Once-for-All
Get supernet
You can quickly load a supernet as following
import torch
super_net_name = "ofa_supernet_mbv3_w10"
# other options:
# ofa_supernet_resnet50 /
# ofa_supernet_mbv3_w12 /
# ofa_supernet_proxyless
super_net = torch.hub.load('mit-han-lab/once-for-all', super_net_name, pretrained=True).eval()
| OFA Network | Design Space | Resolution | Width Multiplier | Depth | Expand Ratio | kernel Size |
|---|---|---|---|---|---|---|
| ofa_resnet50 | ResNet50D | 128 – 224 | 0.65, 0.8, 1.0 | 0, 1, 2 | 0.2, 0.25, 0.35 | 3 |
| ofa_mbv3_d234_e346_k357_w1.0 | MobileNetV3 | 128 – 224 | 1.0 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |
| ofa_mbv3_d234_e346_k357_w1.2 | MobileNetV3 | 160 – 224 | 1.2 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |
| ofa_proxyless_d234_e346_k357_w1.3 | ProxylessNAS | 128 – 224 | 1.3 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |
Below are the usage of sampling / selecting a subnet from the supernet
# Randomly sample sub-networks from OFA network
super_net.sample_active_subnet()
random_subnet = super_net.get_active_subnet(preserve_weight=True)
# Manually set the sub-network
super_net.set_active_subnet(ks=7, e=6, d=4)
manual_subnet = super_net.get_active_subnet(preserve_weight=True)
Get Specialized Architecture
import torch
# or load a architecture specialized for certain platform
net_config = "resnet50D_MAC_4_1B"
specialized_net, image_size = torch.hub.load('mit-han-lab/once-for-all', net_config, pretrained=True)
specialized_net.eval()
More models and configurations can be found in once-for-all/model-zoo and obtained through the following scripts
ofa_specialized_get = torch.hub.load('mit-han-lab/once-for-all', "ofa_specialized_get")
model, image_size = ofa_specialized_get("flops@595M_top1@80.0_finetune@75", pretrained=True)
model.eval()
The model’s prediction can be evalutaed by
# Download an example image from pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try:
urllib.URLopener().retrieve(url, filename)
except:
urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
Model Description
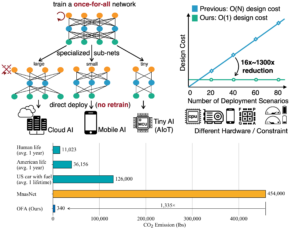
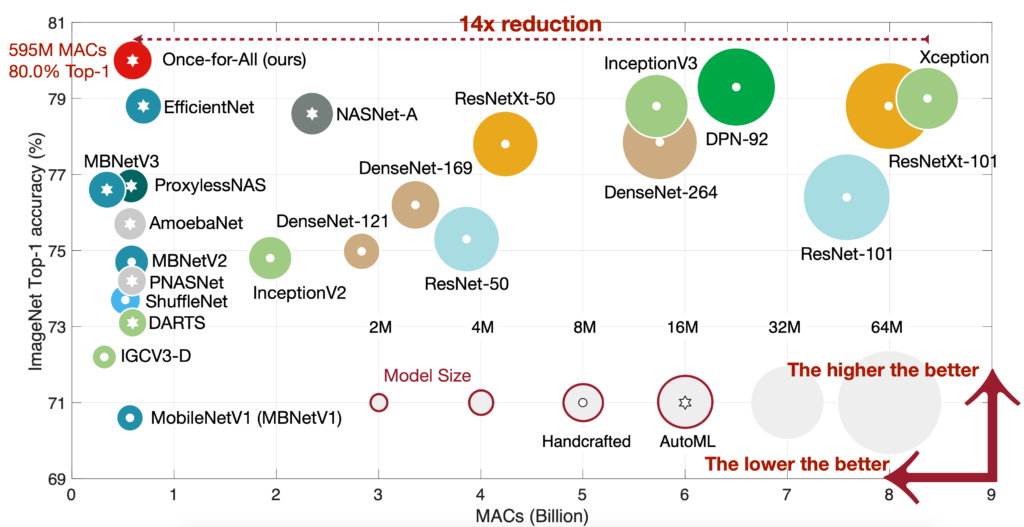
Once-for-all models are from Once for All: Train One Network and Specialize it for Efficient Deployment. Conventional approaches either manually design or use neural architecture search (NAS) to find a specialized neural network and train it from scratch for each case, which is computationally prohibitive (causing CO2 emission as much as 5 cars’ lifetime) thus unscalable. In this work, we propose to train a once-for-all (OFA) network that supports diverse architectural settings by decoupling training and search. Across diverse edge devices, OFA consistently outperforms state-of-the-art (SOTA) NAS methods (up to 4.0% ImageNet top1 accuracy improvement over MobileNetV3, or same accuracy but 1.5x faster than MobileNetV3, 2.6x faster than EfficientNet w.r.t measured latency) while reducing many orders of magnitude GPU hours and CO2 emission. In particular, OFA achieves a new SOTA 80.0% ImageNet top-1 accuracy under the mobile setting (<600M MACs).
References
@inproceedings{
cai2020once,
title={Once for All: Train One Network and Specialize it for Efficient Deployment},
author={Han Cai and Chuang Gan and Tianzhe Wang and Zhekai Zhang and Song Han},
booktitle={International Conference on Learning Representations},
year={2020},
url={https://arxiv.org/pdf/1908.09791.pdf}
}