ignite.handlers
Complete list of generic handlers
Checkpoint handler can be used to periodically save and load objects which have attribute |
|
Handler that saves input checkpoint on a disk. |
|
ModelCheckpoint handler, inherits from |
|
Exponential moving average (EMA) handler can be used to compute a smoothed version of model. |
|
EarlyStopping handler can be used to stop the training if no improvement after a given number of events. |
|
Learning rate finder handler for supervised trainers. |
|
TerminateOnNan handler can be used to stop the training if the process_function's output contains a NaN or infinite number or torch.tensor. |
|
TimeLimit handler can be used to control training time for computing environments where session time is limited. |
|
BasicTimeProfiler can be used to profile the handlers, events, data loading and data processing times. |
|
HandlersTimeProfiler can be used to profile the handlers, data loading and data processing times. |
|
Timer object can be used to measure (average) time between events. |
|
Helper method to setup global_step_transform function using another engine. |
|
EpochOutputStore handler to save output prediction and target history after every epoch, could be useful for e.g., visualization purposes. |
Base class for save handlers |
|
An abstract class for updating an optimizer's parameter value during training. |
|
An abstract class for updating an engine state parameter values during training. |
Loggers
Base logger and its helper handlers. |
|
ClearML logger and its helper handlers. |
|
MLflow logger and its helper handlers. |
|
Neptune logger and its helper handlers. |
|
Polyaxon logger and its helper handlers. |
|
TensorBoard logger and its helper handlers. |
|
TQDM logger. |
|
Visdom logger and its helper handlers. |
|
WandB logger and its helper handlers. |
|
FBResearch logger and its helper handlers. |
See also
Below are a comprehensive list of examples of various loggers.
See tensorboardX mnist example and CycleGAN and EfficientNet notebooks for detailed usage.
See visdom mnist example for detailed usage.
See neptune mnist example for detailed usage.
See tqdm mnist example for detailed usage.
See wandb mnist example for detailed usage.
See clearml mnist example for detailed usage.
Parameter scheduler
An abstract class for updating an engine state or optimizer's parameter value during training. |
|
Concat a list of parameter schedulers. |
|
Anneals 'start_value' to 'end_value' over each cycle. |
|
An abstract class for updating an optimizer's parameter value over a cycle of some size. |
|
A wrapper class to call torch.optim.lr_scheduler objects as ignite handlers. |
|
Linearly adjusts param value to 'end_value' for a half-cycle, then linearly adjusts it back to 'start_value' for a half-cycle. |
|
Scheduler helper to group multiple schedulers into one. |
|
An abstract class for updating an optimizer's parameter value during training. |
|
Piecewise linear parameter scheduler |
|
Reduce LR when a metric stops improving. |
|
Helper method to create a learning rate scheduler with a linear warm-up. |
State Parameter scheduler
An abstract class for updating an engine state parameter values during training. |
|
Update a parameter during training by using a user defined callable object. |
|
Piecewise linear state parameter scheduler. |
|
Update a parameter during training by using exponential function. |
|
Update a parameter during training by using a step function. |
|
Update a parameter during training by using a multi step function. |
More on parameter scheduling
In this section there are visual examples of various parameter schedulings that can be achieved.
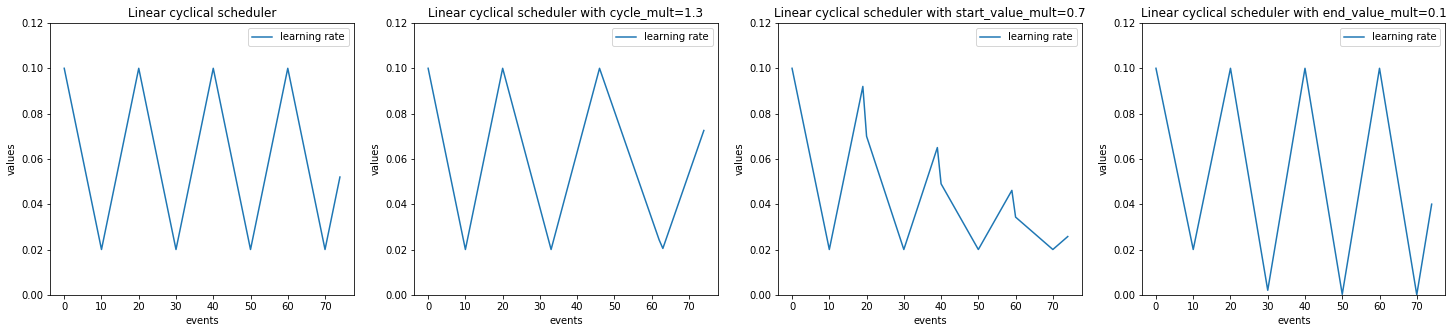
Example with CosineAnnealingScheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.handlers import CosineAnnealingScheduler
lr_values_1 = np.array(CosineAnnealingScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2, cycle_size=20))
lr_values_2 = np.array(CosineAnnealingScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2, cycle_size=20, cycle_mult=1.3))
lr_values_3 = np.array(CosineAnnealingScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2,
cycle_size=20, start_value_mult=0.7))
lr_values_4 = np.array(CosineAnnealingScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2,
cycle_size=20, end_value_mult=0.1))
plt.figure(figsize=(25, 5))
plt.subplot(141)
plt.title("Cosine annealing")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(142)
plt.title("Cosine annealing with cycle_mult=1.3")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(143)
plt.title("Cosine annealing with start_value_mult=0.7")
plt.plot(lr_values_3[:, 0], lr_values_3[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(144)
plt.title("Cosine annealing with end_value_mult=0.1")
plt.plot(lr_values_4[:, 0], lr_values_4[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
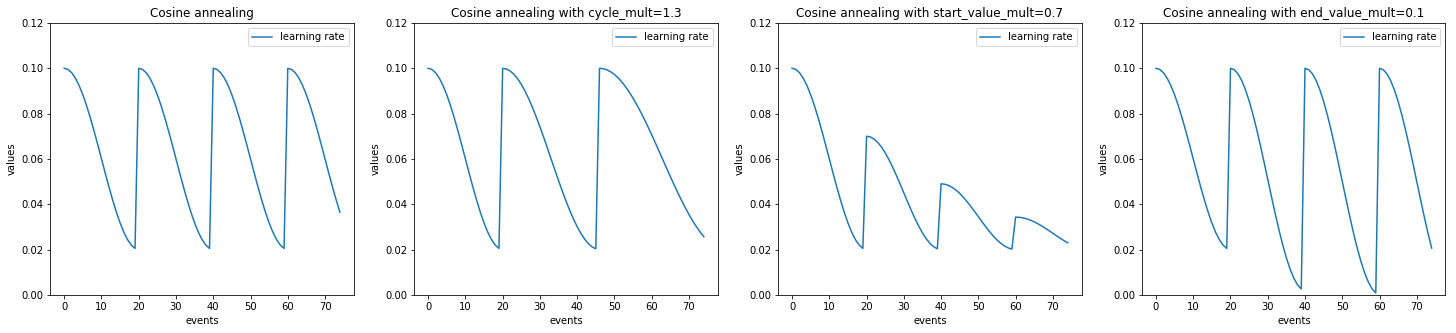
Example with ignite.handlers.param_scheduler.LinearCyclicalScheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.handlers import LinearCyclicalScheduler
lr_values_1 = np.array(LinearCyclicalScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2, cycle_size=20))
lr_values_2 = np.array(LinearCyclicalScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2, cycle_size=20, cycle_mult=1.3))
lr_values_3 = np.array(LinearCyclicalScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2,
cycle_size=20, start_value_mult=0.7))
lr_values_4 = np.array(LinearCyclicalScheduler.simulate_values(num_events=75, param_name='lr',
start_value=1e-1, end_value=2e-2,
cycle_size=20, end_value_mult=0.1))
plt.figure(figsize=(25, 5))
plt.subplot(141)
plt.title("Linear cyclical scheduler")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(142)
plt.title("Linear cyclical scheduler with cycle_mult=1.3")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(143)
plt.title("Linear cyclical scheduler with start_value_mult=0.7")
plt.plot(lr_values_3[:, 0], lr_values_3[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
plt.subplot(144)
plt.title("Linear cyclical scheduler with end_value_mult=0.1")
plt.plot(lr_values_4[:, 0], lr_values_4[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.ylim([0.0, 0.12])
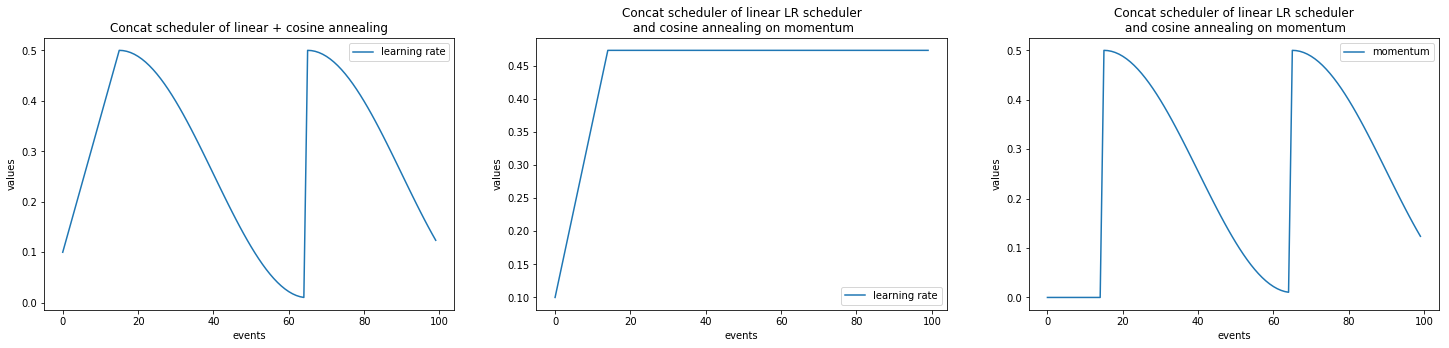
Example with ignite.handlers.param_scheduler.ConcatScheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.handlers import LinearCyclicalScheduler, CosineAnnealingScheduler, ConcatScheduler
import torch
t1 = torch.zeros([1], requires_grad=True)
optimizer = torch.optim.SGD([t1], lr=0.1)
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.1, end_value=0.5, cycle_size=30)
scheduler_2 = CosineAnnealingScheduler(optimizer, "lr", start_value=0.5, end_value=0.01, cycle_size=50)
durations = [15, ]
lr_values_1 = np.array(ConcatScheduler.simulate_values(num_events=100, schedulers=[scheduler_1, scheduler_2], durations=durations))
t1 = torch.zeros([1], requires_grad=True)
optimizer = torch.optim.SGD([t1], lr=0.1)
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.1, end_value=0.5, cycle_size=30)
scheduler_2 = CosineAnnealingScheduler(optimizer, "momentum", start_value=0.5, end_value=0.01, cycle_size=50)
durations = [15, ]
lr_values_2 = np.array(ConcatScheduler.simulate_values(num_events=100, schedulers=[scheduler_1, scheduler_2], durations=durations,
param_names=["lr", "momentum"]))
plt.figure(figsize=(25, 5))
plt.subplot(131)
plt.title("Concat scheduler of linear + cosine annealing")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(132)
plt.title("Concat scheduler of linear LR scheduler\n and cosine annealing on momentum")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(133)
plt.title("Concat scheduler of linear LR scheduler\n and cosine annealing on momentum")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 2], label="momentum")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
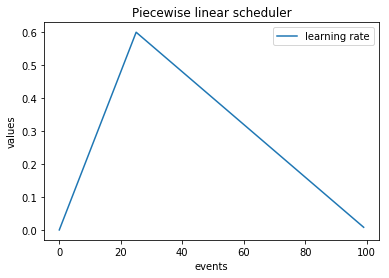
Piecewise linear scheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.handlers import LinearCyclicalScheduler, ConcatScheduler
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.0, end_value=0.6, cycle_size=50)
scheduler_2 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.6, end_value=0.0, cycle_size=150)
durations = [25, ]
lr_values = np.array(ConcatScheduler.simulate_values(num_events=100, schedulers=[scheduler_1, scheduler_2], durations=durations))
plt.title("Piecewise linear scheduler")
plt.plot(lr_values[:, 0], lr_values[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
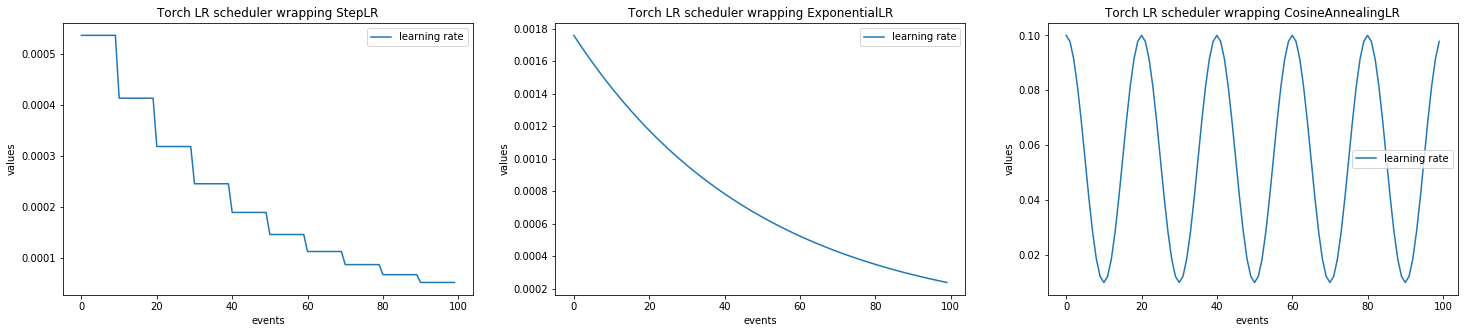
Example with ignite.handlers.param_scheduler.LRScheduler
import numpy as np
import matplotlib.pylab as plt
from ignite.handlers import LRScheduler
import torch
from torch.optim.lr_scheduler import ExponentialLR, StepLR, CosineAnnealingLR
tensor = torch.zeros([1], requires_grad=True)
optimizer = torch.optim.SGD([tensor], lr=0.1)
lr_scheduler_1 = StepLR(optimizer=optimizer, step_size=10, gamma=0.77)
lr_scheduler_2 = ExponentialLR(optimizer=optimizer, gamma=0.98)
lr_scheduler_3 = CosineAnnealingLR(optimizer=optimizer, T_max=10, eta_min=0.01)
lr_values_1 = np.array(LRScheduler.simulate_values(num_events=100, lr_scheduler=lr_scheduler_1))
lr_values_2 = np.array(LRScheduler.simulate_values(num_events=100, lr_scheduler=lr_scheduler_2))
lr_values_3 = np.array(LRScheduler.simulate_values(num_events=100, lr_scheduler=lr_scheduler_3))
plt.figure(figsize=(25, 5))
plt.subplot(131)
plt.title("Torch LR scheduler wrapping StepLR")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(132)
plt.title("Torch LR scheduler wrapping ExponentialLR")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(133)
plt.title("Torch LR scheduler wrapping CosineAnnealingLR")
plt.plot(lr_values_3[:, 0], lr_values_3[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
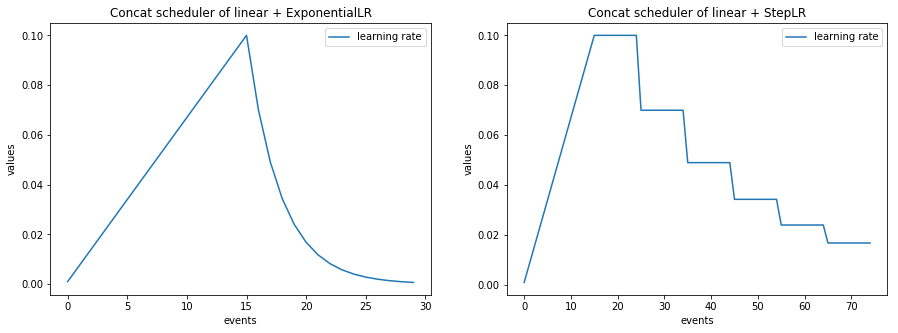
Concatenate with torch schedulers
import numpy as np
import matplotlib.pylab as plt
from ignite.handlers import LRScheduler, ConcatScheduler
import torch
from torch.optim.lr_scheduler import ExponentialLR, StepLR
t1 = torch.zeros([1], requires_grad=True)
optimizer = torch.optim.SGD([t1], lr=0.1)
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.001, end_value=0.1, cycle_size=30)
lr_scheduler = ExponentialLR(optimizer=optimizer, gamma=0.7)
scheduler_2 = LRScheduler(lr_scheduler=lr_scheduler)
durations = [15, ]
lr_values_1 = np.array(ConcatScheduler.simulate_values(num_events=30, schedulers=[scheduler_1, scheduler_2], durations=durations))
scheduler_1 = LinearCyclicalScheduler(optimizer, "lr", start_value=0.001, end_value=0.1, cycle_size=30)
lr_scheduler = StepLR(optimizer=optimizer, step_size=10, gamma=0.7)
scheduler_2 = LRScheduler(lr_scheduler=lr_scheduler)
durations = [15, ]
lr_values_2 = np.array(ConcatScheduler.simulate_values(num_events=75, schedulers=[scheduler_1, scheduler_2], durations=durations))
plt.figure(figsize=(15, 5))
plt.subplot(121)
plt.title("Concat scheduler of linear + ExponentialLR")
plt.plot(lr_values_1[:, 0], lr_values_1[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(122)
plt.title("Concat scheduler of linear + StepLR")
plt.plot(lr_values_2[:, 0], lr_values_2[:, 1], label="learning rate")
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
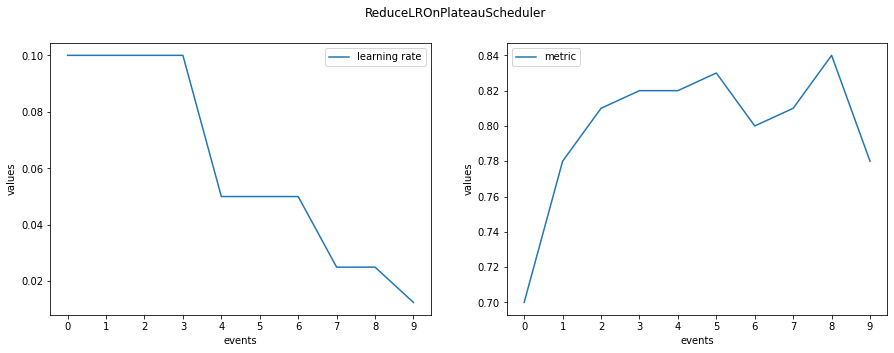
Example with ignite.handlers.param_scheduler.ReduceLROnPlateauScheduler
import matplotlib.pyplot as plt
import numpy as np
from ignite.handlers import ReduceLROnPlateauScheduler
metric_values = [0.7, 0.78, 0.81, 0.82, 0.82, 0.83, 0.80, 0.81, 0.84, 0.78]
num_events = 10
init_lr = 0.1
lr_values = np.array(ReduceLROnPlateauScheduler.simulate_values(
num_events, metric_values, init_lr,
factor=0.5, patience=1, mode='max', threshold=0.01, threshold_mode='abs'
)
)
plt.figure(figsize=(15, 5))
plt.suptitle("ReduceLROnPlateauScheduler")
plt.subplot(121)
plt.plot(lr_values[:, 1], label="learning rate")
plt.xticks(lr_values[:, 0])
plt.xlabel("events")
plt.ylabel("values")
plt.legend()
plt.subplot(122)
plt.plot(metric_values, label="metric")
plt.xticks(lr_values[:, 0])
plt.xlabel("events")
plt.ylabel("values")
plt.legend()