we do in this script.
One should also pass:
the number of frames in each batch collected,
the number of random steps executed independently from the policy,
the devices used for policy execution
the devices used to store data before the data is passed to the main process.
The total frames we will use during training should be around 1M.
total_frames = 10_000 # 1_000_000
The number of frames returned by the collector at each iteration of the outer loop is equal to the length of each sub-trajectories times the number of environments run in parallel in each collector.
In other words, we expect batches from the collector to have a shape
[env_per_collector, traj_len] where
traj_len=frames_per_batch/env_per_collector:
traj_len = 200
frames_per_batch = env_per_collector * traj_len
init_random_frames = 5000
num_collectors = 2
from torchrl.collectors import SyncDataCollector
from torchrl.envs import ExplorationType
collector = SyncDataCollector(
parallel_env,
policy=actor_model_explore,
total_frames=total_frames,
frames_per_batch=frames_per_batch,
init_random_frames=init_random_frames,
reset_at_each_iter=False,
split_trajs=False,
device=collector_device,
exploration_type=ExplorationType.RANDOM,
)
Evaluator: building your recorder object
As the training data is obtained using some exploration strategy, the true
performance of our algorithm needs to be assessed in deterministic mode. We
do this using a dedicated class, Recorder, which executes the policy in
the environment at a given frequency and returns some statistics obtained
from these simulations.
The following helper function builds this object:
from torchrl.trainers import Recorder
def make_recorder(actor_model_explore, transform_state_dict, record_interval):
base_env = make_env()
environment = make_transformed_env(base_env)
environment.transform[2].init_stats(
3
) # must be instantiated to load the state dict
environment.transform[2].load_state_dict(transform_state_dict)
recorder_obj = Recorder(
record_frames=1000,
policy_exploration=actor_model_explore,
environment=environment,
exploration_type=ExplorationType.MEAN,
record_interval=record_interval,
)
return recorder_obj
We will be recording the performance every 10 batch collected
record_interval = 10
recorder = make_recorder(
actor_model_explore, transform_state_dict, record_interval=record_interval
)
from torchrl.data.replay_buffers import (
LazyMemmapStorage,
PrioritizedSampler,
RandomSampler,
TensorDictReplayBuffer,
)
Replay buffer
Replay buffers come in two flavors: prioritized (where some error signal is used to give a higher likelihood of sampling to some items than others) and regular, circular experience replay.
TorchRL replay buffers are composable: one can pick up the storage, sampling and writing strategies. It is also possible to store tensors on physical memory using a memory-mapped array. The following function takes care of creating the replay buffer with the desired hyperparameters:
from torchrl.envs import RandomCropTensorDict
def make_replay_buffer(buffer_size, batch_size, random_crop_len, prefetch=3, prb=False):
if prb:
sampler = PrioritizedSampler(
max_capacity=buffer_size,
alpha=0.7,
beta=0.5,
)
else:
sampler = RandomSampler()
replay_buffer = TensorDictReplayBuffer(
storage=LazyMemmapStorage(
buffer_size,
scratch_dir=buffer_scratch_dir,
),
batch_size=batch_size,
sampler=sampler,
pin_memory=False,
prefetch=prefetch,
transform=RandomCropTensorDict(random_crop_len, sample_dim=1),
)
return replay_buffer
We’ll store the replay buffer in a temporary directory on disk
import tempfile
tmpdir = tempfile.TemporaryDirectory()
buffer_scratch_dir = tmpdir.name
Replay buffer storage and batch size
TorchRL replay buffer counts the number of elements along the first dimension.
Since we’ll be feeding trajectories to our buffer, we need to adapt the buffer
size by dividing it by the length of the sub-trajectories yielded by our
data collector.
Regarding the batch-size, our sampling strategy will consist in sampling
trajectories of length traj_len=200 before selecting sub-trajectories
or length random_crop_len=25 on which the loss will be computed.
This strategy balances the choice of storing whole trajectories of a certain
length with the need for providing samples with a sufficient heterogeneity
to our loss. The following figure shows the dataflow from a collector
that gets 8 frames in each batch with 2 environments run in parallel,
feeds them to a replay buffer that contains 1000 trajectories and
samples sub-trajectories of 2 time steps each.
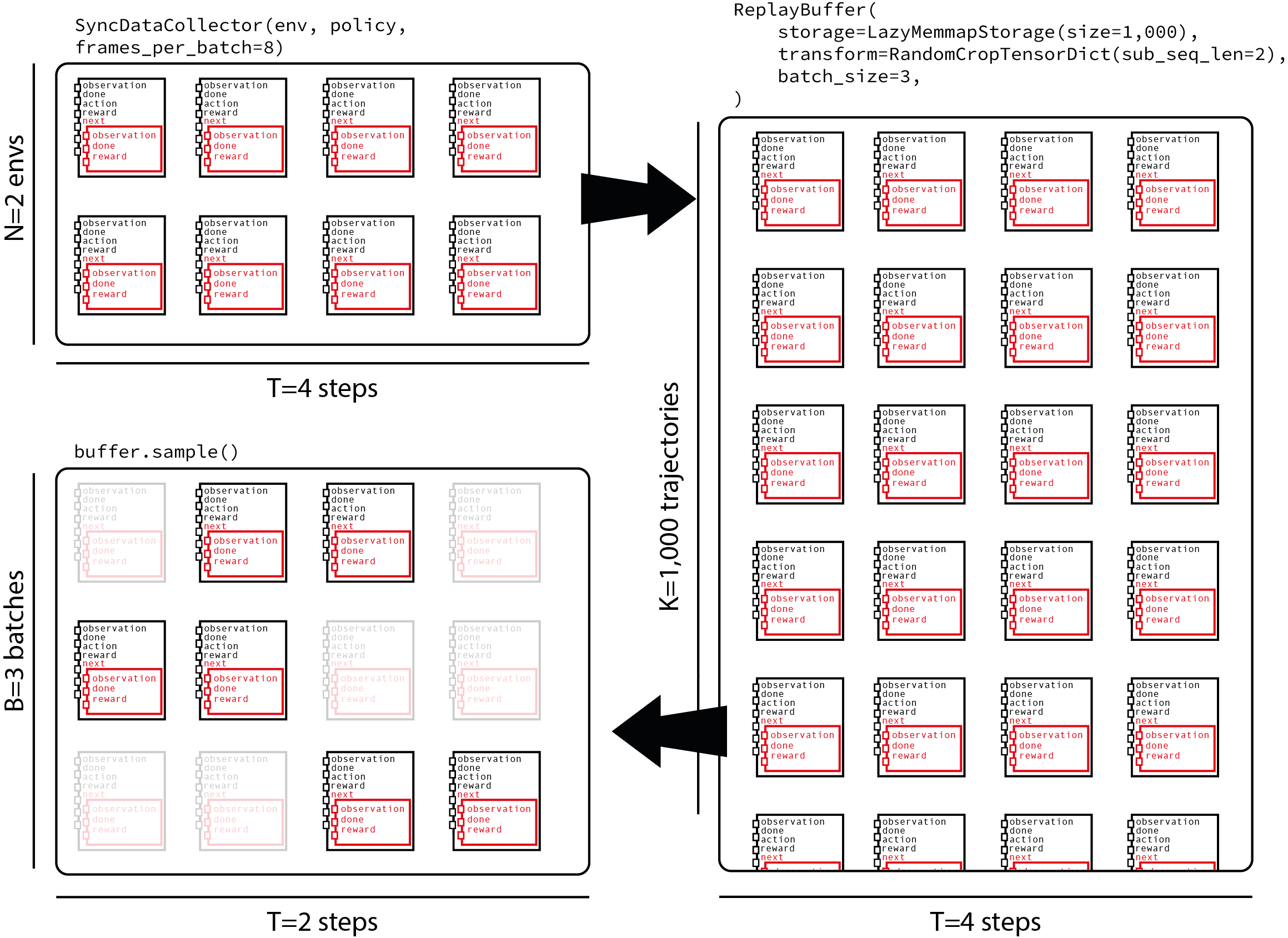
Let’s start with the number of frames stored in the buffer
def ceil_div(x, y):
return -x // (-y)
buffer_size = 1_000_000
buffer_size = ceil_div(buffer_size, traj_len)
Prioritized replay buffer is disabled by default
prb = False
We also need to define how many updates we’ll be doing per batch of data
collected. This is known as the update-to-data or UTD ratio:
update_to_data = 64
We’ll be feeding the loss with trajectories of length 25:
random_crop_len = 25
In the original paper, the authors perform one update with a batch of 64 elements for each frame collected. Here, we reproduce the same ratio but while realizing several updates at each batch collection. We adapt our batch-size to achieve the same number of update-per-frame ratio:
batch_size = ceil_div(64 * frames_per_batch, update_to_data * random_crop_len)
replay_buffer = make_replay_buffer(
buffer_size=buffer_size,
batch_size=batch_size,
random_crop_len=random_crop_len,
prefetch=3,
prb=prb,
)
Loss module construction
We build our loss module with the actor and qnet we’ve just created.
Because we have target parameters to update, we _must_ create a target network
updater.
gamma = 0.99
lmbda = 0.9
tau = 0.001 # Decay factor for the target network
loss_module = DDPGLoss(actor, qnet)
let’s use the TD(lambda) estimator!
loss_module.make_value_estimator(ValueEstimators.TDLambda, gamma=gamma, lmbda=lmbda)
Note
Off-policy usually dictates a TD(0) estimator. Here, we use a TD(
Target network updater
Target networks are a crucial part of off-policy RL sota-implementations.
Updating the target network parameters is made easy thanks to the
HardUpdate and SoftUpdate
classes. They’re built with the loss module as argument, and the update is
achieved via a call to updater.step() at the appropriate location in the
training loop.
from torchrl.objectives.utils import SoftUpdate
target_net_updater = SoftUpdate(loss_module, eps=1 - tau)
Optimizer
Finally, we will use the Adam optimizer for the policy and value network:
from torch import optim
optimizer_actor = optim.Adam(
loss_module.actor_network_params.values(True, True), lr=1e-4, weight_decay=0.0
)
optimizer_value = optim.Adam(
loss_module.value_network_params.values(True, True), lr=1e-3, weight_decay=1e-2
)
total_collection_steps = total_frames // frames_per_batch
Time to train the policy
The training loop is pretty straightforward now that we have built all the modules we need.
rewards = []
rewards_eval = []
# Main loop
collected_frames = 0
pbar = tqdm.tqdm(total=total_frames)
r0 = None
for i, tensordict in enumerate(collector):
# update weights of the inference policy
collector.update_policy_weights_()
if r0 is None:
r0 = tensordict["next", "reward"].mean().item()
pbar.update(tensordict.numel())
# extend the replay buffer with the new data
current_frames = tensordict.numel()
collected_frames += current_frames
replay_buffer.extend(tensordict.cpu())
# optimization steps
if collected_frames >= init_random_frames:
for _ in range(update_to_data):
# sample from replay buffer
sampled_tensordict = replay_buffer.sample().to(device)
# Compute loss
loss_dict = loss_module(sampled_tensordict)
# optimize
loss_dict["loss_actor"].backward()
gn1 = torch.nn.utils.clip_grad_norm_(
loss_module.actor_network_params.values(True, True), 10.0
)
optimizer_actor.step()
optimizer_actor.zero_grad()
loss_dict["loss_value"].backward()
gn2 = torch.nn.utils.clip_grad_norm_(
loss_module.value_network_params.values(True, True), 10.0
)
optimizer_value.step()
optimizer_value.zero_grad()
gn = (gn1**2 + gn2**2) ** 0.5
# update priority
if prb:
replay_buffer.update_tensordict_priority(sampled_tensordict)
# update target network
target_net_updater.step()
rewards.append(
(
i,
tensordict["next", "reward"].mean().item(),
)
)
td_record = recorder(None)
if td_record is not None:
rewards_eval.append((i, td_record["r_evaluation"].item()))
if len(rewards_eval) and collected_frames >= init_random_frames:
target_value = loss_dict["target_value"].item()
loss_value = loss_dict["loss_value"].item()
loss_actor = loss_dict["loss_actor"].item()
rn = sampled_tensordict["next", "reward"].mean().item()
rs = sampled_tensordict["next", "reward"].std().item()
pbar.set_description(
f"reward: {rewards[-1][1]: 4.2f} (r0 = {r0: 4.2f}), "
f"reward eval: reward: {rewards_eval[-1][1]: 4.2f}, "
f"reward normalized={rn :4.2f}/{rs :4.2f}, "
f"grad norm={gn: 4.2f}, "
f"loss_value={loss_value: 4.2f}, "
f"loss_actor={loss_actor: 4.2f}, "
f"target value: {target_value: 4.2f}"
)
# update the exploration strategy
actor_model_explore.step(current_frames)
collector.shutdown()
del collector
0%| | 0/10000 [00:00<?, ?it/s]
8%|▊ | 800/10000 [00:00<00:02, 3341.44it/s]
16%|█▌ | 1600/10000 [00:01<00:08, 972.21it/s]
24%|██▍ | 2400/10000 [00:01<00:05, 1450.21it/s]
32%|███▏ | 3200/10000 [00:01<00:03, 1892.96it/s]
40%|████ | 4000/10000 [00:02<00:02, 2269.56it/s]
48%|████▊ | 4800/10000 [00:02<00:02, 2582.90it/s]
56%|█████▌ | 5600/10000 [00:02<00:01, 2831.95it/s]
reward: -2.79 (r0 = -1.96), reward eval: reward: -0.00, reward normalized=-2.48/5.85, grad norm= 55.29, loss_value= 313.46, loss_actor= 16.18, target value: -17.03: 56%|█████▌ | 5600/10000 [00:04<00:01, 2831.95it/s]
reward: -2.79 (r0 = -1.96), reward eval: reward: -0.00, reward normalized=-2.48/5.85, grad norm= 55.29, loss_value= 313.46, loss_actor= 16.18, target value: -17.03: 64%|██████▍ | 6400/10000 [00:04<00:04, 853.52it/s]
reward: -1.87 (r0 = -1.96), reward eval: reward: -0.00, reward normalized=-2.68/5.85, grad norm= 202.05, loss_value= 304.94, loss_actor= 13.16, target value: -17.24: 64%|██████▍ | 6400/10000 [00:06<00:04, 853.52it/s]
reward: -1.87 (r0 = -1.96), reward eval: reward: -0.00, reward normalized=-2.68/5.85, grad norm= 202.05, loss_value= 304.94, loss_actor= 13.16, target value: -17.24: 72%|███████▏ | 7200/10000 [00:07<00:05, 535.98it/s]
reward: -5.27 (r0 = -1.96), reward eval: reward: -0.00, reward normalized=-2.96/5.83, grad norm= 215.11, loss_value= 276.88, loss_actor= 17.72, target value: -20.46: 72%|███████▏ | 7200/10000 [00:09<00:05, 535.98it/s]
reward: -5.27 (r0 = -1.96), reward eval: reward: -0.00, reward normalized=-2.96/5.83, grad norm= 215.11, loss_value= 276.88, loss_actor= 17.72, target value: -20.46: 80%|████████ | 8000/10000 [00:10<00:04, 429.53it/s]
reward: -5.04 (r0 = -1.96), reward eval: reward: -0.00, reward normalized=-2.68/5.49, grad norm= 94.22, loss_value= 189.84, loss_actor= 15.74, target value: -17.99: 80%|████████ | 8000/10000 [00:11<00:04, 429.53it/s]
reward: -5.04 (r0 = -1.96), reward eval: reward: -0.00, reward normalized=-2.68/5.49, grad norm= 94.22, loss_value= 189.84, loss_actor= 15.74, target value: -17.99: 88%|████████▊ | 8800/10000 [00:12<00:03, 388.35it/s]
reward: -1.05 (r0 = -1.96), reward eval: reward: 2.85, reward normalized=-2.68/4.91, grad norm= 88.90, loss_value= 153.33, loss_actor= 14.20, target value: -19.37: 88%|████████▊ | 8800/10000 [00:15<00:03, 388.35it/s]
reward: -1.05 (r0 = -1.96), reward eval: reward: 2.85, reward normalized=-2.68/4.91, grad norm= 88.90, loss_value= 153.33, loss_actor= 14.20, target value: -19.37: 96%|█████████▌| 9600/10000 [00:16<00:01, 313.88it/s]
reward: 0.95 (r0 = -1.96), reward eval: reward: 2.85, reward normalized=-2.82/5.52, grad norm= 122.12, loss_value= 198.87, loss_actor= 14.87, target value: -19.42: 96%|█████████▌| 9600/10000 [00:18<00:01, 313.88it/s]
reward: 0.95 (r0 = -1.96), reward eval: reward: 2.85, reward normalized=-2.82/5.52, grad norm= 122.12, loss_value= 198.87, loss_actor= 14.87, target value: -19.42: : 10400it [00:19, 296.66it/s]
reward: -5.00 (r0 = -1.96), reward eval: reward: 2.85, reward normalized=-2.38/4.70, grad norm= 135.29, loss_value= 136.95, loss_actor= 19.89, target value: -17.72: : 10400it [00:21, 296.66it/s]
Experiment results
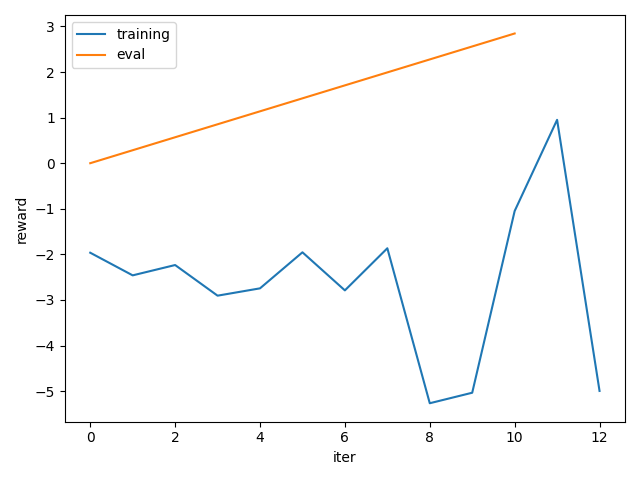
We make a simple plot of the average rewards during training. We can observe that our policy learned quite well to solve the task.
Note
As already mentioned above, to get a more reasonable performance,
use a greater value for total_frames for example, 1M.
from matplotlib import pyplot as plt
plt.figure()
plt.plot(*zip(*rewards), label="training")
plt.plot(*zip(*rewards_eval), label="eval")
plt.legend()
plt.xlabel("iter")
plt.ylabel("reward")
plt.tight_layout()
Conclusion
In this tutorial, we have learned how to code a loss module in TorchRL given the concrete example of DDPG.
The key takeaways are:
How to use the
LossModuleclass to code up a new loss component;How to use (or not) a target network, and how to update its parameters;
How to create an optimizer associated with a loss module.
Next Steps
To iterate further on this loss module we might consider:
Using @dispatch (see [Feature] Distpatch IQL loss module.)
Allowing flexible TensorDict keys.
Total running time of the script: (1 minutes 50.926 seconds)
Estimated memory usage: 18 MB
