Overview
The most recent LLM serving frameworks and models increasingly adopt attention variants, such as Grouped Query Attention (GQA), Multi-Query Attention (MQA), PagedAttention, and sliding windows to balance accuracy and performance. Traditionally, each variant requires manually rewriting FlashAttention kernels to get reasonable performance for each specific case.
PyTorch’s torch.nn.attention.flex_attention provides a general design that covers both flexibility and efficiency. It accepts user-defined score_mod and mask_mod to describe the attention variants and their combinations, and then uses torch.compile to lower these functions to automatically generate a highly efficient FlashAttention kernel. A common attention computation is as follows:
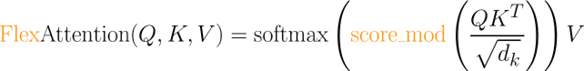
Many attention variants, e.g, Alibi Bias, Relative Position Embedding, or Tanh Soft-Capping, can be represented by the user-defined function score_mod.
Besides variants related to the attention score, other variants like the Casual Mask in Decoder layer and Jagged Tensors, are caused by the compute sparsity and can be described by the mask_mod. More examples about score_mod and mask_mod can be found in the FlexAttention Part 1 and Part 2 blogs.
The benefits of FlexAttention have led to its widespread adoption across popular LLM ecosystem projects, including HuggingFace, vLLM, and SGLang. This adoption significantly reduces the effort required to quickly adapt the latest LLM models.
Native Support FlexAttention on Intel® GPUs
FlexAttention is a powerful and flexible attention kernel in PyTorch that behaves similarly to FlashAttention but offers greater freedom to modify attention scores and masking logic. The kernel is implemented in Triton, a language that lets programmers write Cooperative Thread Array (CTA-level) GPU kernels, also known as block-level kernels.
Currently, the FlexAttention kernel template consists of two kernels: flex_atention and flex_decoding. The flex_attention kernel is designed for the prefill stage of inference and training, while the flex_decoding kernel targets the decoding stage of inference with short query and long KV cache scenarios. In PyTorch 2.9, all FlexAttention scenarios for both forward and backward are natively supported on Intel GPUs, aligned with PyTorch’s standard GPU behavior. This provides users with consistent and portable performance across different GPUs, enabling developers to write code once and achieve significant attention mechanism efficiency without any modifications.
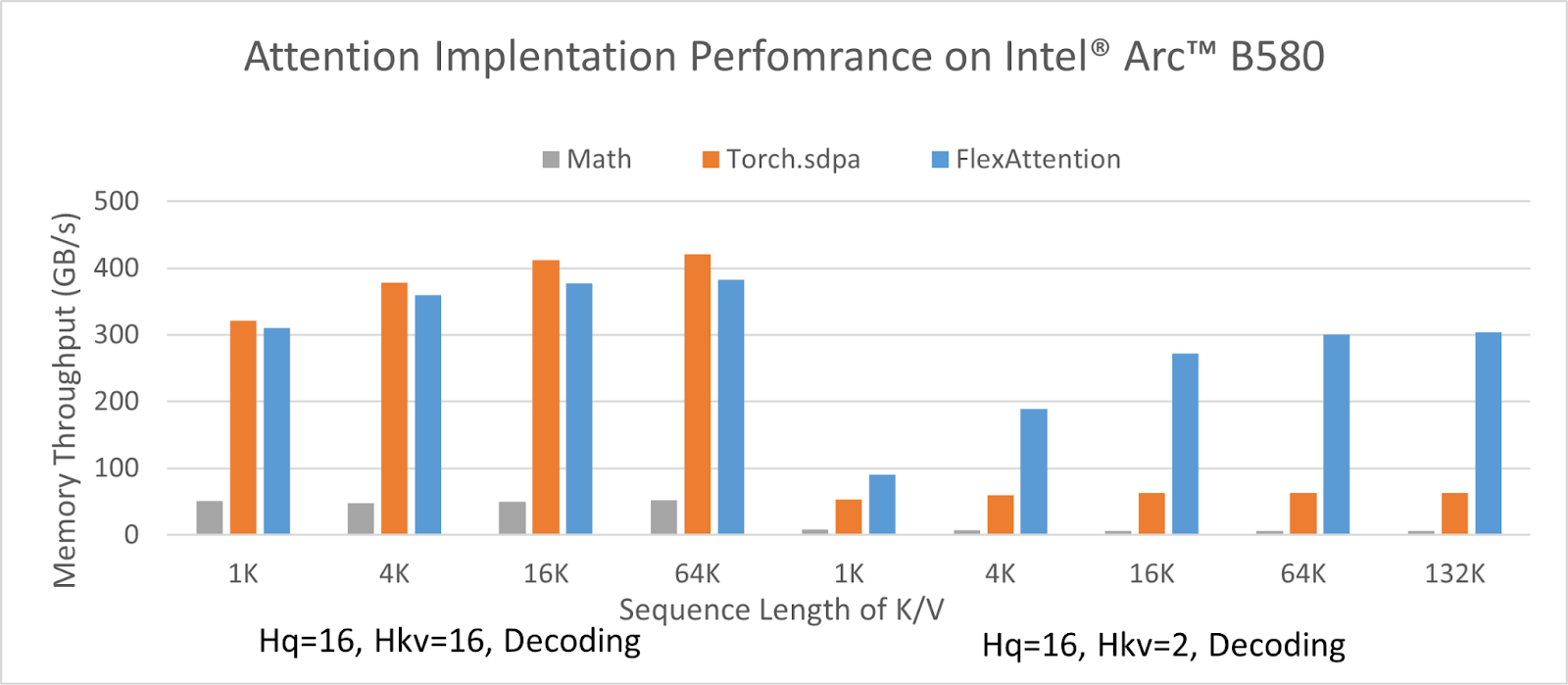
The following figure shows the kernel performance for different configurations on Intel® Arc™ B580 Graphics. With BS=1 and head_dim=128, for the Multi-Head Attention (MHA) configuration with Hq=16, Hkv=16, the FlexAttention kernel performs on par with PyTorch scaled_dot_product_attention using the oneDNN backend and significantly outperforms the Math backend. And for the GQA configuration with Hq=16, Hkv=2, FlexAttention outperforms both backends.
The public Triton compiler does not support compiling Triton kernels for Intel GPUs. Triton XPU is an Intel maintained extension of the Triton compiler that adds support for Intel GPUs, in addition to NVIDIA and AMD GPUs supported by the public Triton release. PyTorch 2.9 integrates Triton XPU, enabling Triton kernels to run on Intel GPUs. In the following sections, we introduce the optimizations applied to FlexAttention kernels using Triton XPU on Intel GPUs.
FlexAttention Attention Kernel Optimizations on Intel® GPUs
To understand the CTA-level tiling pattern in FlexAttention, we can begin with the dense attention case where no block_mask is used. (Sparse attention follows a similar pattern, except that only valid blocks are scheduled.) The FlexAttention API is designed to compute dense attention over Q, K, and V as illustrated:
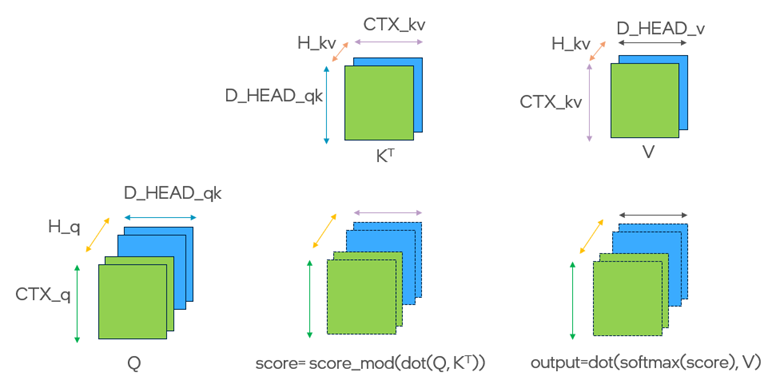
The kernel tiles the problem along the H_q, CTX_q, and CTX_kv dimensions of the Q, Kᵀ, and V matrices. The inputs are partitioned into smaller blocks:
- q: BLOCK_M × D_HEAD_qk
- kᵀ: D_HEAD_qk × BLOCK_N
- v: BLOCK_N × D_HEAD_v
Each CTA iterates serially through the CTX_kv dimension in chunks of BLOCK_N, performing (CTX_kv / BLOCK_N) steps to cover the full attention context.
When score_mod or block_mask introduces more complex computation or conditional logic inside the kernel, FlexAttention can become compute bound, as the GPU performs substantially more arithmetic per memory access. In simpler configurations, however, performance is often memory bound with data movement dominating execution time. Nevertheless, key/value (K/V) blocks movement remains the primary performance bottleneck across configurations: K/V blocks must be fetched repeatedly from global memory by different thread blocks, limiting achievable throughput even in compute heavy regimes.
To maximize FlexAttention’s efficiency, the goal is to overlap matrix multiplication, arithmetic computation, and memory access as much as possible.
Intel GPU AI-specific Features
Intel’s latest GPU architecture, included in the Intel® Arc™ B-Series Graphics cards, provides two specialized hardware components specifically designed to accelerate AI workloads:
- Intel XMX (Xe Matrix eXtensions)
XMX engines are Intel’s dedicated matrix-multiplication units—similar in concept to NVIDIA’s Tensor Cores or AMD’s Matrix Cores. They deliver high-throughput mixed-precision compute, which is critical for deep learning operations like attention.
- Block I/O
Block I/O significantly improves the efficiency of moving data from memory into registers. When used together with XMX engines, it provides streamlined, high-bandwidth data access for large AI kernels. Key Block I/O hardware capabilities include:
Direct 2D matrix loading from global memory into registers with fewer cycles.
Automatic boundary protection and zero-padding, reducing ALU operations for boundary check and padding.
Built-in support for 2D transposition and Vector Neural Network Instructions (VNNI)-format transformation during data transfer.
Asynchronous prefetching from global memory to cache, enabling better pipeline overlap.
Support for key AI data types such as INT8, BF16, and FP16 — all critical for modern inference and mixed-precision training.
Triton XPU integrates both XMX and Block I/O hardware features to accelerate Triton kernels on Intel GPUs, leveraging these dedicated components to reduce data-dependency stalls, hide memory latency, and improve overall kernel performance.
FlexAttention Tiling at Warp Level and Block I/O Synergy
PyTorch’s FlexAttention introduces high level, device backend agnostic optimizations to the attention algorithm, as described in the FlexAttention blog. These optimizations are applied uniformly across supported hardware targets. The Triton XPU compiler backend then further optimizes the underlying kernel generated in Triton language, enabling efficient execution and high performance on Intel GPUs.
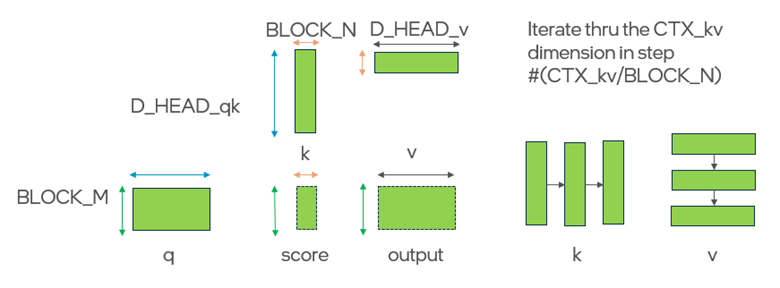
In Triton, warp level tiling is largely handled automatically by the compiler. Building on this, the Triton XPU backend further subdivides each CTA-level tile into efficient horizontal warp tiles to better match the underlying hardware. For example, when using two warps per CTA, the resulting tiling pattern can be illustrated as follows:
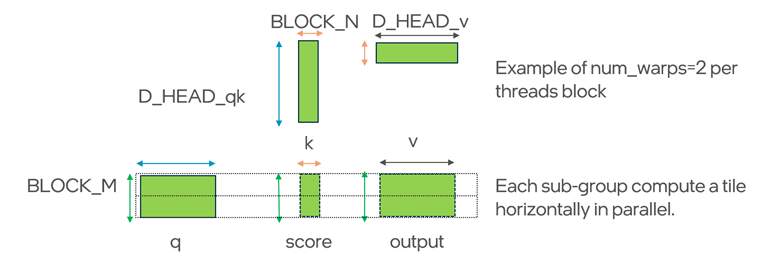
The figure illustrates how a single Triton program instance (thread block) computes a tiled portion of the attention operation. Each instance processes a block of queries of size BLOCK_M × D_HEAD_qk, which is kept fixed and reused. Keys and values are streamed in tiles of size D_HEAD_qk × BLOCK_N and BLOCK_N × D_HEAD_v, respectively. For each K tile, a BLOCK_M × BLOCK_N score tile is computed (Q × Kᵀ), softmaxed horizontally, and then multiplied with the corresponding V tile to accumulate a BLOCK_M × D_HEAD_v output tile. Parallelism is achieved by dividing the thread block into two sub-groups (warps) evenly, where each sub-group computes a portion of the tile horizontally along the N dimension. This tiling maximizes the usage of register and can run efficiently on Intel GPU, which favors register-based storage over Shared Local Memory (SLM)-based storage.
Advantages of Register-Based Execution
Query, score, and output matrices are stored directly in the general register file (GRF) of physical threads, avoiding reliance on SLM. This provides several benefits:
- XMX engines operate only on register operands, so avoiding SLM removes an extra data-movement bottleneck.
- Horizontal reductions (e.g., softmax) can be performed entirely within a warp, eliminating costly synchronization.
- The score from the first matmul can be directly reused as the input A for the next matmul, avoiding additional loads or stores through SLM.
As a result, the FlexAttention kernel executes almost entirely from registers, reducing synchronization, eliminating SLM traffic, and delivering high performance for transformer workloads on Intel GPUs.
Disadvantages of Register-Based Execution
The primary limitation is that general-purpose registers (GRFs) are private to each physical thread, causing the K and V matrices to be redundantly loaded into registers by multiple threads and rendering the kernel memory-bound. This limitation is mitigated by Triton XPU’s software loop pipelining optimization based on Block I/O. Within the software pipeline, hardware features are leveraged to overlap memory-to-cache transfers, cache-to-register loads, and MMA execution.
- Block I/O prefetching enables asynchronous data transfers from HBM to cache.
- Block I/O load operations asynchronously transfer data from cache to registers using a hardware scoreboard.
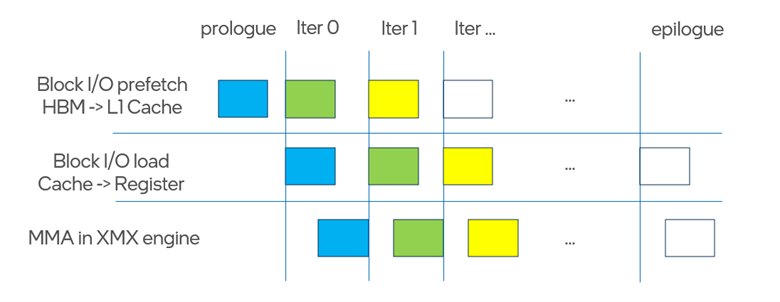
As illustrated, each iteration pipelines XMX (MMA) computation with HBM-to-L1 cache prefetching effectively hiding a large portion of memory latency. The distance of the XMX (MMA) computation and HBM-to-L1 cache prefetching in the pipelines is controlled by num_stages of the software loop pipeline.
The effectiveness of this overlap depends on the hardware resources involved and their relative latencies. For kernels with sufficiently large iteration counts, performance follows the roofline model and becomes either memory bound when memory latency dominates MMA latency or compute bound when MMA latency dominates memory latency.
In Triton XPU, software pipelining explicitly overlaps memory accesses with MMA computation by using Block I/O prefetching. Increasing num_stages increases the number of outstanding memory loads to better saturate the memory subsystem, at the cost of higher L1 cache usage.
To explicitly overlap MMA execution with cache-to-register loads in software pipeline results in excessive register pressure and spilling, leading to degraded performance. Consequently, overlap MMA and cache-to-register transfers are delegated to the hardware via instruction-level and thread-level parallelism in the same loot iteration.
FlexDecoding on Triton XPU
FlexDecoding is a specialized variant of flexible attention optimized for the decoding phase (CTX_q=1). Beyond the memory-access optimizations employed by FlexAttention, FlexDecoding introduces two key enhancements:
- Parallel K/V Processing: The K and V matrices are partitioned along CTX_kv dimensions across multiple kernel instances. This transformation converts serial iteration into parallel execution while reducing redundant K and V matrix loading.
- Optimized Vector-Matrix Operations: The XMX engine’s native support for vector–matrix multiplication (M=1), eliminates the need for padding on the CTX_q dimension for query or score matrices when the query context size is small, thereby improving decoding efficiency on Intel GPUs.
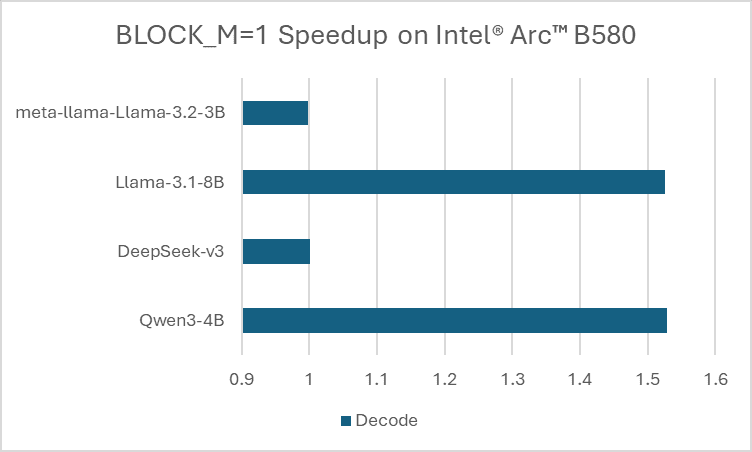
Maximizing the Performance of FlexAttention and FlexDecoding on Intel GPUs
Since users can supply arbitrary functions that modify attention scores (e.g., through score_mod) or apply custom masking logic (e.g., through mask_mod), and attention shapes may vary, the optimal kernel configuration, such as tiling sizes, number of stages, warp counts, and shared-memory usage, can differ significantly across use cases. Although the XPU heuristic template provides a default configuration for the FlexAttention kernel, a one-size-fits-all configuration is rarely optimal for diverse attention shapes and custom logic.
To handle this variability, max-autotune is a mode users can enable in torch.compile. In this mode, TorchInductor explores a wide range of kernel parameters, including block sizes, num_stages, warp counts, and tiling dimensions, and selects the configuration that delivers the best empirical performance. The max-autotune mode is supported on Intel GPUs as well.
FlexAttention Application in LLM Ecosystem
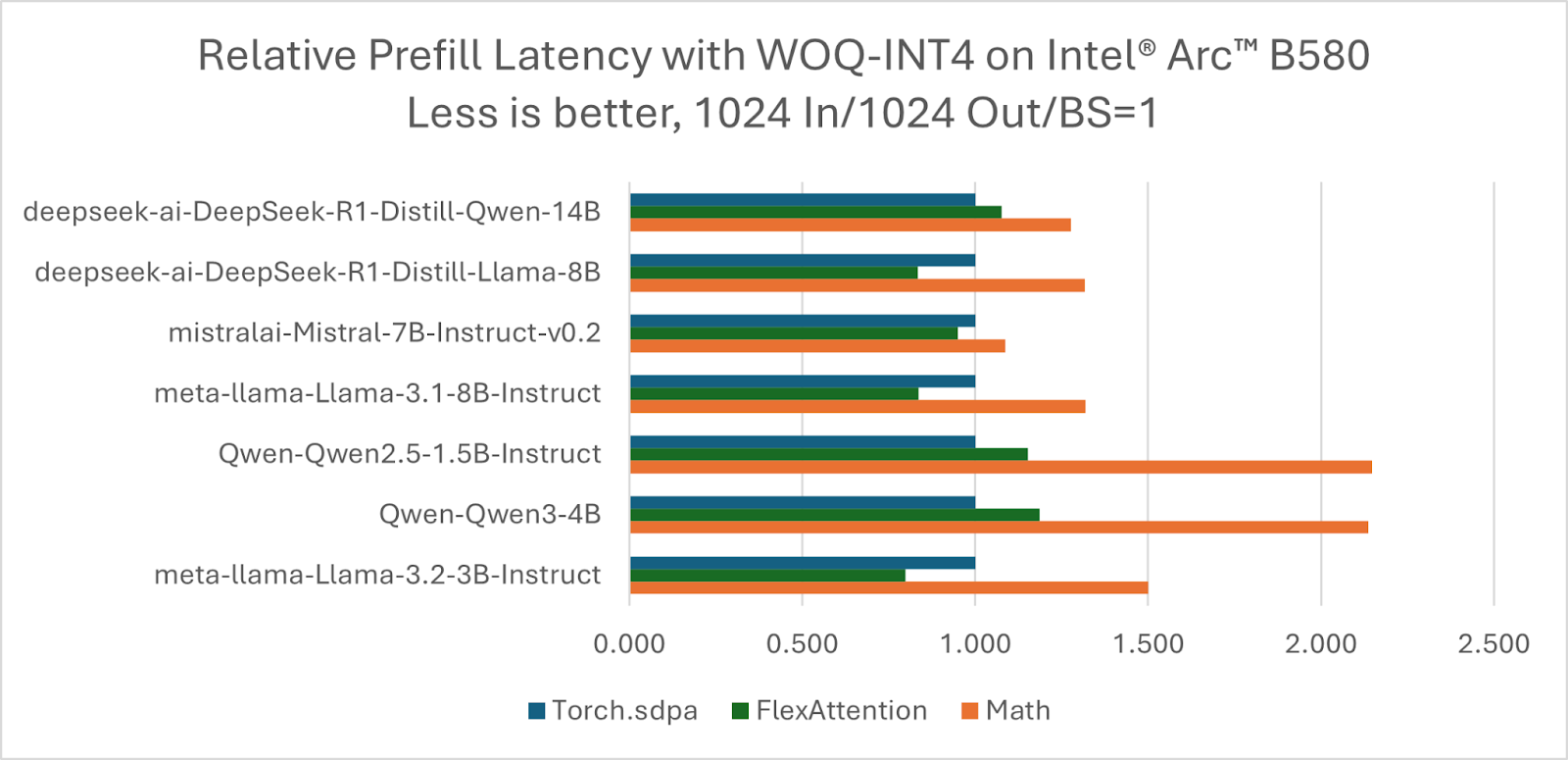
FlexAttention has been widely integrated into the popular LLM ecosystem libraries. The following figures show the performance of some popular LLMs based on HF/transformers and TorchAO. Take the torch.scaled_dot_prdocut_attention as baseline, 4/7 models can get better performance for the prefill stage using FlexAttention, while 5/7 models for the decoding stage.
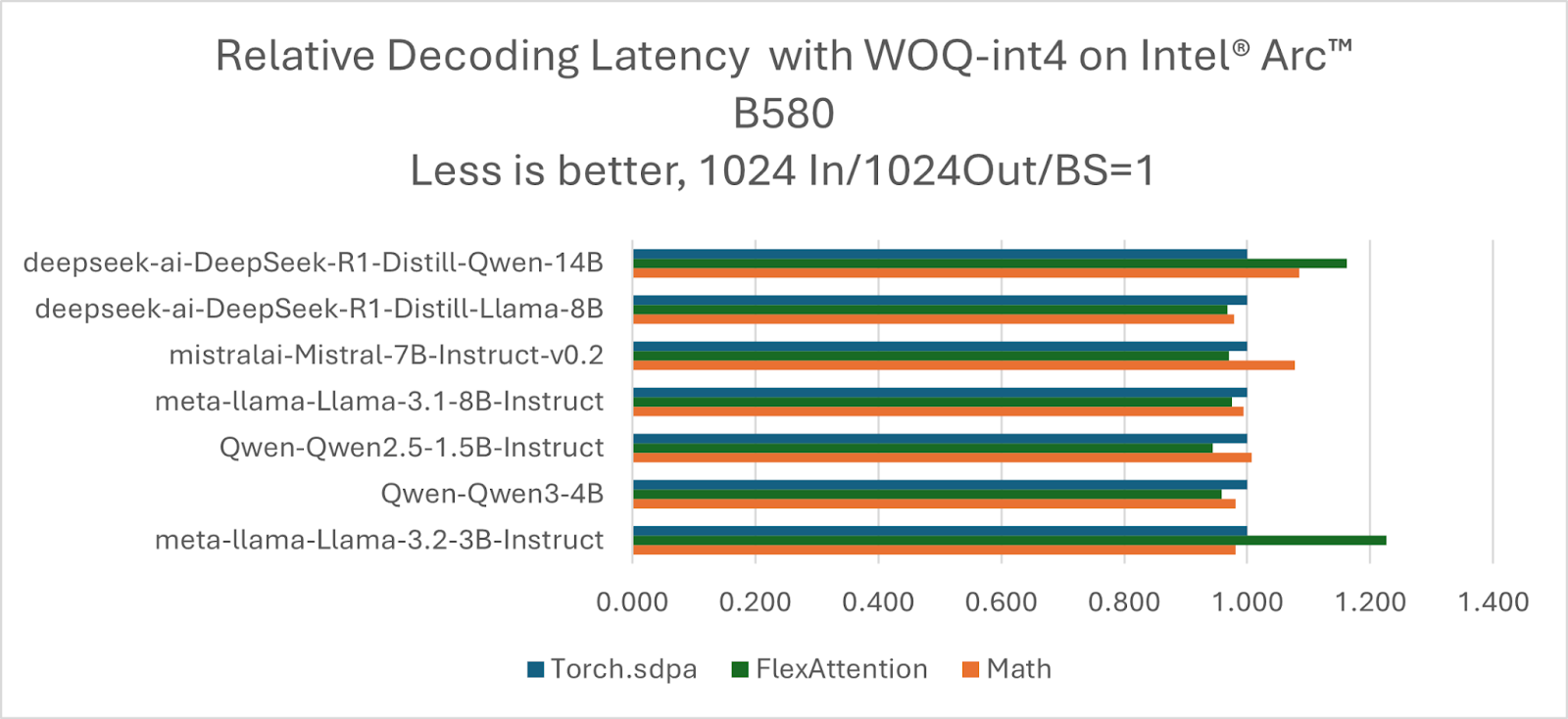
Conclusion and Future Work
We present the FlexAttention optimization progress on Intel GPUs and also show the reasonable performance data we have achieved for both kernel and end-to-end levels in this blog. FlexAttention is designed to cover all kinds of attention variants and their combination. In the future, we will extend our benchmark scope to cover more models and scenarios, e.g., chunked prefill and PagedAttention in LLM serving frameworks. Except for the Triton kernel template, we will also follow the community to enable more computation backends.
Product and Performance Information
Intel® Core™ i5-13400 (Arc B580, 12GB VRAM), Ubuntu 24.10, Driver:25.35.35096.9, PyTorch 2.9.1, TorchAO-v0.14.1