MEAL_V2
We require one additional Python dependency
!pip install timm
import torch
# list of models: 'mealv1_resnest50', 'mealv2_resnest50', 'mealv2_resnest50_cutmix', 'mealv2_resnest50_380x380', 'mealv2_mobilenetv3_small_075', 'mealv2_mobilenetv3_small_100', 'mealv2_mobilenet_v3_large_100', 'mealv2_efficientnet_b0'
# load pretrained models, using "mealv2_resnest50_cutmix" as an example
model = torch.hub.load('szq0214/MEAL-V2','meal_v2', 'mealv2_resnest50_cutmix', pretrained=True)
model.eval()
All pre-trained models expect input images normalized in the same way, i.e. mini-batches of 3-channel RGB images of shape (3 x H x W), where H and W are expected to be at least 224. The images have to be loaded in to a range of [0, 1] and then normalized using mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225].
Here’s a sample execution.
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
# Download ImageNet labels
!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
# Read the categories
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Show top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
Model Description
MEAL V2 models are from the MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks paper.
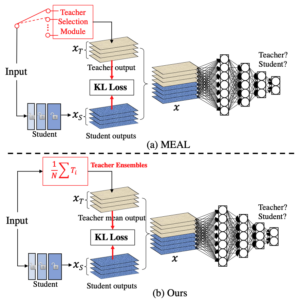
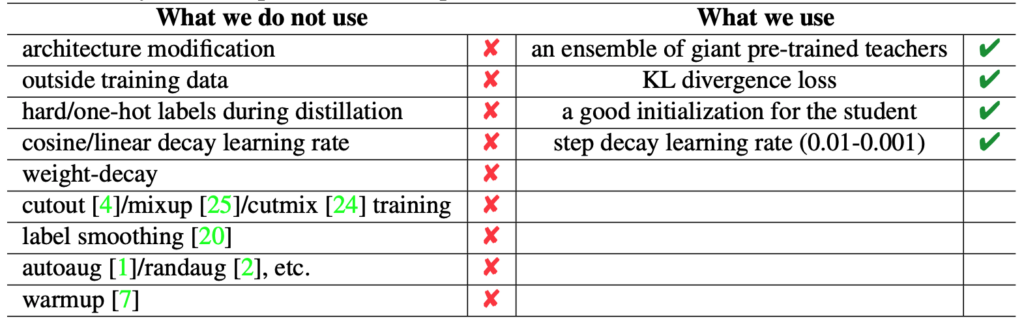
In this paper, we introduce a simple yet effective approach that can boost the vanilla ResNet-50 to 80%+ Top-1 accuracy on ImageNet without any tricks. Generally, our method is based on the recently proposed MEAL, i.e., ensemble knowledge distillation via discriminators. We further simplify it through 1) adopting the similarity loss and discriminator only on the final outputs and 2) using the average of softmax probabilities from all teacher ensembles as the stronger supervision for distillation. One crucial perspective of our method is that the one-hot/hard label should not be used in the distillation process. We show that such a simple framework can achieve state-of-the-art results without involving any commonly-used tricks, such as 1) architecture modification; 2) outside training data beyond ImageNet; 3) autoaug/randaug; 4) cosine learning rate; 5) mixup/cutmix training; 6) label smoothing; etc.
| Models | Resolution | #Parameters | Top-1/Top-5 | |
|---|---|---|---|---|
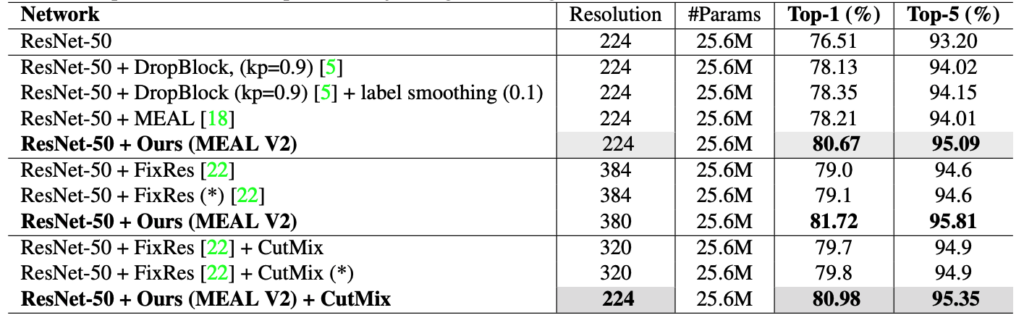
| MEAL-V1 w/ ResNet50 | 224 | 25.6M | 78.21/94.01 | GitHub |
| MEAL-V2 w/ ResNet50 | 224 | 25.6M | 80.67/95.09 | |
| MEAL-V2 w/ ResNet50 | 380 | 25.6M | 81.72/95.81 | |
| MEAL-V2 + CutMix w/ ResNet50 | 224 | 25.6M | 80.98/95.35 | |
| MEAL-V2 w/ MobileNet V3-Small 0.75 | 224 | 2.04M | 67.60/87.23 | |
| MEAL-V2 w/ MobileNet V3-Small 1.0 | 224 | 2.54M | 69.65/88.71 | |
| MEAL-V2 w/ MobileNet V3-Large 1.0 | 224 | 5.48M | 76.92/93.32 | |
| MEAL-V2 w/ EfficientNet-B0 | 224 | 5.29M | 78.29/93.95 |
References
Please refer to our papers MEAL V2, MEAL for more details.
@article{shen2020mealv2,
title={MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks},
author={Shen, Zhiqiang and Savvides, Marios},
journal={arXiv preprint arXiv:2009.08453},
year={2020}
}
@inproceedings{shen2019MEAL,
title = {MEAL: Multi-Model Ensemble via Adversarial Learning},
author = {Shen, Zhiqiang and He, Zhankui and Xue, Xiangyang},
booktitle = {AAAI},
year = {2019}
}