TLDR: We show promising results of up to a 1.46x speedup with <2% drop in accuracy on float32 Vision Transformers on A100 GPUs by applying block sparsity on MLP module’s weights. This approach can potentially be applied to other types of transformers including large language models. Our implementation and benchmarks to reproduce our results are available at https://github.com/pytorch-labs/superblock.
Introduction
PyTorch has landed a lot of improvements to CUDA kernels that implement block sparse matrix multiplications. Recent updates to Pytorch can lead up to 4.8x speedup on large matrix multiplication shapes with high sparsity levels over dense baselines.
In this blog, we show the promising results of applying block sparsity on weights of linear layers of MLP (multi-layer perceptron) layers in vision transformers (ViTs) and show end-to-end model speedups on A100 Nvidia GPUs.
As a recap, block sparsity sparsifies weights in tiles of blocks of predetermined size, rather than sparsifying individual elements. This particular sparsity pattern is interesting because it is amenable to GPU acceleration via fast sparse kernels. For more information about the differences between different sparsity patterns, or about sparsity as a whole, please check out torchao.

Illustrations of different types of sparsity.
Approach
Our approach can be broken down into two distinct steps:
- Training the model from scratch using block sparse masks subnets.
- Folding these masks into our weights to accelerate them for inference.
We explain our training and inference steps below
Training
Starting with an uninitialized Vision Transformer, we apply random trainable masks with a specified block size and sparsity level on the weights of output projection linear layer of attention blocks, the weights of the two linear layers inside the MLP, a.k.a., FFN (feed forward networks), as well as the final linear classification layer. The forward pass during training follows the supermask approach, as each mask is converted to binary map using a tuned threshold based on sparsity requirements, e.g., if we want 80% sparsity, we will have the threshold automatically tuned to keep top 20% weights. The masks are of a square <block size>x<block size> elements, where <block size> is a hyperparameter. The priority of the weights is dependent on the mask value or score which is trained. We multiply the binary masks of each layer with the weights to sparsify the model.
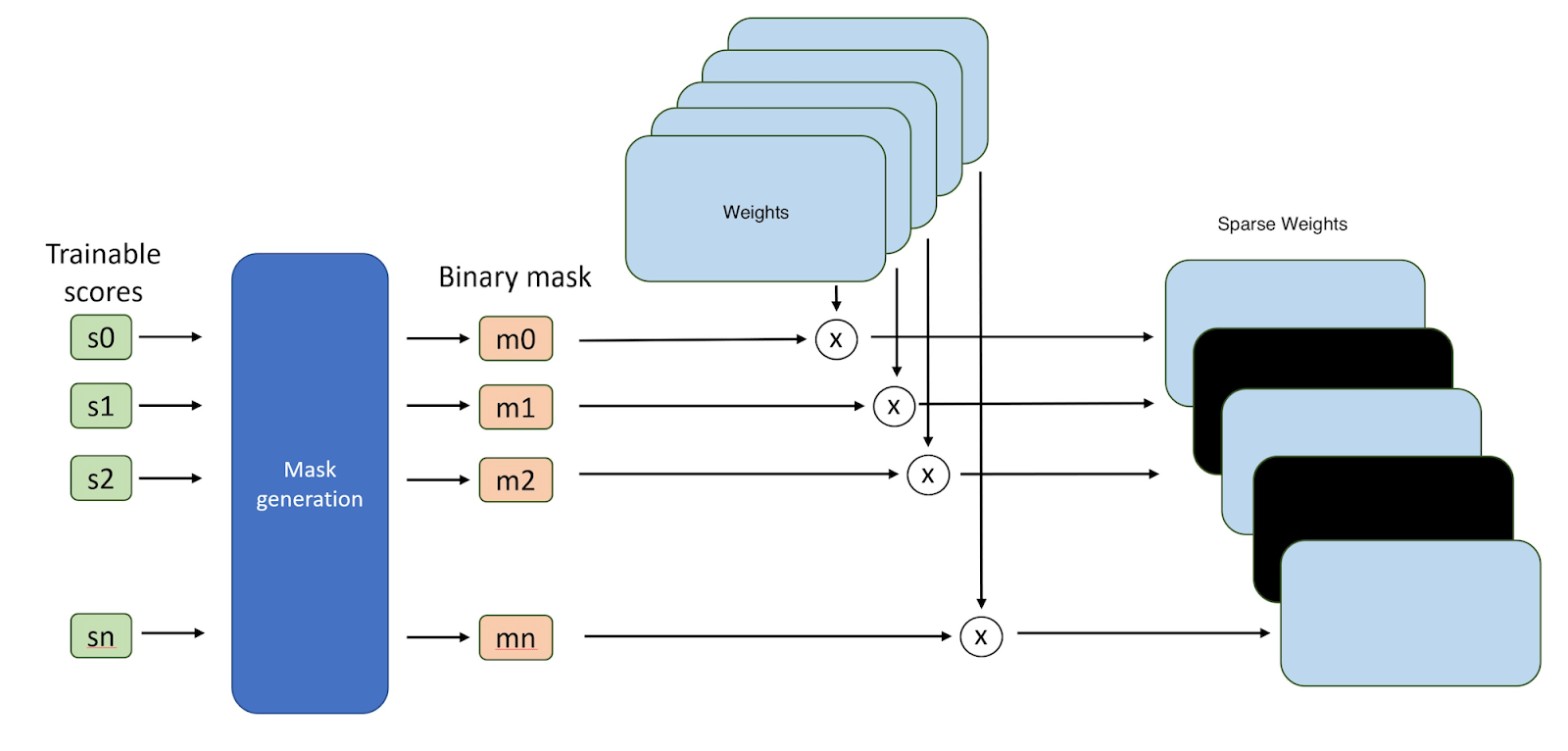
Illustration of the Supermask sparsification approach.
Inference
After training, the dense weights can be turned to sparse weights by multiplying with the mask and stored for inference. At this stage, although the weights have a high percentage of zero values, they are still stored in dense format. We use PyTorch’s to_sparse_bsr() API to to convert the weights to Block Sparse Representation (BSR) format that stores only the non-zero values and the indices of their blocks. This step only needs to be done once and the results can be cached for runtime.
During runtime, no changes in code are required. We just pass any input tensor to the model, and when the forward() function of the sparsified linear layers are invoked, PyTorch takes care of invoking the optimized matrix multiplication for block sparse weights. This should work for A100 as well as H100 NVIDIA GPUs.
Results: Microbenchmarks
To validate the viability of block sparsity from a performance standpoint, we first ran a series of microbenchmarks using this simple script. Using the linear shapes from ViT-b, we compared the speedup of our block sparse kernels across a single linear layer as we varied the sparsity level and block size of the weight matrix.
We run using PyTorch 2.3.0.dev20240305+cu121 nightly on NVIDIA A100s and report the speedup of each sparsity configuration compared to dense baseline. We observed positive speedups when block size >=32 or sparsity level >= 0.8 for float32, while for bfloat16 we observe smaller speedups and usually for block size 64 and higher sparsities. Hence, for end-to-end speedups on the model, we will focus in this blog on float32 and leave bfloat16 for future work.
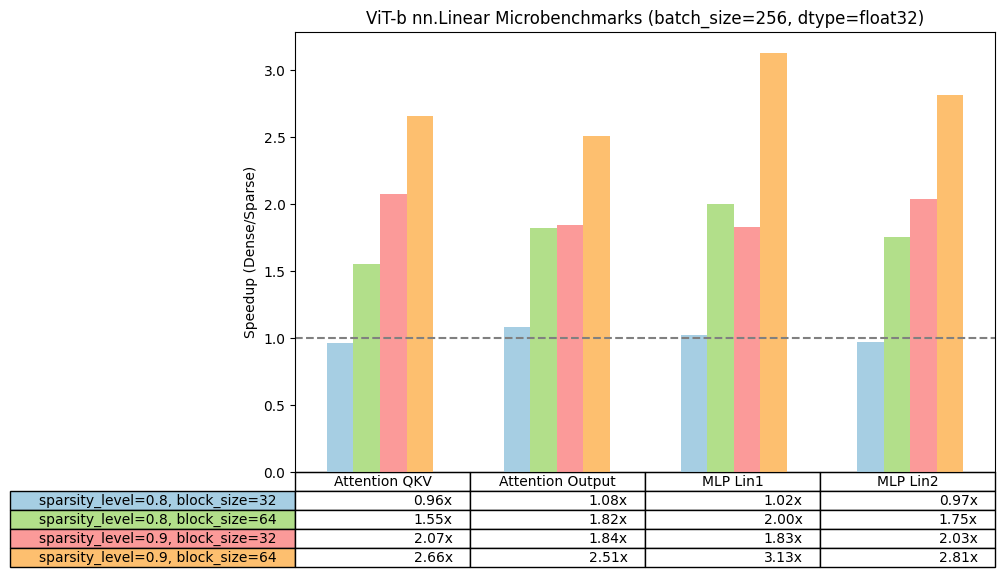
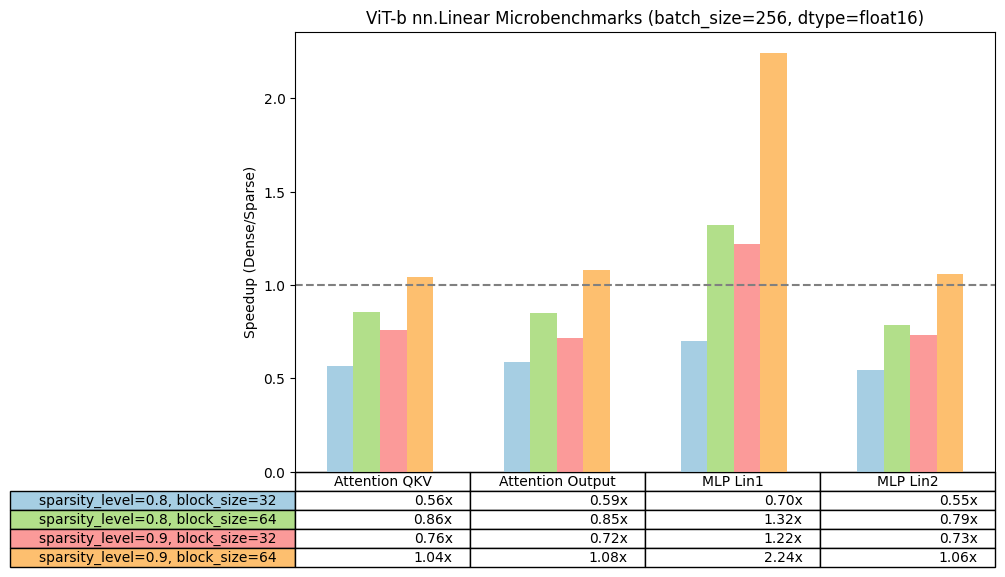
Micro benchmarking results on linear layers of ViT-b-16.
Results: Vision Transformers
Once we confirmed that we were able to show speedups over the linear layers, we focused on showing end-to-end speedups on ViT_B_16.
We trained this model from scratch on ImageNet dataset using the standard ViT_B_16 recipe. We show speedups for sparsifying MLP modules and leave sparsifying weights of input and output projections of attention for future work.
We looked at wall-clock inference speedup, focusing on batch size 256. We found that:
- For 90% sparsity we can get 1.24x, 1.37x, 1.65x speedups for block sizes 16, 32, and 64 respectively.
- To obtain speedup, the minimum sparsity for block sizes 16, 32, and 64 are 0.86, 0.82, and 0.7 respectively. Hence, as expected, the larger the block size, the smaller sparsity we need to obtain speedup.
We note a limitation of the sparse_bsr() API: that layers need to be multiples of the block size. Since the dimensions of the last FC classification layer in ViT was not a multiple of the block size, they were not converted to BSR representation in our experiments.
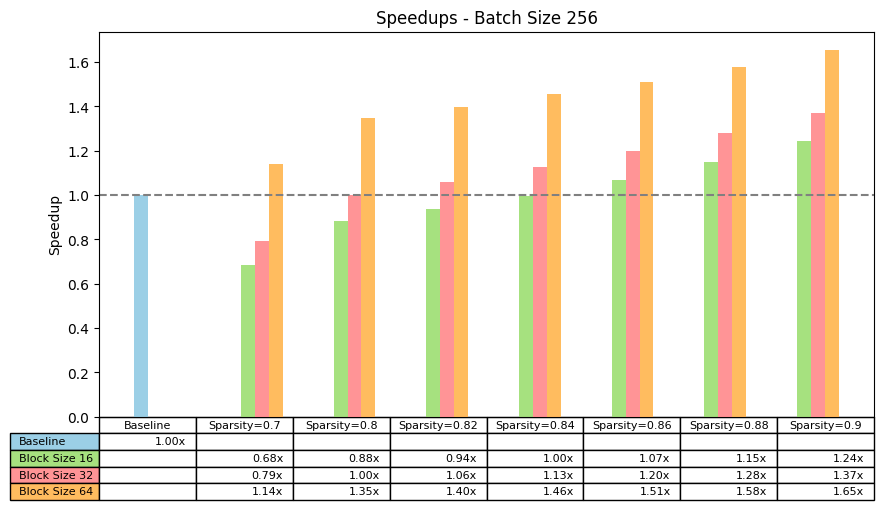
Speedup on ViT-b-16 with batch size 256 on MLP modules across different batch sparsities and block sizes.
We also explored the speedup for different batch sizes for 90% sparsity. We observed a speedup over the baseline for batch sizes starting from 16 and upwards. While bigger block sizes have bigger speedups at the largest batch sizes, the smallest possible batch size to obtain >1 speedup is smaller for smaller block sizes.
We believe on-device hardware can obtain speedups for batch size 1 as they – unlike server GPUs – can be fully utilized at such small batch sizes.
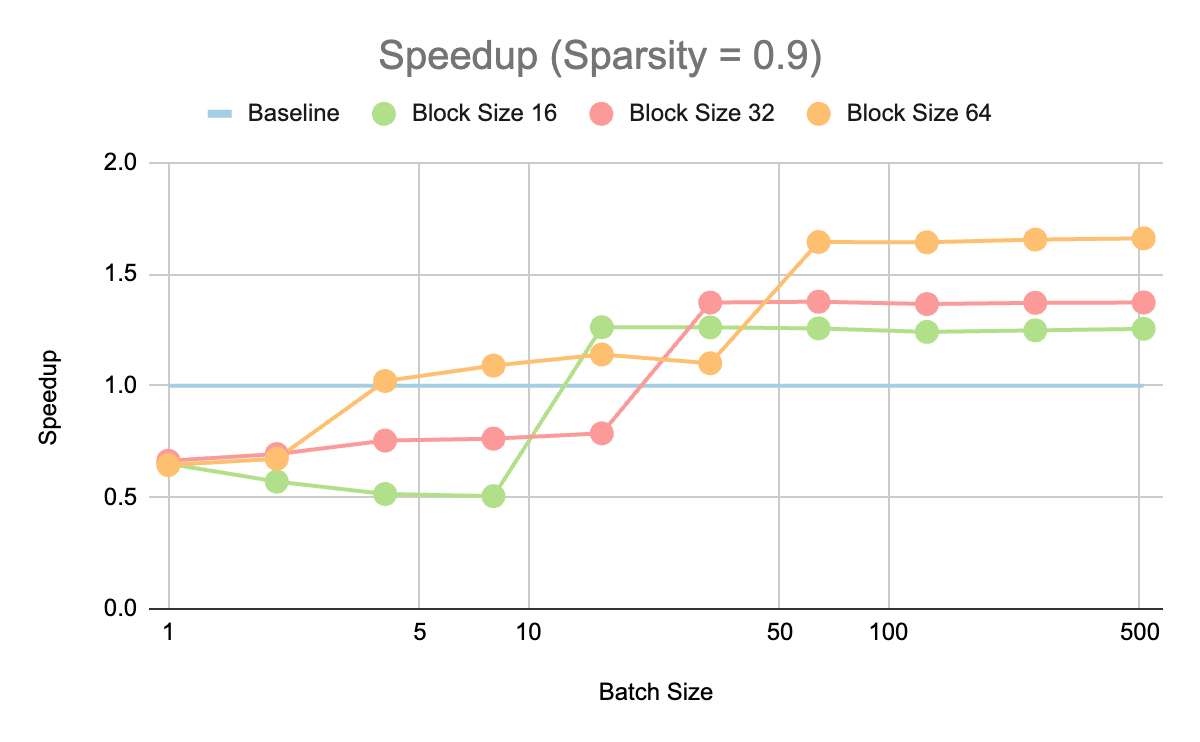
Speedup on ViT-b-16 with 90% sparsity on MLP modules across different batch sizes and block sizes.
Looking at the Top-1 accuracy on ImageNet=blurred test set of the sparsified models for different block sizes and sparsities, we see a few expected results:
- low levels of sparsity (<=70%) have no meaningful regression in accuracy
- mid levels of sparsity (>=80% to <90%) have limited regression in accuracy
- high levels of sparsity (>=90%) removes so many weights that accuracy is significantly impacted
More research could be done to improve accuracies of higher sparsities and larger block sizes. We hope that the block sparsity support in PyTorch and the illustrated speedups in this blog will encourage researchers to explore more accurate sparsification approaches.
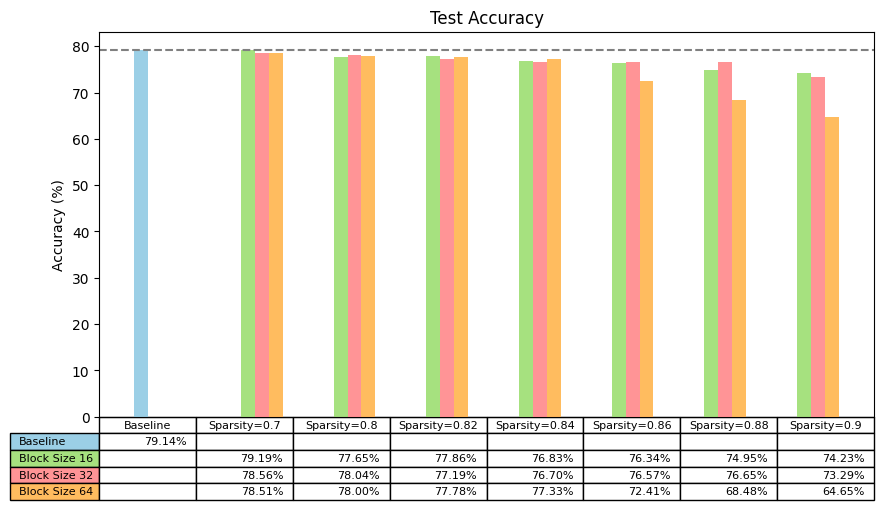
Accuracies on training ViT-b-16 on ImageNet-blurred using the SuperMask approach.
Next Steps
We have shown promising speedups for block sparsifying MLP modules ViT in float32 precision. There is still more work to be done in order to observe speedups on bfloat16 and we hope to obtain progress on that soon. Possible next steps to further optimize block sparsity on vision transformers and transformers in general:
- Perform block sparsity on attention input and output projections.
- Perform block sparsity during finetuning rather than training from scratch.
- Perform further optimizations on the matmul kernels for ViT’s linear operator specific shapes (especially for 80% and lower sparsity).
- Combine with other optimizations such as int8 and torch.compile()
- Explore other weight sparsification algorithms, e.g., Spartan, to improve accuracy
- Explore selecting weights to sparsify (e.g., specific transformer layers)
Please reach out to melhoushi@meta.com if you have questions or are interested in contributing to block sparsification!
Additionally if you’re broadly interested in sparsity please feel free to reach out to @jcaip / jessecai@meta.com and please come check out torchao, a community we’re building for architecture optimization techniques like quantization and sparsity.