Over the past year, Mixture of Experts (MoE) models have surged in popularity, fueled by powerful open-source models like DBRX, Mixtral, DeepSeek, and many more. At Databricks, we’ve worked closely with the PyTorch team to scale training of MoE models. In this blog post, we’ll talk about how we scale to over three thousand GPUs using PyTorch Distributed and MegaBlocks, an efficient open-source MoE implementation in PyTorch.
What is a MoE?
A MoE model is a model architecture that uses multiple expert networks to make predictions. A gating network is used to route and combine the outputs of experts, ensuring each expert is trained on a different, specialized distribution of tokens. The architecture of a transformer-based large language model typically consists of an embedding layer that leads into multiple transformer blocks (Figure 1, Subfigure A). Each transformer block contains an attention block and a dense feed forward network (Figure 1, Subfigure B). These transformer blocks are stacked such that the output of one transformer block leads to the input of the next block. The final output goes through a fully connected layer and softmax to obtain probabilities for the next token to output.
When using a MoE in LLMs, the dense feed forward layer is replaced by a MoE layer which consists of a gating network and a number of experts (Figure 1, Subfigure D). The gating network, typically a linear feed forward network, takes in each token and produces a set of weights that determine which tokens are routed to which experts. The experts themselves are typically implemented as a feed forward network as well. During training, the gating network adapts to assign inputs to the experts, enabling the model to specialize and improve its performance. The router outputs are then used to weigh expert outputs to give the final output of the MoE layer.
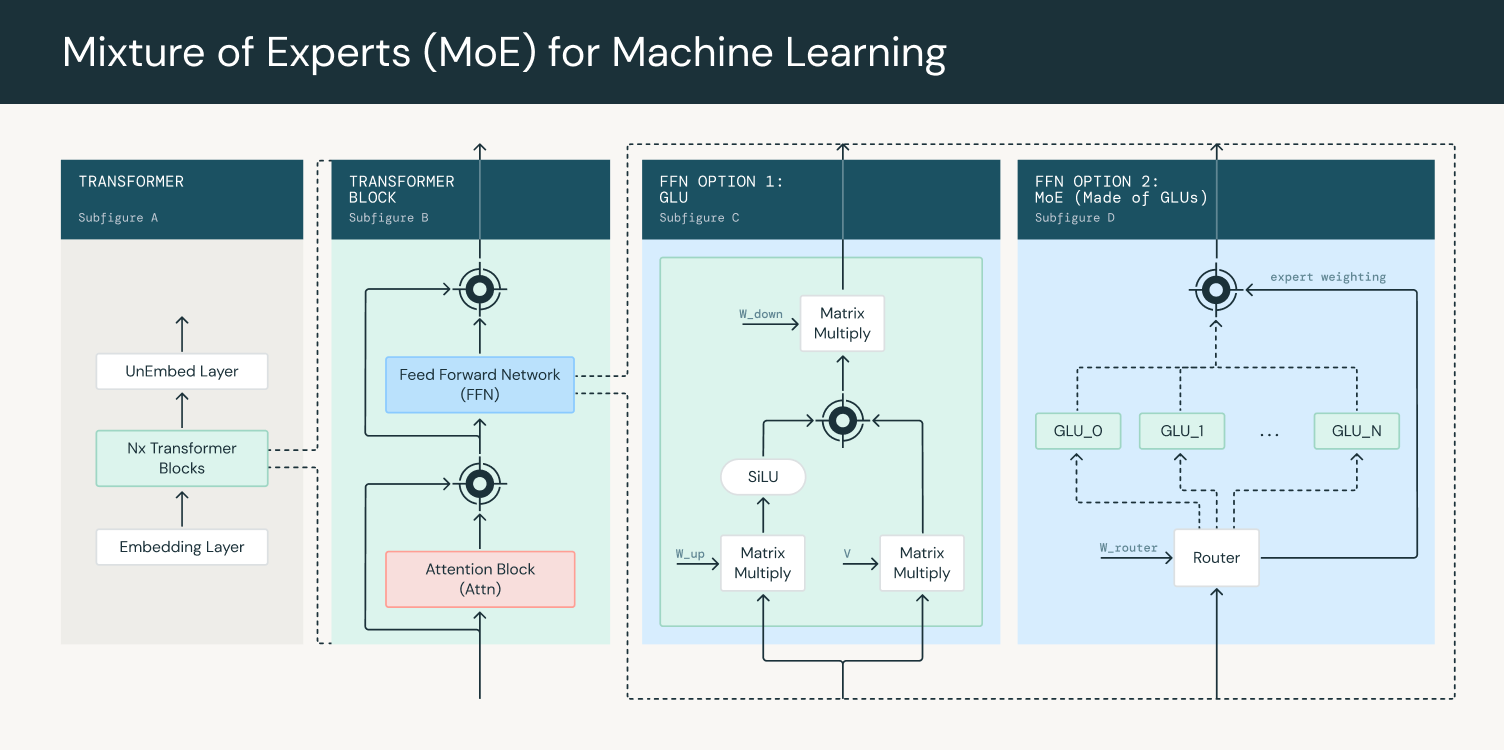
Figure 1: Using Mixture of Experts in a transformer block
Compared to dense models, MoEs provide more efficient training for a given compute budget. This is because the gating network only sends tokens to a subset of experts, reducing the computational load. As a result, the capacity of a model (its total number of parameters) can be increased without proportionally increasing the computational requirements. During inference, only some of the experts are used, so a MoE is able to perform faster inference than a dense model. However, the entire model needs to be loaded in memory, not just the experts being used.
The sparsity in MoEs that allows for greater computational efficiency comes from the fact that a particular token will only be routed to a subset of experts. The number of experts and how experts are chosen depends on the implementation of the gating network, but a common method is top k. The gating network first predicts a probability value for each expert, then routes the token to the top k experts to obtain the output. However, if all tokens always go to the same subset of experts, training becomes inefficient and the other experts end up undertrained. To alleviate this problem, a load balancing loss is introduced that encourages even routing to all experts.
The number of experts and choosing the top k experts is an important factor in designing MoEs. A higher number of experts allows scaling up to larger models without increasing computational cost. This means that the model has a higher capacity for learning, however, past a certain point the performance gains tend to diminish. The number of experts chosen needs to be balanced with the inference costs of serving the model since the entire model needs to be loaded in memory. Similarly, when choosing top k, a lower top k during training results in smaller matrix multiplications, leaving free computation on the table if communication costs are large enough. During inference, however, a higher top k generally leads to slower inference speed.
MegaBlocks
MegaBlocks is an efficient MoE implementation that uses sparse matrix multiplication to compute expert outputs in parallel despite uneven token assignment. MegaBlocks implements a dropless MoE that avoids dropping tokens while using GPU kernels that maintain efficient training. Prior to MegaBlocks, dynamic routing formulations forced a tradeoff between model quality and hardware efficiency. Previously, users had to either drop tokens from computation or waste computation and memory on padding. Experts can receive a variable number of tokens and the expert computation can be performed efficiently using block sparse matrix multiplication. We’ve integrated MegaBlocks into LLM Foundry to enable scaling MoE training to thousands of GPUs.
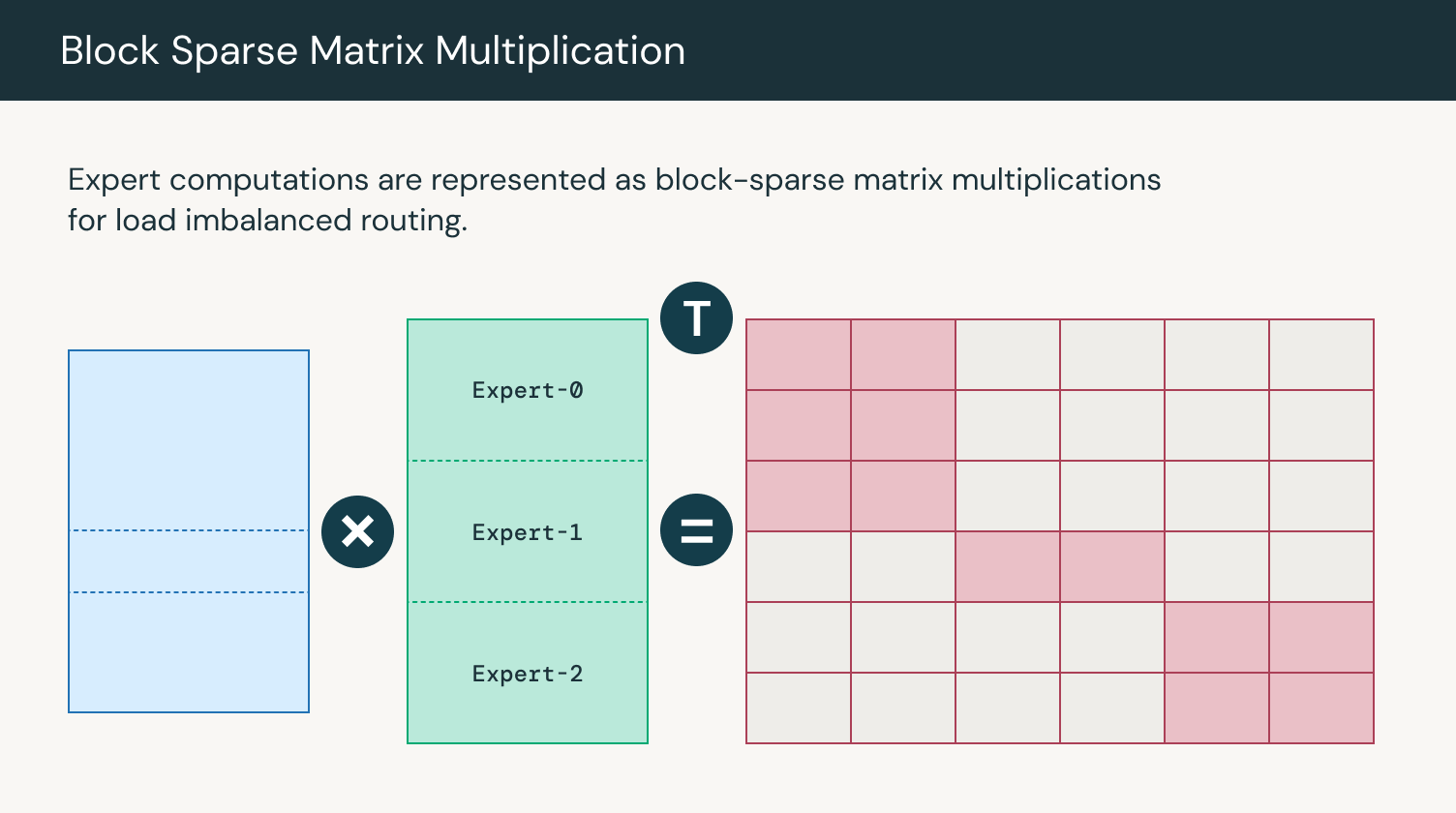
Figure 2: Matrix multiplication for expert computations
Expert Parallelism
As models scale to larger sizes and fail to fit on a single GPU, we require more advanced forms of parallelism. Expert parallelism is a form of model parallelism where we place different experts on different GPUs for better performance. Instead of expert weights being communicated across all GPUs, tokens are sent to the device that contains the expert. By moving data instead of weights, we can aggregate data across multiple machines for a single expert. The router determines which tokens from the input sequence should be sent to which experts. This is typically done by computing a gating score for each token-expert pair, and then routing each token to the top-scoring experts. Once the token-to-expert assignments are determined, an all-to-all communication step is performed to dispatch the tokens to the devices hosting the relevant experts. This involves each device sending the tokens assigned to experts on other devices, while receiving tokens assigned to its local experts.
The key advantage of expert parallelism is processing a few, larger matrix multiplications instead of several small matrix multiplications. As each GPU only has a subset of experts, it only has to do computation for those experts. Correspondly, as we aggregate tokens across multiple GPUs, the size of each matrix is proportionally larger. As GPUs are optimized for large-scale parallel computations, larger operations can better exploit their capabilities, leading to higher utilization and efficiency. A more in depth explanation of the benefits of larger matrix multiplications can be found here. Once the computation is complete, another all-to-all communication step is performed to send the expert outputs back to their original devices.
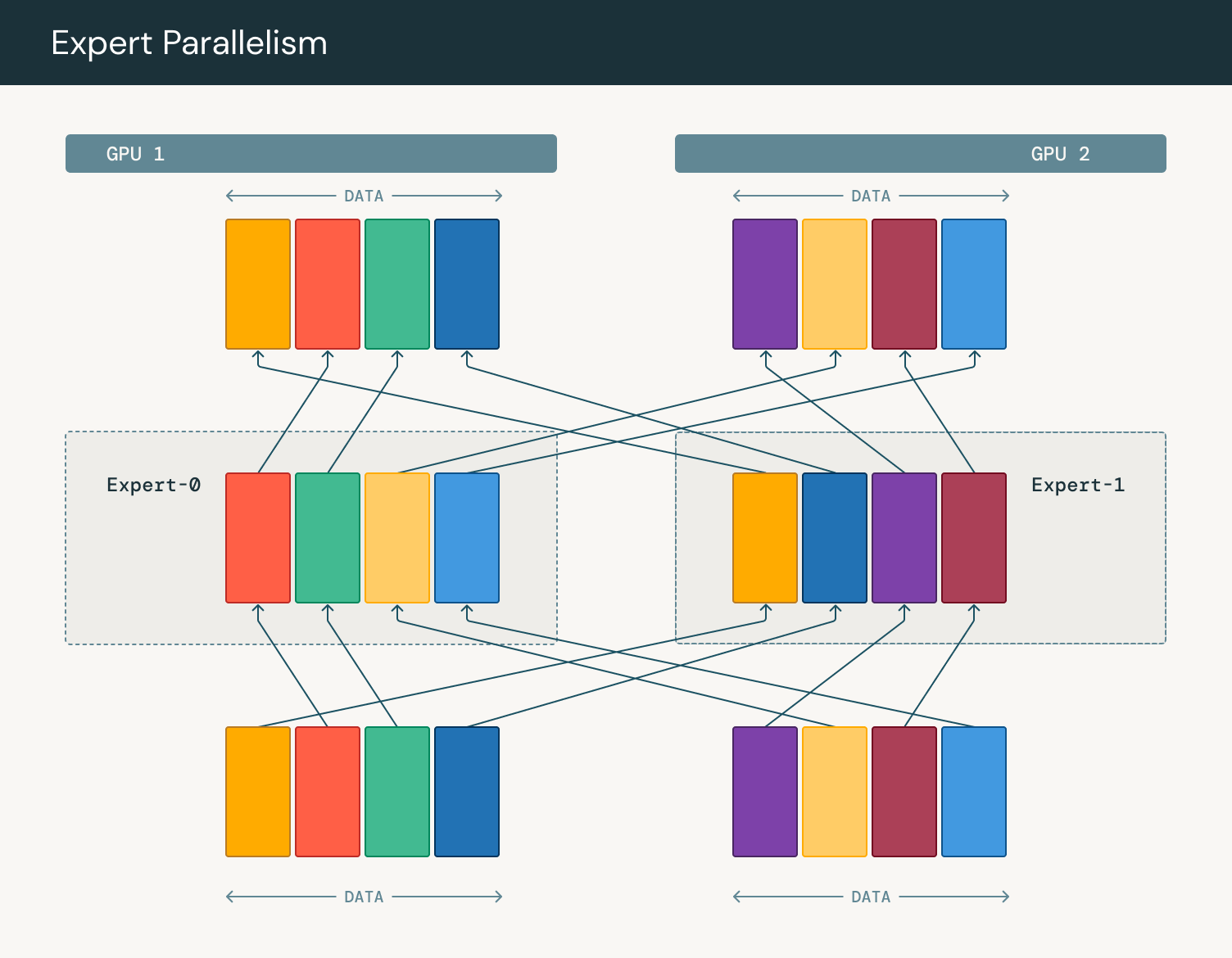
Figure 3: Token routing in expert parallelism
We leverage PyTorch’s DTensor, a low-level abstraction for describing how tensors are sharded and replicated, to effectively implement expert parallelism. We first manually place experts on different GPUs, typically sharding across a node to ensure we can leverage NVLink for fast GPU communication when we route tokens. We can then build a device mesh on top of this layout, which lets us succinctly describe the parallelism across the entire cluster. We can use this device mesh to easily checkpoint or rearrange experts when we need alternate forms of parallelism.
Scaling ZeRO-3 with PyTorch FSDP
In conjunction with expert parallelism, we use data parallelism for all other layers, where each GPU stores a copy of the model and optimizer and processes a different chunk of data. After each GPU has completed a forward and backward pass, gradients are accumulated across GPUs for a global model update.
ZeRO-3 is a form of data parallelism where weights and optimizers are sharded across each GPU instead of being replicated. Each GPU now only stores a subset of the full model, dramatically reducing memory pressure. When a part of the model is needed for computation, it is gathered across all the GPUs, and after the computation is complete, the gathered weights are discarded. We use PyTorch’s implementation of ZeRO-3, called Fully Sharded Data Parallel (FSDP).
As we scale to thousands of GPUs, the cost of communication across devices increases, slowing down training. Communication increases due to the need to synchronize and share model parameters, gradients, and optimizer states across all GPUs which involves all-gather and reduce-scatter operations. To mitigate this issue while keeping the benefits of FSDP, we utilize Hybrid Sharded Data Parallel (HSDP) to shard the model and optimizer across a set number of GPUs and replicate this multiple times to fully utilize the cluster. With HSDP, an additional all reduce operation is needed in the backward pass to sync gradients across replicas. This approach allows us to balance memory efficiency and communication cost during large scale distributed training. To use HSDP we can extend our previous device mesh from expert parallelism and let PyTorch do the heavy lifting of actually sharding and gathering when needed.
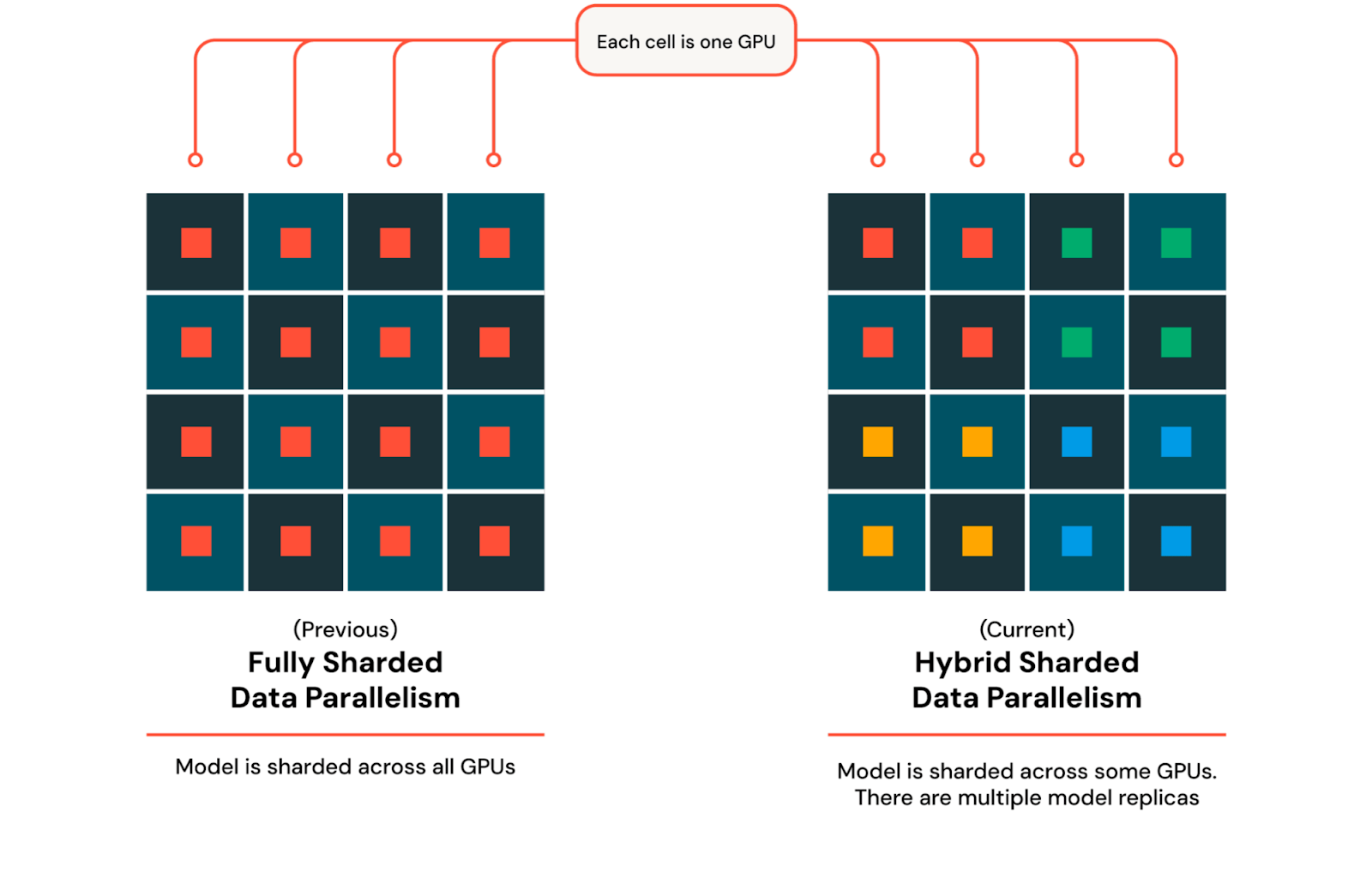
Figure 4: FSDP and HSDP
With PyTorch, we can effectively combine these two types of parallelism, leveraging FSDP’s higher level API while using the lower-level DTensor abstraction when we want to implement something custom like expert parallelism. We now have a 3D device mesh with expert parallel shard dimension, ZeRO-3 shard dimension, and a replicate dimension for pure data parallelism. Together, these techniques deliver near linear scaling across very large clusters, allowing us to achieve MFU numbers over 40%.
Elastic Checkpointing with Torch Distributed
Fault tolerance is crucial for ensuring that LLMs can be trained reliably over extended periods, especially in distributed environments where node failures are common. To avoid losing progress when jobs inevitably encounter failures, we checkpoint the state of the model, which includes parameters, optimizer states, and other necessary metadata. When a failure occurs, the system can resume from the last saved state rather than starting over. To ensure robustness to failures, we need to checkpoint often and save and load checkpoints in the most performant way possible to minimize downtime. Additionally, if too many GPUs fail, our cluster size may change. Accordingly, we need the ability to elastically resume on a different number of GPUs.
PyTorch supports elastic checkpointing through its distributed training framework, which includes utilities for both saving and loading checkpoints across different cluster configurations. PyTorch Distributed Checkpoint ensures the model’s state can be saved and restored accurately across all nodes in the training cluster in parallel, regardless of any changes in the cluster’s composition due to node failures or additions.
Additionally, when training very large models, the size of checkpoints may be very large, leading to very slow checkpoint upload and download times. PyTorch Distributed Checkpoint supports sharded checkpoints, which enables each GPU to save and load only its portion of the model. When combining sharded checkpointing with elastic training, each GPU reads the metadata file to determine which shards to download on resumption. The metadata file contains information on what parts of each tensor are stored in each shard. The GPU can then download the shards for its part of the model and load that part of the checkpoint.
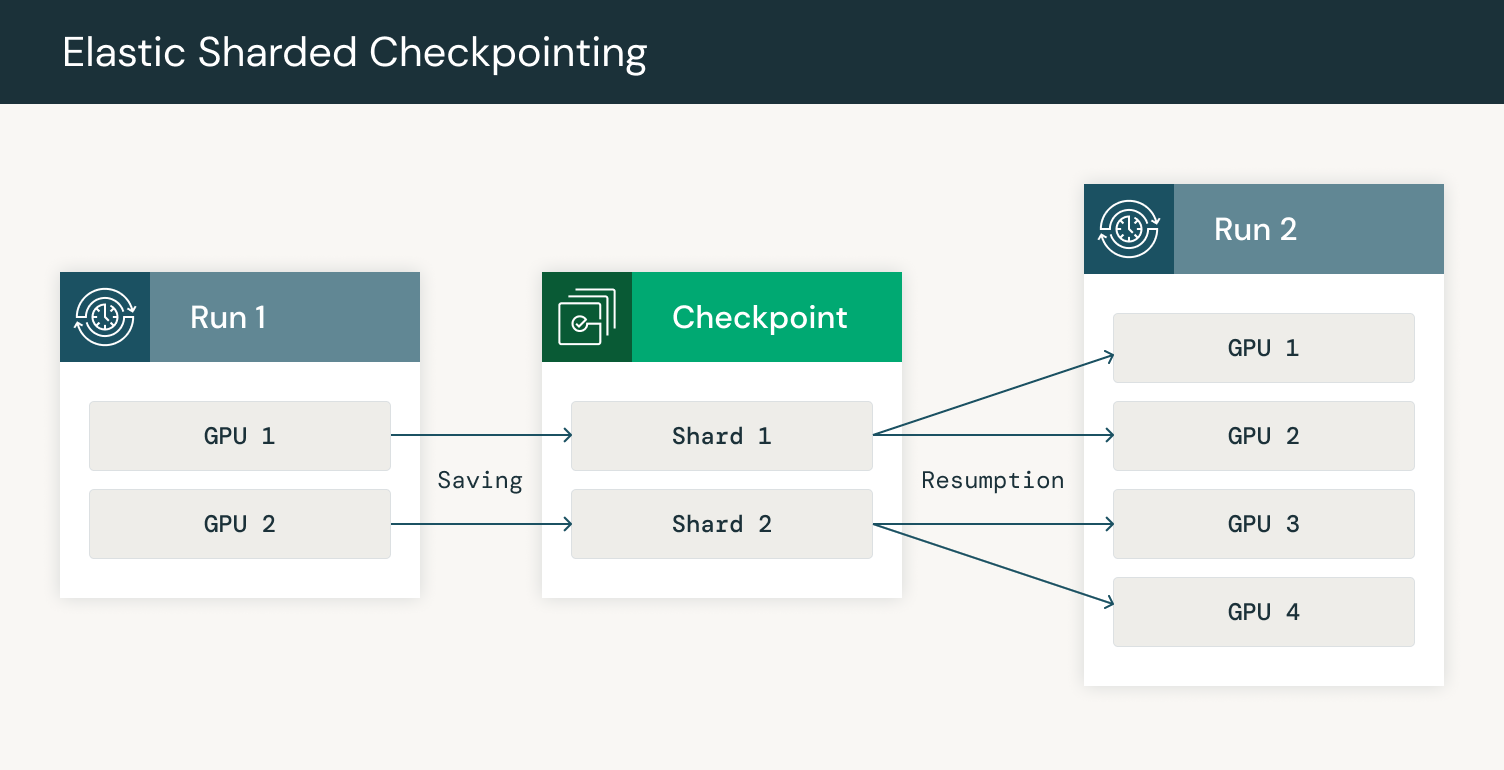
Figure 5: Checkpointing saving and resumption resharded on additional GPUs
By parallelizing checkpointing across GPUs, we can spread out network load, improving robustness and speed. When training a model with 3000+ GPUs, network bandwidth quickly becomes a bottleneck. We take advantage of the replication in HSDP to first download checkpoints on one replica and then send the necessary shards to other replicas. With our integration in Composer, we can reliably upload checkpoints to cloud storage as frequently as every 30 minutes and automatically resume from the latest checkpoint in the event of a node failure in less than 5 minutes.
Conclusion
We’re very excited to see how PyTorch is enabling training state-of-the-art LLMs with great performance. In our post, we’ve shown how we implemented efficient MoE training through Pytorch Distributed and MegaBlocks on Foundry. Furthermore, Pytorch elastic checkpointing allowed us to quickly resume training on a different number of GPUs when node failures occurred. Using Pytorch HSDP has allowed us to scale training efficiently as well as improve checkpointing resumption times. We look forward to continuing building on a strong and vibrant open-source community to help bring great AI models to everyone. Come join us in building great models at LLM Foundry and PyTorch.