In this blog, we present an end-to-end Quantization-Aware Training (QAT) flow for large language models in PyTorch. We demonstrate how QAT in PyTorch can recover up to 96% of the accuracy degradation on hellaswag and 68% of the perplexity degradation on wikitext for Llama3 compared to post-training quantization (PTQ). We present the QAT APIs in torchao and showcase how users can leverage them for fine-tuning in torchtune.
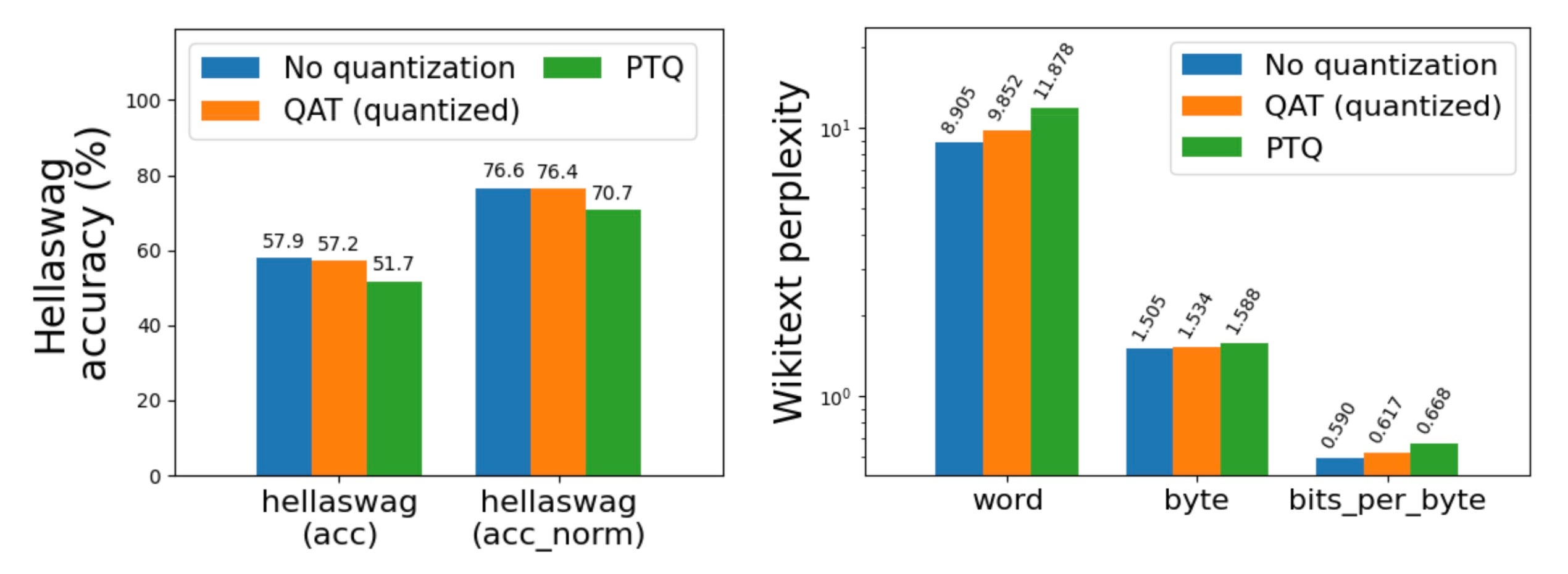
Figure 1: Llama3-8B fine-tuned on the C4 dataset (en subset) with and without QAT using int8 per token dynamic activations + int4 grouped per channel weights, evaluated on hellaswag and wikitext on a A100 GPU. Note the log scale for wikitext (lower is better).
To demonstrate the effectiveness of QAT in an end-to-end flow, we further lowered the quantized model to XNNPACK, a highly optimized neural network library for backends including iOS and Android, through executorch. After lowering to XNNPACK, the QAT model saw 16.8% lower perplexity than the PTQ model, while maintaining the same model size and on-device inference and generation speeds.
| Lowered model metric | PTQ | QAT |
| Wikitext word perplexity (↓) | 23.316 | 19.403 |
| Wikitext byte perplexity (↓) | 1.850 | 1.785 |
| Wikitext bits per byte (↓) | 0.887 | 0.836 |
| Model size | 3.881 GB | 3.881 GB |
| On-device inference speed | 5.065 tok/s | 5.265 tok/s |
| On-device generation speed | 8.369 tok/s | 8.701 tok/s |
Table 1: QAT achieved 16.8% lower perplexity and unchanged model sizes and on-device inference and generation speeds on the Llama3-8B model lowered to XNNPACK. Linear layers are quantized using int8 per token dynamic activations + int4 grouped per channel weights, and embeddings are additionally quantized to int4 using a group size of 32 (QAT is only applied to linear layers). Wikitext evaluation is performed using 5 samples and a max sequence length of 127 on server CPU, since evaluation is not available on device (lower is better for all wikitext results). On-device inference and generation is benchmarked on the Samsung Galaxy S22 smartphone.
QAT APIs
We are excited for users to try our QAT API in torchao, which can be leveraged for both training and fine-tuning. This API involves two steps, prepare and convert: prepare applies a transformation on the linear layers in the model to simulate the numerics of quantization during training, and convert actually quantizes these layers into lower bit-widths after training. The converted model can then be used in the exact same way as the PTQ model:
import torch
from torchtune.models.llama3 import llama3
from torchao.quantization.prototype.qat import Int8DynActInt4WeightQATQuantizer
# Smaller version of llama3 to fit in a single GPU
model = llama3(
vocab_size=4096,
num_layers=16,
num_heads=16,
num_kv_heads=4,
embed_dim=2048,
max_seq_len=2048,
).cuda()
# Quantizer for int8 dynamic per token activations +
# int4 grouped per channel weights, only for linear layers
qat_quantizer = Int8DynActInt4WeightQATQuantizer()
# Insert "fake quantize" operations into linear layers.
# These operations simulate quantization numerics during
# training without performing any dtype casting
model = qat_quantizer.prepare(model)
# Standard training loop
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=1e-5)
loss_fn = torch.nn.CrossEntropyLoss()
for i in range(10):
example = torch.randint(0, 4096, (2, 16)).cuda()
target = torch.randn((2, 16, 4096)).cuda()
output = model(example)
loss = loss_fn(output, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
# Convert fake quantize to actual quantize operations
# The quantized model has the exact same structure as the
# quantized model produced in the corresponding PTQ flow
# through `Int8DynActInt4WeightQuantizer`
model = qat_quantizer.convert(model)
# inference or generate
Fine-tuning with torchtune
We also integrated this QAT flow into torchtune and provided recipes to run this in a distributed setting, similar to the existing full fine-tune distributed recipe. Users can additionally apply QAT during LLM fine-tuning by running the following command. See this README for more details.
tune run --nproc_per_node 8 qat_distributed --config llama3/8B_qat_full
What is Quantization-Aware Training?
Quantization-Aware Training (QAT) is a common quantization technique for mitigating model accuracy/perplexity degradation that arises from quantization. This is achieved by simulating quantization numerics during training while keeping the weights and/or activations in the original data type, typically float, effectively “fake quantizing” the values instead of actually casting them to lower bit-widths:
# PTQ: x_q is quantized and cast to int8
# scale and zero point (zp) refer to parameters used to quantize x_float
# qmin and qmax refer to the range of quantized values
x_q = (x_float / scale + zp).round().clamp(qmin, qmax).cast(int8)
# QAT: x_fq is still in float
# Fake quantize simulates the numerics of quantize + dequantize
x_fq = (x_float / scale + zp).round().clamp(qmin, qmax)
x_fq = (x_fq - zp) * scale
Since quantization involves non-differentiable operations like rounding, the QAT backward pass typically uses straight-through estimators (STE), a mechanism to estimate the gradients flowing through non-smooth functions, to ensure the gradients passed to the original weights are still meaningful. In this manner, the gradients are computed with the knowledge that the weights will ultimately be quantized after training, effectively allowing the model to adjust for quantization noise during the training process. Note that an alternative to QAT is quantized training, which actually casts the values to lower bit dtypes during training, but prior efforts have only seen success up to 8-bits, whereas QAT is effective even at lower bit-widths.
QAT in PyTorch
We added an initial QAT flow in torchao under prototype here. Currently we support int8 dynamic per-token activations + int4 grouped per-channel weights (abbreviated 8da4w) for linear layers. These settings are motivated by a combination of kernel availability on edge backends and prior research on LLM quantization, which found that per-token activation and per-group weight quantization achieves the best model quality for LLMs compared to other quantization schemes.
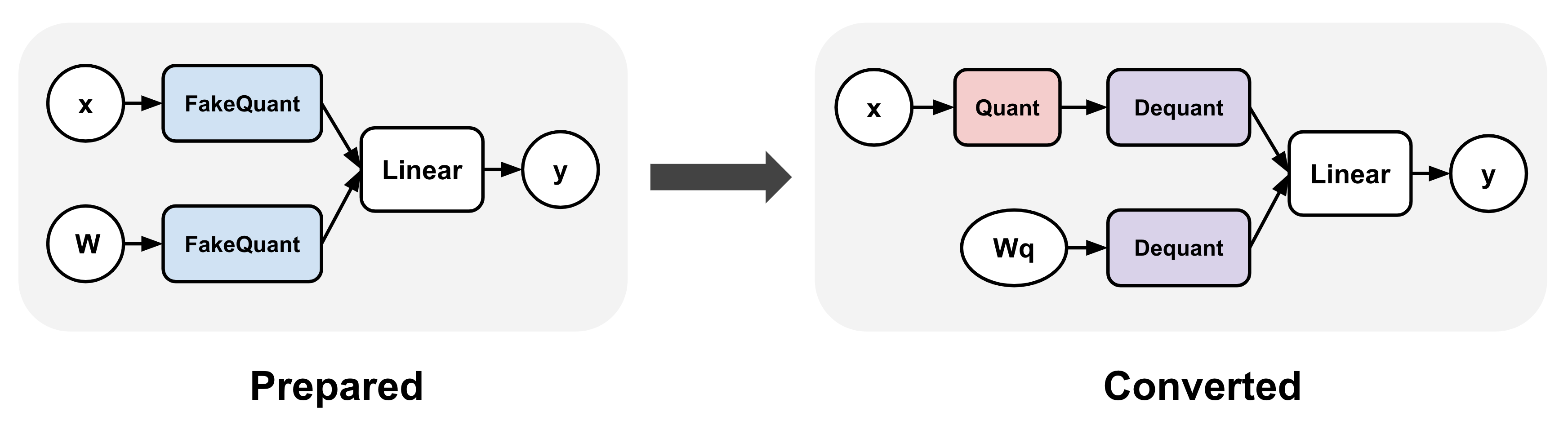
Figure 2: torchao QAT flow. This flow involves two steps: (1) prepare, which inserts the fake quantization ops into the model’s linear layers, and (2) convert, which converts these fake quantization ops with actual quantize and dequantize ops after training.
This flow produces the exact same quantized model as the PTQ flow using the same quantization settings (through Int8DynActInt4WeightQuantizer), but with quantized weights that achieve superior accuracies and perplexities. Thus, we can use the model converted from the QAT flow as a drop-in replacement for the PTQ model and reuse all the backend delegation logic and underlying kernels.
Experimental Results
All experiments in this blog post are performed using the torchtune QAT integration described above. We use 6-8 A100 GPUs with 80 GBs each to fine-tune Llama2-7B and Llama3-8B on the C4 dataset (en subset) for 5000 steps. For all experiments, we use batch size = 2, learning rate = 2e-5, max sequence length = 4096 for Llama2 and 8192 for Llama3, Fully Sharded Data Parallel (FSDP) as our distribution strategy, and activation checkpointing to reduce memory footprint. For 8da4w experiments, we use a group size of 256 for weights.
Since the pre-training dataset is not easily accessible, we perform QAT during the fine-tuning process. Empirically, we found that disabling fake quantization for the first N steps led to better results, presumably because doing so allows the weights to stabilize before we start introducing quantization noise to the fine-tuning process. We disable fake quantization for the first 1000 steps for all our experiments.
We evaluate our quantized models using the lm-evaluation-harness integration in torchtune. We report evaluation results from a variety of tasks commonly used to evaluate LLMs, including hellaswag, a commonsense sentence completion task, wikitext, a next token/byte prediction task, and a few question-answering tasks such as arc, openbookqa, and piqa. For wikitext, perplexity refers to the inverse of how well the model can predict the next word or byte (lower is better), and bits_per_byte refers to how many bits are needed to predict the next byte (lower is also better here). For all other tasks, acc_norm refers to the accuracy normalized by the byte-length of the target string.
Int8 Dynamic Activations + Int4 Weight Quantization (8da4w)
Starting with Llama2 8da4w quantization, we saw that QAT was able to recover 62% of the normalized accuracy degradation on hellaswag compared to PTQ, and 58% and 57% of the word and byte perplexity degradation (respectively) on wikitext. We see similar improvements for most of the other tasks.
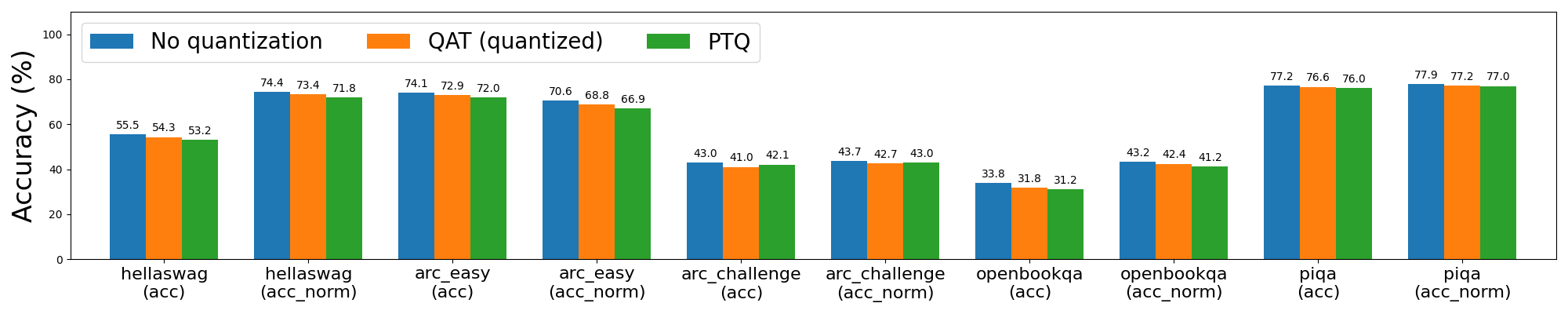
Figure 3a: Llama2-7B 8da4w quantization with and without QAT
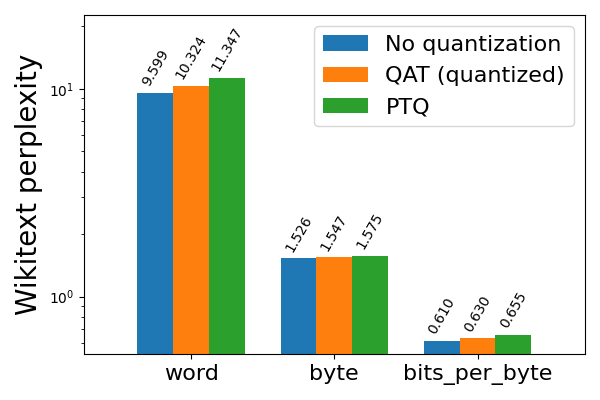
Figure 3b: Llama2-7B 8da4w quantization with and without QAT, evaluated on wikitext (lower is better)
Llama3 8da4w quantization saw even more pronounced improvements with QAT. On the hellaswag evaluation task, we were able to recover 96% of the normalized accuracy degradation on hellaswag compared to PTQ, with minimal overall degradation (<1%) compared to the non-quantized accuracy. On the wikitext evaluation task, QAT recovered 68% and 65% of the word and byte perplexity degradation (respectively). Even on arc_challenge, which was difficult for Llama2 QAT, we were able to recover 51% of the normalized accuracy degradation.
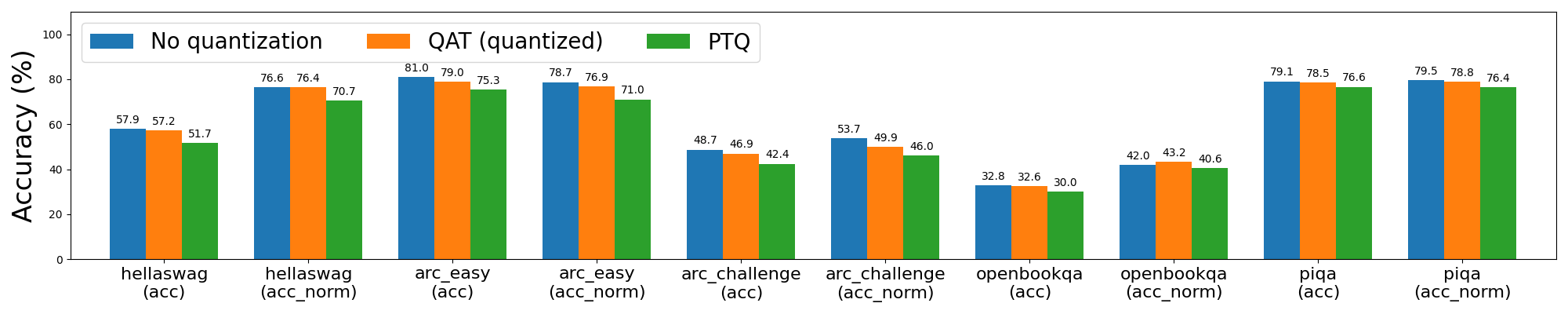
Figure 4a: Llama3-8B 8da4w quantization with and without QAT
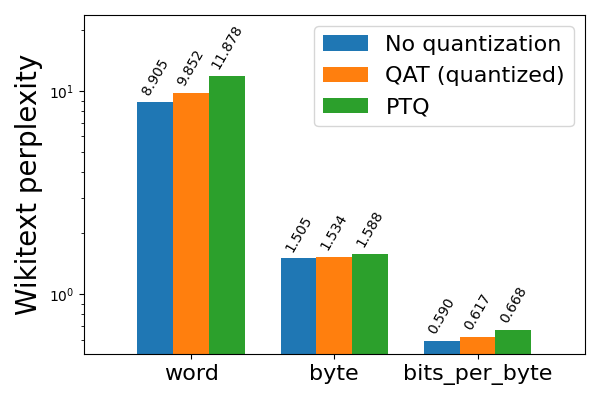
Figure 4b: Llama3-8B 8da4w quantization with and without QAT, evaluated on wikitext (lower is better)
Lower Bit Weight Only Quantization
We further extended the torchao QAT flow to 2-bit and 3-bit weight only quantization and repeated the same experiments for Llama3-8B. Quantization degradation is more severe at lower bit-widths, so we use a group size of 32 for all experiments for finer-grained quantization.
However, this is still not enough for 2-bits PTQ, which saw wikitext perplexity explode. To mitigate this problem, we leverage knowledge from prior sensitivity analysis that the first 3 and last 2 layers of the Llama3 model are the most sensitive, and skip quantizing these layers in exchange for a moderate increase in quantized model size (1.78 GB for 2-bits and 1.65 GB for 3-bits). This brought the wikitext word perplexity down from 603336 to 6766, which is significant but still far from acceptable. To further improve the quantized model, we turn to QAT.
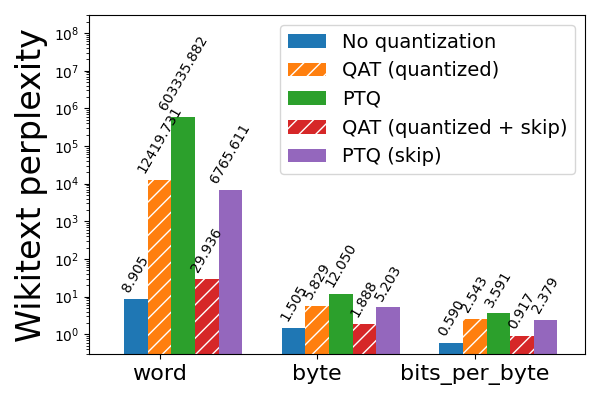
Figure 5a: Llama3-8B 2-bit weight only quantization with and without QAT, evaluated on wikitext (lower is better). Bars with “skip” refer to skipping quantization for the first 3 and last 2 layers of the model, which are more sensitive to quantization. Note the log scale.
We observe that applying QAT while skipping quantization for the first 3 and last 2 layers further brought the word perplexity down to a much more reasonable value of 30 (from 6766). More generally, QAT was able to recover 53% of the normalized accuracy degradation on hellaswag compared to PTQ, and 99% and 89% of the word and byte perplexity degradation (respectively) on wikitext. Without skipping the sensitive layers, however, QAT was far less effective at mitigating degradation in quantized model quality.
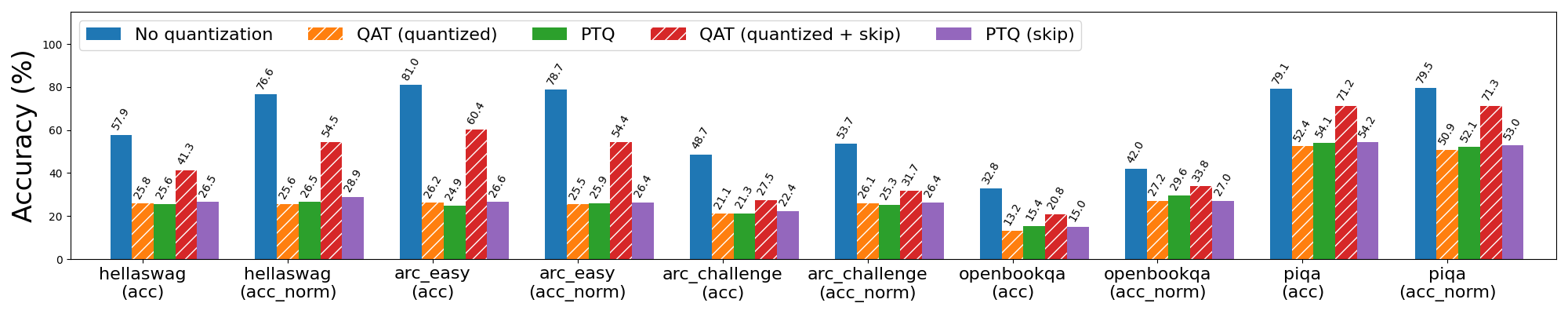
Figure 5b: Llama3-8B 2-bit weight only quantization with and without QAT. Bars with “skip” refer to skipping quantization for the first 3 and last 2 layers of the model, which are more sensitive to quantization.
For 3-bit weight only quantization, QAT was effective even without skipping the first 3 and last 2 layers, though skipping these layers still led to better results for both PTQ and QAT. In the skip case, QAT was able to recover 63% of the normalized accuracy degradation on hellaswag compared to PTQ, and 72% and 65% of the word and byte perplexity degradation (respectively) on wikitext.
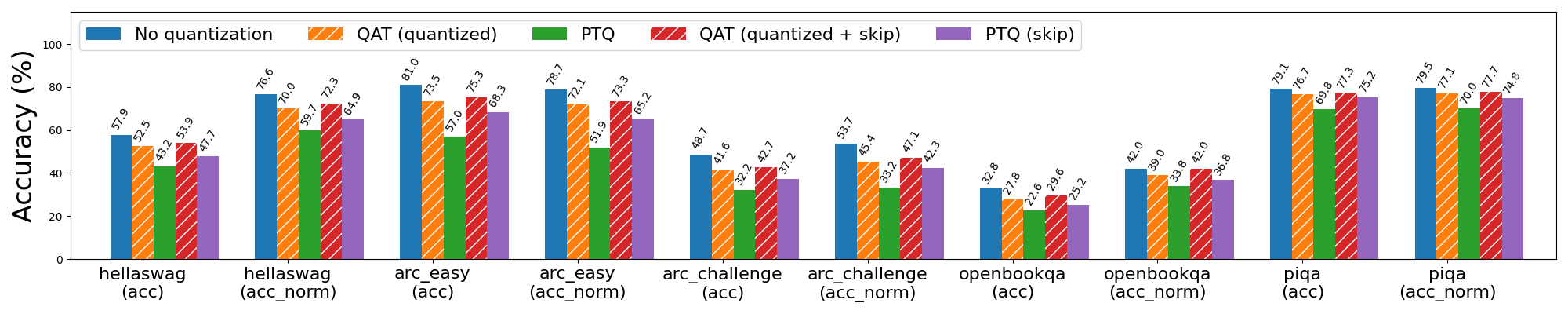
Figure 6a: Llama3-8B 3-bit weight only quantization with and without QAT. Bars with “skip” refer to skipping quantization for the first 3 and last 2 layers of the model, which are more sensitive to quantization.
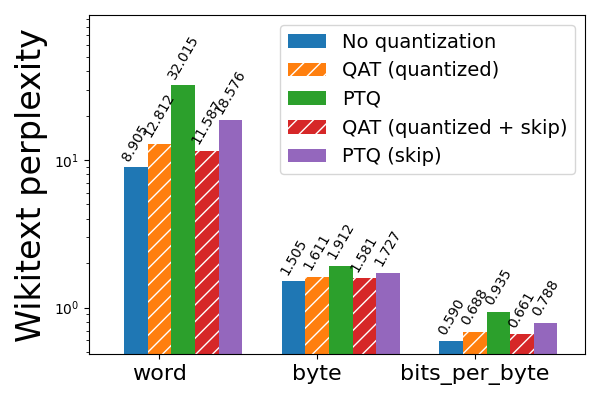
Figure 6b: Llama3-8B 3-bit weight only quantization with and without QAT, evaluated on wikitext (lower is better). Bars with “skip” refer to skipping quantization for the first 3 and last 2 layers of the model, which are more sensitive to quantization. Note the log scale.
QAT Overhead
QAT inserts many fake quantize operations throughout the model, adding considerable overhead to both the fine-tuning speed and the memory usage. For a model like Llama3-8B for example, we have (32 * 7) + 1 = 225 linear layers, each of which has at least 1 fake quantize for the weights and potentially 1 fake quantize for the input activations. Memory footprint increase is also significant, since we cannot mutate the weights in-place and so we need to clone them before applying fake quantization, though this overhead can be mostly mitigated by enabling activation checkpointing.
In our microbenchmarks, we found that 8da4w QAT fine-tuning is ~34% slower than regular full fine-tuning. With activation checkpointing, the memory increase per GPU is around 2.35 GB. Most of these overheads are fundamental to how QAT works, though we may be able to speed up computation with torch.compile in the future.
| Per GPU statistics | Full fine-tuning | QAT fine-tuning |
| Median tokens per second | 546.314 tok/s | 359.637 tok/s |
| Median peak memory | 67.501 GB | 69.850 GB |
Table 2: Llama3 QAT fine-tuning overhead for int8 per token dynamic activations + int4 grouped per channel weights on 6 A100 GPUs (each with 80GB memory).
Looking Ahead
In this blog, we presented a QAT flow for LLMs through torchao, integrated this flow with the fine-tuning APIs in torchtune, and demonstrated its potential to recover most of the quantization degradation compared to PTQ and match non-quantized performance on certain tasks. There are many directions for future explorations:
- Hyperparameter tuning. It is likely that extensive hyperparameter tuning can further improve the results of finetuning and QAT. In addition to the general hyperparameters like the learning rate, batch size, dataset size, and number of fine-tuning steps, we should also tune QAT-specific ones, such as when to start/stop fake quantization, how many steps to fake quantize, and regularization parameters for fake quantized values.
- Outlier reduction techniques. In our experiments, we found that both PTQ and QAT were susceptible to outliers. In addition to simple clamping and regularization during fine-tuning, we can explore techniques that allow the network to learn how to control these outliers (e.g. learned quantization ranges, clipped softmax, and gated attention), or possibly even borrow outlier suppression techniques from post-training settings (e.g. SpinQuant, SmoothQuant) and apply them sparingly throughout the fine-tuning process.
- Mixed-precision and more complex dtypes. Especially in the lower bit regime, we saw that skipping quantization for certain sensitive layers was effective for both PTQ and QAT. Did we need to skip quantizing these layers altogether, or can we still quantize them, just to lower bit-widths? It will be interesting to explore mixed-precision quantization in the context of QAT. Training with newer dtypes such as MX4 is another promising direction, especially given that the upcoming Blackwell GPUs will no longer support int4 tensor cores.
- Composability with LoRA and QLoRA. Our QAT integration in torchtune currently only supports the full fine-tuning workflow. However, many users wish to fine-tune their models using low-ranked adaptors to substantially reduce their memory footprint. Composing QAT with techniques like LoRA / QLoRA will enable users to reap the memory and performance benefits of these approaches while producing a model that will ultimately be quantized with minimal model quality degradation.
- Composability with torch.compile. This is another potential way to significantly speed up fake quantization computations in QAT while reducing memory footprint. torch.compile is currently not compatible with the distribution strategy used in full distributed fine-tuning recipes in torchtune (with or without QAT), but support will be added in the near future.
- Quantizing other layers. In this work, we only explored quantizing the linear layers. However, in the context of long sequence lengths, the KV cache often becomes the throughput bottleneck and can reach tens of GBs, hence LLM-QAT explored quantizing the KV cache alongside activations and weights. Prior work has also had success with quantizing the embedding layer down to 2-bits in other transformer-based models.
- End-to-end evaluation on performant cuda kernels. A natural extension of this work is to provide an end-to-end QAT flow evaluated on performant cuda kernels, similar to the existing 8da4w QAT flow lowered to XNNPACK kernels through executorch. For int4 weight only quantization, we can leverage the efficient int4 weight mm kernel with bitpacking for quantization, and there is ongoing work to add QAT support for this kernel: https://github.com/pytorch/ao/pull/383. For 8da4w quantization, mixed 4-bit/8-bit GEMM is also being added in cutlass. This will be needed to build an efficient 8da4w cuda kernel.
The QAT code can be found here. Please refer to this torchtune tutorial to get started. If you have any further questions, please feel free to open an issue on the torchao github or reach out to andrewor@meta.com. We welcome your feedback and contributions!