ignite.contrib.handlers
Contribution module of handlers
custom_events
- class ignite.contrib.handlers.custom_events.CustomPeriodicEvent(n_iterations=None, n_epochs=None)[source]
DEPRECATED. Use filtered events instead. Handler to define a custom periodic events as a number of elapsed iterations/epochs for an engine.
When custom periodic event is created and attached to an engine, the following events are fired: 1) K iterations is specified: - Events.ITERATIONS_<K>_STARTED - Events.ITERATIONS_<K>_COMPLETED
1) K epochs is specified: - Events.EPOCHS_<K>_STARTED - Events.EPOCHS_<K>_COMPLETED
Examples:
from ignite.engine import Engine, Events from ignite.contrib.handlers import CustomPeriodicEvent # Let's define an event every 1000 iterations cpe1 = CustomPeriodicEvent(n_iterations=1000) cpe1.attach(trainer) # Let's define an event every 10 epochs cpe2 = CustomPeriodicEvent(n_epochs=10) cpe2.attach(trainer) @trainer.on(cpe1.Events.ITERATIONS_1000_COMPLETED) def on_every_1000_iterations(engine): # run a computation after 1000 iterations # ... print(engine.state.iterations_1000) @trainer.on(cpe2.Events.EPOCHS_10_STARTED) def on_every_10_epochs(engine): # run a computation every 10 epochs # ... print(engine.state.epochs_10)
param_scheduler
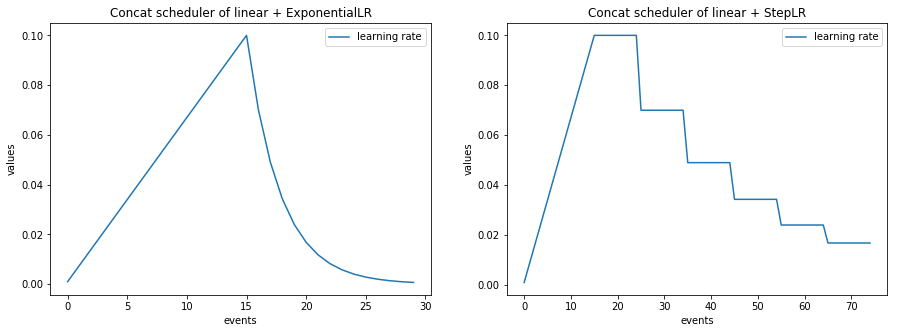
- class ignite.contrib.handlers.param_scheduler.ConcatScheduler(schedulers, durations, save_history=False)[source]
Concat a list of parameter schedulers.
The ConcatScheduler goes through a list of schedulers given by schedulers. Duration of each scheduler is defined by durations list of integers.
- Parameters
schedulers (list of ParamScheduler) – list of parameter schedulers.
durations (list of int) – list of number of events that lasts a parameter scheduler from schedulers.
save_history (bool, optional) – whether to log the parameter values to engine.state.param_history, (default=False).
Examples:
from ignite.contrib.handlers.param_scheduler import ConcatScheduler from ignite.contrib.handlers.param_scheduler import LinearCyclicalScheduler from ignite.contrib.handlers.param_scheduler import CosineAnnealingScheduler scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.1, end_value=0.5, cycle_size=60) scheduler_2 = CosineAnnealingScheduler(optimizer, "lr", start_value=0.5, end_value=0.01, cycle_size=60) combined_scheduler = ConcatScheduler(schedulers=[scheduler_1, scheduler_2], durations=[30, ]) trainer.add_event_handler(Events.ITERATION_STARTED, combined_scheduler) # # Sets the Learning rate linearly from 0.1 to 0.5 over 30 iterations. Then # starts an annealing schedule from 0.5 to 0.01 over 60 iterations. # The annealing cycles are repeated indefinitely. #
- get_param()[source]
Method to get current optimizer’s parameter values
- Returns
list of params, or scalar param
- load_state_dict(state_dict)[source]
Copies parameters from
state_dictinto this ConcatScheduler.- Parameters
state_dict (dict) – a dict containing parameters.
- classmethod simulate_values(num_events, schedulers, durations, param_names=None, **kwargs)[source]
Method to simulate scheduled values during num_events events.
- Parameters
num_events (int) – number of events during the simulation.
schedulers (list of ParamScheduler) – list of parameter schedulers.
durations (list of int) – list of number of events that lasts a parameter scheduler from schedulers.
param_names (list or tuple of str, optional) – parameter name or list of parameter names to simulate values. By default, the first scheduler’s parameter name is taken.
- Returns
list of [event_index, value_0, value_1, …], where values correspond to param_names.
- class ignite.contrib.handlers.param_scheduler.CosineAnnealingScheduler(optimizer, param_name, start_value, end_value, cycle_size, cycle_mult=1.0, start_value_mult=1.0, end_value_mult=1.0, save_history=False, param_group_index=None)[source]
Anneals ‘start_value’ to ‘end_value’ over each cycle.
The annealing takes the form of the first half of a cosine wave (as suggested in [Smith17]).
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – name of optimizer’s parameter to update.
start_value (float) – value at start of cycle.
end_value (float) – value at the end of the cycle.
cycle_size (int) – length of cycle.
cycle_mult (float, optional) – ratio by which to change the cycle_size at the end of each cycle (default=1).
start_value_mult (float, optional) – ratio by which to change the start value at the end of each cycle (default=1.0).
end_value_mult (float, optional) – ratio by which to change the end value at the end of each cycle (default=1.0).
save_history (bool, optional) – whether to log the parameter values to engine.state.param_history, (default=False).
param_group_index (int, optional) – optimizer’s parameters group to use.
Note
If the scheduler is bound to an ‘ITERATION_*’ event, ‘cycle_size’ should usually be the number of batches in an epoch.
Examples:
from ignite.contrib.handlers.param_scheduler import CosineAnnealingScheduler scheduler = CosineAnnealingScheduler(optimizer, 'lr', 1e-1, 1e-3, len(train_loader)) trainer.add_event_handler(Events.ITERATION_STARTED, scheduler) # # Anneals the learning rate from 1e-1 to 1e-3 over the course of 1 epoch. #
from ignite.contrib.handlers.param_scheduler import CosineAnnealingScheduler from ignite.contrib.handlers.param_scheduler import LinearCyclicalScheduler optimizer = SGD( [ {"params": model.base.parameters(), 'lr': 0.001), {"params": model.fc.parameters(), 'lr': 0.01), ] ) scheduler1 = LinearCyclicalScheduler(optimizer, 'lr', 1e-7, 1e-5, len(train_loader), param_group_index=0) trainer.add_event_handler(Events.ITERATION_STARTED, scheduler1, "lr (base)") scheduler2 = CosineAnnealingScheduler(optimizer, 'lr', 1e-5, 1e-3, len(train_loader), param_group_index=1) trainer.add_event_handler(Events.ITERATION_STARTED, scheduler2, "lr (fc)")
- Smith17
Smith, Leslie N. “Cyclical learning rates for training neural networks.” Applications of Computer Vision (WACV), 2017 IEEE Winter Conference on. IEEE, 2017
- get_param()[source]
Method to get current optimizer’s parameter value
- class ignite.contrib.handlers.param_scheduler.CyclicalScheduler(optimizer, param_name, start_value, end_value, cycle_size, cycle_mult=1.0, start_value_mult=1.0, end_value_mult=1.0, save_history=False, param_group_index=None)[source]
An abstract class for updating an optimizer’s parameter value over a cycle of some size.
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – name of optimizer’s parameter to update.
start_value (float) – value at start of cycle.
end_value (float) – value at the middle of the cycle.
cycle_size (int) – length of cycle, value should be larger than 1.
cycle_mult (float, optional) – ratio by which to change the cycle_size. at the end of each cycle (default=1.0).
start_value_mult (float, optional) – ratio by which to change the start value at the end of each cycle (default=1.0).
end_value_mult (float, optional) – ratio by which to change the end value at the end of each cycle (default=1.0).
save_history (bool, optional) – whether to log the parameter values to engine.state.param_history, (default=False).
param_group_index (int, optional) – optimizer’s parameters group to use.
Note
If the scheduler is bound to an ‘ITERATION_*’ event, ‘cycle_size’ should usually be the number of batches in an epoch.
- class ignite.contrib.handlers.param_scheduler.LRScheduler(lr_scheduler, save_history=False, **kwargs)[source]
A wrapper class to call torch.optim.lr_scheduler objects as ignite handlers.
- Parameters
lr_scheduler (subclass of torch.optim.lr_scheduler._LRScheduler) – lr_scheduler object to wrap.
save_history (bool, optional) – whether to log the parameter values to engine.state.param_history, (default=False).
from ignite.contrib.handlers.param_scheduler import LRScheduler from torch.optim.lr_scheduler import StepLR step_scheduler = StepLR(optimizer, step_size=3, gamma=0.1) scheduler = LRScheduler(step_scheduler) # In this example, we assume to have installed PyTorch>=1.1.0 # (with new `torch.optim.lr_scheduler` behaviour) and # we attach scheduler to Events.ITERATION_COMPLETED # instead of Events.ITERATION_STARTED to make sure to use # the first lr value from the optimizer, otherwise it is will be skipped: trainer.add_event_handler(Events.ITERATION_COMPLETED, scheduler)
- get_param()[source]
Method to get current optimizer’s parameter value
- classmethod simulate_values(num_events, lr_scheduler, **kwargs)[source]
Method to simulate scheduled values during num_events events.
- class ignite.contrib.handlers.param_scheduler.LinearCyclicalScheduler(optimizer, param_name, start_value, end_value, cycle_size, cycle_mult=1.0, start_value_mult=1.0, end_value_mult=1.0, save_history=False, param_group_index=None)[source]
Linearly adjusts param value to ‘end_value’ for a half-cycle, then linearly adjusts it back to ‘start_value’ for a half-cycle.
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – name of optimizer’s parameter to update.
start_value (float) – value at start of cycle.
end_value (float) – value at the middle of the cycle.
cycle_size (int) – length of cycle.
cycle_mult (float, optional) – ratio by which to change the cycle_size at the end of each cycle (default=1).
start_value_mult (float, optional) – ratio by which to change the start value at the end of each cycle (default=1.0).
end_value_mult (float, optional) – ratio by which to change the end value at the end of each cycle (default=1.0).
save_history (bool, optional) – whether to log the parameter values to engine.state.param_history, (default=False).
param_group_index (int, optional) – optimizer’s parameters group to use.
Note
If the scheduler is bound to an ‘ITERATION_*’ event, ‘cycle_size’ should usually be the number of batches in an epoch.
Examples:
from ignite.contrib.handlers.param_scheduler import LinearCyclicalScheduler scheduler = LinearCyclicalScheduler(optimizer, 'lr', 1e-3, 1e-1, len(train_loader)) trainer.add_event_handler(Events.ITERATION_STARTED, scheduler) # # Linearly increases the learning rate from 1e-3 to 1e-1 and back to 1e-3 # over the course of 1 epoch #
- get_param()[source]
Method to get current optimizer’s parameter values
- Returns
list of params, or scalar param
- class ignite.contrib.handlers.param_scheduler.ParamGroupScheduler(schedulers, names=None, save_history=False)[source]
Scheduler helper to group multiple schedulers into one.
- Parameters
schedulers (list/tuple of ParamScheduler) – list/tuple of parameter schedulers.
optimizer = SGD( [ {"params": model.base.parameters(), 'lr': 0.001), {"params": model.fc.parameters(), 'lr': 0.01), ] ) scheduler1 = LinearCyclicalScheduler(optimizer, 'lr', 1e-7, 1e-5, len(train_loader), param_group_index=0) scheduler2 = CosineAnnealingScheduler(optimizer, 'lr', 1e-5, 1e-3, len(train_loader), param_group_index=1) lr_schedulers = [scheduler1, scheduler2] names = ["lr (base)", "lr (fc)"] scheduler = ParamGroupScheduler(schedulers=lr_schedulers, names=names) # Attach single scheduler to the trainer trainer.add_event_handler(Events.ITERATION_STARTED, scheduler)
- get_param()[source]
Method to get current optimizer’s parameter values
- load_state_dict(state_dict)[source]
Copies parameters from
state_dictinto this ParamScheduler.- Parameters
state_dict (dict) – a dict containing parameters.
- classmethod simulate_values(num_events, schedulers, **kwargs)[source]
Method to simulate scheduled values during num_events events.
- class ignite.contrib.handlers.param_scheduler.ParamScheduler(optimizer, param_name, save_history=False, param_group_index=None)[source]
An abstract class for updating an optimizer’s parameter value during training.
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – name of optimizer’s parameter to update.
save_history (bool, optional) – whether to log the parameter values to engine.state.param_history, (default=False).
param_group_index (int, optional) – optimizer’s parameters group to use
Note
Parameter scheduler works independently of the internal state of the attached optimizer. More precisely, whatever the state of the optimizer (newly created or used by another scheduler) the scheduler sets defined absolute values.
- abstract get_param()[source]
Method to get current optimizer’s parameter values
- load_state_dict(state_dict)[source]
Copies parameters from
state_dictinto this ParamScheduler.- Parameters
state_dict (dict) – a dict containing parameters.
- classmethod plot_values(num_events, **scheduler_kwargs)[source]
Method to plot simulated scheduled values during num_events events.
This class requires matplotlib package to be installed:
pip install matplotlib
- Parameters
num_events (int) – number of events during the simulation.
**scheduler_kwargs – parameter scheduler configuration kwargs.
- Returns
matplotlib.lines.Line2D
Examples
import matplotlib.pylab as plt plt.figure(figsize=(10, 7)) LinearCyclicalScheduler.plot_values(num_events=50, param_name='lr', start_value=1e-1, end_value=1e-3, cycle_size=10))
- classmethod simulate_values(num_events, **scheduler_kwargs)[source]
Method to simulate scheduled values during num_events events.
- Parameters
num_events (int) – number of events during the simulation.
**scheduler_kwargs – parameter scheduler configuration kwargs.
- Returns
[event_index, value]
- Return type
list of pairs
Examples:
lr_values = np.array(LinearCyclicalScheduler.simulate_values(num_events=50, param_name='lr', start_value=1e-1, end_value=1e-3, cycle_size=10)) plt.plot(lr_values[:, 0], lr_values[:, 1], label="learning rate") plt.xlabel("events") plt.ylabel("values") plt.legend()
- class ignite.contrib.handlers.param_scheduler.PiecewiseLinear(optimizer, param_name, milestones_values, save_history=False, param_group_index=None)[source]
Piecewise linear parameter scheduler
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – name of optimizer’s parameter to update.
milestones_values (list of tuples (int, float)) – list of tuples (event index, parameter value) represents milestones and parameter. Milestones should be increasing integers.
save_history (bool, optional) – whether to log the parameter values to engine.state.param_history, (default=False).
param_group_index (int, optional) – optimizer’s parameters group to use.
- Returns
piecewise linear scheduler
- Return type
scheduler = PiecewiseLinear(optimizer, "lr", milestones_values=[(10, 0.5), (20, 0.45), (21, 0.3), (30, 0.1), (40, 0.1)]) # Attach to the trainer trainer.add_event_handler(Events.ITERATION_STARTED, scheduler) # # Sets the learning rate to 0.5 over the first 10 iterations, then decreases linearly from 0.5 to 0.45 between # 10th and 20th iterations. Next there is a jump to 0.3 at the 21st iteration and LR decreases linearly # from 0.3 to 0.1 between 21st and 30th iterations and remains 0.1 until the end of the iterations. #
- get_param()[source]
Method to get current optimizer’s parameter values
- Returns
list of params, or scalar param
- ignite.contrib.handlers.param_scheduler.create_lr_scheduler_with_warmup(lr_scheduler, warmup_start_value, warmup_duration, warmup_end_value=None, save_history=False, output_simulated_values=None)[source]
Helper method to create a learning rate scheduler with a linear warm-up.
- Parameters
lr_scheduler (ParamScheduler or subclass of torch.optim.lr_scheduler._LRScheduler) – learning rate scheduler after the warm-up.
warmup_start_value (float) – learning rate start value of the warm-up phase.
warmup_duration (int) – warm-up phase duration, number of events.
warmup_end_value (float) – learning rate end value of the warm-up phase, (default=None). If None, warmup_end_value is set to optimizer initial lr.
save_history (bool, optional) – whether to log the parameter values to engine.state.param_history, (default=False).
output_simulated_values (list, optional) – optional output of simulated learning rate values. If output_simulated_values is a list of None, e.g. [None] * 100, after the execution it will be filled by 100 simulated learning rate values.
- Returns
learning rate scheduler with linear warm-up.
- Return type
Note
If the first learning rate value provided by lr_scheduler is different from warmup_end_value, an additional event is added after the warm-up phase such that the warm-up ends with warmup_end_value value and then lr_scheduler provides its learning rate values as normally.
Examples
torch_lr_scheduler = ExponentialLR(optimizer=optimizer, gamma=0.98) lr_values = [None] * 100 scheduler = create_lr_scheduler_with_warmup(torch_lr_scheduler, warmup_start_value=0.0, warmup_end_value=0.1, warmup_duration=10, output_simulated_values=lr_values) lr_values = np.array(lr_values) # Plot simulated values plt.plot(lr_values[:, 0], lr_values[:, 1], label="learning rate") # Attach to the trainer trainer.add_event_handler(Events.ITERATION_STARTED, scheduler)
lr_finder
- class ignite.contrib.handlers.lr_finder.FastaiLRFinder[source]
Learning rate finder handler for supervised trainers.
While attached, the handler increases the learning rate in between two boundaries in a linear or exponential manner. It provides valuable information on how well the network can be trained over a range of learning rates and what can be an optimal learning rate.
Examples:
from ignite.contrib.handlers import FastaiLRFinder trainer = ... model = ... optimizer = ... lr_finder = FastaiLRFinder() to_save = {"model": model, "optimizer": optimizer} with lr_finder.attach(trainer, to_save=to_save) as trainer_with_lr_finder: trainer_with_lr_finder.run(dataloader) # Get lr_finder results lr_finder.get_results() # Plot lr_finder results (requires matplotlib) lr_finder.plot() # get lr_finder suggestion for lr lr_finder.lr_suggestion()
Note
When context manager is exited all LR finder’s handlers are removed.
Note
Please, also keep in mind that all other handlers attached the trainer will be executed during LR finder’s run.
Note
This class may require matplotlib package to be installed to plot learning rate range test:
pip install matplotlib
References
Cyclical Learning Rates for Training Neural Networks: https://arxiv.org/abs/1506.01186
fastai/lr_find: https://github.com/fastai/fastai
- attach(trainer, to_save, output_transform=<function FastaiLRFinder.<lambda>>, num_iter=None, end_lr=10.0, step_mode='exp', smooth_f=0.05, diverge_th=5.0)[source]
Attaches lr_finder to a given trainer. It also resets model and optimizer at the end of the run.
Usage:
to_save = {"model": model, "optimizer": optimizer} with lr_finder.attach(trainer, to_save=to_save) as trainer_with_lr_finder: trainer_with_lr_finder.run(dataloader)`- Parameters
trainer (Engine) – lr_finder is attached to this trainer. Please, keep in mind that all attached handlers will be executed.
to_save (Mapping) – dictionary with optimizer and other objects that needs to be restored after running the LR finder. For example, to_save={‘optimizer’: optimizer, ‘model’: model}. All objects should implement state_dict and load_state_dict methods.
output_transform (callable, optional) – function that transforms the trainer’s state.output after each iteration. It must return the loss of that iteration.
num_iter (int, optional) – number of iterations for lr schedule between base lr and end_lr. Default, it will run for trainer.state.epoch_length * trainer.state.max_epochs.
end_lr (float, optional) – upper bound for lr search. Default, 10.0.
step_mode (str, optional) – “exp” or “linear”, which way should the lr be increased from optimizer’s initial lr to end_lr. Default, “exp”.
smooth_f (float, optional) – loss smoothing factor in range [0, 1). Default, 0.05
diverge_th (float, optional) – Used for stopping the search when current loss > diverge_th * best_loss. Default, 5.0.
Notes
lr_finder cannot be attached to more than one trainer at a time
- Returns
trainer used for finding the lr
- Return type
trainer_with_lr_finder
- get_results()[source]
Returns: dictionary with loss and lr logs fromm the previous run
- lr_suggestion()[source]
Returns: learning rate at the minimum numerical gradient
- plot(skip_start=10, skip_end=5, log_lr=True)[source]
Plots the learning rate range test.
This method requires matplotlib package to be installed:
pip install matplotlib
- Parameters
time_profilers
- class ignite.contrib.handlers.time_profilers.BasicTimeProfiler[source]
BasicTimeProfiler can be used to profile the handlers, events, data loading and data processing times.
Examples:
from ignite.contrib.handlers import BasicTimeProfiler trainer = Engine(train_updater) # Create an object of the profiler and attach an engine to it profiler = BasicTimeProfiler() profiler.attach(trainer) @trainer.on(Events.EPOCH_COMPLETED) def log_intermediate_results(): profiler.print_results(profiler.get_results()) trainer.run(dataloader, max_epochs=3) profiler.write_results('path_to_dir/time_profiling.csv')
- get_results()[source]
Method to fetch the aggregated profiler results after the engine is run
results = profiler.get_results()
- static print_results(results)[source]
Method to print the aggregated results from the profiler
profiler.print_results(results)
Example output:
---------------------------------------------------- | Time profiling stats (in seconds): | ---------------------------------------------------- total | min/index | max/index | mean | std Processing function: 157.46292 | 0.01452/1501 | 0.26905/0 | 0.07730 | 0.01258 Dataflow: 6.11384 | 0.00008/1935 | 0.28461/1551 | 0.00300 | 0.02693 Event handlers: 2.82721 - Events.STARTED: [] 0.00000 - Events.EPOCH_STARTED: [] 0.00006 | 0.00000/0 | 0.00000/17 | 0.00000 | 0.00000 - Events.ITERATION_STARTED: ['PiecewiseLinear'] 0.03482 | 0.00001/188 | 0.00018/679 | 0.00002 | 0.00001 - Events.ITERATION_COMPLETED: ['TerminateOnNan'] 0.20037 | 0.00006/866 | 0.00089/1943 | 0.00010 | 0.00003 - Events.EPOCH_COMPLETED: ['empty_cuda_cache', 'training.<locals>.log_elapsed_time', ] 2.57860 | 0.11529/0 | 0.14977/13 | 0.12893 | 0.00790 - Events.COMPLETED: [] not yet triggered
- write_results(output_path)[source]
Method to store the unaggregated profiling results to a csv file
profiler.write_results('path_to_dir/awesome_filename.csv')
Example output:
----------------------------------------------------------------- epoch iteration processing_stats dataflow_stats Event_STARTED ... 1.0 1.0 0.00003 0.252387 0.125676 1.0 2.0 0.00029 0.252342 0.125123
tensorboard_logger
See tensorboardX mnist example and CycleGAN and EfficientNet notebooks for detailed usage.
- class ignite.contrib.handlers.tensorboard_logger.GradsHistHandler(model, tag=None)[source]
Helper handler to log model’s gradients as histograms.
Examples
from ignite.contrib.handlers.tensorboard_logger import * # Create a logger tb_logger = TensorboardLogger(log_dir="experiments/tb_logs") # Attach the logger to the trainer to log model's weights norm after each iteration tb_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=GradsHistHandler(model) )
- Parameters
model (torch.nn.Module) – model to log weights
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.tensorboard_logger.GradsScalarHandler(model, reduction=<function norm>, tag=None)[source]
Helper handler to log model’s gradients as scalars. Handler iterates over the gradients of named parameters of the model, applies reduction function to each parameter produce a scalar and then logs the scalar.
Examples
from ignite.contrib.handlers.tensorboard_logger import * # Create a logger tb_logger = TensorboardLogger(log_dir="experiments/tb_logs") # Attach the logger to the trainer to log model's weights norm after each iteration tb_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=GradsScalarHandler(model, reduction=torch.norm) )
- Parameters
model (torch.nn.Module) – model to log weights
reduction (callable) – function to reduce parameters into scalar
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.tensorboard_logger.OptimizerParamsHandler(optimizer, param_name='lr', tag=None)[source]
Helper handler to log optimizer parameters
Examples
from ignite.contrib.handlers.tensorboard_logger import * # Create a logger tb_logger = TensorboardLogger(log_dir="experiments/tb_logs") # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration tb_logger.attach( trainer, log_handler=OptimizerParamsHandler(optimizer), event_name=Events.ITERATION_STARTED ) # or equivalently tb_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer )
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – parameter name
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.tensorboard_logger.OutputHandler(tag, metric_names=None, output_transform=None, global_step_transform=None)[source]
Helper handler to log engine’s output and/or metrics
Examples
from ignite.contrib.handlers.tensorboard_logger import * # Create a logger tb_logger = TensorboardLogger(log_dir="experiments/tb_logs") # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer`: tb_logger.attach( evaluator, log_handler=OutputHandler( tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) ), event_name=Events.EPOCH_COMPLETED ) # or equivalently tb_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) )
Another example, where model is evaluated every 500 iterations:
from ignite.contrib.handlers.tensorboard_logger import * @trainer.on(Events.ITERATION_COMPLETED(every=500)) def evaluate(engine): evaluator.run(validation_set, max_epochs=1) tb_logger = TensorboardLogger(log_dir="experiments/tb_logs") def global_step_transform(*args, **kwargs): return trainer.state.iteration # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # every 500 iterations. Since evaluator engine does not have access to the training iteration, we # provide a global_step_transform to return the trainer.state.iteration for the global_step, each time # evaluator metrics are plotted on Tensorboard. tb_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metrics=["nll", "accuracy"], global_step_transform=global_step_transform )
- Parameters
tag (str) – common title for all produced plots. For example, “training”
metric_names (list of str, optional) – list of metric names to plot or a string “all” to plot all available metrics.
output_transform (callable, optional) – output transform function to prepare engine.state.output as a number. For example, output_transform = lambda output: output This function can also return a dictionary, e.g {“loss”: loss1, “another_loss”: loss2} to label the plot with corresponding keys.
global_step_transform (callable, optional) – global step transform function to output a desired global step. Input of the function is (engine, event_name). Output of function should be an integer. Default is None, global_step based on attached engine. If provided, uses function output as global_step. To setup global step from another engine, please use
global_step_from_engine().
Note
Example of global_step_transform:
def global_step_transform(engine, event_name): return engine.state.get_event_attrib_value(event_name)
- class ignite.contrib.handlers.tensorboard_logger.TensorboardLogger(*args, **kwargs)[source]
TensorBoard handler to log metrics, model/optimizer parameters, gradients during the training and validation.
By default, this class favors tensorboardX package if installed:
pip install tensorboardX
otherwise, it falls back to using PyTorch’s SummaryWriter (>=v1.2.0).
- Parameters
*args – Positional arguments accepted from SummaryWriter.
**kwargs –
Keyword arguments accepted from SummaryWriter. For example, log_dir to setup path to the directory where to log.
Examples
from ignite.contrib.handlers.tensorboard_logger import * # Create a logger tb_logger = TensorboardLogger(log_dir="experiments/tb_logs") # Attach the logger to the trainer to log training loss at each iteration tb_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {"loss": loss} ) # Attach the logger to the evaluator on the training dataset and log NLL, Accuracy metrics after each epoch # We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer` instead of `train_evaluator`. tb_logger.attach_output_handler( train_evaluator, event_name=Events.EPOCH_COMPLETED, tag="training", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer), ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch of the # `trainer` instead of `evaluator`. tb_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer)), ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration tb_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer, param_name='lr' # optional ) # Attach the logger to the trainer to log model's weights norm after each iteration tb_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsScalarHandler(model) ) # Attach the logger to the trainer to log model's weights as a histogram after each epoch tb_logger.attach( trainer, event_name=Events.EPOCH_COMPLETED, log_handler=WeightsHistHandler(model) ) # Attach the logger to the trainer to log model's gradients norm after each iteration tb_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=GradsScalarHandler(model) ) # Attach the logger to the trainer to log model's gradients as a histogram after each epoch tb_logger.attach( trainer, event_name=Events.EPOCH_COMPLETED, log_handler=GradsHistHandler(model) ) # We need to close the logger with we are done tb_logger.close()
It is also possible to use the logger as context manager:
from ignite.contrib.handlers.tensorboard_logger import * with TensorboardLogger(log_dir="experiments/tb_logs") as tb_logger: trainer = Engine(update_fn) # Attach the logger to the trainer to log training loss at each iteration tb_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {"loss": loss} )
- attach(engine, log_handler, event_name)
Attach the logger to the engine and execute log_handler function at event_name events.
- Parameters
engine (Engine) – engine object.
log_handler (callable) – a logging handler to execute
event_name – event to attach the logging handler to. Valid events are from
Eventsor any event_name added byregister_events().
- Returns
RemovableEventHandle, which can be used to remove the handler.
- attach_opt_params_handler(engine, event_name, *args, **kwargs)
Shortcut method to attach OptimizerParamsHandler to the logger.
- Parameters
- Returns
RemovableEventHandle, which can be used to remove the handler.
- class ignite.contrib.handlers.tensorboard_logger.WeightsHistHandler(model, tag=None)[source]
Helper handler to log model’s weights as histograms.
Examples
from ignite.contrib.handlers.tensorboard_logger import * # Create a logger tb_logger = TensorboardLogger(log_dir="experiments/tb_logs") # Attach the logger to the trainer to log model's weights norm after each iteration tb_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsHistHandler(model) )
- Parameters
model (torch.nn.Module) – model to log weights
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.tensorboard_logger.WeightsScalarHandler(model, reduction=<function norm>, tag=None)[source]
Helper handler to log model’s weights as scalars. Handler iterates over named parameters of the model, applies reduction function to each parameter produce a scalar and then logs the scalar.
Examples
from ignite.contrib.handlers.tensorboard_logger import * # Create a logger tb_logger = TensorboardLogger(log_dir="experiments/tb_logs") # Attach the logger to the trainer to log model's weights norm after each iteration tb_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsScalarHandler(model, reduction=torch.norm) )
- Parameters
model (torch.nn.Module) – model to log weights
reduction (callable) – function to reduce parameters into scalar
tag (str, optional) – common title for all produced plots. For example, “generator”
- ignite.contrib.handlers.tensorboard_logger.global_step_from_engine(engine, custom_event_name=None)[source]
Helper method to setup global_step_transform function using another engine. This can be helpful for logging trainer epoch/iteration while output handler is attached to an evaluator.
visdom_logger
See visdom mnist example for detailed usage.
- class ignite.contrib.handlers.visdom_logger.GradsScalarHandler(model, reduction=<function norm>, tag=None, show_legend=False)[source]
Helper handler to log model’s gradients as scalars. Handler iterates over the gradients of named parameters of the model, applies reduction function to each parameter produce a scalar and then logs the scalar.
Examples
from ignite.contrib.handlers.visdom_logger import * # Create a logger vd_logger = VisdomLogger() # Attach the logger to the trainer to log model's weights norm after each iteration vd_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=GradsScalarHandler(model, reduction=torch.norm) )
- Parameters
model (torch.nn.Module) – model to log weights
reduction (callable) – function to reduce parameters into scalar
tag (str, optional) – common title for all produced plots. For example, “generator”
show_legend (bool, optional) – flag to show legend in the window
- add_scalar(logger, k, v, event_name, global_step)
Helper method to log a scalar with VisdomLogger.
- Parameters
logger (VisdomLogger) – visdom logger
k (str) – scalar name which is used to set window title and y-axis label
event_name – Event name which is used to setup x-axis label. Valid events are from
Eventsor any event_name added byregister_events().global_step (int) – global step, x-axis value
- class ignite.contrib.handlers.visdom_logger.OptimizerParamsHandler(optimizer, param_name='lr', tag=None, show_legend=False)[source]
Helper handler to log optimizer parameters
Examples
from ignite.contrib.handlers.visdom_logger import * # Create a logger vb_logger = VisdomLogger() # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration vd_logger.attach( trainer, log_handler=OptimizerParamsHandler(optimizer), event_name=Events.ITERATION_STARTED ) # or equivalently vd_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer )
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – parameter name
tag (str, optional) – common title for all produced plots. For example, “generator”
show_legend (bool, optional) – flag to show legend in the window
- add_scalar(logger, k, v, event_name, global_step)
Helper method to log a scalar with VisdomLogger.
- Parameters
logger (VisdomLogger) – visdom logger
k (str) – scalar name which is used to set window title and y-axis label
event_name – Event name which is used to setup x-axis label. Valid events are from
Eventsor any event_name added byregister_events().global_step (int) – global step, x-axis value
- class ignite.contrib.handlers.visdom_logger.OutputHandler(tag, metric_names=None, output_transform=None, global_step_transform=None, show_legend=False)[source]
Helper handler to log engine’s output and/or metrics
Examples
from ignite.contrib.handlers.visdom_logger import * # Create a logger vd_logger = VisdomLogger() # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer`: vd_logger.attach( evaluator, log_handler=OutputHandler( tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) ), event_name=Events.EPOCH_COMPLETED ) # or equivalently vd_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) )
Another example, where model is evaluated every 500 iterations:
from ignite.contrib.handlers.visdom_logger import * @trainer.on(Events.ITERATION_COMPLETED(every=500)) def evaluate(engine): evaluator.run(validation_set, max_epochs=1) vd_logger = VisdomLogger() def global_step_transform(*args, **kwargs): return trainer.state.iteration # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # every 500 iterations. Since evaluator engine does not have access to the training iteration, we # provide a global_step_transform to return the trainer.state.iteration for the global_step, each time # evaluator metrics are plotted on Visdom. vd_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metrics=["nll", "accuracy"], global_step_transform=global_step_transform )
- Parameters
tag (str) – common title for all produced plots. For example, “training”
metric_names (list of str, optional) – list of metric names to plot or a string “all” to plot all available metrics.
output_transform (callable, optional) – output transform function to prepare engine.state.output as a number. For example, output_transform = lambda output: output This function can also return a dictionary, e.g {“loss”: loss1, “another_loss”: loss2} to label the plot with corresponding keys.
global_step_transform (callable, optional) – global step transform function to output a desired global step. Input of the function is (engine, event_name). Output of function should be an integer. Default is None, global_step based on attached engine. If provided, uses function output as global_step. To setup global step from another engine, please use
global_step_from_engine().show_legend (bool, optional) – flag to show legend in the window
Note
Example of global_step_transform:
def global_step_transform(engine, event_name): return engine.state.get_event_attrib_value(event_name)
- add_scalar(logger, k, v, event_name, global_step)
Helper method to log a scalar with VisdomLogger.
- Parameters
logger (VisdomLogger) – visdom logger
k (str) – scalar name which is used to set window title and y-axis label
event_name – Event name which is used to setup x-axis label. Valid events are from
Eventsor any event_name added byregister_events().global_step (int) – global step, x-axis value
- class ignite.contrib.handlers.visdom_logger.VisdomLogger(server=None, port=None, num_workers=1, raise_exceptions=True, **kwargs)[source]
VisdomLogger handler to log metrics, model/optimizer parameters, gradients during the training and validation.
This class requires visdom package to be installed:
pip install git+https://github.com/facebookresearch/visdom.git
- Parameters
server (str, optional) – visdom server URL. It can be also specified by environment variable VISDOM_SERVER_URL
port (int, optional) – visdom server’s port. It can be also specified by environment variable VISDOM_PORT
num_workers (int, optional) – number of workers to use in concurrent.futures.ThreadPoolExecutor to post data to visdom server. Default, num_workers=1. If num_workers=0 and logger uses the main thread. If using Python 2.7 and num_workers>0 the package futures should be installed: pip install futures
**kwargs – kwargs to pass into visdom.Visdom.
Note
We can also specify username/password using environment variables: VISDOM_USERNAME, VISDOM_PASSWORD
Warning
Frequent logging, e.g. when logger is attached to Events.ITERATION_COMPLETED, can slow down the run if the main thread is used to send the data to visdom server (num_workers=0). To avoid this situation we can either log less frequently or set num_workers=1.
Examples
from ignite.contrib.handlers.visdom_logger import * # Create a logger vd_logger = VisdomLogger() # Attach the logger to the trainer to log training loss at each iteration vd_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {"loss": loss} ) # Attach the logger to the evaluator on the training dataset and log NLL, Accuracy metrics after each epoch # We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer` instead of `train_evaluator`. vd_logger.attach_output_handler( train_evaluator, event_name=Events.EPOCH_COMPLETED, tag="training", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer), ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch of the # `trainer` instead of `evaluator`. vd_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer)), ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration vd_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer, param_name='lr' # optional ) # Attach the logger to the trainer to log model's weights norm after each iteration vd_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsScalarHandler(model) ) # Attach the logger to the trainer to log model's gradients norm after each iteration vd_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=GradsScalarHandler(model) ) # We need to close the logger with we are done vd_logger.close()
It is also possible to use the logger as context manager:
from ignite.contrib.handlers.visdom_logger import * with VisdomLogger() as vd_logger: trainer = Engine(update_fn) # Attach the logger to the trainer to log training loss at each iteration vd_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {"loss": loss} )
- attach(engine, log_handler, event_name)
Attach the logger to the engine and execute log_handler function at event_name events.
- Parameters
engine (Engine) – engine object.
log_handler (callable) – a logging handler to execute
event_name – event to attach the logging handler to. Valid events are from
Eventsor any event_name added byregister_events().
- Returns
RemovableEventHandle, which can be used to remove the handler.
- attach_opt_params_handler(engine, event_name, *args, **kwargs)
Shortcut method to attach OptimizerParamsHandler to the logger.
- Parameters
- Returns
RemovableEventHandle, which can be used to remove the handler.
- class ignite.contrib.handlers.visdom_logger.WeightsScalarHandler(model, reduction=<function norm>, tag=None, show_legend=False)[source]
Helper handler to log model’s weights as scalars. Handler iterates over named parameters of the model, applies reduction function to each parameter produce a scalar and then logs the scalar.
Examples
from ignite.contrib.handlers.visdom_logger import * # Create a logger vd_logger = VisdomLogger() # Attach the logger to the trainer to log model's weights norm after each iteration vd_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsScalarHandler(model, reduction=torch.norm) )
- Parameters
model (torch.nn.Module) – model to log weights
reduction (callable) – function to reduce parameters into scalar
tag (str, optional) – common title for all produced plots. For example, “generator”
show_legend (bool, optional) – flag to show legend in the window
- add_scalar(logger, k, v, event_name, global_step)
Helper method to log a scalar with VisdomLogger.
- Parameters
logger (VisdomLogger) – visdom logger
k (str) – scalar name which is used to set window title and y-axis label
event_name – Event name which is used to setup x-axis label. Valid events are from
Eventsor any event_name added byregister_events().global_step (int) – global step, x-axis value
- ignite.contrib.handlers.visdom_logger.global_step_from_engine(engine, custom_event_name=None)[source]
Helper method to setup global_step_transform function using another engine. This can be helpful for logging trainer epoch/iteration while output handler is attached to an evaluator.
neptune_logger
See neptune mnist example for detailed usage.
- class ignite.contrib.handlers.neptune_logger.GradsScalarHandler(model, reduction=<function norm>, tag=None)[source]
Helper handler to log model’s gradients as scalars. Handler iterates over the gradients of named parameters of the model, applies reduction function to each parameter produce a scalar and then logs the scalar.
Examples
from ignite.contrib.handlers.neptune_logger import * # Create a logger # We are using the api_token for the anonymous user neptuner but you can use your own. npt_logger = NeptuneLogger( api_token="ANONYMOUS", project_name="shared/pytorch-ignite-integration", experiment_name="cnn-mnist", # Optional, params={"max_epochs": 10}, # Optional, tags=["pytorch-ignite","minst"] # Optional ) # Attach the logger to the trainer to log model's weights norm after each iteration npt_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=GradsScalarHandler(model, reduction=torch.norm) )
- Parameters
model (torch.nn.Module) – model to log weights
reduction (callable) – function to reduce parameters into scalar
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.neptune_logger.NeptuneLogger(*args, **kwargs)[source]
Neptune handler to log metrics, model/optimizer parameters, gradients during the training and validation. It can also log model checkpoints to Neptune server.
pip install neptune-client
- Parameters
api_token (str | None) – Required in online mode. Neputne API token, found on https://neptune.ai. Read how to get your API key https://docs.neptune.ai/python-api/tutorials/get-started.html#copy-api-token.
project_name (str) – Required in online mode. Qualified name of a project in a form of “namespace/project_name” for example “tom/minst-classification”. If None, the value of NEPTUNE_PROJECT environment variable will be taken. You need to create the project in https://neptune.ai first.
offline_mode (bool) – Optional default False. If offline_mode=True no logs will be send to neptune. Usually used for debug purposes.
experiment_name (str, optional) – Optional. Editable name of the experiment. Name is displayed in the experiment’s Details (Metadata section) and in experiments view as a column.
upload_source_files (list, optional) – Optional. List of source files to be uploaded. Must be list of str or single str. Uploaded sources are displayed in the experiment’s Source code tab. If None is passed, Python file from which experiment was created will be uploaded. Pass empty list ([]) to upload no files. Unix style pathname pattern expansion is supported. For example, you can pass *.py to upload all python source files from the current directory. For recursion lookup use **/*.py (for Python 3.5 and later). For more information see glob library.
params (dict, optional) – Optional. Parameters of the experiment. After experiment creation params are read-only. Parameters are displayed in the experiment’s Parameters section and each key-value pair can be viewed in experiments view as a column.
properties (dict, optional) – Optional default is {}. Properties of the experiment. They are editable after experiment is created. Properties are displayed in the experiment’s Details and each key-value pair can be viewed in experiments view as a column.
tags (list, optional) – Optional default []. Must be list of str. Tags of the experiment. Tags are displayed in the experiment’s Details and can be viewed in experiments view as a column.
Examples
from ignite.contrib.handlers.neptune_logger import * # Create a logger # We are using the api_token for the anonymous user neptuner but you can use your own. npt_logger = NeptuneLogger( api_token="ANONYMOUS", project_name="shared/pytorch-ignite-integration", experiment_name="cnn-mnist", # Optional, params={"max_epochs": 10}, # Optional, tags=["pytorch-ignite","minst"] # Optional ) # Attach the logger to the trainer to log training loss at each iteration npt_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {'loss': loss} ) # Attach the logger to the evaluator on the training dataset and log NLL, Accuracy metrics after each epoch # We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer` instead of `train_evaluator`. npt_logger.attach_output_handler( train_evaluator, event_name=Events.EPOCH_COMPLETED, tag="training", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer), ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch of the # `trainer` instead of `evaluator`. npt_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer)), ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration npt_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer, param_name='lr' # optional ) # Attach the logger to the trainer to log model's weights norm after each iteration npt_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsScalarHandler(model) )
Explore an experiment with neptune tracking here: https://ui.neptune.ai/o/shared/org/pytorch-ignite-integration/e/PYTOR1-18/charts You can save model checkpoints to a Neptune server:
from ignite.handlers import Checkpoint def score_function(engine): return engine.state.metrics["accuracy"] to_save = {"model": model} handler = Checkpoint( to_save, NeptuneSaver(npt_logger), n_saved=2, filename_prefix="best", score_function=score_function, score_name="validation_accuracy", global_step_transform=global_step_from_engine(trainer) ) validation_evaluator.add_event_handler(Events.COMPLETED, handler)
It is also possible to use the logger as context manager:
from ignite.contrib.handlers.neptune_logger import * # We are using the api_token for the anonymous user neptuner but you can use your own. with NeptuneLogger(api_token="ANONYMOUS", project_name="shared/pytorch-ignite-integration", experiment_name="cnn-mnist", # Optional, params={"max_epochs": 10}, # Optional, tags=["pytorch-ignite","minst"] # Optional ) as npt_logger: trainer = Engine(update_fn) # Attach the logger to the trainer to log training loss at each iteration npt_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {"loss": loss} )
- attach(engine, log_handler, event_name)
Attach the logger to the engine and execute log_handler function at event_name events.
- Parameters
engine (Engine) – engine object.
log_handler (callable) – a logging handler to execute
event_name – event to attach the logging handler to. Valid events are from
Eventsor any event_name added byregister_events().
- Returns
RemovableEventHandle, which can be used to remove the handler.
- attach_opt_params_handler(engine, event_name, *args, **kwargs)
Shortcut method to attach OptimizerParamsHandler to the logger.
- Parameters
- Returns
RemovableEventHandle, which can be used to remove the handler.
- class ignite.contrib.handlers.neptune_logger.NeptuneSaver(neptune_logger)[source]
Handler that saves input checkpoint to the Neptune server.
- Parameters
neptune_logger (ignite.contrib.handlers.neptune_logger.NeptuneLogger) – an instance of NeptuneLogger class.
Examples
from ignite.contrib.handlers.neptune_logger import * # Create a logger # We are using the api_token for the anonymous user neptuner but you can use your own. npt_logger = NeptuneLogger( api_token="ANONYMOUS", project_name="shared/pytorch-ignite-integration", experiment_name="cnn-mnist", # Optional, params={"max_epochs": 10}, # Optional, tags=["pytorch-ignite","minst"] # Optional ) ... evaluator = create_supervised_evaluator(model, metrics=metrics, ...) ... from ignite.handlers import Checkpoint def score_function(engine): return engine.state.metrics["accuracy"] to_save = {"model": model} # pass neptune logger to NeptuneServer handler = Checkpoint( to_save, NeptuneSaver(npt_logger), n_saved=2, filename_prefix="best", score_function=score_function, score_name="validation_accuracy", global_step_transform=global_step_from_engine(trainer) ) evaluator.add_event_handler(Events.COMPLETED, handler)
- # We need to close the logger when we are done
npt_logger.close()
For example, you can access model checkpoints and download them from here: https://ui.neptune.ai/o/shared/org/pytorch-ignite-integration/e/PYTOR1-18/charts
- class ignite.contrib.handlers.neptune_logger.OptimizerParamsHandler(optimizer, param_name='lr', tag=None)[source]
Helper handler to log optimizer parameters
Examples
from ignite.contrib.handlers.neptune_logger import * # Create a logger # We are using the api_token for the anonymous user neptuner but you can use your own. npt_logger = NeptuneLogger( api_token="ANONYMOUS", project_name="shared/pytorch-ignite-integration", experiment_name="cnn-mnist", # Optional, params={"max_epochs": 10}, # Optional, tags=["pytorch-ignite","minst"] # Optional ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration npt_logger.attach( trainer, log_handler=OptimizerParamsHandler(optimizer), event_name=Events.ITERATION_STARTED ) # or equivalently npt_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer )
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – parameter name
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.neptune_logger.OutputHandler(tag, metric_names=None, output_transform=None, global_step_transform=None)[source]
Helper handler to log engine’s output and/or metrics
Examples
from ignite.contrib.handlers.neptune_logger import * # Create a logger # We are using the api_token for the anonymous user neptuner but you can use your own. npt_logger = NeptuneLogger( api_token="ANONYMOUS", project_name="shared/pytorch-ignite-integration", experiment_name="cnn-mnist", # Optional, params={"max_epochs": 10}, # Optional, tags=["pytorch-ignite","minst"] # Optional ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer`: npt_logger.attach( evaluator, log_handler=OutputHandler( tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) ), event_name=Events.EPOCH_COMPLETED ) # or equivalently npt_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) )
Another example, where model is evaluated every 500 iterations:
from ignite.contrib.handlers.neptune_logger import * @trainer.on(Events.ITERATION_COMPLETED(every=500)) def evaluate(engine): evaluator.run(validation_set, max_epochs=1) # We are using the api_token for the anonymous user neptuner but you can use your own. npt_logger = NeptuneLogger( api_token="ANONYMOUS", project_name="shared/pytorch-ignite-integration", experiment_name="cnn-mnist", # Optional, params={"max_epochs": 10}, # Optional, tags=["pytorch-ignite", "minst"] # Optional ) def global_step_transform(*args, **kwargs): return trainer.state.iteration # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # every 500 iterations. Since evaluator engine does not have access to the training iteration, we # provide a global_step_transform to return the trainer.state.iteration for the global_step, each time # evaluator metrics are plotted on NeptuneML. npt_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metrics=["nll", "accuracy"], global_step_transform=global_step_transform )
- Parameters
tag (str) – common title for all produced plots. For example, “training”
metric_names (list of str, optional) – list of metric names to plot or a string “all” to plot all available metrics.
output_transform (callable, optional) – output transform function to prepare engine.state.output as a number. For example, output_transform = lambda output: output This function can also return a dictionary, e.g {“loss”: loss1, “another_loss”: loss2} to label the plot with corresponding keys.
global_step_transform (callable, optional) – global step transform function to output a desired global step. Input of the function is (engine, event_name). Output of function should be an integer. Default is None, global_step based on attached engine. If provided, uses function output as global_step. To setup global step from another engine, please use
global_step_from_engine().
Note
Example of global_step_transform:
def global_step_transform(engine, event_name): return engine.state.get_event_attrib_value(event_name)
- class ignite.contrib.handlers.neptune_logger.WeightsScalarHandler(model, reduction=<function norm>, tag=None)[source]
Helper handler to log model’s weights as scalars. Handler iterates over named parameters of the model, applies reduction function to each parameter produce a scalar and then logs the scalar.
Examples
from ignite.contrib.handlers.neptune_logger import * # Create a logger # We are using the api_token for the anonymous user neptuner but you can use your own. npt_logger = NeptuneLogger( api_token="ANONYMOUS", project_name="shared/pytorch-ignite-integration", experiment_name="cnn-mnist", # Optional, params={"max_epochs": 10}, # Optional, tags=["pytorch-ignite","minst"] # Optional ) # Attach the logger to the trainer to log model's weights norm after each iteration npt_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsScalarHandler(model, reduction=torch.norm) )
- Parameters
model (torch.nn.Module) – model to log weights
reduction (callable) – function to reduce parameters into scalar
tag (str, optional) – common title for all produced plots. For example, “generator”
- ignite.contrib.handlers.neptune_logger.global_step_from_engine(engine, custom_event_name=None)[source]
Helper method to setup global_step_transform function using another engine. This can be helpful for logging trainer epoch/iteration while output handler is attached to an evaluator.
mlflow_logger
- class ignite.contrib.handlers.mlflow_logger.MLflowLogger(tracking_uri=None)[source]
MLflow tracking client handler to log parameters and metrics during the training and validation.
This class requires mlflow package to be installed:
pip install mlflow
- Parameters
tracking_uri (str) – MLflow tracking uri. See MLflow docs for more details
Examples
from ignite.contrib.handlers.mlflow_logger import * # Create a logger mlflow_logger = MLflowLogger() # Log experiment parameters: mlflow_logger.log_params({ "seed": seed, "batch_size": batch_size, "model": model.__class__.__name__, "pytorch version": torch.__version__, "ignite version": ignite.__version__, "cuda version": torch.version.cuda, "device name": torch.cuda.get_device_name(0) }) # Attach the logger to the trainer to log training loss at each iteration mlflow_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {'loss': loss} ) # Attach the logger to the evaluator on the training dataset and log NLL, Accuracy metrics after each epoch # We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer` instead of `train_evaluator`. mlflow_logger.attach_output_handler( train_evaluator, event_name=Events.EPOCH_COMPLETED, tag="training", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer), ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch of the # `trainer` instead of `evaluator`. mlflow_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer)), ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration mlflow_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer, param_name='lr' # optional )
- attach(engine, log_handler, event_name)
Attach the logger to the engine and execute log_handler function at event_name events.
- Parameters
engine (Engine) – engine object.
log_handler (callable) – a logging handler to execute
event_name – event to attach the logging handler to. Valid events are from
Eventsor any event_name added byregister_events().
- Returns
RemovableEventHandle, which can be used to remove the handler.
- attach_opt_params_handler(engine, event_name, *args, **kwargs)
Shortcut method to attach OptimizerParamsHandler to the logger.
- Parameters
- Returns
RemovableEventHandle, which can be used to remove the handler.
- class ignite.contrib.handlers.mlflow_logger.OptimizerParamsHandler(optimizer, param_name='lr', tag=None)[source]
Helper handler to log optimizer parameters
Examples
from ignite.contrib.handlers.mlflow_logger import * # Create a logger mlflow_logger = MLflowLogger() # Optionally, user can specify tracking_uri with corresponds to MLFLOW_TRACKING_URI # mlflow_logger = MLflowLogger(tracking_uri="uri") # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration mlflow_logger.attach( trainer, log_handler=OptimizerParamsHandler(optimizer), event_name=Events.ITERATION_STARTED ) # or equivalently mlflow_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer )
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – parameter name
tag (str, optional) – common title for all produced plots. For example, ‘generator’
- class ignite.contrib.handlers.mlflow_logger.OutputHandler(tag, metric_names=None, output_transform=None, global_step_transform=None)[source]
Helper handler to log engine’s output and/or metrics.
Examples
from ignite.contrib.handlers.mlflow_logger import * # Create a logger mlflow_logger = MLflowLogger() # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer`: mlflow_logger.attach( evaluator, log_handler=OutputHandler( tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) ), event_name=Events.EPOCH_COMPLETED ) # or equivalently mlflow_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) )
Another example, where model is evaluated every 500 iterations:
from ignite.contrib.handlers.mlflow_logger import * @trainer.on(Events.ITERATION_COMPLETED(every=500)) def evaluate(engine): evaluator.run(validation_set, max_epochs=1) mlflow_logger = MLflowLogger() def global_step_transform(*args, **kwargs): return trainer.state.iteration # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # every 500 iterations. Since evaluator engine does not have access to the training iteration, we # provide a global_step_transform to return the trainer.state.iteration for the global_step, each time # evaluator metrics are plotted on MLflow. mlflow_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metrics=["nll", "accuracy"], global_step_transform=global_step_transform )
- Parameters
tag (str) – common title for all produced plots. For example, ‘training’
metric_names (list of str, optional) – list of metric names to plot or a string “all” to plot all available metrics.
output_transform (callable, optional) – output transform function to prepare engine.state.output as a number. For example, output_transform = lambda output: output This function can also return a dictionary, e.g {‘loss’: loss1, ‘another_loss’: loss2} to label the plot with corresponding keys.
global_step_transform (callable, optional) – global step transform function to output a desired global step. Input of the function is (engine, event_name). Output of function should be an integer. Default is None, global_step based on attached engine. If provided, uses function output as global_step. To setup global step from another engine, please use
global_step_from_engine().
Note
Example of global_step_transform:
def global_step_transform(engine, event_name): return engine.state.get_event_attrib_value(event_name)
- ignite.contrib.handlers.mlflow_logger.global_step_from_engine(engine, custom_event_name=None)[source]
Helper method to setup global_step_transform function using another engine. This can be helpful for logging trainer epoch/iteration while output handler is attached to an evaluator.
tqdm_logger
See tqdm mnist example for detailed usage.
- class ignite.contrib.handlers.tqdm_logger.ProgressBar(persist=False, bar_format='{desc}[{n_fmt}/{total_fmt}] {percentage:3.0f}%|{bar}{postfix} [{elapsed}<{remaining}]', **tqdm_kwargs)[source]
TQDM progress bar handler to log training progress and computed metrics.
- Parameters
persist (bool, optional) – set to
Trueto persist the progress bar after completion (default =False)bar_format (str, optional) – Specify a custom bar string formatting. May impact performance. [default: ‘{desc}[{n_fmt}/{total_fmt}] {percentage:3.0f}%|{bar}{postfix} [{elapsed}<{remaining}]’]. Set to
Noneto usetqdmdefault bar formatting: ‘{l_bar}{bar}{r_bar}’, where l_bar=’{desc}: {percentage:3.0f}%|’ and r_bar=’| {n_fmt}/{total_fmt} [{elapsed}<{remaining}, {rate_fmt}{postfix}]’. For more details on the formatting, see tqdm docs.**tqdm_kwargs – kwargs passed to tqdm progress bar. By default, progress bar description displays “Epoch [5/10]” where 5 is the current epoch and 10 is the number of epochs. If tqdm_kwargs defines desc, e.g. “Predictions”, than the description is “Predictions [5/10]” if number of epochs is more than one otherwise it is simply “Predictions”.
Examples
Simple progress bar
trainer = create_supervised_trainer(model, optimizer, loss) pbar = ProgressBar() pbar.attach(trainer) # Progress bar will looks like # Epoch [2/50]: [64/128] 50%|█████ [06:17<12:34]
Log output to a file instead of stderr (tqdm’s default output)
trainer = create_supervised_trainer(model, optimizer, loss) log_file = open("output.log", "w") pbar = ProgressBar(file=log_file) pbar.attach(trainer)
Attach metrics that already have been computed at
ITERATION_COMPLETED(such asRunningAverage)trainer = create_supervised_trainer(model, optimizer, loss) RunningAverage(output_transform=lambda x: x).attach(trainer, 'loss') pbar = ProgressBar() pbar.attach(trainer, ['loss']) # Progress bar will looks like # Epoch [2/50]: [64/128] 50%|█████ , loss=0.123 [06:17<12:34]
Directly attach the engine’s output
trainer = create_supervised_trainer(model, optimizer, loss) pbar = ProgressBar() pbar.attach(trainer, output_transform=lambda x: {'loss': x}) # Progress bar will looks like # Epoch [2/50]: [64/128] 50%|█████ , loss=0.123 [06:17<12:34]
Note
When adding attaching the progress bar to an engine, it is recommend that you replace every print operation in the engine’s handlers triggered every iteration with
pbar.log_messageto guarantee the correct format of the stdout.Note
When using inside jupyter notebook, ProgressBar automatically uses tqdm_notebook. For correct rendering, please install ipywidgets. Due to tqdm notebook bugs, bar format may be needed to be set to an empty string value.
- attach(engine, metric_names=None, output_transform=None, event_name=Events.ITERATION_COMPLETED, closing_event_name=Events.EPOCH_COMPLETED)[source]
Attaches the progress bar to an engine object.
- Parameters
engine (Engine) – engine object.
metric_names (list of str, optional) – list of metric names to plot or a string “all” to plot all available metrics.
output_transform (callable, optional) – a function to select what you want to print from the engine’s output. This function may return either a dictionary with entries in the format of
{name: value}, or a single scalar, which will be displayed with the default name output.event_name – event’s name on which the progress bar advances. Valid events are from
Events.closing_event_name – event’s name on which the progress bar is closed. Valid events are from
Events.
Note: accepted output value types are numbers, 0d and 1d torch tensors and strings
- attach_opt_params_handler(engine, event_name, *args, **kwargs)[source]
Intentionally empty
polyaxon_logger
- class ignite.contrib.handlers.polyaxon_logger.OptimizerParamsHandler(optimizer, param_name='lr', tag=None)[source]
Helper handler to log optimizer parameters
Examples
from ignite.contrib.handlers.polyaxon_logger import * # Create a logger plx_logger = PolyaxonLogger() # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration plx_logger.attach( trainer, log_handler=OptimizerParamsHandler(optimizer), event_name=Events.ITERATION_STARTED ) # or equivalently plx_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer )
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – parameter name
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.polyaxon_logger.OutputHandler(tag, metric_names=None, output_transform=None, global_step_transform=None)[source]
Helper handler to log engine’s output and/or metrics.
Examples
from ignite.contrib.handlers.polyaxon_logger import * # Create a logger plx_logger = PolyaxonLogger() # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer`: plx_logger.attach( evaluator, log_handler=OutputHandler( tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) ), event_name=Events.EPOCH_COMPLETED ) # or equivalently plx_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) )
Another example, where model is evaluated every 500 iterations:
from ignite.contrib.handlers.polyaxon_logger import * @trainer.on(Events.ITERATION_COMPLETED(every=500)) def evaluate(engine): evaluator.run(validation_set, max_epochs=1) plx_logger = PolyaxonLogger() def global_step_transform(*args, **kwargs): return trainer.state.iteration # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # every 500 iterations. Since evaluator engine does not have access to the training iteration, we # provide a global_step_transform to return the trainer.state.iteration for the global_step, each time # evaluator metrics are plotted on Polyaxon. plx_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metrics=["nll", "accuracy"], global_step_transform=global_step_transform )
- Parameters
tag (str) – common title for all produced plots. For example, “training”
metric_names (list of str, optional) – list of metric names to plot or a string “all” to plot all available metrics.
output_transform (callable, optional) – output transform function to prepare engine.state.output as a number. For example, output_transform = lambda output: output This function can also return a dictionary, e.g {“loss”: loss1, “another_loss”: loss2} to label the plot with corresponding keys.
global_step_transform (callable, optional) – global step transform function to output a desired global step. Input of the function is (engine, event_name). Output of function should be an integer. Default is None, global_step based on attached engine. If provided, uses function output as global_step. To setup global step from another engine, please use
global_step_from_engine().
Note
Example of global_step_transform:
def global_step_transform(engine, event_name): return engine.state.get_event_attrib_value(event_name)
- class ignite.contrib.handlers.polyaxon_logger.PolyaxonLogger(*args, **kwargs)[source]
Polyaxon tracking client handler to log parameters and metrics during the training and validation.
This class requires polyaxon-client package to be installed:
pip install polyaxon-client
Examples
from ignite.contrib.handlers.polyaxon_logger import * # Create a logger plx_logger = PolyaxonLogger() # Log experiment parameters: plx_logger.log_params(**{ "seed": seed, "batch_size": batch_size, "model": model.__class__.__name__, "pytorch version": torch.__version__, "ignite version": ignite.__version__, "cuda version": torch.version.cuda, "device name": torch.cuda.get_device_name(0) }) # Attach the logger to the trainer to log training loss at each iteration plx_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {"loss": loss} ) # Attach the logger to the evaluator on the training dataset and log NLL, Accuracy metrics after each epoch # We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer` instead of `train_evaluator`. plx_logger.attach_output_handler( train_evaluator, event_name=Events.EPOCH_COMPLETED, tag="training", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer), ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch of the # `trainer` instead of `evaluator`. plx_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer)), ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration plx_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer, param_name='lr' # optional )
- Parameters
*args – Positional arguments accepted from Experiment.
**kwargs –
Keyword arguments accepted from Experiment.
- attach(engine, log_handler, event_name)
Attach the logger to the engine and execute log_handler function at event_name events.
- Parameters
engine (Engine) – engine object.
log_handler (callable) – a logging handler to execute
event_name – event to attach the logging handler to. Valid events are from
Eventsor any event_name added byregister_events().
- Returns
RemovableEventHandle, which can be used to remove the handler.
- attach_opt_params_handler(engine, event_name, *args, **kwargs)
Shortcut method to attach OptimizerParamsHandler to the logger.
- Parameters
- Returns
RemovableEventHandle, which can be used to remove the handler.
- ignite.contrib.handlers.polyaxon_logger.global_step_from_engine(engine, custom_event_name=None)[source]
Helper method to setup global_step_transform function using another engine. This can be helpful for logging trainer epoch/iteration while output handler is attached to an evaluator.
wandb_logger
See wandb mnist example for detailed usage.
- class ignite.contrib.handlers.wandb_logger.OptimizerParamsHandler(optimizer, param_name='lr', tag=None, sync=None)[source]
Helper handler to log optimizer parameters
Examples
from ignite.contrib.handlers.wandb_logger import * # Create a logger. All parameters are optional. See documentation # on wandb.init for details. wandb_logger = WandBLogger( entity="shared", project="pytorch-ignite-integration", name="cnn-mnist", config={"max_epochs": 10}, tags=["pytorch-ignite", "minst"] ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration wandb_logger.attach( trainer, log_handler=OptimizerParamsHandler(optimizer), event_name=Events.ITERATION_STARTED ) # or equivalently wandb_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer )
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – parameter name
tag (str, optional) – common title for all produced plots. For example, “generator”
sync (bool, optional) – If set to False, process calls to log in a seperate thread. Default (None) uses whatever the default value of wandb.log.
- class ignite.contrib.handlers.wandb_logger.OutputHandler(tag, metric_names=None, output_transform=None, global_step_transform=None, sync=None)[source]
Helper handler to log engine’s output and/or metrics
Examples
from ignite.contrib.handlers.wandb_logger import * # Create a logger. All parameters are optional. See documentation # on wandb.init for details. wandb_logger = WandBLogger( entity="shared", project="pytorch-ignite-integration", name="cnn-mnist", config={"max_epochs": 10}, tags=["pytorch-ignite", "minst"] ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=lambda *_: trainer.state.iteration,` to take iteration value # of the `trainer`: wandb_logger.attach( evaluator, log_handler=OutputHandler( tag="validation", metric_names=["nll", "accuracy"], global_step_transform=lambda *_: trainer.state.iteration, ), event_name=Events.EPOCH_COMPLETED ) # or equivalently wandb_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=lambda *_: trainer.state.iteration, )
Another example, where model is evaluated every 500 iterations:
from ignite.contrib.handlers.wandb_logger import * @trainer.on(Events.ITERATION_COMPLETED(every=500)) def evaluate(engine): evaluator.run(validation_set, max_epochs=1) # Create a logger. All parameters are optional. See documentation # on wandb.init for details. wandb_logger = WandBLogger( entity="shared", project="pytorch-ignite-integration", name="cnn-mnist", config={"max_epochs": 10}, tags=["pytorch-ignite", "minst"] ) def global_step_transform(*args, **kwargs): return trainer.state.iteration # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # every 500 iterations. Since evaluator engine does not have access to the training iteration, we # provide a global_step_transform to return the trainer.state.iteration for the global_step, each time # evaluator metrics are plotted on Weights & Biases. wandb_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metrics=["nll", "accuracy"], global_step_transform=global_step_transform )
- Parameters
tag (str) – common title for all produced plots. For example, “training”
metric_names (list of str, optional) – list of metric names to plot or a string “all” to plot all available metrics.
output_transform (callable, optional) – output transform function to prepare engine.state.output as a number. For example, output_transform = lambda output: output This function can also return a dictionary, e.g {“loss”: loss1, “another_loss”: loss2} to label the plot with corresponding keys.
global_step_transform (callable, optional) – global step transform function to output a desired global step. Input of the function is (engine, event_name). Output of function should be an integer. Default is None, global_step based on attached engine. If provided, uses function output as global_step. To setup global step from another engine, please use
global_step_from_engine().sync (bool, optional) – If set to False, process calls to log in a seperate thread. Default (None) uses whatever the default value of wandb.log.
Note
Example of global_step_transform:
def global_step_transform(engine, event_name): return engine.state.get_event_attrib_value(event_name)
- class ignite.contrib.handlers.wandb_logger.WandBLogger(*args, **kwargs)[source]
Weights & Biases handler to log metrics, model/optimizer parameters, gradients during training and validation. It can also be used to log model checkpoints to the Weights & Biases cloud.
pip install wandb
This class is also a wrapper for the wandb module. This means that you can call any wandb function using this wrapper. See examples on how to save model parameters and gradients.
- Parameters
*args – Positional arguments accepted by wandb.init.
**kwargs – Keyword arguments accepted by wandb.init. Please see wandb.init for documentation of possible parameters.
Examples
from ignite.contrib.handlers.wandb_logger import * # Create a logger. All parameters are optional. See documentation # on wandb.init for details. wandb_logger = WandBLogger( entity="shared", project="pytorch-ignite-integration", name="cnn-mnist", config={"max_epochs": 10}, tags=["pytorch-ignite", "minst"] ) # Attach the logger to the trainer to log training loss at each iteration wandb_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {"loss": loss} ) # Attach the logger to the evaluator on the training dataset and log NLL, Accuracy metrics after each epoch # We setup `global_step_transform=lambda *_: trainer.state.iteration` to take iteration value # of the `trainer`: wandb_logger.attach_output_handler( train_evaluator, event_name=Events.EPOCH_COMPLETED, tag="training", metric_names=["nll", "accuracy"], global_step_transform=lambda *_: trainer.state.iteration, ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=lambda *_: trainer.state.iteration` to take iteration value # of the `trainer` instead of `evaluator`. wandb_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=lambda *_: trainer.state.iteration, ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration wandb_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer, param_name='lr' # optional )
If you want to log model gradients, the model call graph, etc., use the logger as wrapper of wandb. Refer to the documentation of wandb.watch for details:
wandb_logger = WandBLogger( entity="shared", project="pytorch-ignite-integration", name="cnn-mnist", config={"max_epochs": 10}, tags=["pytorch-ignite", "minst"] ) model = torch.nn.Sequential(...) wandb_logger.watch(model)
For model checkpointing, Weights & Biases creates a local run dir, and automatically synchronizes all files saved there at the end of the run. You can just use the wandb_logger.run.dir as path for the ModelCheckpoint:
from ignite.handlers import ModelCheckpoint def score_function(engine): return engine.state.metrics['accuracy'] model_checkpoint = ModelCheckpoint( wandb_logger.run.dir, n_saved=2, filename_prefix='best', require_empty=False, score_function=score_function, score_name="validation_accuracy", global_step_transform=global_step_from_engine(trainer) ) evaluator.add_event_handler(Events.COMPLETED, model_checkpoint, {'model': model})
- attach(engine, log_handler, event_name)
Attach the logger to the engine and execute log_handler function at event_name events.
- Parameters
engine (Engine) – engine object.
log_handler (callable) – a logging handler to execute
event_name – event to attach the logging handler to. Valid events are from
Eventsor any event_name added byregister_events().
- Returns
RemovableEventHandle, which can be used to remove the handler.
- attach_opt_params_handler(engine, event_name, *args, **kwargs)
Shortcut method to attach OptimizerParamsHandler to the logger.
- Parameters
- Returns
RemovableEventHandle, which can be used to remove the handler.
- ignite.contrib.handlers.wandb_logger.global_step_from_engine(engine, custom_event_name=None)[source]
Helper method to setup global_step_transform function using another engine. This can be helpful for logging trainer epoch/iteration while output handler is attached to an evaluator.
trains_logger
See trains mnist example for detailed usage.
- class ignite.contrib.handlers.trains_logger.GradsHistHandler(model, tag=None)[source]
Helper handler to log model’s gradients as histograms.
Examples
from ignite.contrib.handlers.trains_logger import * # Create a logger trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) # Attach the logger to the trainer to log model's weights norm after each iteration trains_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=GradsHistHandler(model) )
- Parameters
model (torch.nn.Module) – model to log weights
tag (str, optional) – common title for all produced plots. For example, ‘generator’
- class ignite.contrib.handlers.trains_logger.GradsScalarHandler(model, reduction=<function norm>, tag=None)[source]
Helper handler to log model’s gradients as scalars. Handler iterates over the gradients of named parameters of the model, applies reduction function to each parameter produce a scalar and then logs the scalar.
Examples
from ignite.contrib.handlers.trains_logger import * # Create a logger trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) # Attach the logger to the trainer to log model's weights norm after each iteration trains_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=GradsScalarHandler(model, reduction=torch.norm) )
- Parameters
model (torch.nn.Module) – model to log weights
reduction (callable) – function to reduce parameters into scalar
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.trains_logger.OptimizerParamsHandler(optimizer, param_name='lr', tag=None)[source]
Helper handler to log optimizer parameters
Examples
from ignite.contrib.handlers.trains_logger import * # Create a logger trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration trains_logger.attach( trainer, log_handler=OptimizerParamsHandler(optimizer), event_name=Events.ITERATION_STARTED ) # or equivalently trains_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer )
- Parameters
optimizer (torch.optim.Optimizer or object) – torch optimizer or any object with attribute
param_groupsas a sequence.param_name (str) – parameter name
tag (str, optional) – common title for all produced plots. For example, “generator”
- class ignite.contrib.handlers.trains_logger.OutputHandler(tag, metric_names=None, output_transform=None, global_step_transform=None)[source]
Helper handler to log engine’s output and/or metrics
Examples
from ignite.contrib.handlers.trains_logger import * # Create a logger trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer`: trains_logger.attach( evaluator, log_handler=OutputHandler( tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) ), event_name=Events.EPOCH_COMPLETED ) # or equivalently trains_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer) )
Another example, where model is evaluated every 500 iterations:
from ignite.contrib.handlers.trains_logger import * @trainer.on(Events.ITERATION_COMPLETED(every=500)) def evaluate(engine): evaluator.run(validation_set, max_epochs=1) # Create a logger trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) def global_step_transform(*args, **kwargs): return trainer.state.iteration # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # every 500 iterations. Since evaluator engine does not have access to the training iteration, we # provide a global_step_transform to return the trainer.state.iteration for the global_step, each time # evaluator metrics are plotted on Trains. trains_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metrics=["nll", "accuracy"], global_step_transform=global_step_transform )
- Parameters
tag (str) – common title for all produced plots. For example, “training”
metric_names (list of str, optional) – list of metric names to plot or a string “all” to plot all available metrics.
output_transform (callable, optional) – output transform function to prepare engine.state.output as a number. For example, output_transform = lambda output: output This function can also return a dictionary, e.g {“loss”: loss1, “another_loss”: loss2} to label the plot with corresponding keys.
global_step_transform (callable, optional) – global step transform function to output a desired global step. Input of the function is (engine, event_name). Output of function should be an integer. Default is None, global_step based on attached engine. If provided, uses function output as global_step. To setup global step from another engine, please use
global_step_from_engine().
Note
Example of global_step_transform:
def global_step_transform(engine, event_name): return engine.state.get_event_attrib_value(event_name)
- class ignite.contrib.handlers.trains_logger.TrainsLogger(*_, **kwargs)[source]
Trains handler to log metrics, text, model/optimizer parameters, plots during training and validation. Also supports model checkpoints logging and upload to the storage solution of your choice (i.e. Trains File server, S3 bucket etc.)
pip install trains trains-init
- Parameters
project_name (str) – The name of the project in which the experiment will be created. If the project does not exist, it is created. If
project_nameisNone, the repository name is used. (Optional)task_name (str) – The name of Task (experiment). If
task_nameisNone, the Python experiment script’s file name is used. (Optional)task_type (str) – Optional. The task type. Valid values are: -
TaskTypes.training(Default) -TaskTypes.train-TaskTypes.testing-TaskTypes.inference
Examples
from ignite.contrib.handlers.trains_logger import * # Create a logger trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) # Attach the logger to the trainer to log training loss at each iteration trains_logger.attach_output_handler( trainer, event_name=Events.ITERATION_COMPLETED, tag="training", output_transform=lambda loss: {"loss": loss} ) # Attach the logger to the evaluator on the training dataset and log NLL, Accuracy metrics after each epoch # We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch # of the `trainer` instead of `train_evaluator`. trains_logger.attach_output_handler( train_evaluator, event_name=Events.EPOCH_COMPLETED, tag="training", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer), ) # Attach the logger to the evaluator on the validation dataset and log NLL, Accuracy metrics after # each epoch. We setup `global_step_transform=global_step_from_engine(trainer)` to take the epoch of the # `trainer` instead of `evaluator`. trains_logger.attach_output_handler( evaluator, event_name=Events.EPOCH_COMPLETED, tag="validation", metric_names=["nll", "accuracy"], global_step_transform=global_step_from_engine(trainer)), ) # Attach the logger to the trainer to log optimizer's parameters, e.g. learning rate at each iteration trains_logger.attach_opt_params_handler( trainer, event_name=Events.ITERATION_STARTED, optimizer=optimizer, param_name='lr' # optional ) # Attach the logger to the trainer to log model's weights norm after each iteration trains_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsScalarHandler(model) )
- attach(engine, log_handler, event_name)
Attach the logger to the engine and execute log_handler function at event_name events.
- Parameters
engine (Engine) – engine object.
log_handler (callable) – a logging handler to execute
event_name – event to attach the logging handler to. Valid events are from
Eventsor any event_name added byregister_events().
- Returns
RemovableEventHandle, which can be used to remove the handler.
- attach_opt_params_handler(engine, event_name, *args, **kwargs)
Shortcut method to attach OptimizerParamsHandler to the logger.
- Parameters
- Returns
RemovableEventHandle, which can be used to remove the handler.
- attach_output_handler(engine, event_name, *args, **kwargs)
Shortcut method to attach OutputHandler to the logger.
- Parameters
- Returns
RemovableEventHandle, which can be used to remove the handler.
- classmethod bypass_mode()[source]
Returns the bypass mode state. .. note:
`GITHUB_ACTIONS` env will automatically set bypass_mode to ``True`` unless overridden specifically with ``TrainsLogger.set_bypass_mode(False)``.
- Returns
If True, all outside communication is skipped.
- Return type
- classmethod set_bypass_mode(bypass)[source]
Will bypass all outside communication, and will drop all logs. Should only be used in “standalone mode”, when there is no access to the trains-server. :param bypass: If
True, all outside communication is skipped.- Parameters
bypass (bool) –
- Return type
None
- class ignite.contrib.handlers.trains_logger.TrainsSaver(logger=None, output_uri=None, dirname=None, *args, **kwargs)[source]
Handler that saves input checkpoint as Trains artifacts
- Parameters
logger (TrainsLogger, optional) – An instance of
TrainsLogger, ensuring a valid TrainsTaskhas been initialized. If not provided, and a Trains Task has not been manually initialized, a runtime error will be raised.output_uri (str, optional) – The default location for output models and other artifacts uploaded by Trains. For more information, see
trains.Task.init.dirname (str, optional) – Directory path where the checkpoint will be saved. If not provided, a temporary directory will be created.
Examples
from ignite.contrib.handlers.trains_logger import * from ignite.handlers import Checkpoint trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) to_save = {"model": model} handler = Checkpoint( to_save, TrainsSaver(), n_saved=1, score_function=lambda e: 123, score_name="acc", filename_prefix="best", global_step_transform=global_step_from_engine(trainer) ) validation_evaluator.add_event_handler(Events.EVENT_COMPLETED, handler)
- get_local_copy(filename)[source]
Get artifact local copy.
Warning
In distributed configuration this method should be called on rank 0 process.
- class ignite.contrib.handlers.trains_logger.WeightsHistHandler(model, tag=None)[source]
Helper handler to log model’s weights as histograms.
Examples
from ignite.contrib.handlers.trains_logger import * # Create a logger trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) # Attach the logger to the trainer to log model's weights norm after each iteration trains_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsHistHandler(model) )
- Parameters
model (torch.nn.Module) – model to log weights
tag (str, optional) – common title for all produced plots. For example, ‘generator’
- class ignite.contrib.handlers.trains_logger.WeightsScalarHandler(model, reduction=<function norm>, tag=None)[source]
Helper handler to log model’s weights as scalars. Handler iterates over named parameters of the model, applies reduction function to each parameter produce a scalar and then logs the scalar.
Examples
from ignite.contrib.handlers.trains_logger import * # Create a logger trains_logger = TrainsLogger( project_name="pytorch-ignite-integration", task_name="cnn-mnist" ) # Attach the logger to the trainer to log model's weights norm after each iteration trains_logger.attach( trainer, event_name=Events.ITERATION_COMPLETED, log_handler=WeightsScalarHandler(model, reduction=torch.norm) )
- Parameters
model (torch.nn.Module) – model to log weights
reduction (callable) – function to reduce parameters into scalar
tag (str, optional) – common title for all produced plots. For example, “generator”
- ignite.contrib.handlers.trains_logger.global_step_from_engine(engine, custom_event_name=None)[source]
Helper method to setup global_step_transform function using another engine. This can be helpful for logging trainer epoch/iteration while output handler is attached to an evaluator.
More on parameter scheduling
In this section there are visual examples of various parameter schedulings that can be achieved.
Example with ignite.contrib.handlers.CosineAnnealingScheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.contrib.handlers import CosineAnnealingScheduler
lr_values_1 = np.array(CosineAnnealingScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2, cycle_size=20))
lr_values_2 = np.array(CosineAnnealingScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2, cycle_size=20, cycle_mult=1.3))
lr_values_3 = np.array(CosineAnnealingScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2,
cycle_size=20, start_value_mult=0.7))
lr_values_4 = np.array(CosineAnnealingScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2,
cycle_size=20, end_value_mult=0.1))
plt.figure(figsize=(25, 5))
plt.subplot(141)
plt.title("Cosine annealing")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(142)
plt.title("Cosine annealing with cycle_mult=1.3")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(143)
plt.title("Cosine annealing with start_value_mult=0.7")
plt.plot(lr_values_3[:, 0], lr_values_3[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(144)
plt.title("Cosine annealing with end_value_mult=0.1")
plt.plot(lr_values_4[:, 0], lr_values_4[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
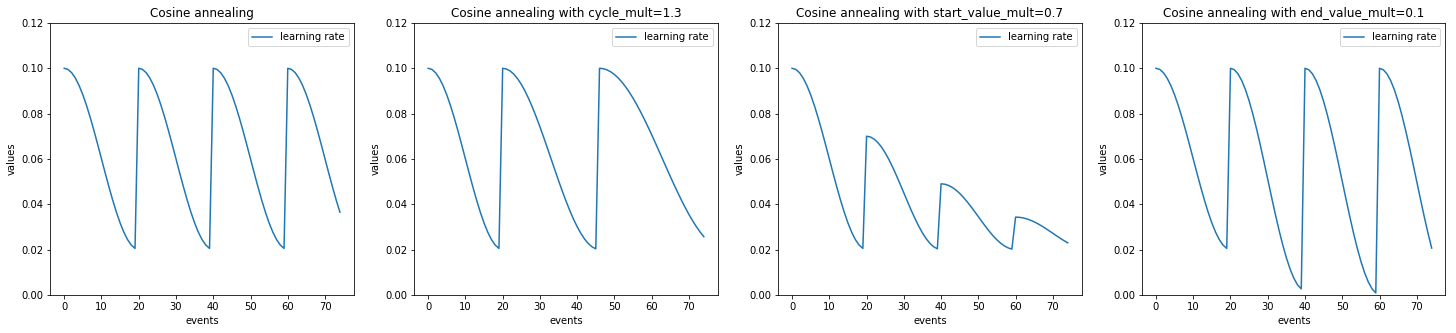
Example with ignite.contrib.handlers.LinearCyclicalScheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.contrib.handlers import LinearCyclicalScheduler
lr_values_1 = np.array(LinearCyclicalScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2, cycle_size=20))
lr_values_2 = np.array(LinearCyclicalScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2, cycle_size=20, cycle_mult=1.3))
lr_values_3 = np.array(LinearCyclicalScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2,
cycle_size=20, start_value_mult=0.7))
lr_values_4 = np.array(LinearCyclicalScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2,
cycle_size=20, end_value_mult=0.1))
plt.figure(figsize=(25, 5))
plt.subplot(141)
plt.title("Linear cyclical scheduler")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(142)
plt.title("Linear cyclical scheduler with cycle_mult=1.3")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(143)
plt.title("Linear cyclical scheduler with start_value_mult=0.7")
plt.plot(lr_values_3[:, 0], lr_values_3[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(144)
plt.title("Linear cyclical scheduler with end_value_mult=0.1")
plt.plot(lr_values_4[:, 0], lr_values_4[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
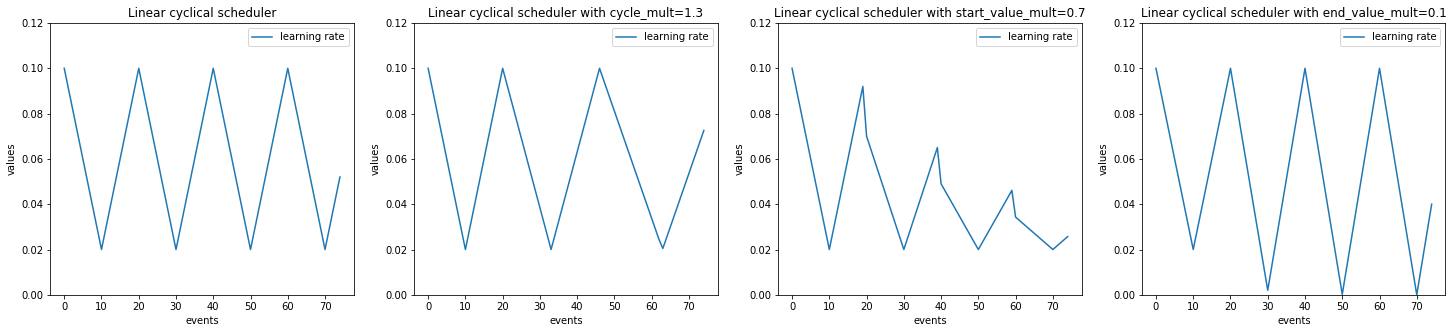
Example with ignite.contrib.handlers.ConcatScheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.contrib.handlers import LinearCyclicalScheduler, CosineAnnealingScheduler, ConcatScheduler
import torch
t1 = torch.zeros([1], requires_grad=True)
optimizer = torch.optim.SGD([t1], lr=0.1)
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.1, end_value=0.5, cycle_size=30)
scheduler_2 = CosineAnnealingScheduler(optimizer, "lr", start_value=0.5, end_value=0.01, cycle_size=50)
durations = [15, ]
lr_values_1 = np.array(ConcatScheduler.simulate_values(num_events=100, schedulers=[scheduler_1, scheduler_2], durations=durations))
t1 = torch.zeros([1], requires_grad=True)
optimizer = torch.optim.SGD([t1], lr=0.1)
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.1, end_value=0.5, cycle_size=30)
scheduler_2 = CosineAnnealingScheduler(optimizer, "momentum", start_value=0.5, end_value=0.01, cycle_size=50)
durations = [15, ]
lr_values_2 = np.array(ConcatScheduler.simulate_values(num_events=100, schedulers=[scheduler_1, scheduler_2], durations=durations,
param_names=["lr", "momentum"]))
plt.figure(figsize=(25, 5))
plt.subplot(131)
plt.title("Concat scheduler of linear + cosine annealing")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(132)
plt.title("Concat scheduler of linear LR scheduler\n and cosine annealing on momentum")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(133)
plt.title("Concat scheduler of linear LR scheduler\n and cosine annealing on momentum")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 2], label="momentum")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
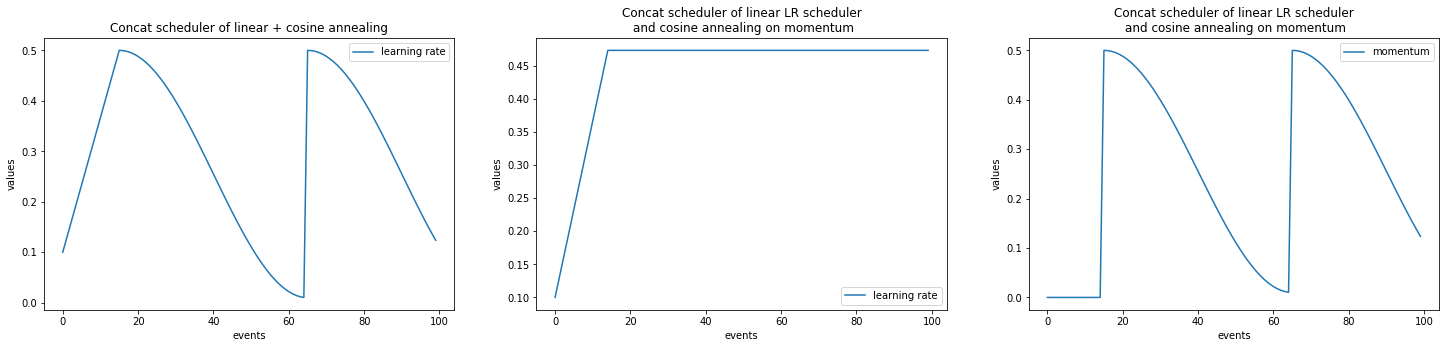
Piecewise linear scheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.contrib.handlers import LinearCyclicalScheduler, ConcatScheduler
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.0, end_value=0.6, cycle_size=50)
scheduler_2 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.6, end_value=0.0, cycle_size=150)
durations = [25, ]
lr_values = np.array(ConcatScheduler.simulate_values(num_events=100, schedulers=[scheduler_1, scheduler_2], durations=durations))
plt.title("Piecewise linear scheduler")
plt.plot(lr_values[:, 0], lr_values[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
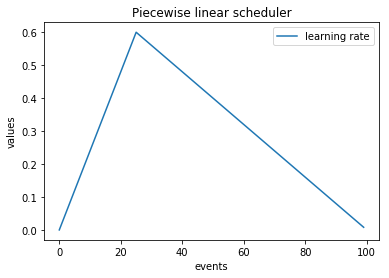
Example with ignite.contrib.handlers.LRScheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.contrib.handlers import LRScheduler
import torch
from torch.optim.lr_scheduler import ExponentialLR, StepLR, CosineAnnealingLR
tensor = torch.zeros([1], requires_grad=True)
optimizer = torch.optim.SGD([tensor], lr=0.1)
lr_scheduler_1 = StepLR(optimizer=optimizer, step_size=10, gamma=0.77)
lr_scheduler_2 = ExponentialLR(optimizer=optimizer, gamma=0.98)
lr_scheduler_3 = CosineAnnealingLR(optimizer=optimizer, T_max=10, eta_min=0.01)
lr_values_1 = np.array(LRScheduler.simulate_values(num_events=100, lr_scheduler=lr_scheduler_1))
lr_values_2 = np.array(LRScheduler.simulate_values(num_events=100, lr_scheduler=lr_scheduler_2))
lr_values_3 = np.array(LRScheduler.simulate_values(num_events=100, lr_scheduler=lr_scheduler_3))
plt.figure(figsize=(25, 5))
plt.subplot(131)
plt.title("Torch LR scheduler wrapping StepLR")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(132)
plt.title("Torch LR scheduler wrapping ExponentialLR")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(133)
plt.title("Torch LR scheduler wrapping CosineAnnealingLR")
plt.plot(lr_values_3[:, 0], lr_values_3[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
Concatenate with torch schedulers
import numpy as np
import matplotlib.pylab as plt
from ignite.contrib.handlers import LRScheduler, ConcatScheduler
import torch
from torch.optim.lr_scheduler import ExponentialLR, StepLR
t1 = torch.zeros([1], requires_grad=True)
optimizer = torch.optim.SGD([t1], lr=0.1)
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.001, end_value=0.1, cycle_size=30)
lr_scheduler = ExponentialLR(optimizer=optimizer, gamma=0.7)
scheduler_2 = LRScheduler(lr_scheduler=lr_scheduler)
durations = [15, ]
lr_values_1 = np.array(ConcatScheduler.simulate_values(num_events=30, schedulers=[scheduler_1, scheduler_2], durations=durations))
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.001, end_value=0.1, cycle_size=30)
lr_scheduler = StepLR(optimizer=optimizer, step_size=10, gamma=0.7)
scheduler_2 = LRScheduler(lr_scheduler=lr_scheduler)
durations = [15, ]
lr_values_2 = np.array(ConcatScheduler.simulate_values(num_events=75, schedulers=[scheduler_1, scheduler_2], durations=durations))
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.title("Concat scheduler of linear + ExponentialLR")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(122)
plt.title("Concat scheduler of linear + StepLR")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()