What is the unsaid joy of local LLMs?
The magic of downloading weights, running some experiments overnight, maybe your room gets a bit toasty, and voila, you create a small but performant model that runs on your desktop.
Often this involves a big GPU machine and lots of cables; in our case, it was a very lovely box that fit just within the spaces of the monitor stand and kept our hands warm. Truly, DGX Spark is really fun to look at!

In this blog, we share a recipe to run Full-Fine-Tuning for Llama 3.1-8B-Instruct on Synthetic data and unlock “Reasoning” in an LLM using the DGX Spark box. Thanks to the unified memory, we are able to generate synthetic thinking traces and fine-tune the model on it entirely locally.

Text in red color shows the added behaviour from the Fine-Tuned model on NVIDIA DGX Spark.
The entire recipe runs offline on DGX Spark in under a day. We are able to run full fine-tuning for Llama-3.1-8B-Instruct without any issues, with context length of 16k tokens and a batch size of 16
We plan to share more experiments on Llama 70B and FP4 experiments on even more exciting topics in a future blog. Stay tuned!
Adding Reasoning Behaviour in Llama-3.1-8BLarge Language Models’ ability to reason and think has shown large gains in practice, thanks to inference time scaling.
We ask the question: Can we create this behaviour for a specific topic by fine-tuning on synthetic thinking traces?
We prompt Llama 3.3-70B-Instruct running locally to add Chain of Thought to existing chats
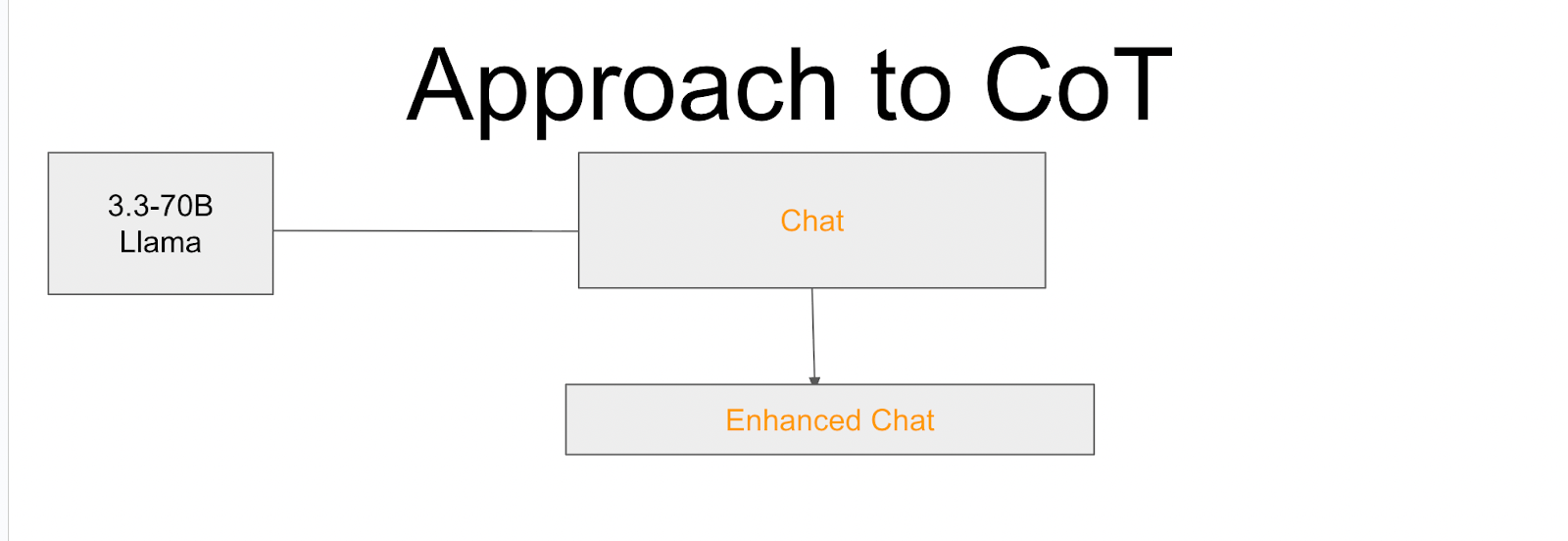
Data Generation
Note: We generate synthetic CoT over the entire ToolACE dataset, which consists of 11k conversation pairs
This feature is supported out of box via Synthetic-Data-Kit, which offers an intuitive CLI to prepare and enrich your datasets for Fine-Tuning LLMs.
We can run this locally using vLLM on DGX Spark and use the following approach to generate CoT responses:
We use a single command
synthetic-data-kit create --type cot-enhance /path/to/dataset
Then we can create a custom prompt in a configuration file and use it like so:
# cot_tools_config.yaml
vllm: api_base: "http://localhost:8000/v1" model: "unsloth/Meta-Llama-3.3-70B-Instruct" max_retries: 3 retry_delay: 1.0 generation: temperature: 0.2 # Lower temperature for more consistent reasoning top_p: 0.95 max_tokens: 16384 # Allow for longer outputs to accommodate CoT reasoning # The most important part - our custom Chain of Thought prompt prompts: cot_enhancement: | You are a highly intelligent AI with an IQ of 170, and your job is to enhance existing conversation examples. Remember to return the entire conversation as is, BUT BUT, we will add Chain of Thought and planning to "Assistant" messages whenever they return a tool call. Remember, ONLY when an assistant message returns a tool call will we add thinking and reasoning traces before it to add logic. Otherwise, we don't touch the conversation history. Remember to return the entire message, but only enhance the assistant messages whenever a tool is called in the conversation by adding thoughts. Please keep in mind that we are not modifying anything in the example, nor are we changing what it does. We are only adding CoT every time a tool gets called in the conversation. Think out loud and maximize your tokens when adding CoT. For example, if you see: "from": "assistant", "value": "<tool>[Some API(param=\"value\")]</tool>" Change it to: "from": "assistant", "value": "Let me think about this request. I need to gather X information using Tool Y. To do this, I need to set the parameter to 'value' because of reason Z. <tool>[Some API(param=\"value\")]</tool>" BEGIN WORK NOW. Enhance the assistant's messages with detailed Chain of Thought reasoning before each tool call: {conversations}
Note: We generate synthetic CoT over the entire ToolACE dataset, which consists of 11k conversation pairs
synthetic-data-kit -c cot_tools_config.yaml create test_files/conversation_example.json \ --type cot-enhance \ –output enhanced_output/
Unlocking Local Full Fine Tuning with NVIDIA DGX Spark
Fine-tuning large language models is quite well understood, and there are a lot of knobs we can work with when performing supervised fine-tuning.
For our experiments, we follow Full-Fine Tuning to showcase the power of 128GB Unified memory of NVIDIA DGX Sparks.
128GB Unified Memory is Spacious!
The great thing about DGX Spark is: All of the available memory for training is exposed as a unified 128GB interface. So when performing Supervised Fine-Tuning, we can work with the assumption that we have a 128GB memory device to work with instead of spending time on offloading settings.
This enables us to run Full Fine-Tuning for Llama-3.1-8B instead of experimenting configurations to squeeze everything into working device memory.
Context Length
Bigger memory allows us to train experiments on longer contexts, make it easier to teach tasks like tool-calling.
For our use case, we fine-tune Llama on synthetic reasoning traces. These can get quite lengthy! In our case, our experiments run at 16k tokens.
Memory requirements quadratically increase as we increase sequence length with LLMs.
This is another area where DGX Sparks shine: Even at Full-Fine-Tune with 16k context length, we are at roughly 80% memory usage peak (Device Usage Graphs in results section below) .
Batch Size
Another great rule is to maximise batch sizes in powers of 2 to allow faster LLM convergence, for our experiments we have enough room to set batch_size at 16-this is really great!
Why Full Fine Tune?
Thanks to 128G, we are able to run 8B FFT entirely on DGX Spark, so we decided to follow this route for maximum performance and we report results from our experiments below
Full-Fine-Tuning
We use TorchTune for Full Fine-Tuning experiments. Torchtune offers an intuitive CLI that interacts with configs to offer a single line for running experiments.
The entire config and details are available here
We explain the key configurations below:
tune run full_finetune_single_device --config fft-8b.yaml
Key items we set in the config:
Seq_len: 16384
Batch_size: 16
Epochs: 3
Dtype: bf16
The whole fine-tuning pipeline from data generation to full fine-tuning is only a one-day job, with each epoch averaging just around 8 hours. This is really impressive!
Note: You can squeeze more performance, given that we note peak memory usage around 80% during the entire run.
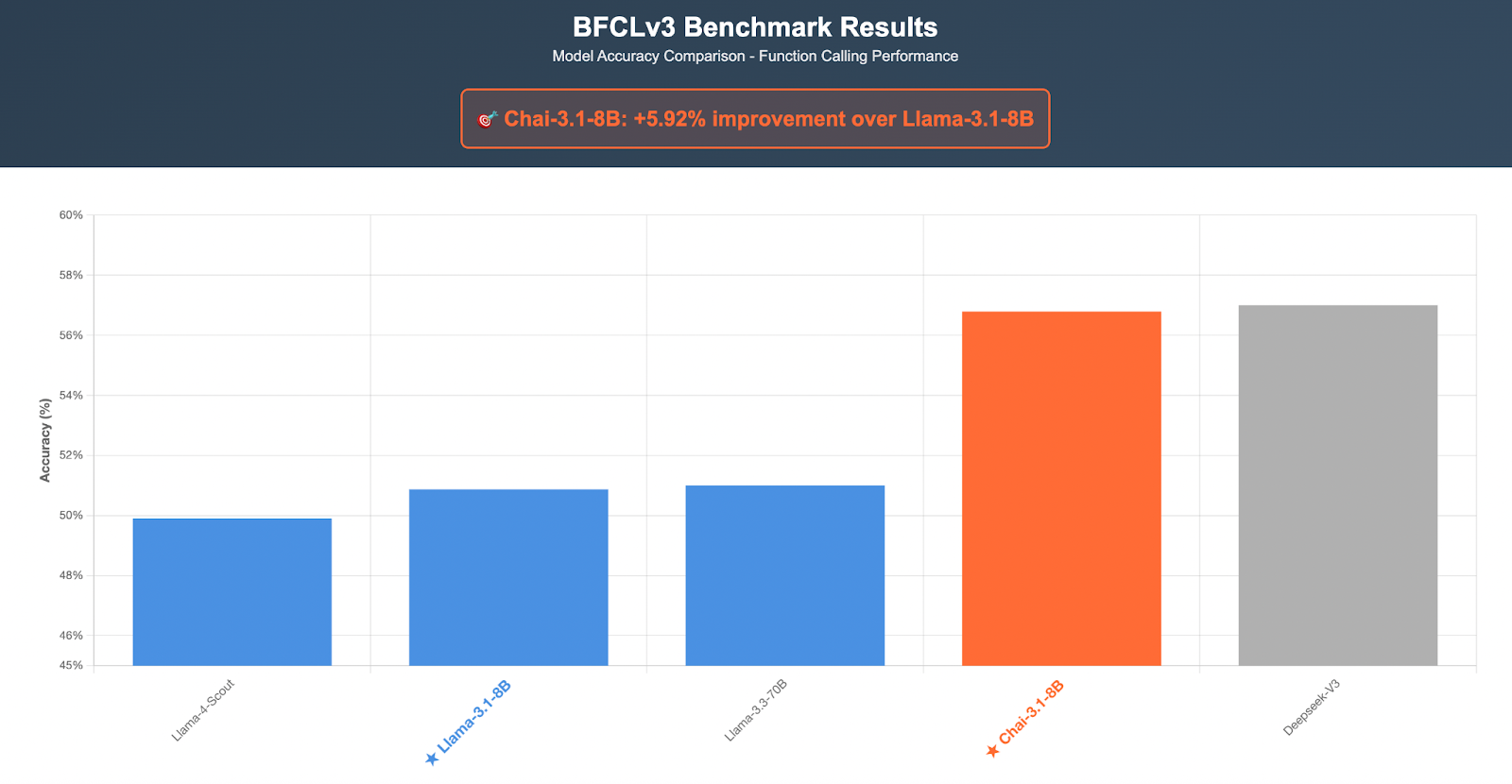
Results
Below we show both the hero training run graphs followed by performance on function calling benchmarks:
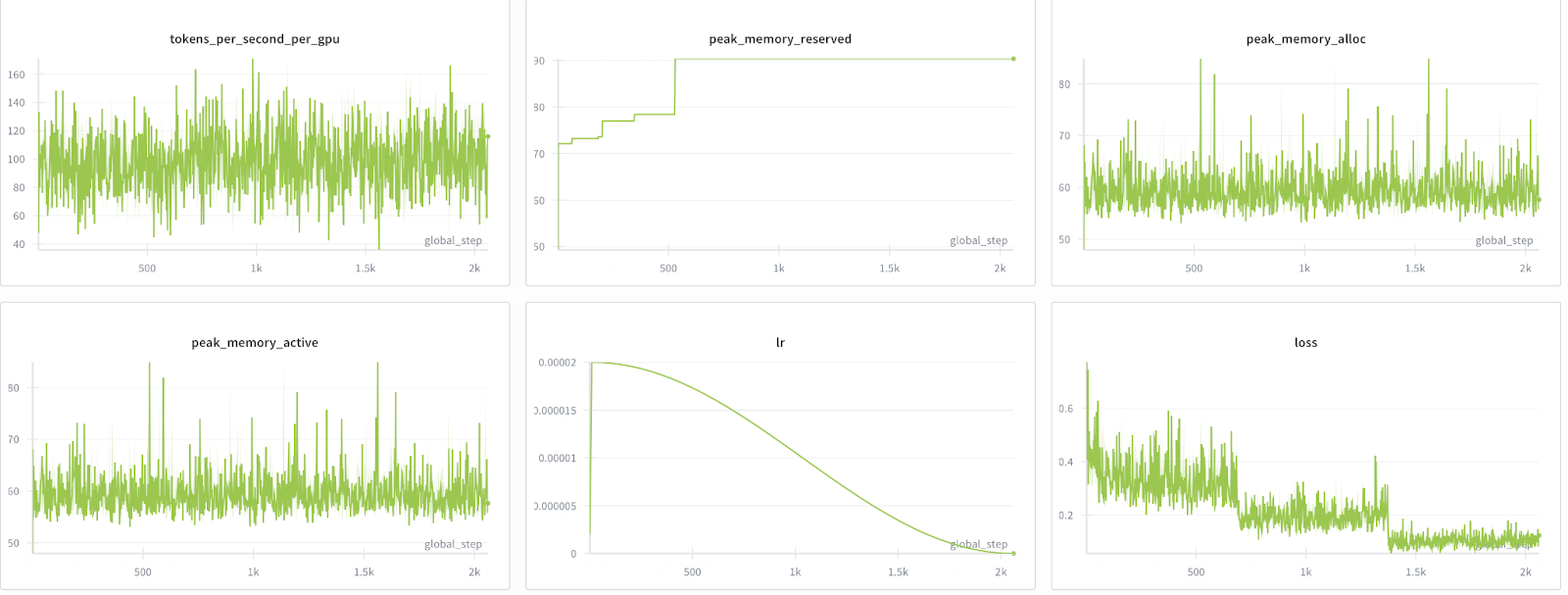
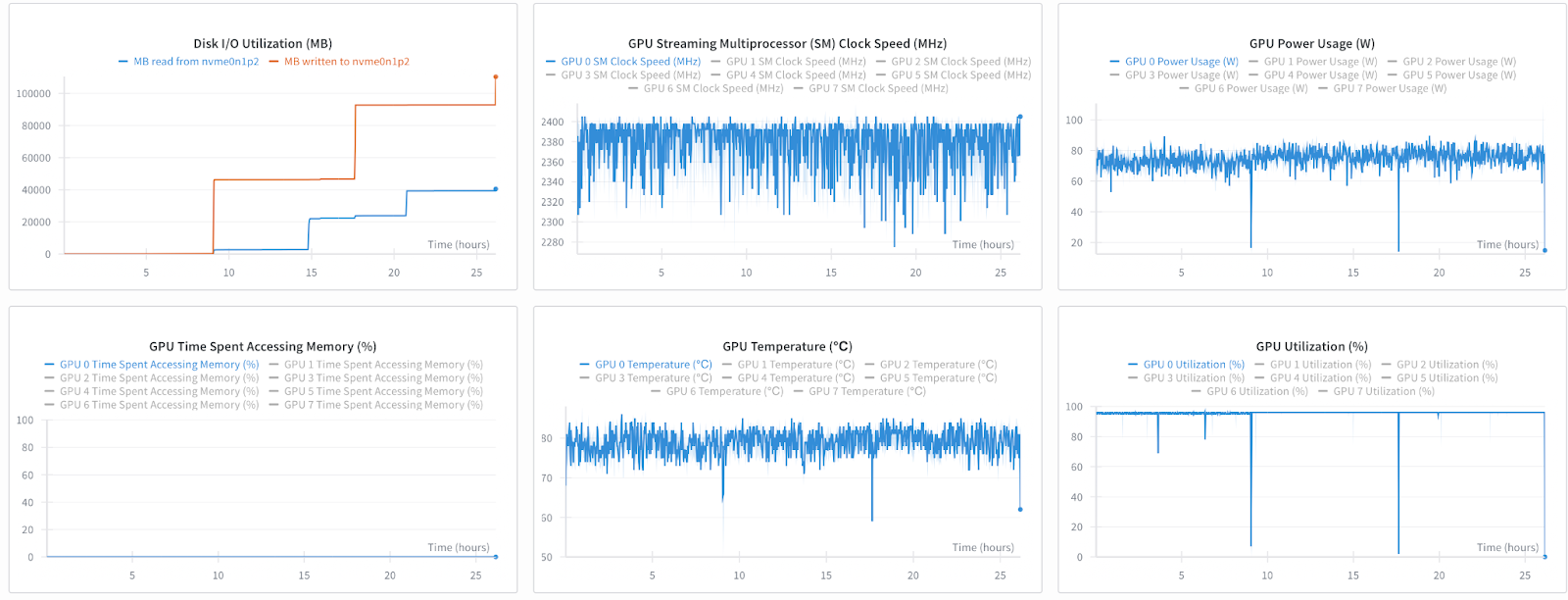
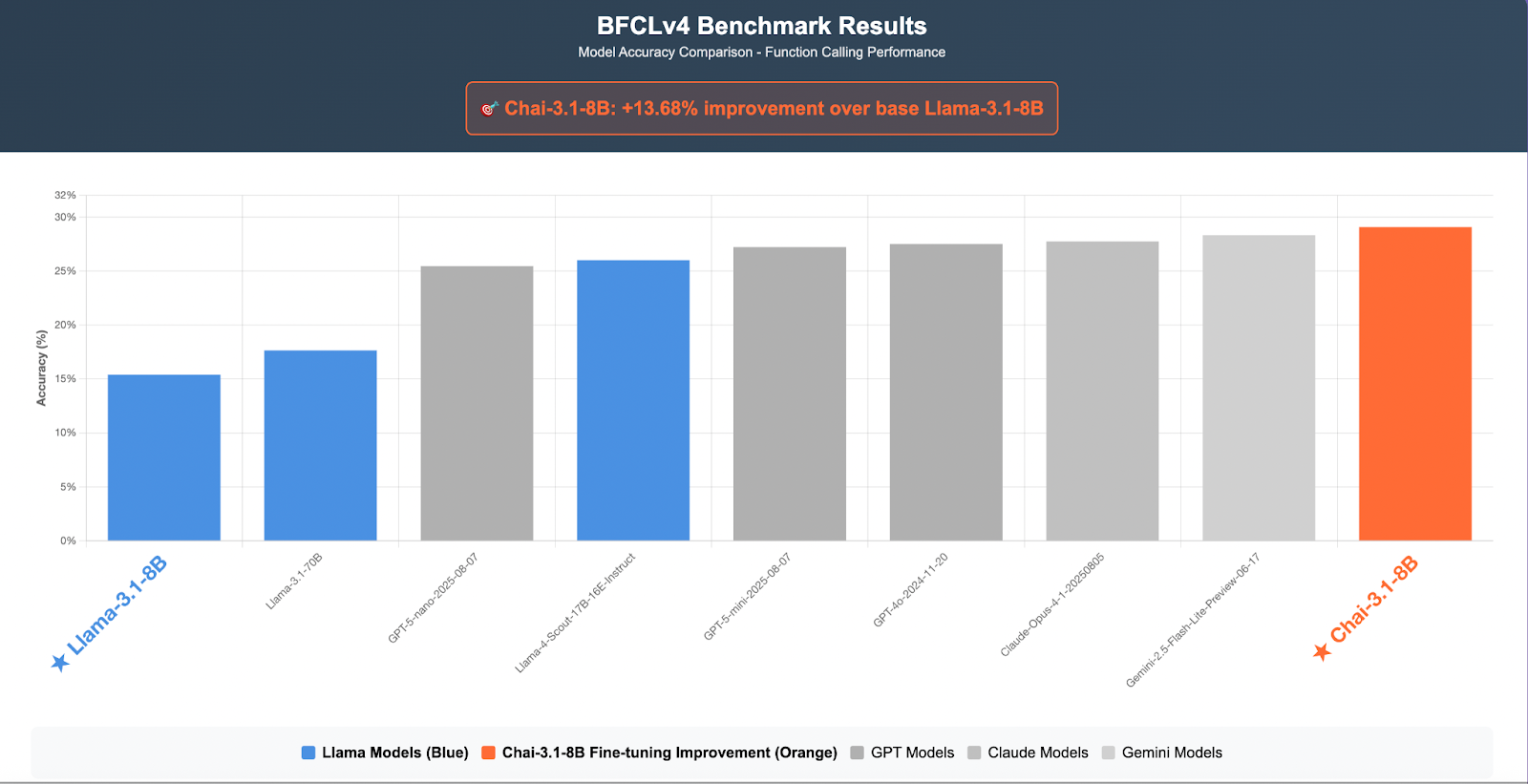
For our recipe, we use the ToolACE dataset and baseline results on BFCLv3 as well as v4 (recently released)
BFCL measures the following:
- Multi-Turn Tool Calling
- Tool Calling in parallel support
- Ability to perform agentic calls (v4)
- Ability to perform web searches based on open-ended queries (v4)
Conclusion
We show an end to end recipe that runs on DGX Spark, utilizing its unified memory to perform Full-Fine-Tuning on Llama-3.1-8B-Instruct.
We generate synthetic thinking and chain of thought, which we then fine-tune the model to improve its performance reported above.
In future blogs, we will explore Llama-3.3-70B recipes as well as some more recipes that show FP4 power of the box. Please stay tuned!