In our previous Quantization-Aware Training (QAT) blog, we introduced the initial QAT flow in TorchAO for large language models targeting edge devices with ExecuTorch. Since then, we extended this flow to also target fast CUDA kernels like the ones in MSLK for fast inference in vLLM, and incorporated this flow into popular fine-tuning frameworks like Unsloth and Axolotl. We also explored more advanced QAT techniques like PARQ for lower bit quantization (prototype):
- Unsloth integration: Recover up to 66.9% accuracy degradation with INT4 QAT and achieve 1.73x inference speedup compared to BF16. Also check out our notebooks and HuggingFace checkpoints for an end-to-end guide.
- Axolotl integration: Recover up to 71.6% accuracy degradation with NVFP4 QAT (prototype) and achieve 1.35x inference speedup with 1/4th of the HBM usage compared to BF16 on B200 GPUs.
- PARQ: (prototype) An alternate optimizer-based QAT technique for lower bit quantization. Achieve on par accuracy with a 3-bit per-row model compared to a 4-bit per-group baseline, while using only ~58% memory footprint and decoding at ~1.57x faster throughput.
Try out our latest QAT flow with a few lines of code!
from torchao.quantization import quantize_, Int4WeightOnlyConfig from torchao.quantization.qat import QATConfig # The same config to use for Post-Training Quantization (PTQ) base_config = Int4WeightOnlyConfig(group_size=32) # Prepare step: model is now "fake quantized" and ready for training quantize_(model, QATConfig(base_config, step="prepare") train(model) # Convert step: model is now quantized and ready for inference quantize_(model, QATConfig(base_config, step="convert")
Quantization-Aware Training
One well-known technique to mitigate the accuracy degradation from post-training quantization (PTQ) is QAT, which is an optional fine-tuning step that adapts the model weights towards a representation that is more “aware” that they will be quantized eventually. QAT achieves this by “fake quantizing” weights and optionally activations during training, which means mimicking PTQ numerics as closely as possible and then immediately dequantizing back to high precision values during the forward pass, while leaving the backward pass unchanged.
QAT can also be combined with Low-Rank Adapation (LoRA) to reap the benefits of both worlds: significantly reducing storage and compute requirements during training while mitigating quantization degradation. LoRA is a popular fine-tuning technique that reduces the number of trainable parameters significantly by freezing the original model weights and instead training only a new set of LoRA “adapters” that are a small fraction of the model in terms of size. During training, fake quantization is applied to both the LoRA adapters (A and B in Figure 1) and the frozen weights (and optionally the input activations), since the adapters will eventually be merged back into the weights in the quantized model. This technique has been shown to speed up QAT by 1.89x while reducing the memory required by 36.1%.
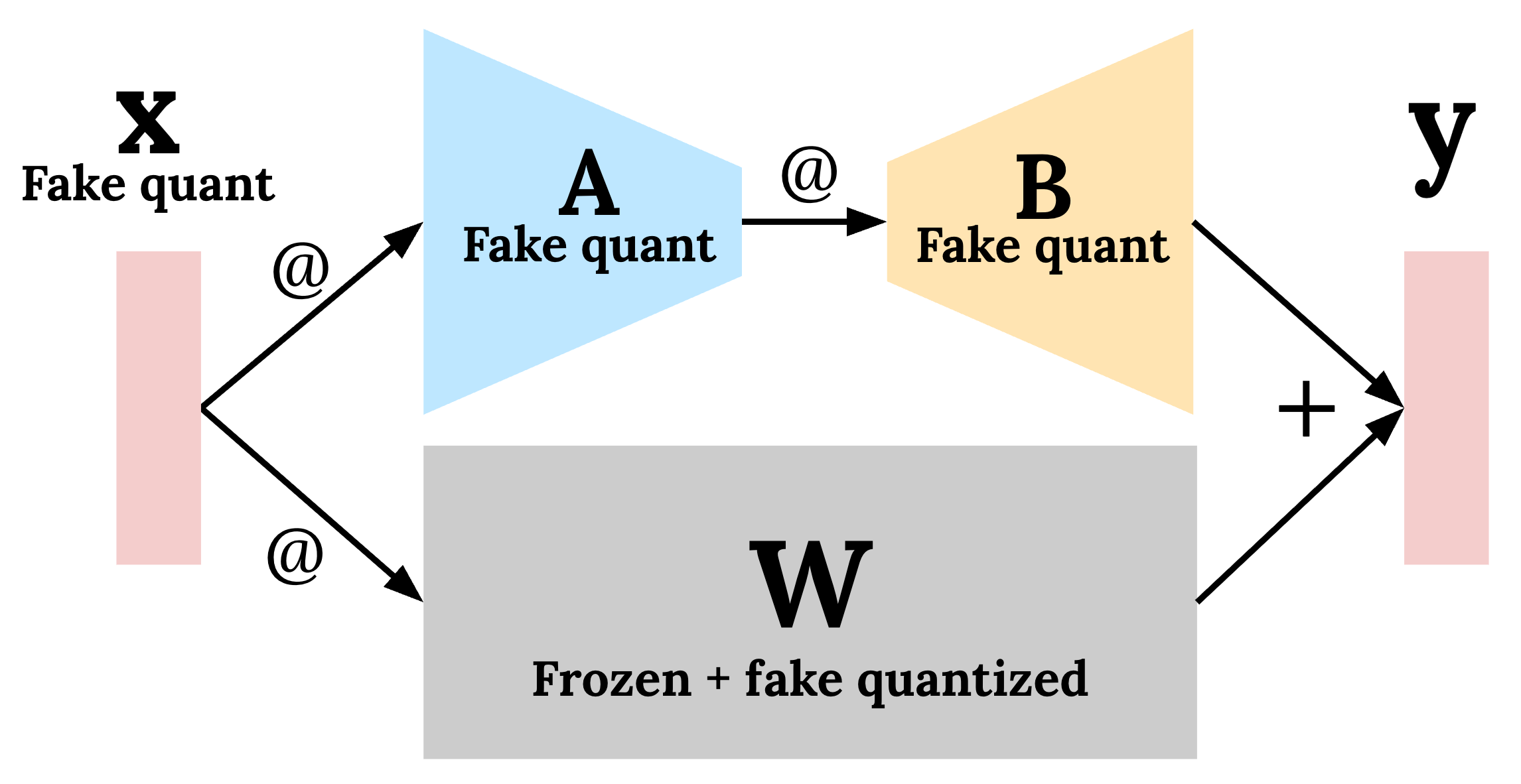
Figure 1: Combining QAT + LoRA allows users to mitigate quantization degradation while speeding up training and reducing memory footprint during training. Fake quantization is applied dynamically to the frozen weights, the LoRA adapters, and (optionally) the input activations.
Note that QAT + LoRA differs from QLoRA in that weights (and optionally activations) are fake quantized during training, instead of actually quantized to actual lower bit dtypes (e.g. NF4) and stored in this representation before training. In general, the quantization scheme simulated during QAT should match the actual post-training quantization scheme as much as possible.
As of TorchAO 0.16.0, we support the following dtype combinations:
| Weight dtype | Input activation dtype | TorchAO config |
| INT4 | FP32, BF16 | Int4WeightOnlyConfig |
| INT4 | FP8 | Float8DynamicActivationInt4WeightConfig |
| INT4 | INT8 | Int8DynamicActivationIntxWeightConfig (for edge) |
| NVFP4 | NVFP4 | NVFP4DynamicActivationNVFP4WeightConfig (prototype) |
Integration with Unsloth
TorchAO’s QAT support is integrated into Unsloth’s fine-tuning workflows for both full fine-tuning (training all model parameters) and LoRA fine-tuning (training only the adapters). In our initial experiments, INT4 weight-only QAT recovered 66.9% accuracy degradation for Gemma3-4B on GPQA and 45.5% for Gemma3-12B on BBH when compared to the quantized baseline without QAT (Figure 2). This translates to raw accuracy improvements of 2.1% and 1.0%, respectively, just by applying fake quantization during fine-tuning (Figure 3). The resulting QAT quantized model can be used as a drop-in replacement for the non-QAT quantized model since the model structure is unchanged, but with superior accuracy.
Figure 2: Unsloth leverages QAT in TorchAO to recover accuracy degradation by up to 66.9% using INT4 QAT + LoRA (source). QAT recovered 45.5% of the 4.5% accuracy lost on Gemma3-12B BBH, 66.9% of the 1.5% accuray lost on Gemma3-4B GPTQ, 36.3% of the 1.11 word perplexity increase for Qwen3-4B WikiText, and 36.0% of the 4.5% accuracy lost on Llama-3.2-1B MMLU Pro.
Figure 3: Unsloth leverages QAT in TorchAO to boost the raw accuracy of quantized and fine-tuned models by up to 2.1% using INT4 QAT + LoRA (source). QAT recovered 2.1% out of 4.5% accuracy lost on Gemma3-12B BBH, 1.0% out of 1.5% accuracy lost on Gemma3-4B GPQA, 2.0% out of 5.8% accuracy lost on Qwen3-4B MMLU Pro, and 0.7% out of 2.0% accuracy lost on Llama-3.2-3B MMLU Pro.
Unsloth users can enable QAT in their fine-tuning workflows by simply specifying the extra qat_scheme flag as follows. For an end-to-end example, check out Unsloth’s free QAT notebooks or the model cards in our HuggingFace checkpoints, which were also fine-tuned with Unsloth.
from unsloth import FastLanguageModel model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/gemma3-12b-it", max_seq_length = 2048, load_in_16bit = True, ) model = FastLanguageModel.get_peft_model( model, r = 16, target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",], lora_alpha = 32, # We support fp8-int4, fp8-fp8, int4, int8-int4, phone-deployment qat_scheme = "int4", )
Unsloth also leverages TorchAO QAT to deploy models to smartphones like Pixel 8 and iPhone 15 Pro through ExecuTorch, recovering up to 70% accuracy degradation in the process. Users can specify qat_scheme = "phone-deployment"or"int8-int4"for this use case. For more details, please refer to this blog.
Integration with Axolotl
We also integrated TorchAO’s QAT support into Axolotl’s multi-GPU full fine-tuning workflows. Axolotl supports a wide variety of QAT schemes, including INT4 weight-only, FP8 dynamic activations + INT4 weights, and NVFP4 dynamic activations + NVFP4 weights (prototype).
Thanks to support from Lambda Labs, we were able to demonstrate the effectiveness of QAT on a Lambda Labs Instant Cluster comprising 2xB200 nodes connected with NVLINK intra-node and Infiniband inter-node by training model using QAT of sizes up to 72B parameters. In our initial experiments, NVFP4 QAT recovered significant accuracy degradation when fine-tuning and evaluating across both instruction-following and mathematical reasoning tasks and benchmarks. We recovered up to 63.2% of the accuracy degradation on Gemma3-12B, and 71.6% on Gemma3-27B, translating to +3.2% and +2.3% raw accuracy improvements, respectively (Figures 4 and 5).
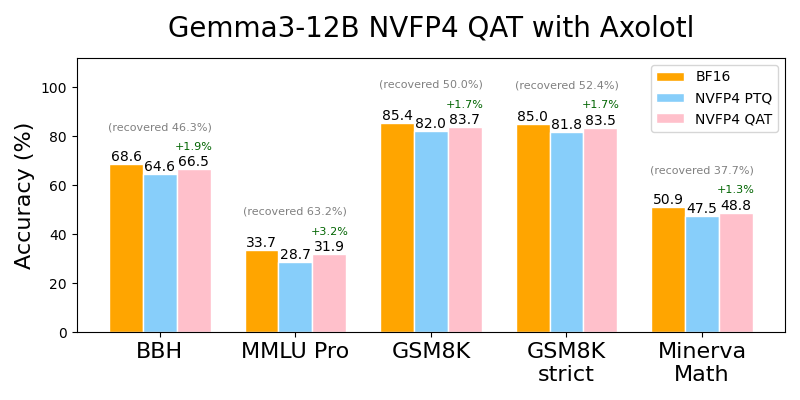
Figure 4: Axolotl leverages NVFP4 QAT in TorchAO to recover accuracy degradation by up to 63.2% (+3.2% in absolute accuracy) for Gemma3-12B.
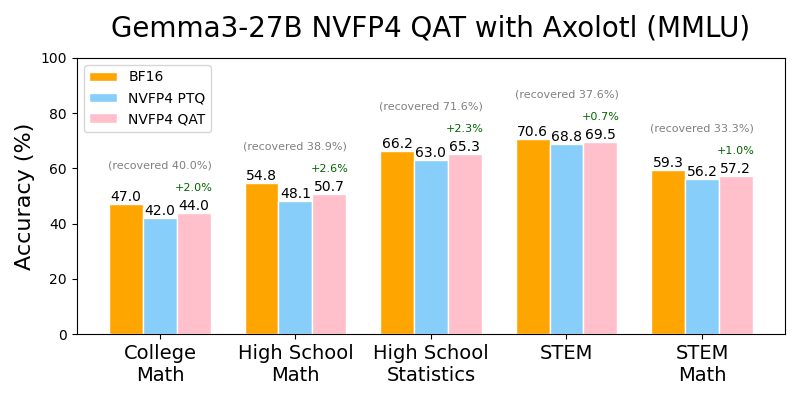
Figure 5: Axolotl leverages NVFP4 QAT in TorchAO to recover accuracy degradation by up to 71.6% (+2.4% in absolute accuracy) for Gemma3-27B across a variety of MMLU tasks.
Applying QAT to Axolotl fine-tuning workflows is straightforward. Simply add the following section in your config file (see these example configs):
# my_qat_workflow.yaml qat: activation_dtype: nvfp4 weight_dtype: nvfp4 group_size: 16 # NVFP4 only supports group size of 16 per specification
Then run the following to fine-tune and quantize with the same config. Note that fine-tuning with NVFP4 QAT is only supported on Blackwell GPUs or above for now:
axolotl train my_qat_workflow.yaml axolotl quantize my_qat_workflow.yaml
For more detailed instructions, please refer to the following documentation:
Piecewise-Affine Regularized Quantization (PARQ)
PARQ is a new algorithm in TorchAO that makes doing QAT with custom lower bit schemes straightforward (see 2025 ICML paper). In particular, it supports QAT with a “stretched elastic quantization” function that spreads the output values more evenly across the quantization grid, in contrast to the usual affine grid. Recent research shows that this is essential for quality when quantizing below 4 bits. In our experiments, the 3-bit per-row model trained with PARQ achieved on par accuracy with the 4-bit per-group baseline, while using only ~58% memory footprint and decoding at ~1.57x faster throughput.
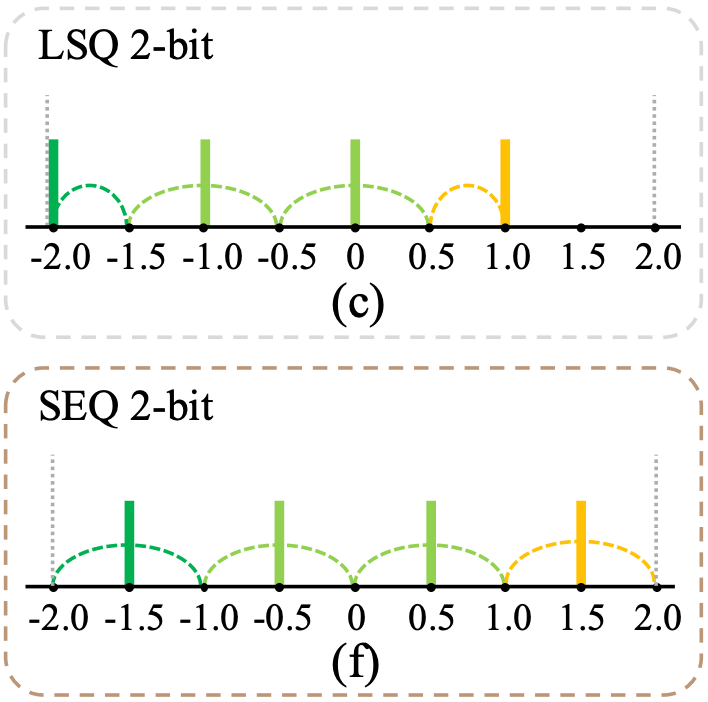
Beyond simplifying experimentation with ultra-low-bit QAT, PARQ integrates seamlessly with ExecuTorch similar to the existing TorchAO QAT flow, enabling an end-to-end path from training to efficient on-device deployment using the PyTorch ecosystem.
TorchAO Integration
Existing TorchAO QAT works by swapping modules in the forward pass. PARQ takes a different approach: it performs quantization directly inside the optimizer’s step function. Users specify which parameters to quantize, along with the quantization functions and granularities, when defining the optimizer’s param_groups. As a result, no changes to the model code are required.
PARQ quantizes weights by applying configuration classes and quantization primitives from TorchAO’s quantize_ API. Depending on the config, it can choose quantization parameters based on an affine grid or the new stretched grid suitable for low-bit QAT. This close integration between PARQ and existing QAT methods ensures a familiar setup process and numerical consistency. Furthermore, it easily composes with dynamic activation quantization from the same API.
In TorchAO, we provide simple APIs for configuring PARQ optimizers to match a wide range of quantization strategies. For example, you might quantize all linear layers to 2 bits while keeping token embeddings at 4 bits. This ability to mix quantizers and bitwidths makes it easy to explore advanced configurations and significantly speeds up experimentation.
import torch from torchao.prototype.parq.api import QuantConfig, create_optimizer # Define how to quantize linear weights from `model.parameters()` def linear_filter_fn(module, fqn): return isinstance(module, torch.nn.Linear) and fqn.endswith("weight") linear_config = QuantConfig(bitwidth=2, group_size=None) quant_configs_and_filter_fns = [(linear_config, linear_filter_fn)] # Apply `parq.optim.QuantOptimizer` to quantize in `optimizer.step()` optimizer = create_optimizer( model, quant_configs_and_filter_fns, base_optimizer_cls=torch.optim.AdamW, base_optimizer_kwargs={"weight_decay": 1e-2}, quant_per_channel=True, )
Low-bit QAT on Phi-4-mini-instruct and deployment with ExecuTorch
To showcase PARQ in a realistic setting, we performed low-bit fine-tuning on Microsoft’s Phi-4-mini-instruct model, using a variety of quantization schemes and compared these against a 4-bit PTQ baseline for both accuracy and on-device performance.
We release HuggingFace model cards and scripts for reproducing these results on public data:
- 2bit: Phi-4-mini-instruct-parq-2w-4e-shared
- 3bit: Phi-4-mini-instruct-parq-3w-4e-shared
- 4bit: Phi-4-mini-instruct-parq-4w-4e-shared-gsm
| Linear quantization | Embedding quantization | Finetuning task | ExecuTorch *.pte model size | |
| 2bit QAT | 2-bit per-row | 4-bit per-row, tied with lm_head | General conversation | 1.13GB |
| 3bit QAT | 3-bit per-row | 4-bit per-row, tied with lm_head | General conversation | 1.53GB |
| 4bit QAT | 4-bit per row | 4-bit per-row, tied with lm_head | Grade school math problems | 1.93GB |
| 4bit PTQ | 4-bit per-group (32), including lm_head | 8-bit per-row | N/A | 2.78GB |
Despite using a far coarser per-row quantization granularity, our 3-bit QAT model performs on par with a 4-bit PTQ model on a range of reasoning benchmarks, as we see in the benchmarks below. In addition, the 4-bit QAT model we optimized for grade school math is nearly 17% more accurate than the 4-bit PTQ baseline on such problems.
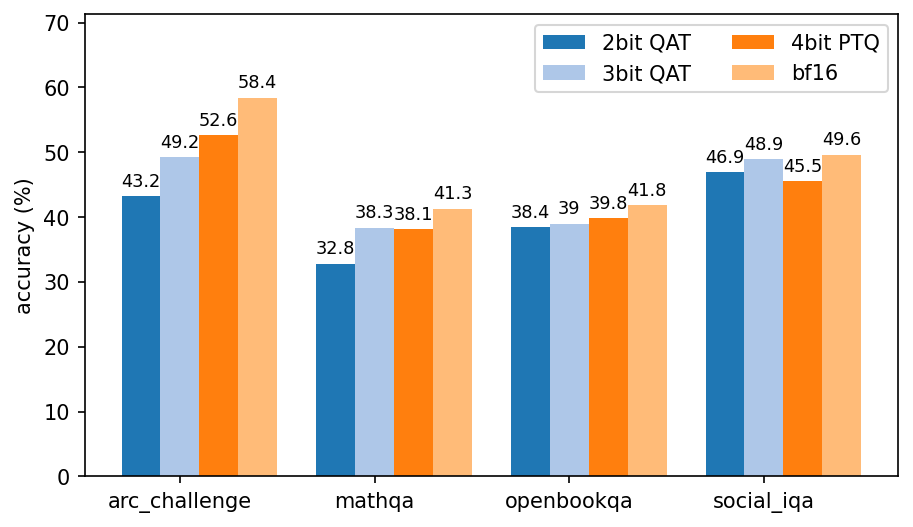
Figure 7a: Accuracies for sub-4 bit models trained with PARQ vs. 4-bit PTQ and base bf16 models.
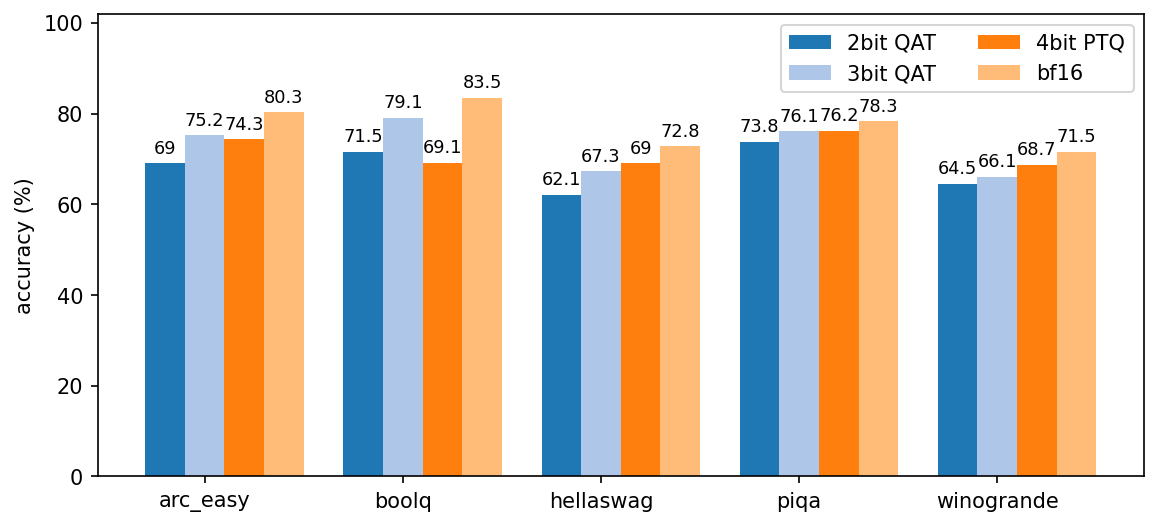
Figure 7b: Continuation of Figure 7a.
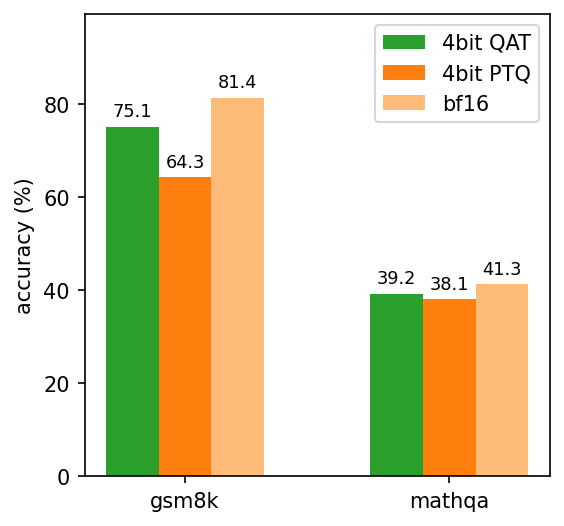
Figure 8: PARQ accuracies on math word problem benchmarks.
With ExecuTorch, we can run the 2, 3, and 4 bit models above on mobile devices. Below we show performance data and screenshots from running the models on iPhone 15 Pro: we see lower bitwidths leading to significant gains in decode speed and memory usage. Indeed, the exported 3-bit model takes only ~58% the memory footprint of the 4-bit model, while decoding at a ~1.57x faster speed, even though it achieves similar accuracy across the benchmarks above.
| Model | ExecuTorch backend | Memory (GB) | Decode speed (tok/sec) |
| 2bit QAT | TorchAO lowbit kernels | 1.4 | 27 |
| 3bit QAT | TorchAO lowbit kernels | 1.8 | 22 |
| 4bit QAT | TorchAO lowbit kernels | 2.2 | 18 |
| 4bit PTQ | XNNPACK | 3.1 | 14 |
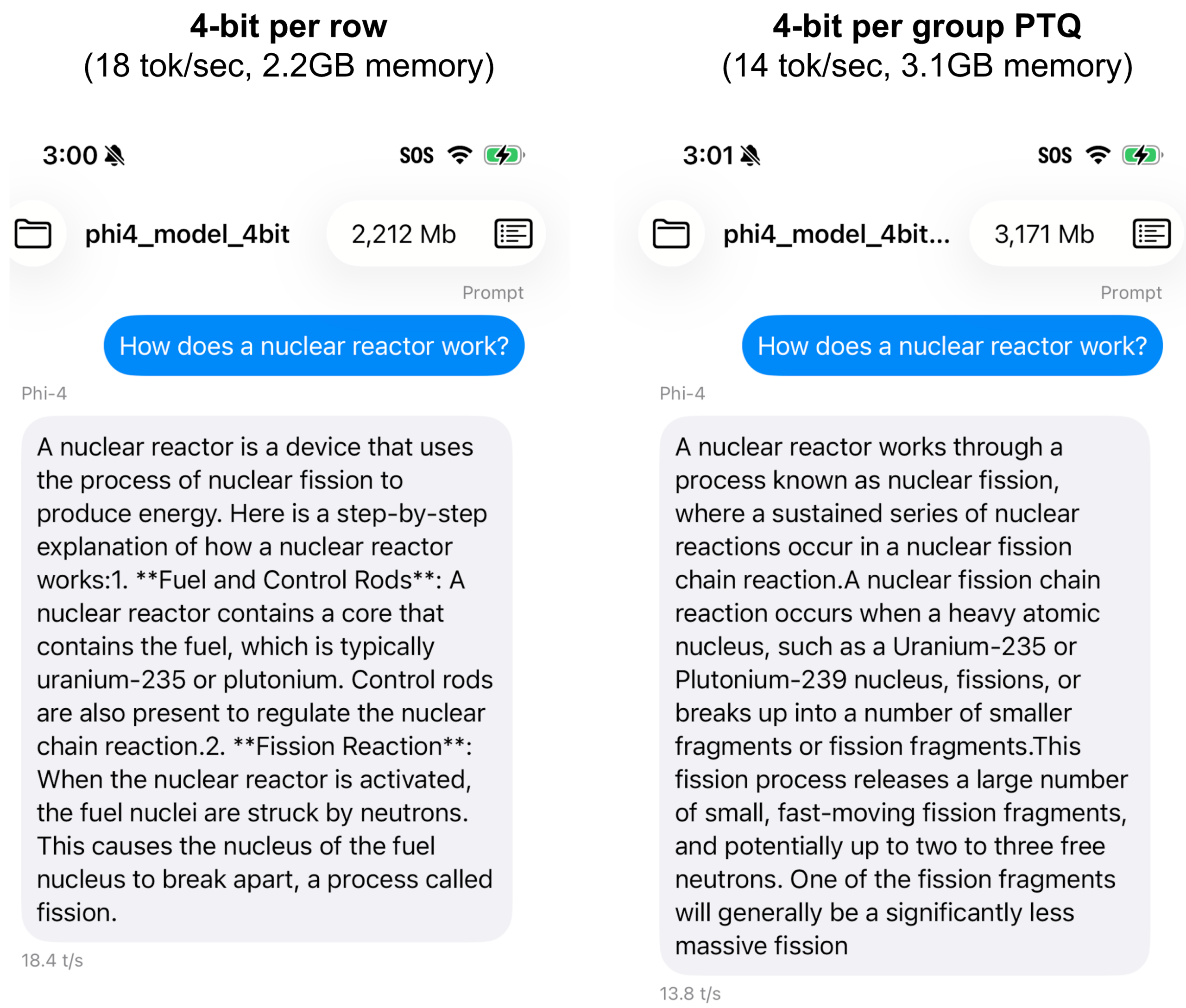

Figure 9: Example output of Phi-4-mini-instruct quantized with and without PARQ QAT at bit-widths of 2, 3, and 4, deployed on an iPhone 15 Pro using ExecuTorch.
Looking Ahead
In this blog, we highlighted two new TorchAO QAT integrations with Unsloth and Axolotl and presented PARQ, a novel optimizer-based QAT technique targeting lower bit settings. In the near future, we plan to explore the following directions to continue this work:
- Reinforcement Learning. Popular RL algorithms like Proximal Policy Optimization (PPO) and Group Relative Policy Optimization (GRPO) can benefit from on-the-fly quantized rollouts. To maintain true on-policy RL training, however, QAT will be needed to match inference numerics. Exploring how TorchAO QAT can be applied in this setting will be an interesting direction to explore.
- Leveraging GPU kernels during QAT. There are opportunities to speed up training using custom kernels designed for QAT like the ones in FP-Quant, e.g., performing MXFP4 GEMM during forward and MXFP8 GEMM during backward in this autograd function. For QAT workflows targeting integer quantized dtypes, replicating the integer numerics during training can additionally reduce potential numerical discrepancies in the end-to-end workflow.
- Further integrations. We also plan to incorporate QAT into newer fine-tuning frameworks like TorchForge and improve our existing integrations by, for example, adding LoRA support to Axolotl QAT.
- PARQ. We plan to extend support for experimental new optimization algorithms. These are similar to PARQ’s existing algorithm but have more precise convergence guarantees on nonconvex problems.
Acknowledgements
We are deeply grateful to our external collaborators Daniel Han, Michael Han, Datta Nimmaturi (Unsloth), Salman Mohammadi, and Wing Lian (Axolotl) for a fruitful TorchAO QAT integration. We also thank Nick Harvey from Lambda Labs for providing the infrastructure for running our NVFP4 QAT experiments. Finally, we express our gratitude to everyone who provided valuable feedback to the project and this blog, including Driss Guessous, Vasiliy Kuznetsov, Supriya Rao, Mark Saroufim, and Lin Xiao.