Reproducibility is an essential requirement for many fields of research including those based on machine learning techniques. However, many machine learning publications are either not reproducible or are difficult to reproduce. With the continued growth in the number of research publications, including tens of thousands of papers now hosted on arXiv and submissions to conferences at an all time high, research reproducibility is more important than ever. While many of these publications are accompanied by code as well as trained models which is helpful but still leaves a number of steps for users to figure out for themselves.
We are excited to announce the availability of PyTorch Hub, a simple API and workflow that provides the basic building blocks for improving machine learning research reproducibility. PyTorch Hub consists of a pre-trained model repository designed specifically to facilitate research reproducibility and enable new research. It also has built-in support for Colab, integration with Papers With Code and currently contains a broad set of models that include Classification and Segmentation, Generative, Transformers, etc.
[Owner] Publishing models
PyTorch Hub supports the publication of pre-trained models (model definitions and pre-trained weights) to a GitHub repository by adding a simple hubconf.py file. This provides an enumeration of which models are to be supported and a list of dependencies needed to run the models. Examples can be found in the torchvision, huggingface-bert and gan-model-zoo repositories.
Let us look at the simplest case: torchvision’s hubconf.py:
# Optional list of dependencies required by the package
dependencies = ['torch']
from torchvision.models.alexnet import alexnet
from torchvision.models.densenet import densenet121, densenet169, densenet201, densenet161
from torchvision.models.inception import inception_v3
from torchvision.models.resnet import resnet18, resnet34, resnet50, resnet101, resnet152,\
resnext50_32x4d, resnext101_32x8d
from torchvision.models.squeezenet import squeezenet1_0, squeezenet1_1
from torchvision.models.vgg import vgg11, vgg13, vgg16, vgg19, vgg11_bn, vgg13_bn, vgg16_bn, vgg19_bn
from torchvision.models.segmentation import fcn_resnet101, deeplabv3_resnet101
from torchvision.models.googlenet import googlenet
from torchvision.models.shufflenetv2 import shufflenet_v2_x0_5, shufflenet_v2_x1_0
from torchvision.models.mobilenet import mobilenet_v2
In torchvision, the models have the following properties:
- Each model file can function and be executed independently
- They dont require any package other than PyTorch (encoded in
hubconf.pyasdependencies['torch']) - They dont need separate entry-points, because the models when created, work seamlessly out of the box
Minimizing package dependencies reduces the friction for users to load your model for immediate experimentation.
A more involved example is HuggingFace’s BERT models. Here is their hubconf.py
dependencies = ['torch', 'tqdm', 'boto3', 'requests', 'regex']
from hubconfs.bert_hubconf import (
bertTokenizer,
bertModel,
bertForNextSentencePrediction,
bertForPreTraining,
bertForMaskedLM,
bertForSequenceClassification,
bertForMultipleChoice,
bertForQuestionAnswering,
bertForTokenClassification
)
Each model then requires an entrypoint to be created. Here is a code snippet to specify an entrypoint of the bertForMaskedLM model, which returns the pre-trained model weights.
def bertForMaskedLM(*args, **kwargs):
"""
BertForMaskedLM includes the BertModel Transformer followed by the
pre-trained masked language modeling head.
Example:
...
"""
model = BertForMaskedLM.from_pretrained(*args, **kwargs)
return model
These entry-points can serve as wrappers around complex model factories. They can give a clean and consistent help docstring, have logic to support downloading of pretrained weights (for example via pretrained=True) or have additional hub-specific functionality such as visualization.
With a hubconf.py in place, you can send a pull request based on the template here. Our goal is to curate high-quality, easily-reproducible, maximally-beneficial models for research reproducibility. Hence, we may work with you to refine your pull request and in some cases reject some low-quality models to be published. Once we accept your pull request, your model will soon appear on Pytorch hub webpage for all users to explore.
[User] Workflow
As a user, PyTorch Hub allows you to follow a few simple steps and do things like: 1) explore available models; 2) load a model; and 3) understand what methods are available for any given model. Let’s walk through some examples of each.
Explore available entrypoints.
Users can list all available entrypoints in a repo using the torch.hub.list() API.
>>> torch.hub.list('pytorch/vision')
>>>
['alexnet',
'deeplabv3_resnet101',
'densenet121',
...
'vgg16',
'vgg16_bn',
'vgg19',
'vgg19_bn']
Note that PyTorch Hub also allows auxillary entrypoints (other than pretrained models), e.g. bertTokenizer for preprocessing in the BERT models, to make the user workflow smoother.
Load a model
Now that we know which models are available in the Hub, users can load a model entrypoint using the torch.hub.load() API. This only requires a single command without the need to install a wheel. In addition the torch.hub.help() API can provide useful information about how to instantiate the model.
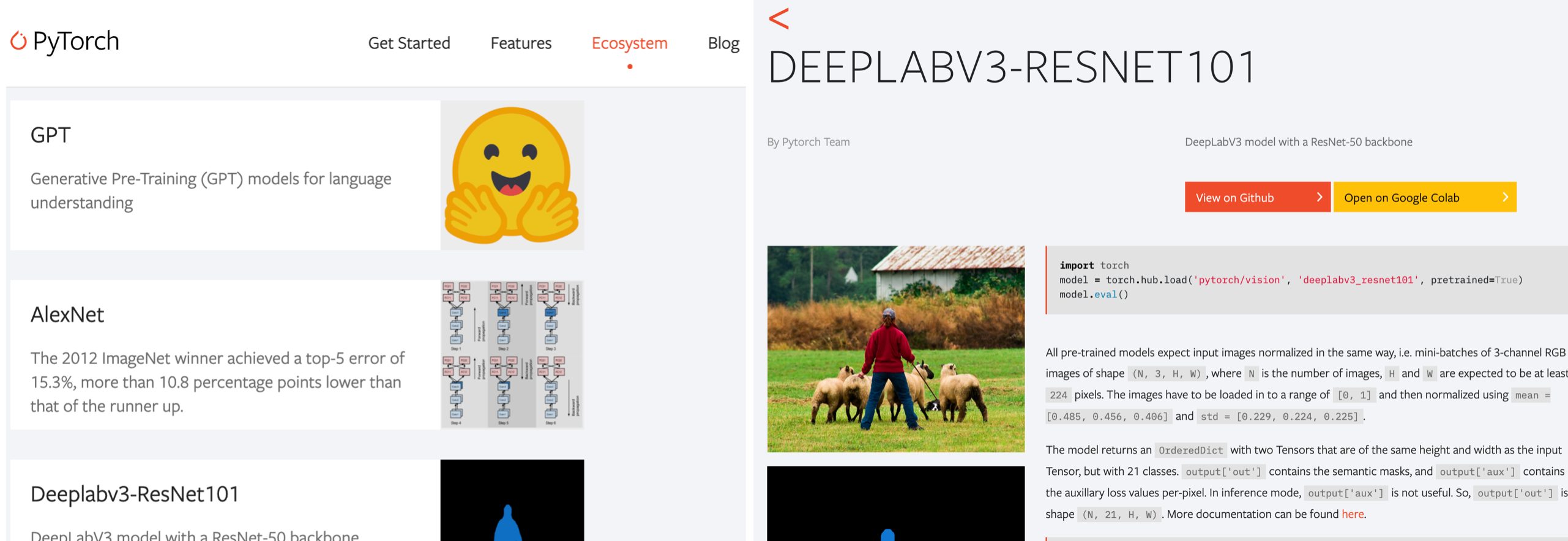
print(torch.hub.help('pytorch/vision', 'deeplabv3_resnet101'))
model = torch.hub.load('pytorch/vision', 'deeplabv3_resnet101', pretrained=True)
It is also common that repo owners will want to continually add bug fixes or performance improvements. PyTorch Hub makes it super simple for users to get the latest update by calling:
model = torch.hub.load(..., force_reload=True)
We believe this will help to alleviate the burden of repetitive package releases by repo owners and instead allow them to focus more on their research. It also ensures that, as a user, you are getting the freshest available models.
On the contrary, stability is important for users. Hence, some model owners serve them from a specificed branch or tag, rather than the master branch, to ensure stability of the code. For example, pytorch_GAN_zoo serves them from the hub branch:
model = torch.hub.load('facebookresearch/pytorch_GAN_zoo:hub', 'DCGAN', pretrained=True, useGPU=False)
Note that the *args, **kwargs passed to hub.load() are used to instantiate a model. In the above example, pretrained=True and useGPU=False are given to the model’s entrypoint.
Explore a loaded model
Once you have a model from PyTorch Hub loaded, you can use the following workflow to find out the available methods that are supported as well as understand better what arguments are requires to run it.
dir(model) to see all available methods of the model. Let’s take a look at bertForMaskedLM’s available methods.
>>> dir(model)
>>>
['forward'
...
'to'
'state_dict',
]
help(model.forward) provides a view into what arguments are required to make your loaded model run
>>> help(model.forward)
>>>
Help on method forward in module pytorch_pretrained_bert.modeling:
forward(input_ids, token_type_ids=None, attention_mask=None, masked_lm_labels=None)
...
Have a closer look at the BERT and DeepLabV3 pages, where you can see how these models can be used once loaded.
Other ways to explore
Models available in PyTorch Hub also support both Colab and are directly linked on Papers With Code and you can get started with a single click. Here is a good example to get started with (shown below).
Additional resources:
- PyTorch Hub API documentation can be found here.
- Submit a model here for publication in PyTorch Hub.
- Go to https://pytorch.org/hub to learn more about the available models.
- Look for more models to come on paperswithcode.com.
A BIG thanks to the folks at HuggingFace, the PapersWithCode team, fast.ai and Nvidia as well as Morgane Riviere (FAIR Paris) and lots of others for helping bootstrap this effort!!
Cheers!
Team PyTorch
FAQ:
Q: If we would like to contribute a model that is already in the Hub but perhaps mine has better accuracy, should I still contribute?
A: Yes!! A next step for Hub is to implement an upvote/downvote system to surface the best models.
Q: Who hosts the model weights for PyTorch Hub?
A: You, as the contributor, are responsible to host the model weights. You can host your model in your favorite cloud storage or, if it fits within the limits, on GitHub. If it is not within your means to host the weights, check with us via opening an issue on the hub repository.
Q: What if my model is trained on private data? Should I still contribute this model?
A: No! PyTorch Hub is centered around open research and that extends to the usage of open datasets to train these models on. If a pull request for a proprietary model is submitted, we will kindly ask that you resubmit a model trained on something open and available.
Q: Where are my downloaded models saved?
A: We follow the XDG Base Directory Specification and adhere to common standards around cached files and directories.
The locations are used in the order of:
- Calling
hub.set_dir(<PATH_TO_HUB_DIR>) $TORCH_HOME/hub, if environment variableTORCH_HOMEis set.$XDG_CACHE_HOME/torch/hub, if environment variableXDG_CACHE_HOMEis set.~/.cache/torch/hub